

Базы данных |
БГУИР, ПОИТ |
|
|
3.3. Нормализация и нормальные формы
3.3.1. Определение
Нормализация (normalization) – группировка и/или распределение атрибутов по отношениям с целью устранения аномалий операций с БД, обеспечения целостности данных и оптимизации модели БД.
3.3.2. Требования нормализации
Как правило, не существует «единственно правильного способа нормализации» для достаточно сложной БД – у всех решений есть плюсы и минусы. Но желательно придерживаться следующих требований.
Эти требования могут противоречить друг другу, так что не стремитесь выполнить их все любой ценой. Выбирайте то, что важно для вашей конкретной БД!
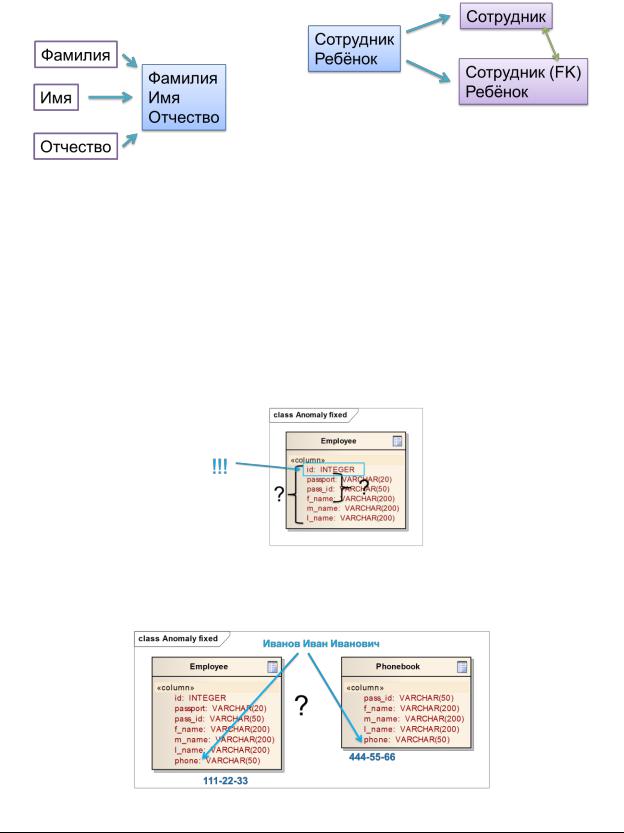
Требование минимальности первичных ключей
Первичные ключи отношений должны быть минимальными. Это требование идеально выполняется с введением суррогатных PK.
Требование надёжности данных
Модель БД должна по возможности минимизировать или устранять избыточность данных.
Стр: 53/248
Базы данных |
БГУИР, ПОИТ |
|
|
Требование производительности системы
Модель БД должна позволять обеспечивать необходимую производительность операций.
Хммм… Возможно, такая схема, и обеспечивает необходимую производительность, но… есть сомнения.
Требование сохранения производительности
Разброс времени реакции на различные операции с данными должен быть минимальным.
Это требование выполняют крайне редко, т.к. очень часто наблюдается явный «перевес» в сторону каких-то операций при реальном использовании БД.
Требование непротиворечивости данных
Модель БД должна минимизировать вероятность возникновения противоречивости данных при любых операциях с данными.
Иными словами – связи должны быть установлены ЯВНО!
Стр: 54/248
Базы данных |
БГУИР, ПОИТ |
|
|
Требование гибкости структуры
Модель БД должна быть способной к адаптации в случае необходимости внесения изменений.
Это достигается за счёт:
Мнемоничных имён. |
«abc» – плохо, «user_id» – хорошо |
Комментариев. |
К полям, таблицам, связям, в хра- |
|
нимых подпрограммах и т.д. |
Документации. |
Сначала её не пишут, а потом |
|
проклинают тех, кто в своё время |
|
не написал . |
Схемы в общепринятой нотации. |
Хорошо подходит UML или IDEF0. |
Отсутствия глупых ограничений. |
… вроде ID пользователя размером |
|
в 1 байт. И при этом ещё нет до- |
|
кументации – вообще жуть по- |
|
лучается. |
Требование актуальности данных
В каждый момент времени БД должна содержать актуальный набор данных.
Стр: 55/248

Базы данных |
БГУИР, ПОИТ |
|
|
3.3.3. Нормальные формы низких порядков
Нормальная форма (НФ, normal form) – ограничение схемы БД, вводимое с целью устранения определённых нежелательных свойств при выполнении реляционных операций.
Первая нормальная форма (1НФ)
Отношение находится в 1НФ, если все его атрибуты являются атомарными, т.е. не имеют компонентов.
Атрибут будет считаться атомарным, если в предметной области не существует операции, для выполнения которой понадобилось бы извлечь часть атрибута.
На рисунке слева представлена схема ненормализованного (до 1НФ) отношения, справа – нормализованного.
Внимание! Атомарность должна соблюдаться на уровне БД, т.е. с помощью БД не должно выполняться никаких операций над частью поля.
Поэтому, например, хранение в поле сериализованных данных, которые всегда добавляются, обновляются, удаляются и извлекаются ЦЕЛИКОМ, хоть и не является признаком хорошего тона, но имеет право на существование.
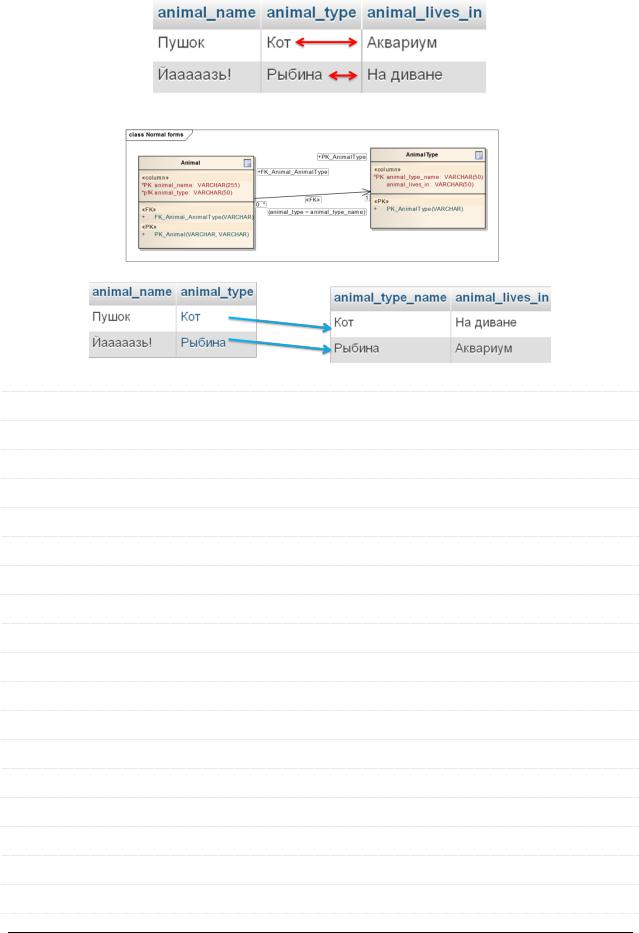
Вторая нормальная форма (2НФ)
Отношение находится во 2НФ, если оно находится в 1НФ, и при этом любой атрибут, не входящий в состав ПК, функционально полно зависит от ПК.
Представим, что у нас есть следующее отношение:
lives_in зависит только от type, а не от {name, type}
Стр: 56/248
Базы данных |
БГУИР, ПОИТ |
|
|
В силу человеческой или программной ошибки очень легко получить вот такой бред:
Если мы исправим модель БД (приведём ко 2НФ), всё будет хорошо:
Стр: 57/248
Базы данных |
БГУИР, ПОИТ |
|
|
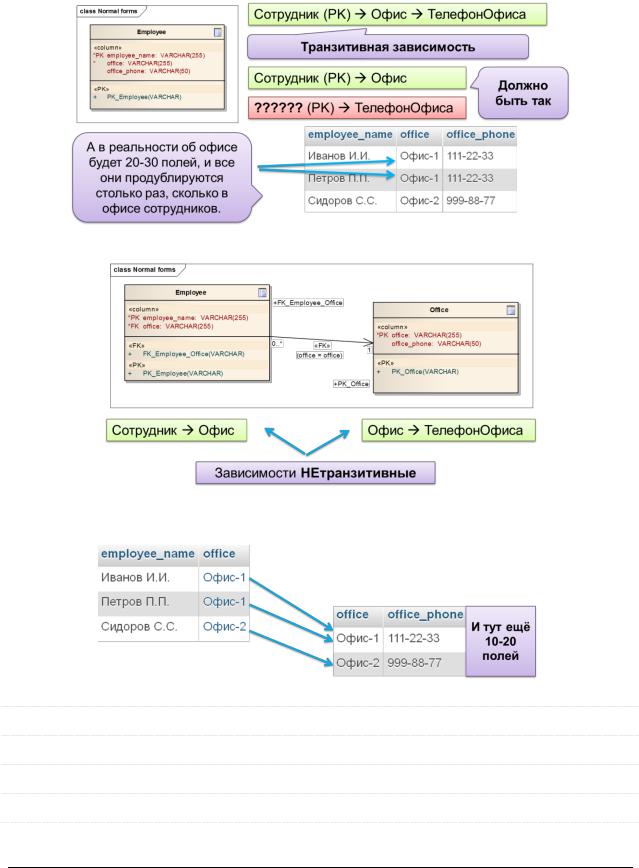
Третья нормальная форма (3НФ)
Отношение находится в 3НФ, если оно находится во 2НФ и при этом любой его неключевой атрибут нетранзитивно (напрямую) зависит от первичного ключа.
На практике нарушение 3НФ проще всего отследить ещё и по бессмысленному дублированию данных в разных строках.
Приведём отношение к 3НФ:
С бессмысленным дублированием данных об офисе (напомним – могут быть десятки столбцов) теперь тоже всё хорошо – дублирования нет:
Стр: 58/248