

Базы данных |
БГУИР, ПОИТ |
|
|
6.1.13.SELECT: [HAVING where_condition]
Указание простого или составного условия выборки, параметры которого не
могут быть вычислены на момент применения условия. Фактически – фильтр, налагаемый на результаты запроса после его выполнения. НЕ опти-
мизируется!
В руководстве сказано…
По стандарту SQL HAVING должен ссылаться только на поля, указанные в GROUP BY или в агрегатных функциях. Но MySQL позволяет HAVING ссылаться на поля, перечисленные в SELECT и подзапросах.
В случае, если возникает ситуация, когда MySQL не может определить, идёт ли речь о поле из SELECT или из GROUP BY, HAVING работает с полем из GROUP BY.
В связи с данной цитатой из руководства приведём пример того, как писать запросы НЕ НАДО (это работает, но такие запросы тяжело сопровождать):
SELECT COUNT(`f1`) AS `f2` FROM `t` GROUP BY `f2` HAVING `f2` = 2;
|
|
Не пишите так!!! |
||
Когда надо применять HAVING? Вспомним пример «показ плательщика, |
||||
СУММА платежей которого больше некоторого числа». |
|
|
||
|
|
|
|
|
Исходная таблица |
|
Запрос |
|
Результат |
|
|
|
|
Ошибка. Запрос |
|
|
SELECT `name`, SUM(`money`) AS `s` |
||
|
|
FROM `payment_archive` GROUP BY |
|
не выполнен. |
|
|
`name` WHERE `s`>100 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SELECT `name`, SUM(`money`) AS `s` |
|
|
|
|
FROM `payment_archive` GROUP BY |
|
|
|
|
`name` HAVING `s`>100 |
|
|
|
|
|
|
|
Стр: 161/248
Базы данных |
БГУИР, ПОИТ |
|
|
6.1.14.SELECT: [ORDER BY …]
Указание имени или номера поля (полей) или выражения, по которым надо отсортировать результаты выборки.
В руководстве сказано…
Если результаты запроса и подзапросов отсортированы по одному и тому же полю в разных направлениях, приоритет имеет сортировка внешнего запроса.
Таким образом, следующий запрос приведёт к сортировке в направлении
DESC.
(SELECT ... ORDER BY `f1` ASC) ORDER BY `f1` DESC
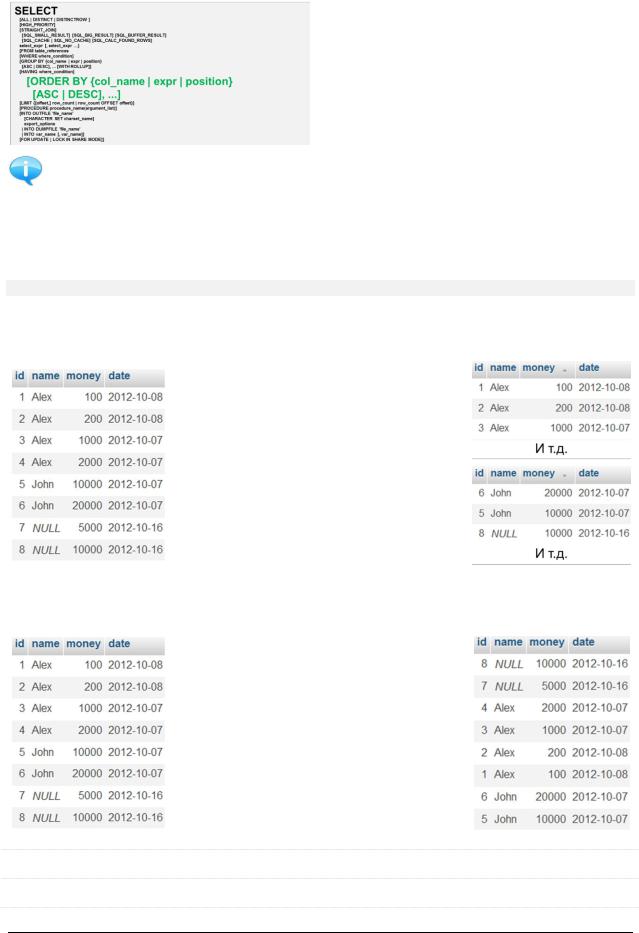
1) Сортировка по одному полю
Исходная таблица |
|
Запрос |
|
Результат |
|
|
По возрастанию (значение по умол- |
|
|
|
|
чанию): |
|
|
|
|
SELECT * FROM `payment_with_date` |
|
|
|
|
ORDER BY `money` ASC |
|
|
|
|
|
|
|
|
|
По убыванию: |
|
|
|
|
SELECT * FROM `payment_with_date` |
|
|
|
|
ORDER BY `money` DESC |
|
|
|
|
|
|
|
2) Сортировка по нескольким полям в разных направлениях |
|
|
||
|
|
|
|
|
Исходная таблица |
|
Запрос |
|
Результат |
|
|
|
|
|
|
|
SELECT * FROM `payment_with_date` |
|
|
|
|
ORDER BY `name` ASC, `money` DESC |
|
|
|
|
|
|
|
Стр: 162/248
Базы данных |
БГУИР, ПОИТ |
|
|
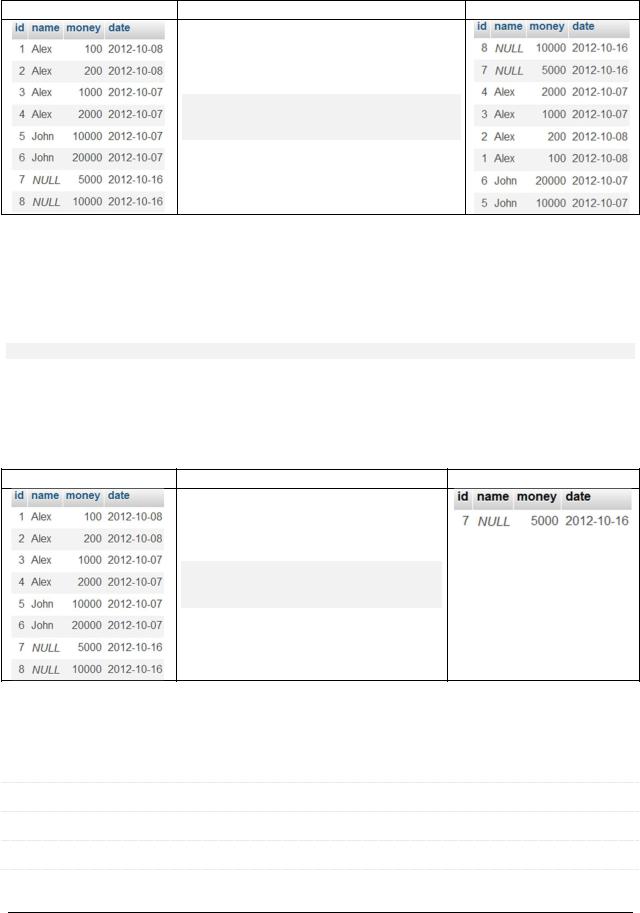
3) Сортировка по выражению
Отсортируем платежи по дню их выполнения (год и месяц не учитывается):
Исходная таблица |
Запрос |
Результат |
SELECT * FROM `payment_with_date`
ORDER BY EXTRACT(DAY FROM `date`)
DESC
ВНИМАНИЕ! Помните, что сортировка по выражению может очень сильно снизить производительность, т.к. MySQL (пока?) не умеет строить индексы на выражениях.
4) Сортировка по номеру поля
SELECT * FROM `payment_with_date` ORDER BY 3 DESC
Несмотря на то, что это работает – НЕ ДЕЛАЙТЕ ТАК! Сортировка по номерам полей «слетит», как только изменится порядок и/или количество полей в таблице.
5) Выбор случайной записи из таблицы
Исходная таблица |
Запрос |
Результат |
SELECT * FROM `payment_with_date` ORDER BY RAND() LIMIT 1
Такое решение может привести к проблемам с производительностью на больших объёмах данных.
О том, как выбрать из таблицы некоторое количество случайных уникаль-
ных записей, читайте здесь: http://svyatoslav.biz/engines/random_records/.
Стр: 163/248
Базы данных |
БГУИР, ПОИТ |
|
|
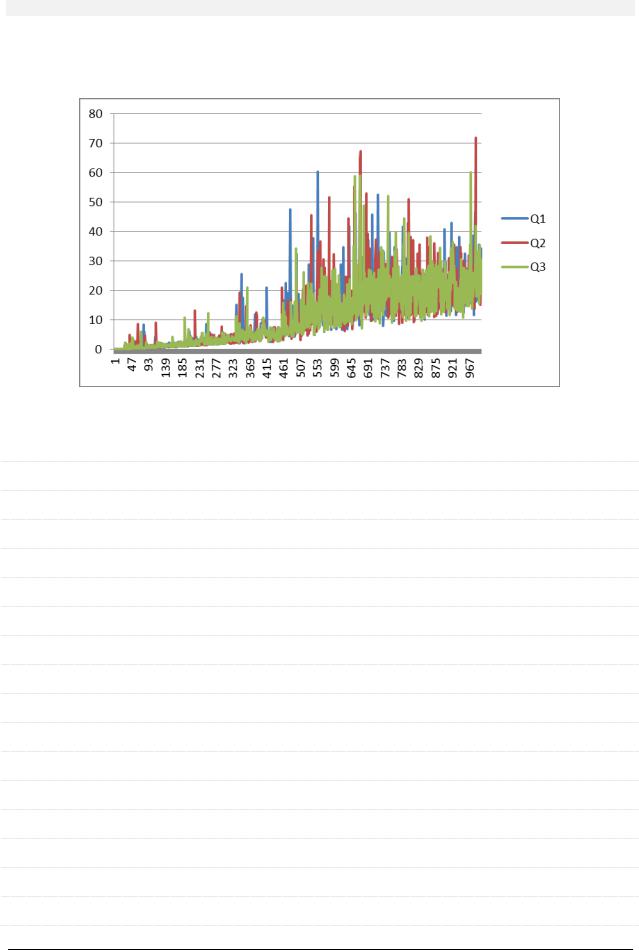
Проверим, как быстро работает такой запрос:
SELECT * FROM `payment_with_date` ORDER BY RAND() LIMIT 1
Будем добавлять в таблицу (ту же, что и при тестировании производительности GROUP BY) по тысяче записей и трижды выполнять запрос на выборку случайной записи (время указано в секундах).
Итак, с увеличением количества записей скорость работы запроса ощутимо падает.
Стр: 164/248