10.3.1. Модель данных при независимом действии двух факторов
Рассмотрим матрицу наблюдений двухфакторного анализа (табл. 10.4). Главный фактор – фактор A, к примеру, влияние настройки станка; дополнительный фактор – фактор B, например, влияние качества сырья. Фактор A принимает n, а фактор B – m различных значений, т.е. n – число станков, m – число партий сырья.
Таблица 10.4
Блоки |
|
Уровни фактора A (способы обработки) |
|
A1 |
|
A2 |
… |
Aj |
… |
|
An |
|
|
|
B1 |
y11 |
|
y12 |
… |
y1j |
… |
y1n |
B2 |
y21 |
|
y22 |
… |
y2j |
… |
y2n |
… |
… |
|
… |
… |
… |
… |
|
… |
Bi |
yi1 |
|
yi2 |
… |
yij |
… |
yin |
… |
… |
|
… |
… |
… |
… |
|
… |
Bm |
ym1 |
|
ym2 |
… |
ymj |
… |
ymn |
Уровни фактора A – способы обработки – отображаются в таблице по столбцам, а уровни фактора B – блоки – по строкам.
В блоке отклики могут значимо различаться только за счет различных уровней фактора A, т.е. за счет различных обработок. Это простейшая матрица наблюдений двухфакторного анализа, т.к. в каждой ячейке имеется только одно наблюдение yij. В отличие от матрицы однофакторного анализа наблюдения в любом столбце не являются однородными, т.е. не образовывают выборки, если влияние мешающего фактора значимо.
Вклады факторов A и B в значения отклика на соответствующих уровнях j и i обозначим через aj и bi. Между факторами нет взаимодействия. Таким образом, каждое наблюдение yij представляется в виде следующей аддитивной модели:
yij = bi + a j + εij , i = 1, m, j = 1, n .
Предполагается, что для случайных величин εij справедливо требование наличия нормального закона распределения N (0,σε2 ) , причем дисперсия σε2
одинакова при всех значениях j и i.
Величины вкладов aj и bi не могут быть восстановлены однозначно. Так, увеличение всех bi и уменьшение всех aj одновременно на одну и ту же константу не изменит значения yij. Для однозначного определения вкладов факторов следует использовать отклонения βi и τj отклика от µ в результате действия факторов B и A
m |
n |
βi + τj = bi + aj − µ, ∑βi = 0, |
∑τ j = 0 , |
i=1 |
j=1 |

где µ − общая средняя значений отклика, ее оценкой является величина y . Величины β1, …, βm называются эффектами блоков, они характеризуют
отклонения от β в результате действия фактора B; τ1, …, τn – эффекты обработки, характеризуют отклонения отклика из-за действия фактора A. Тогда
yij = µ + βi +τ j + εij , i = 1, m, j = 1, n .
Как и в случае однофакторного анализа, нулевая гипотеза H0 об отсутствии эффектов обработки имеет вид: τ1 =τ2 =K=τn = 0 .
10.3.2. F–отношение. Базовая таблица двухфакторного дисперсионного анализа при независимом действии факторов
Общая сумма квадратов Q разбивается уже не на две, а на три части: QA и QB, обусловленные влиянием факторов, и остаточную часть Qост, обусловленную случайной изменчивостью самих наблюдений за счет неучтенных факторов, т.е.
|
|
|
m n |
|
|
|
|
|
|
|
n |
|
|
|
m |
m |
n |
|
|
∑∑( yij − |
|
)2 = m∑( |
|
j − |
|
)2 + n∑ |
|
i + ∑∑( yij − |
|
|
j − |
|
i + |
|
)2 , |
|
|
y |
y |
y |
y |
y |
y |
y |
|
|
|
i= j=1 |
|
|
|
|
|
|
|
j=1 |
|
|
|
i=1 |
i= |
j=1 |
|
|
1442443 |
|
1442443 |
123 |
14444244443 |
|
|
|
|
|
Q |
|
|
Q |
A |
QB |
|
|
|
|
|
|
Q |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ост |
|
|
|
|
|
1 |
m |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
j = |
∑ yij |
|
|
( |
|
j − |
|
) – оценка эффекта |
|
где |
|
y |
– среднее по |
j-му столбцу, |
|
|
|
|
y |
y |
|
|
|
|
|
|
|
|
m i=1 |
1 |
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
обработки τj; |
|
i = |
∑ yij – среднее по i-му блоку, ( |
|
i − |
|
) – оценка эффекта |
|
y |
|
y |
y |
|
|
|
|
|
|
|
|
|
|
|
n |
j=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
блока βi.
Тогда базовая таблица двухфакторного дисперсионного анализа имеет вид:
Таблица 10.5
Источник |
Сумма |
Число степеней |
Средний квадрат |
дисперсии |
квадратов |
свободы |
(оценка дисперсии) |
Главные эффекты |
Qмод = QA + QB |
n+m−2 |
sмод2 |
= |
|
|
|
|
Qмод |
|
|
|
n + m − 2 |
|
|
|
|
|
|
|
Фактор A (способ |
|
|
|
2 |
|
|
|
|
QA |
обработки) |
QA |
n−1 |
sA |
= |
|
|
|
|
|
|
|
n −1 |
|
|
|
|
|
|
|
|
|
Фактор B |
QB |
m−1 |
sB2 = |
|
|
QB |
|
|
|
|
m −1 |
|
|
|
|
|
|
|
|
|
Остаточное |
|
|
2 |
|
|
|
|
|
|
Qост |
рассеяние |
Qост |
(n−1)(m−1) |
sост = |
|
|
|
|
|
|
|
|
|
|
|
|
(n |
−1)(m −1) |
|
|
|
|
Полная (общая) |
Q = Qмод + Qост |
nm−1 |
s2y |
= |
|
|
|
Q |
|
|
nm −1 |
|
|
|
|
|
|
|
|

При выполнении гипотезы H0 об отсутствии эффектов обработки
статистики sA2 и sос2 |
т являются несмещенными оценками общей дисперсии σ y2 . |
Поэтому для проверки нулевой гипотезы дисперсия по фактору A сравнивается |
с остаточной дисперсией. С этой целью вычисляется F–отношение FA = |
s2 |
A |
, |
2 |
|
|
sост |
имеющее F–распределение с n–1, (n–1)(m–1) степенями свободы. Чем больше различие между эффектами обработки τ1, …, τn, тем большую тенденцию к возрастанию проявляет F–статистика. На уровне значимости α гипотеза H0 отвергается, если F > Fα (n −1;(n −1)(m −1)), Fα – критическое значение. В этом случае влияние фактора A на отклик значимо.
|
FB = |
s2 |
Аналогично, по F–отношению |
B |
проверяется гипотеза об |
2 |
отсутствии влияния фактора B. |
|
sост |
|
|
|
= s2
По F–отношению Fмод мод проверяется значимость двухфакторной
sост2
модели с независимым действием факторов.
10.3.3. Модель данных при взаимодействии факторов
Мы рассмотрели случай, когда в каждой ячейке матрицы производится одно наблюдение. Анализ выполняется в предположении независимости или аддитивности эффектов столбцов и строк, а также остаточных эффектов. Это аддитивное свойство на практике встречается редко. Предположим, что к некоторой смеси, из которой делается подошва, добавляются два химических вещества. Добавление вещества A увеличивает прочность материала на 8%, вещества B − на 5%. Однако это не означает, что добавление обоих веществ увеличивает прочность подошвы на 13%.
Если между факторами существует взаимодействие, то ему присуща своя дисперсия σ AB2 . Без наличия параллельных наблюдений выделить величину σ AB2 из общей дисперсии невозможно. Поэтому рассмотрим общую модель, когда в каждой ячейке производится несколько наблюдений. Ограничимся так называемыми сбалансированными планами эксперимента, когда в каждой ячейке содержится равное число наблюдений L.
Каждое наблюдение yijl , l =1, L , представляется в виде
yij = µ + βi +τ j +νij +εijl ,
где νij − эффект взаимодействия факторов ( i-го уровня фактора B с j- м уровнем фактора A), εijl − вариация внутри ячейки.
Основное тождество двухфакторного дисперсионного анализа примет
вид
|
m |
n |
L |
|
|
|
|
|
|
|
|
|
|
Q = ∑∑∑( yijl − |
|
)2 |
= QA +QB +QAB +Qост . |
|
|
|
|
|
y |
|
|
|
|
|
i=1 |
j=1 l=1 |
|
|
|
|
|
|
|
|
|
|
Оценки дисперсий по факторам имеют прежний вид (табл. 10.5), оценка |
|
дисперсии |
взаимодействия факторов sAB2 = |
QAB |
, |
оценка остаточной |
|
(n −1)(m −1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
дисперсии |
sост2 |
= |
Qост |
и оценка полной дисперсии s2y |
= |
Q |
|
. |
|
nm(L −1) |
nmL −1 |
|
|
|
|
|
|
|
|
Остаточная часть Qост характеризует влияние прочих случайных факторов (кроме факторов A, B и их взаимодействия), она обусловлена наличием нескольких наблюдений в ячейке:
m |
n L |
|
|
Qост = ∑∑∑( yijl − |
|
ij )2 . |
|
|
y |
|
|
i=1 |
j=1 l=1 |
|
|
Значимость влияния факторов A, B и их взаимодействия проверяют по |
соответствующим F–отношениям (например, FAB = |
s2 |
AB |
) или их вычисленным |
2 |
|
|
|
|
sост |
уровням значимости.
10.4. Модели дисперсионного анализа со случайными факторами
Рассмотрим гнездовой план с двумя случайными факторами. Фактор A − артикул ткани, фактор B − тип изделия. Исследуем их влияние на затраты времени при изготовлении одного пошивочного изделия. Матрица наблюдений для соответствующего гнездового плана с двумя случайными факторами имеет вид:
Таблица 10.6
№ |
|
|
|
|
|
|
Артикул ткани A |
|
|
|
|
|
|
на- |
|
A1 – хлопок |
… |
|
Ai – шерсть |
… |
|
An – синтетика |
бл. |
|
Тип изделия B |
… |
|
Тип изделия B |
… |
|
Тип изделия B |
l |
B1 |
… |
Bj |
… |
Bm |
… |
B1 |
… |
Bj |
… |
Bm |
… |
B1 |
… |
Bj |
… |
Bm |
1 |
y111 |
… |
y1j1 |
… |
y1m1 |
… |
yi11 |
… |
yij1 |
… |
yim1 |
… |
yn11 |
… |
ynj1 |
… |
ynm1 |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
l |
y11l |
… |
y1jl |
… |
y1ml |
… |
yi1l |
… |
yijl |
… |
yiml |
… |
yn1l |
… |
ynjl |
… |
ynml |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
L |
y11L |
… |
y1jL |
… |
y1mL |
… |
yi1L |
… |
yijL |
… |
yimL |
… |
yn1L |
… |
ynjL |
… |
ynmL |
Сначала случайно выбирается n значений фактора A (n артикулов тканей). Затем для каждого из видов ткани также случайно отбирается m значений фактора B, т.е. m типов изделия, взятых наугад из всего многообразия

ассортимента. Для каждого изделия проводится несколько повторных измерений отклика yijl − затрат времени.
Аддитивная модель для данного плана имеет вид:
yij = µ +τi + βij + εijl ,
где yijl − затраты времени при изготовлении l-го изделия j-го типа из i-й ткани, µ − истинные затраты времени, τi − эффект i-го значения случайного фактора A (артикула ткани), βij − эффект случайно выбранного j-го типа изделия из i-й ткани, εijl − случайная ошибка.
При анализе модели со случайными факторами вклад в общую дисперсию отклика оценивается не по индивидуальным значениям факторов, а по вкладу каждого фактора в целом. В модели II, в отличии от модели с постоянными факторами, все наблюдения отклика имеют одинаковые математические
ожидания µ, µ = y = y , т.к. величины τi , βij и εijl взаимно независимы и нормально распределены с нулевым средним и дисперсиями στ2 , σβ2 и σε2 соответственно. Полная дисперсия отклика в этом случае σ y2 = στ2 +σ β2 +σε2 .
Соответствующие суммы квадратов в данной модели имеют вид:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
Qτ |
= Lm∑( |
|
|
i − |
|
|
)2 |
|
|
|
y |
y |
− сумма квадратов между средними по гнездам из m |
|
i=1 |
|
|
|
столбцов и общим средним |
|
, |
y |
|
n m |
|
|
|
Qβ |
= L∑∑( |
|
ij − |
|
)2 |
|
y |
y |
− сумма квадратов между средними по столбцам и |
i=1 j=1
общим средним в каждом гнезде,
n m L
Qост = ∑∑∑( yijl − y)2 .
i=1 j=1 l=1
Базовая таблица двухфакторного дисперсионного анализа для модели II имеет вид:
Таблица 10.7
|
Источник дисперсии |
Сумма |
Число степеней |
Средний квадрат |
|
квадратов |
свободы |
(оценка дисперсии) |
|
|
|
Между значениями |
|
|
2 |
|
|
Qτ |
|
фактора A |
Qτ |
n−1 |
sτ |
= |
|
|
|
|
|
n −1 |
|
|
|
|
|
|
|
Между значениями |
|
|
|
|
|
Qβ |
|
фактора B при |
|
|
2 |
|
|
|
разных значениях |
Qβ |
n(m−1) |
sβ = |
|
|
|
|
|
|
|
|
n(m −1) |
|
фактора A |
|
|
|
|
|
Qост |
|
Остаточное |
|
|
2 |
|
|
|
рассеяние |
Qост |
nm(L−1) |
sост = |
|
|
|
|
|
|
|
|
nm(L −1) |
|
|
|
|
|

Для рассматриваемого гнездового плана (табл. 10.5) с двумя случайными
|
|
σ 2 |
= 0 |
− |
|
Fτ = |
sτ2 |
факторами гипотеза H0: |
τ |
|
проверяется с помощью F отношения |
|
|
sβ2 |
. |
Для заданного |
уровня |
значимости α нулевая гипотеза |
отклоняется |
при |
Fτ > Fα (n −1;n(m −1)). |
|
|
|
|
|
|
|
|
Гипотеза |
H0: σβ2 |
= 0 |
проверяется сравнением |
Fβ = |
sβ2 |
с |
2 |
|
Fα (n(m −1);nm(L −1)). |
|
|
|
|
sост |
|
|
|
|
|
|
|
|
|
|
Если предположить, что в матрице наблюдений для каждого из видов ткани (гнезда Ai, i = 1, …, n) типы изделия (уровни B1, ..., Bm) одинаковы и отобраны неслучайно, то справедлива модель I, дисперсионный анализ которой можно выполнить, например, в пакете STATGRAPHICS по аналогии с примером. Обычно выводы о влиянии факторов и их взаимодействий, полученные для модели II, сохраняются и для модели I.
Для рассмотренного в указанном примере плана эксперимента с тремя факторами в предположении их случайной природы (модель II) проверка нулевых гипотез об отсутствии влияния на сбыт продукции усложняется.
s2
Взаимодействие трех факторов легко проверяется с помощью отношения sABC2 .
ост
s2
Взаимодействия двух факторов проверяются с помощью отношений типа 2AB
sABC
(для факторов A и B). Проверка же влияния каждого фактора в отдельности возможна только, когда установлено отсутствие его совместного влияния с каждым другим фактором. Так влияние фактора A может быть проверено с
s2
помощью отношения 2A , только если была принята гипотеза об отсутствии
sост
влияния взаимодействия AB и AC.
Модели дисперсионного анализа со случайными факторами неустойчивы к нарушениям предположений о нормальности и независимости эффектов случайных факторов. Эти нарушения могут привести к ошибкам при проверке гипотез.
Упражнение 10.2. На четырех предприятиях B1, ..., B4 прверялись три технологии производства A1, A2, A3 однотипных изделий. Данные о производительности труда в условных единицах приведены в таблице:
Предприятие B |
|
|
Технология производства A |
|
|
|
A1 |
|
|
A2 |
|
|
A3 |
|
|
1 |
2 |
3 |
1 |
2 |
3 |
1 |
2 |
3 |
1 |
50 |
54 |
58 |
62 |
60 |
58 |
65 |
71 |
65 |
2 |
54 |
46 |
50 |
64 |
59 |
60 |
59 |
54 |
61 |
3 |
52 |
48 |
50 |
70 |
62 |
60 |
59 |
66 |
64 |
4 |
60 |
55 |
56 |
58 |
54 |
50 |
71 |
74 |
62 |
Требуется на уровне значимости α = 0,05 установить влияние на производительность труда технологий (фактор A) и предприятий (фактор B).
Глава 11. Корреляционный анализ
Для выяснения тех или иных причинно-следственных связей необходимо вести одновременные наблюдения над парой или большим числом случайных величин, т.е. системой случайных величин. Такую систему называют
многомерной случайной величиной.
Определение 11.1. Корреляционный анализ – совокупность методов исследования параметров многомерного признака, позволяющая по выборке из генеральной совокупности сделать статистические выводы о мерах статистической зависимости между компонентами исследуемого признака.
Понятия корреляции и регрессии появились во второй половине XIX в. благодаря работам английских статистиков К. Пирсона и Ф. Гальтона.
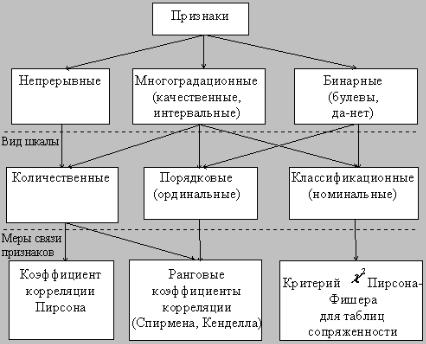
11.1. Типы признаков и их классификация
Исследуемые переменные по виду шкалы принимаемых значений
подразделяются на количественные, порядковые и классификационные.
Количественные признаки измеряются либо в непрерывной шкале, например, температура, длина, либо в интервальной или дискретной шкале −
когда о их величине судят по попаданию наблюдения в определенный диапазон (интервал) значений, например, измерение времени при усадке материала с точностью до недели.
Порядковые (ординальные) признаки не поддаются количественной оценке. Реальным содержанием их измерений является тот порядок, в котором выстраиваются объекты по степени выраженности измеряемого признака. Например, уровни музыкальных и математических способностей учащихся; двигательные и умственные способности детей. На сколько (или во сколько раз) признак более выражен, не имеет значения, действительны лишь операции типа «больше», «меньше».
Содержанием измерений классификационных (номинальных) признаков
являются лишь соотношения типа x = c или x ≠ c , x (a, b) или x (a, b) . Взаимный порядок здесь уже не имеет значения. Каждый признак делит группу исследуемых объектов на подгруппы. Например, при обработке социологических анкет признак пола разделяет людей на мужчин и женщин; профессия имеет уже большее число наименований.
Классификация основных типов переменных по виду шкалы принимаемых значений и способу измерения статистической связи имеет следующий вид
157
Рис. 11.1. Классификация основных типов переменных
11.2. Виды зависимостей между количественными переменными
11.2.1. Функциональные и статистические зависимости
→
Обозначим через Y и X = ( X1,K, X p ) одну и набор случайных величин,
зависимость между которыми нас интересует. В частном случае p=1, и имеем две случайные величины Y и X. Модель взаимосвязи определяется природой
→
анализируемых переменных Y и X , и бывает двух видов.
→
Функциональные зависимости y = f ( x) имеют место при исследовании связей между неслучайными переменными. Выборочные значения y зависят только от соответствующих значений x1, x2, …, xp и полностью ими определяются. В этом случае в статистических методах нет необходимости.
Статистические зависимости характеризуются тем, что изменение одной из величин влечет изменение закона распределения другой. Они возникают в следующих случаях:
→
1) При исследовании связей между случайными переменными Y и X . В этом
→
случае величины Y и X зависят от множества неконтролируемых факторов. 2) При исследовании связей между случайными или неслучайными
→
переменными Y и X , измеряемыми с некоторой случайной ошибкой. В этом
158

случае наблюдаются не сами переменные, а искаженные, случайные величины
Y ′ = Y +εy , X i′ = X i +εxi , i =1, p .
3) При анализе влияния на случайный показатель Y неслучайных факторов X1, X2, …, Xp. Такая связь может быть вызвана двумя причинами:
-ошибками измерения показателя Y, по отношению к которым ошибки измерения факторов X1, …, Xp пренебрежимо малы;
-влиянием помимо факторов X1, …, Xp еще и ряда неконтролируемых (неучтенных) факторов.
11.2.2. Типы корреляционных зависимостей
Отметим особый частный случай статистической зависимости – корреляционную зависимость, изучаемую в корреляционном анализе.
Определение 11.2. Статистическая зависимость, при которой при изменении одной из величин изменяется среднее значение другой, называется корреляционной зависимостью.
Корреляционная зависимость может быть представлена в виде
M[Y / x] = M x [Y ] = ϕ(x) или M[X / y] = M y [X ] =ψ( y) , |
(11.1) |
где ϕ(x) ≠ const , ψ( y) ≠ const .
Уравнения (11.1) называются (модельными) уравнениями регрессии
соответственно Y по X и X по Y, функции ϕ(x) и ψ(y) − функции (модели)
регрессии, а их графики – (модельными) линиями регрессии.
Основная задача корреляционного анализа – выявление статистической связи между случайными переменными и оценка ее тесноты.
Перед изложением материала остановимся на некоторых «ограничительных» моментах в применении корреляционного анализа.
Американскому писателю О. Генри принадлежит ироническое определение статистики: «Есть три вида лжи − просто ложь, ложь злостная и … статистика!». Попробуем разобраться в причинах, побудивших написать эти слова.
Существо и причины найденной статистической зависимости лежат вне статистических методов. Например, можно обнаружить положительную корреляцию между дозами лекарств и смертностью больных, хотя при очень серьезных заболеваниях смертность увеличивается не из-за больших доз медикаментов, а вопреки им.
Корреляционная зависимость может быть обусловлена: - причинной зависимостью между X и Y;

-общей зависимостью X и Y от третьей величины;
-неоднородностью материала;
-быть чисто формальной (нонсенс-корреляция).
Причинная зависимость существует, например, между талантом и успехом, между временем работы и стоимостью произведенной продукции, между урожайностью сельскохозяйственных культур и погодными условиями.
Причиной корреляции вследствие неоднородности является неоднородный статистический материал, в котором объединены в один показатель различные качественные признаки. Это может иметь следствием эффект корреляции, полностью отличающейся от корреляционной связи внутри каждого из этих качественных признаков.
Вслучае зависимости от третьей величины (совместная корреляция)
найденная корреляционная связь не будет отражать фактической причинной зависимости и приведет к неправильным выводам.
Вряду беспричинных корреляций имеется еще формальная корреляция, не находящая никакого объяснения и основанная лишь на количественном соотношении между переменными.
При анализе значимости корреляции можно предложить следующую схему (рис. 11.2), позволяющую выявить истинную корреляцию за счет исключения других возможных зависимостей:
Формальная корреляция
да нет
Корреляция вследствие неоднородности
да нет
Совместная корреляция
да нет
Причинная корреляция
Рис. 11.2. Схема выявления причинной корреляции