

36. Метод «деревья решений».
Возникновение – 50-е годы. Метод также называют деревьями решающих правил, деревьями классификации и регрессии. Это способ представления правил в иерархической, последовательной структуре.
Пример.
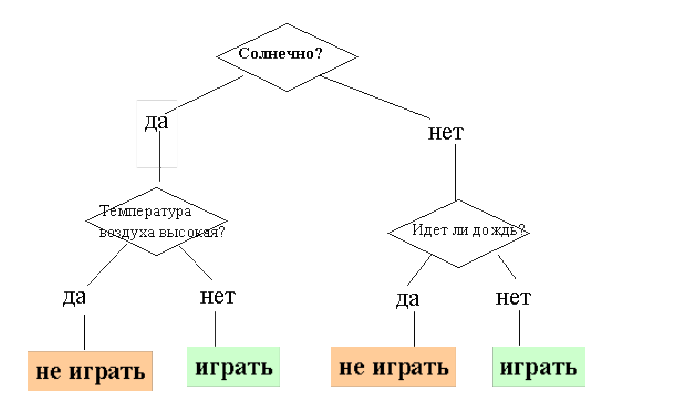
Преимущества метода:
-интуитивность деревьев решений;
-возможность извлекать правила из базы данных на естественном языке;
-не требует от пользователя выбора входных атрибутов;
-точность моделей;
-разработан ряд масштабируемых алгоритмов;
-быстрый процесс обучения;
-обработка пропущенных значений;
-работа и с числовыми, и с категориальными типам данных.
Процесс конструирования:
Основные этапы алгоритмов конструирования деревьев:
-построение или создание дерева (treebuilding);
-сокращение дерева (tree pruning).
Критерии расщепления:
-мера информационного выигрыша (informationgainmeasure)
-индекс Gini, т.е.gini(T), определяется по формуле:
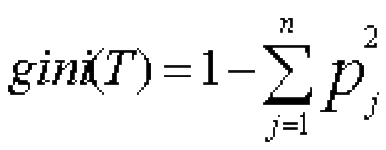
- Большое дерево не означает, что оно подходящее.
Остановка построения дерева.
Остановка – такой момент в процессе построения дерева, когда следует прекратить дальнейшие ветвления.
Варианты остановки:
-ранняя остановка;
-ограничение глубины дерева;
-задание минимального количества примеров.
Сокращение дерева или отсечение ветвей:
Критерии:
-точность распознавания
-ошибка.
Алгоритмы. CART.
-CART (Classification and Regression Tree)
-разработан в 1974-1984 годах четырьмя профессорами статистики
-CARTпредназначен для построения бинарного дерева решений.
Особенности:
-функция оценки качества разбиения;
-механизм отсечения дерева;
-алгоритм обработки пропущенных значений;
-построение деревьев регрессии.
Алгоритмы. С4.5
-строит дерево решений с неограниченным количество ветвей у узла.
-дискретные значения => только классификация
-каждая запись набора данных ассоциирована с одним из предопределенных классов => один из атрибутов набора данных должен являться меткой класса.
-количество классов должно быть значительно меньше количества записей в исследуемом наборе данных.
Перспективы и методы:
- разработка новых масштабируемых алгоритмов;
-метод деревьев – иерархическое, гибкое средство предсказания принадлежности объектов к определенному классу или прогнозирования значений числовых переменных.
-качество работы зависит как от выбора алгоритма, так и от набора исследуемых данных.
-чтобы построить качественную модель, необходимо понимать природу взаимосвязи между зависимыми и независимыми переменными и подготовить достаточный набор данных.
37. Метод «кластеризации».
Кластеризация – это автоматическое разбиение элементов некоторого множества на группы (кластеры) по принципу схожести.
Много практических применений в информатике и других областях:
-анализ данных (DataMining);
-группировка и распознавание объектов;
-извлечение и поиск информации.
Общая схема кластеризации:
1. выделение характеристик.
-выбор свойств, характеризующих объекты:
А) количественные характеристики (координаты, интервалы…);
Б) качественные характеристики (цвет, статус, воинское звание….).
- уменьшение размерности пространства, нормализация характеристик.
-представление объектов в виде характеристических векторов.
2. определение метрики.
-метрика выбирается в зависимости от:
А) пространства, где расположены объекты;
Б) неявных характеристик кластеров.
3. разбиение объектов на группы.
4. представление результатов.
Обычно используется один из следующих способов:
-представление кластеров центроидами;
-представление кластеров набором характерных точек;
--представление кластеров их ограничениями.
Общая схема кластеризации одна, но существуем много различных реализаций этой схемы.
Алгоритмы кластеризации:
-иерархические алгоритмы;
-минимальное покрывающее дерево;
-k-Meansалгоритм (алгоритмk-средних);
-метод ближайшего соседа;
-алгоритмы нечеткой кластеризации;
-применение нейронных сетей;
-генетические алгоритмы;
-метод закалки.
Какой алгоритм выбрать?
-генетические алгоритмы и искусственные нейронные сети хорошо распараллеливаются.
-генетические алгоритмы и метод закалки осуществляют глобальный поиск, но метод закалки сходится очень медленно.
-генетические алгоритмы хорошо работают только для одно- (двух-) мерных объектов, зато не требуется непрерывность координат.
-k-meansбыстро работает и прост в реализации, но создает только кластеры, похожие на гиперсферы.
-иерархические алгоритмы дают оптимальное разбиение на кластеры, но их трудоемкость квадратична.
-на практике лучше всего зарекомендовали себя гибридные походы, где шлифовка кластеров выполняется методом k-Means, а первоначальное разбиение – одним из более сильных методов.