


Базы данных |
БГУИР, ПОИТ |
|
|
4.4. Проектирование БД на физическом уровне
Вспомним определение физического уровня моделирования.
На данном уровне необходимо продумать и реализовать следующие параметры БД.
Права доступа
Права доступа управляются непосредственно самой СУБД, но к проектируемой модели БД можно приложить готовые скрипты по созданию пользователей и передаче им соответствующих прав на те или иные объекты БД.
Задание для самоподготовки: продумать вопрос распределения прав, написать соответствующие скрипты.
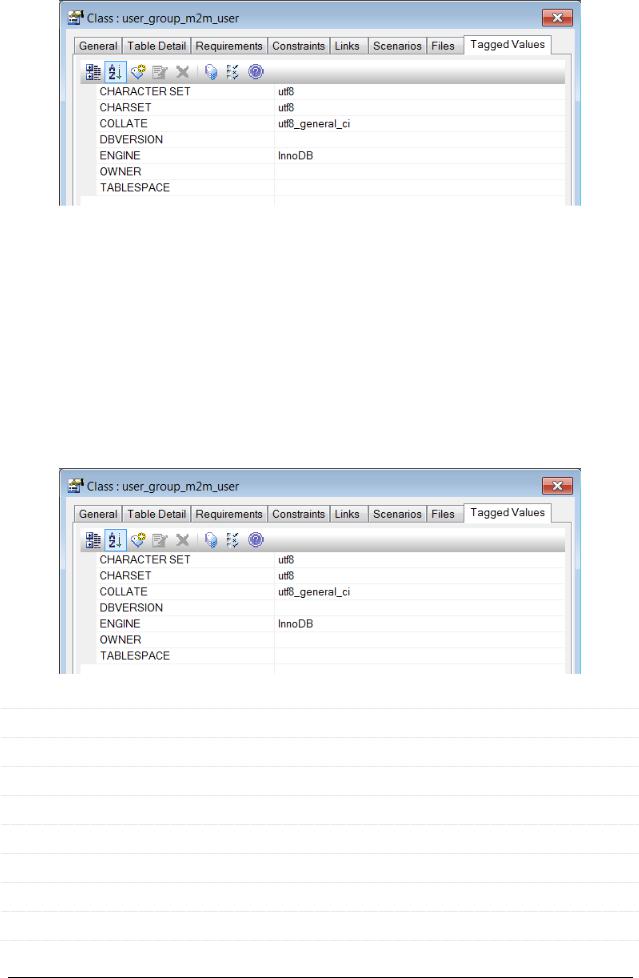
Кодировки (в т.ч. по умолчанию)
Хороший скрипт создания БД должен управлять кодировками явно, но если это невозможно или затруднительно по той или иной причине, можно перенести управление кодировками на прилагаемые к модели БД дополнительные скрипты или указать соответствующие пункты в инструкции по настройке MySQL.
Поскольку мы используем Sparx EA, мы можем указать кодировки через свойство Tagged Values таблицы (создав свои дополнительные значения, см. подробнее здесь).
Стр: 96/248
Базы данных |
БГУИР, ПОИТ |
|
|
В процессе указания кодировок выяснилось, что даже MySQL 5.5.x не может использовать первичные ключи в UTF8 длиннее 180-200 символов (в пересчёте на байты получается превышение максимального размера индекса), что привело к необходимости исправления модели: в некотором случае длина текстовых первичных ключей была уменьшена до 180 символов (вместо 255), в некоторых случаях был изменён тип данных (BINARY вместо VARCHAR, т.к. BINARY – это «просто байты, без кодировки»).
Методы доступа и параметры хранения файлов таблиц
Многие универсальные средства проектирования не позволяют проводить столь тонкую настройку СУБД (и тогда придётся решать этот вопрос дополнительными скриптами или инструкцией по настройке СУБД), но в Sparx EA это делается, опять же, через Tagged Values таблицы см. подробнее здесь).
Стр: 97/248
Базы данных |
БГУИР, ПОИТ |
|
|
Индексы
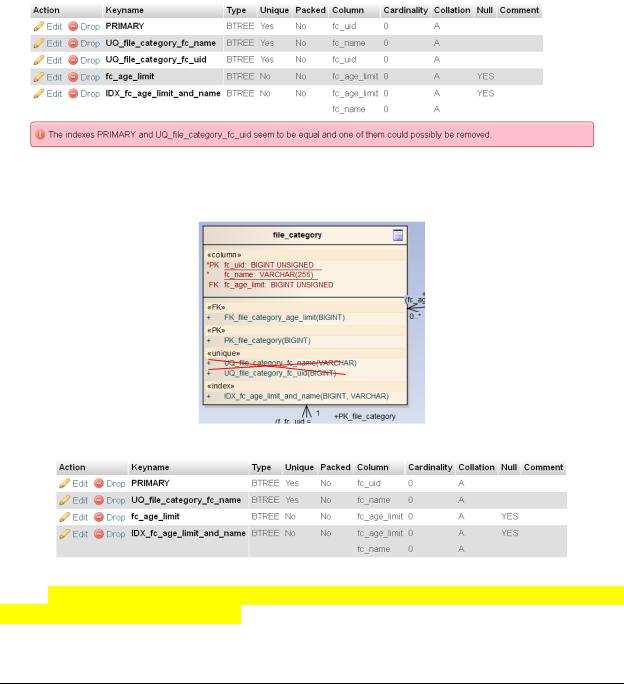
Поскольку индексы (за исключением первичных ключей и ограничений уникальности) не влияют на логику работы БД, создание индексов лучше отложить до момента наполнения БД тестовыми данными и проведения нагрузочного тестирования. Однако, самые очевидные индексы можно создать уже сейчас, тем более, что Sparx EA позволяет это сделать.
Будьте внимательны: в некоторых случаях создание индекса в Sparx EA приводит с «сбрасыванию» сведений о внешних ключах в связях. Если это произошло (при импорте модели в БД вы получаете ошибку № 150), просто выполните заново операцию установки внешних ключей между таблицами, при создании которых возникала ошибка № 150.
Ещё одно замечание по индексам: Sparx EA часто генерирует ОТДЕЛЬНО команды по созданию первичных ключей и уникальных индексов на тех же полях, которые входят в состав первичных ключей. Это легко заметить по сообщениям, например, phpMyAdmin:
В таком случае имеет смысл удалить в модели БД операцию, отвечающую за уникальность первичного ключа (СУБД и так понимает, что он должен быть уникальным).
И теперь всё хорошо:
Задание для самоподготовки: продумать, создать и прокомментировать индексы для остальных таблиц.
Стр: 98/248

Базы данных |
БГУИР, ПОИТ |
|
|
Настройки СУБД
Пожалуй, это самые сложные параметры для настройки через внешние средства проектирования. Если для корректной и эффективной работы БД необходимо настроить СУБД некоторым особенным образом, необходимо исследовать возможности СУБД по управлению такими настройками через SQL и написать соответствующие скрипты, однако часть настроек, вероятно, придётся корректировать средствами администрирования СУБД.
В любом случае – эти настройки должны быть подробно задокументирова-
ны.
Задание для самоподготовки: продумать и описать, какие настройки MySQL 5.5.x могут повлиять на показатели качества проектируемой БД, и какие их значения необходимо выставить для достижения наилучшей работоспособности БД.
Итог
Итак, процесс проектирования завершён. После того, как вы выполните задания и доведёте построение модели до логического завершения, останется её только протестировать.
Стр: 99/248