

Алгоритмы C++
.pdfКоличество различных подстрок в строке
Дана строка  длины
длины  . Требуется посчитать количество её различных подстрок.
. Требуется посчитать количество её различных подстрок.
Будем решать эту задачу итеративно. А именно, научимся, зная текущее количество различных подстрок, пересчитывать это количество при добавлении в конец одного символа.
Итак, пусть — текущее количество различных подстрок строки  , и мы добавляем в конец символ
, и мы добавляем в конец символ  . Очевидно, в результате могли появиться некоторые новые подстроки, оканчивавшиеся на этом новом символе
. Очевидно, в результате могли появиться некоторые новые подстроки, оканчивавшиеся на этом новом символе  . А именно, добавляются в качестве новых те подстроки, оканчивающиеся на символе
. А именно, добавляются в качестве новых те подстроки, оканчивающиеся на символе  и не встречавшиеся ранее.
и не встречавшиеся ранее.
Возьмём строку |
и инвертируем её (запишем символы в обратном порядке). Наша задача — |
|
посчитать, сколько у строки |
таких префиксов, которые не встречаются в ней более нигде. Но если мы посчитаем |
|
для строки префикс-функцию и найдём её максимальное значение |
, то, очевидно, в строке встречается (не |
|
вначале) её префикс длины  , но не большей длины. Понятно, префиксы меньшей длины уж точно встречаются
, но не большей длины. Понятно, префиксы меньшей длины уж точно встречаются
вней.
Итак, мы получили, что число новых подстрок, появляющихся при дописывании символа 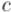 , равно
, равно  .
.
Таким образом, для каждого дописываемого символа мы за |
можем пересчитать количество различных |
подстрок строки. Следовательно, за  мы можем найти количество различных подстрок для любой заданной строки.
мы можем найти количество различных подстрок для любой заданной строки.
Стоит заметить, что совершенно аналогично можно пересчитывать количество различных подстрок и при дописывании символа в начало, а также при удалении символа с конца или с начала.
Сжатие строки
Дана строка  длины
длины  . Требуется найти самое короткое её "сжатое" представление, т.е. найти такую строку
. Требуется найти самое короткое её "сжатое" представление, т.е. найти такую строку
 наименьшей длины, что
наименьшей длины, что  можно представить в виде конкатенации одной или нескольких копий
можно представить в виде конкатенации одной или нескольких копий  .
.
Понятно, что проблема является в нахождении длины искомой строки  . Зная длину, ответом на задачу будет, например, префикс строки
. Зная длину, ответом на задачу будет, например, префикс строки  этой длины.
этой длины.
Посчитаем по строке |
префикс-функцию. Рассмотрим её последнее значение, т.е. |
, и введём |
|
обозначение |
. Покажем, что если |
делится на , то это и будет длиной ответа, |
|
иначе эффективного сжатия не существует, и ответ равен . |
|
||
Действительно, пусть |
делится на . Тогда строку можно представить в виде нескольких блоков длины , причём, |
||
по определению префикс-функции, префикс длины |
будет совпадать с её суффиксом. Но тогда последний |
||
блок должен будет совпадать с предпоследним, предпоследний - с предпредпоследним, и т.д. В итоге получится, что

все блоки блоки совпадают, и такое  действительно подходит под ответ.
действительно подходит под ответ.
Покажем, что этот ответ оптимален. Действительно, в противном случае, если бы нашлось меньшее , то и префикс-функция на конце была бы больше, чем  , т.е. пришли к противоречию.
, т.е. пришли к противоречию.
Пусть теперь  не делится на . Покажем, что отсюда следует, что длина ответа равна
не делится на . Покажем, что отсюда следует, что длина ответа равна  . Докажем от противного
. Докажем от противного
— предположим, что ответ существует, и имеет длину  (
( делитель
делитель  ). Заметим, что префикс-функция необходимо должна быть больше , т.е. этот суффикс должен частично накрывать первый блок. Теперь рассмотрим второй блок строки; т.к. префикс совпадает с суффиксом, и и префикс, и суффикс покрывают этот блок, и
). Заметим, что префикс-функция необходимо должна быть больше , т.е. этот суффикс должен частично накрывать первый блок. Теперь рассмотрим второй блок строки; т.к. префикс совпадает с суффиксом, и и префикс, и суффикс покрывают этот блок, и
их смещение друг относительно друга не делит длину блока (а иначе бы |
делило ), то все символы |
блока совпадают. Но тогда строка состоит из одного и того же символа, отсюда |
, и ответ должен существовать, т. |
е. так мы придём к противоречию. |
|
|
|
|
|
Построение автомата по префикс-функции
Вернёмся к уже неоднократно использованному приёму конкатенации двух строк через разделитель, т.е. для данных
строк и вычисление префикс-функции для строки |
. Очевидно, что т.к. символ |
является |
разделителем, то значение префикс-функции никогда не превысит |
. Отсюда следует, что, как |
|
упоминалось при описании алгоритма вычисления префикс-функции, достаточно хранить только строку и значения префикс-функции для неё, а для всех последующих символов префикс-функцию вычислять на лету:
Действительно, в такой ситуации, зная очередной символ и значение префикс-функции в предыдущей позиции, можно будет вычислить новое значение префикс-функции, никак при этом не используя все предыдущие символы строки  и значения префикс-функции в них.
и значения префикс-функции в них.
Другими словами, мы можем построить автомат: состоянием в нём будет текущее значение префикс-функции, переходы из одного состояния в другое будут осуществляться под действием символа:

Таким образом, даже ещё не имея строки  , мы можем предварительно построить такую таблицу переходов
, мы можем предварительно построить такую таблицу переходов  с помощью того же алгоритма вычисления префикс-функции:
с помощью того же алгоритма вычисления префикс-функции:
string s; // входная строка
const int alphabet = 256; // мощность алфавита символов, обычно меньше
s += '#';
int n = (int) s.length();
vector<int> pi = prefix_function (s);
vector < vector<int> > aut (n, vector<int> (alphabet)); for (int i=0; i<n; ++i)
for (char c=0; c<alphabet; ++c) { int j = i;
while (j > 0 && c != s[j]) j = pi[j-1];
if (c == s[j]) ++j; aut[i][c] = j;
}
Правда, в таком виде алгоритм будет работать за |
( — мощность алфавита). Но заметим, что |
|||
вместо внутреннего цикла |
, который постепенно укорачивает ответ, мы можем воспользоваться уже |
|||
вычисленной частью таблицы: переходя от значения |
к значению |
, мы фактически говорим, что переход |
||
из состояния |
приведёт в то же состояние, что и переход |
, а для него ответ уже точно посчитан (т. |
||
к. |
): |
|
|
|
string s; // входная строка
const int alphabet = 256; // мощность алфавита символов, обычно меньше
s += '#';
int n = (int) s.length();
vector<int> pi = prefix_function (s);
vector < vector<int> > aut (n, vector<int> (alphabet)); for (int i=0; i<n; ++i)

for (char c=0; c<alphabet; ++c) if (i > 0 && c != s[i])
aut[i][c] = aut[pi[i-1]][c];
else
aut[i][c] = i + (c == s[i]);
В итоге получилась крайне простая реализация построения автомата, работающая за  .
.
Когда может быть полезен такой автомат? Для начала вспомним, что мы считаем префикс-функцию для строки  , и её значения обычно используют с единственной целью: найти все вхождения строки
, и её значения обычно используют с единственной целью: найти все вхождения строки  в строку
в строку  .
.
Поэтому самая очевидная польза от построения такого автомата — ускорение вычисления префиксфункции для строки . Построив по строке автомат, нам уже больше не нужна ни строка  ,
,
ни значения префикс-функции в ней, не нужны и никакие вычисления — все переходы (т.е. то, как будет меняться префикс-функция) уже предпосчитаны в таблице.
Но есть и второе, менее очевидное применение. Это случай, когда строка  является гигантской строкой, построенной по какому-либо правилу. Это может быть, например, строка Грея или строка, образованная рекурсивной комбинацией нескольких коротких строк, поданных на вход.
является гигантской строкой, построенной по какому-либо правилу. Это может быть, например, строка Грея или строка, образованная рекурсивной комбинацией нескольких коротких строк, поданных на вход.
Пусть для определённости мы решаем такую задачу: дан номер |
строки Грея, и дана строка |
|
длины |
. Требуется посчитать количество вхождений строки |
в -ю строку Грея. Напомним, строки |
Грея определяются таким образом: |
|
|
|
|
|
|
|
|
В таких случаях даже просто построение строки будет невозможным из-за её астрономической длины (например, -
ая строка Грея имеет длину |
). Тем не менее, мы сможем посчитать значение префикс-функции на конце |
|||
этой строки, зная значение префикс-функции, которое было перед началом этой строки. |
||||
Итак, помимо самого автомата также посчитаем такие величины: |
— значение автомата, достигаемое |
|||
после "скармливания" ему строки , если до этого автомат находился в состоянии |
. Вторая величина — |
|||
— количество вхождений строки |
в строку , если до "скармливания" этой строки |
автомат находился в состоянии |
||
. Фактически, |
— это количество раз, которое автомат принимал значение |
за время |
||
"скармливания" строки . Понятно, что ответом на задачу будет величина |
. |
|||

Как считать эти величины? Во-первых, базовыми значениями являются , . А все последующие значения можно вычислять по предыдущим значениям и используя автомат. Итак, для вычисления
этих значений для некоторого |
мы вспоминаем, что строка |
состоит из |
плюс -ый символ алфавита плюс |
||
снова |
. Тогда после "скармливания" первого куска ( |
) автомат перейдёт в состояние |
, затем |
||
после "скармливания" символа |
он перейдёт в состояние: |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
После этого автомату "скармливается" последний кусок, т.е. 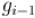 :
:
|
|
|
|
Количества |
легко считаются как сумма количеств по трём кускам : строка |
, символ |
, и снова |
строка |
: |
|
|
|
|
|
|
|
|
|
|
Итак, мы решили задачу для строк Грея, аналогично можно решить целый класс таких задач. Например, точно таким же методом решается следующая задача: дана строка  , и образцы , каждый из которых задаётся следующим образом: это строка из обычных символов, среди которых могут встречаться рекурсивные вставки других
, и образцы , каждый из которых задаётся следующим образом: это строка из обычных символов, среди которых могут встречаться рекурсивные вставки других
строк в форме |
, которая означает, что в это место должно быть вставлено |
экземпляров строки . |
Пример такой схемы: |
|
|
|
|
|
|
|
|
Гарантируется, что это описание не содержит в себе циклических зависимостей. Ограничения таковы, что если явным образом раскрывать рекурсию и находить строки  , то их длины могут достигать порядка
, то их длины могут достигать порядка  .
.
Требуется найти количество вхождений строки  в каждую из строк
в каждую из строк  .
.
Задача решается так же, построением автомата префикс-функции, затем надо вычислять и добавлять в него переходы по целым строкам 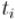 . В общем-то, это просто более общий случай по сравнению с задачей о строках Грея.
. В общем-то, это просто более общий случай по сравнению с задачей о строках Грея.

Алгоритмы хэширования в задачах на строки
Алгоритмы хэширования строк помогают решить очень много задач. Но у них есть большой недостаток: что чаще всего они не 100%-ны, поскольку есть множество строк, хэши которых совпадают. Другое дело, что в большинстве задач на это можно не обращать внимания, поскольку вероятность совпадения хэшей всё-таки очень мала.
Определение хэша и его вычисление
Один из лучших способов определить хэш-функцию от строки S следующий:
h(S) = S[0] + S[1] * P + S[2] * P^2 + S[3] * P^3 + ... + S[N] * P^N
где P - некоторое число.
Разумно выбирать для P простое число, примерно равное количеству символов во входном алфавите. Например, если строки предполаются состоящими только из маленьких латинских букв, то хорошим выбором будет P = 31. Если буквы могут быть и заглавными, и маленькими, то, например, можно P = 57.
Во всех кусках кода в этой статье будет использоваться P = 31.
Само значение хэша желательно хранить в самом большом числовом типе - int64, он же long long. Очевидно, что при длине строки порядка 20 символов уже будет происходить переполнение значение. Ключевой момент - что мы не обращаем внимание на эти переполнения, как бы беря хэш по модулю 2^64.
Пример вычисления хэша, если допустимы только маленькие латинские буквы:
const int p = 31;
long long hash = 0, p_pow = 1;
for (size_t i=0; i<s.length(); ++i)
{
//желательно отнимать 'a' от кода буквы
//единицу прибавляем, чтобы у строки вида 'AAAAA' хэш был ненулевой hash += (s[i] - 'a' + 1) * p_pow;
p_pow *= p;

}
В большинстве задач имеет смысл сначала вычислить все нужные степени P в каком-либо массиве.
Пример задачи. Поиск одинаковых строк
Уже теперь мы в состоянии эффективно решить такую задачу. Дан список строк S[1..N], каждая длиной не более
M символов. Допустим, требуется найти все повторяющиеся строки и разделить их на группы, чтобы в каждой группе были только одинаковые строки.
Обычной сортировкой строк мы бы получили алгоритм со сложностью O (N M log N), в то время как используя хэши,
мы получим O (N M + N log N).
Алгоритм. Посчитаем хэш от каждой строки, и отсортируем строки по этому хэшу.
vector<string> s (n);
//... считывание строк ...
//считаем все степени p, допустим, до 10000 - максимальной длины строк const int p = 31;
vector<long long> p_pow (10000); p_pow[0] = 1;
for (size_t i=1; i<p_pow.size(); ++i) p_pow[i] = p_pow[i-1] * p;
//считаем хэши от всех строк
//в массиве храним значение хэша и номер строки в массиве s
vector < pair<long long, int> > hashes (n); for (int i=0; i<n; ++i)
{
long long hash = 0;
for (size_t j=0; j<s[i].length(); ++j)
hash += (s[i] - 'a' + 1) * p_pow[j]; hashes[i] = make_pair (hash, i);
}
// сортируем по хэшам

sort (hashes.begin(), hashes.end());
// выводим ответ
for (int i=0, group=0; i<n; ++i)
{
if (i == 0 || hashes[i].first != hashes[i-1].first) cout << "\nGroup " << ++group << ":";
cout << ' ' << hashes[i].second;
}
Хэш подстроки и его быстрое вычисление
Предположим, нам дана строка S, и даны индексы I и J. Требуется найти хэш от подстроки S[I..J]. По определению имеем:
H[I..J] = S[I] + S[I+1] * P + S[I+2] * P^2 + ... + S[J] * P^(J-I)
откуда:
H[I..J] * P[I] = S[I] * P[I] + ... + S[J] * P[J],
H[I..J] * P[I] = H[0..J] - H[0..I-1]
Полученное свойство является очень важным.
Действительно, получается, что, зная только хэши от всех префиксов строки S, мы можем за O
(1) получить хэш любой подстроки.
Единственная возникающая проблема - это то, что нужно уметь делить на P[I]. На самом деле, это не так
просто. Поскольку мы вычисляем хэш по модулю 2^64, то для деления на P[I] мы должны найти к нему обратный элемент в поле (например, с помощью Расширенного алгоритма Евклида), и выполнить умножение на этот обратный элемент.
Впрочем, есть и более простой путь. В большинстве случаев, вместо того чтобы делить хэши на степени
P, можно, наоборот, умножать их на эти степени.
Допустим, даны два хэша: один умноженный на P[I], а другой - на P[J]. Если I < J, то умножим перый хэш на P[J-I], иначе же умножим второй хэш на P[J-I]. Теперь мы привели хэши к одной степени, и можем их спокойно сравнивать.

Например, код, который вычисляет хэши всех префиксов, а затем за O (1) сравнивает две подстроки:
string s; int i1, i2, len; // входные данные
//считаем все степени p const int p = 31;
vector<long long> p_pow (s.length()); p_pow[0] = 1;
for (size_t i=1; i<p_pow.size(); ++i) p_pow[i] = p_pow[i-1] * p;
//считаем хэши от всех префиксов vector<long long> h (s.length()); for (size_t i=0; i<s.length(); ++i)
{
h[i] = (s[i] - 'a' + 1) * p_pow[i];
if (i) h[i] += h[i-1];
}
//получаем хэши двух подстрок long long h1 = h[i1+len-1];
if (i1) h1 -= h[i1-1]; long long h2 = h[i2+len-1]; if (i2) h2 -= h[i2-1];
//сравниваем их
if (i1 < i2 && h1 * p_pow[i2-i1] == h2 || i1 > i2 && h1 == h2 * p_pow[i1-i2]) cout << "equal";
else
cout << "different";
Применение хэширования
Вот некоторые типичные применения хэширования:
● Алгоритм Рабина-Карпа поиска подстроки в строке за O (N)

●Определение количества различных подстрок за O (N^2 log N) (см. ниже)
●Определение количества палиндромов внутри строки
Определение количества различных подстрок
Пусть дана строка S длиной N, состоящая только из маленьких латинских букв. Требуется найти количество различных подстрок в этой строке.
Для решения переберём по очереди длину подстроки: L = 1 .. N.
Для каждого L мы построим массив хэшей подстрок длины L, причём приведём хэши к одной степени, и отсортируем этот массив. Количество различных элементов в этом массиве прибавляем к ответу.
Реализация:
string s; // входная строка int n = (int) s.length();
//считаем все степени p const int p = 31;
vector<long long> p_pow (s.length()); p_pow[0] = 1;
for (size_t i=1; i<p_pow.size(); ++i) p_pow[i] = p_pow[i-1] * p;
//считаем хэши от всех префиксов vector<long long> h (s.length()); for (size_t i=0; i<s.length(); ++i)
{
h[i] = (s[i] - 'a' + 1) * p_pow[i];
if (i) h[i] += h[i-1];
}
int result = 0;
// перебираем длину подстроки for (int l=1; l<n; ++l)
{
// ищем ответ для текущей длины