


Базы данных |
БГУИР, ПОИТ |
|
|
6.12. Оператор CALL
6.12.1.Общая структура оператора CALL
Оператор CALL предназначен для вызова хранимых процедур. И всё . Подробно рассматривать его будет в соответствующем разделе.
6.12.2. Пример хранимой процедуры и использования оператора
CALL
А пока, чтобы составить общее представление, рассмотрим один пример. Допустим, нам (по какой-то очень веской причине) нужно определить, у
скольких записей первичный ключ лежит в заданном диапазоне, при этом нам известно только:
Записи лежат в разных таблицах. Имена всех интересующих нас таблиц начинаются с “ctg”.
У каждой таблицы первичный ключ простой (состоит из одного поля), но его имя везде разное.
ВАЖНО! Если в реальной жизни у вас возникают подобные задачи, значит вы что-то очень и очень сильно проморгали на стадии разработки структуры базы данных
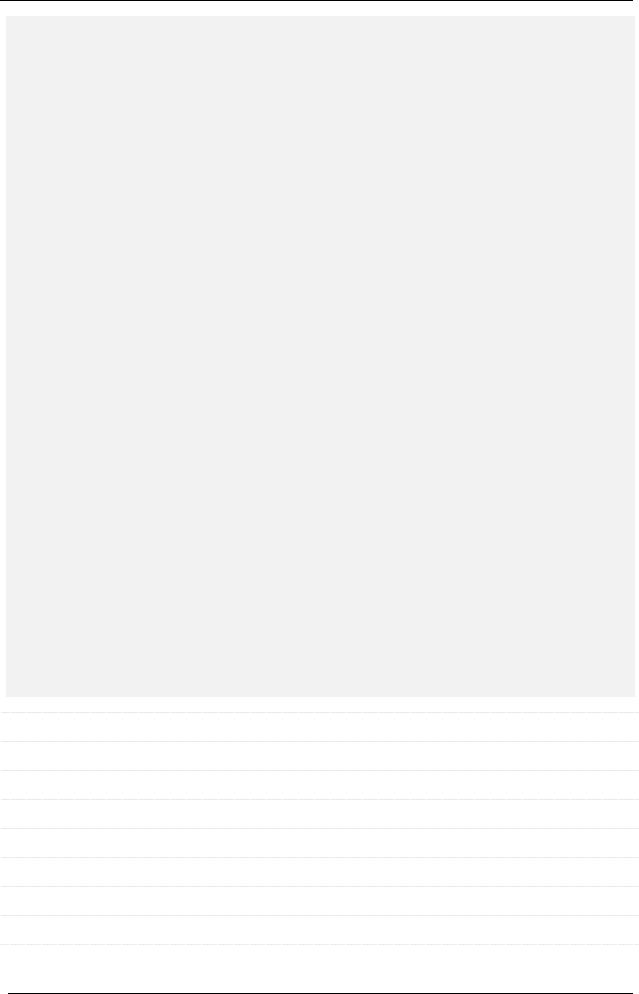
Итак, вот текст хранимой процедуры.
DROP PROCEDURE IF EXISTS RecordsCount;
delimiter //
CREATE PROCEDURE RecordsCount(IN PKmin INT, IN PKmax INT, OUT ResultCount INT)
BEGIN
--Признак того, что в цикле перебора результатов запроса закончились ряды.
DECLARE no_more_rows BOOLEAN DEFAULT FALSE;
--Переменная для хранения имени i-й перебираемое таблицы.
DECLARE table_name CHAR(255) DEFAULT '';
--Счётчик количества найденных удовлетворяющих условию записей.
DECLARE records_count INT DEFAULT 0;
--Создём курсор для запроса, который вернёт список таблиц,
--имена которых соответствуют шаблону. DECLARE tables_cursor CURSOR FOR
SELECT `information_schema`.`tables`.`TABLE_NAME`
FROM `information_schema`.`tables`
WHERE `information_schema`.`tables`.`TABLE_SCHEMA`='shop'
AND `information_schema`.`tables`.`TABLE_NAME` LIKE 'ctg\_%';
--Создаём обработчик ситуации "(больше) записей нет".
DECLARE CONTINUE HANDLER FOR NOT FOUND SET no_more_rows = TRUE;
--Открываем курсор (т.е. выполняем запрос).
OPEN tables_cursor;
--Сбрасываем счётчик.
SET records_count = 0;
Стр: 244/248
Базы данных БГУИР, ПОИТ
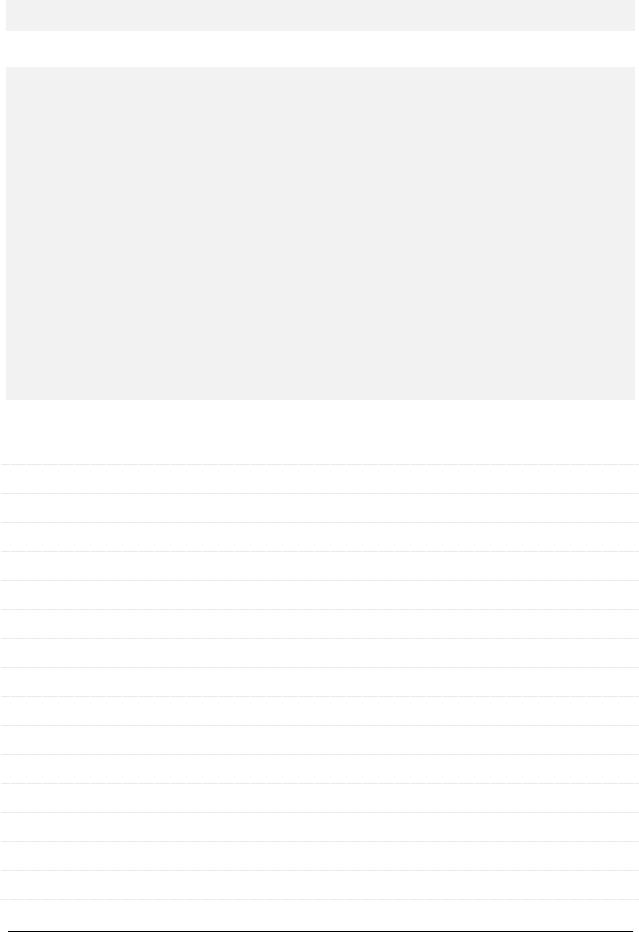
-- Цикл перебора всех найденных таблиц. the_loop: LOOP
-- Извлекаем имя таблицы.
FETCH tables_cursor INTO table_name;
-- Формируем запрос, который вернёт имя первичного ключа таблицы.
SET @query = CONCAT("SELECT `information_schema`.`COLUMNS`.`COLUMN_NAME` INTO @tpk FROM `information_schema`.`COLUMNS`
WHERE `information_schema`.`COLUMNS`.`TABLE_NAME` ='", table_name, "' AND `information_schema`.`COLUMNS`.`COLUMN_KEY` = 'PRI'");
--Формируем выполнимое выражение.
PREPARE real_query FROM @query;
--Выполняем запрос. Теперь в переменной @tpk лежит имя PK таблицы.
EXECUTE real_query;
--Формируем запрос, считающий количество записей, удовлетворяющих условию задачи
SET @query = CONCAT("SELECT COUNT(*) INTO @part FROM ", table_name, " WHERE `",
@tpk, "` >= ", PKmin, " AND `", @tpk, "` <= ", PKmax);
--Формируем выполнимое выражение.
PREPARE real_query FROM @query;
--Выполняем запрос. Теперь в переменной @part лежит
--количество записей данной таблицы, удовлетворяющих условию задачи.
EXECUTE real_query;
--Если мы перебрали все таблицы, чьи имена соответствуют шаблону,
--выходим из цикла.
IF no_more_rows THEN
CLOSE tables_cursor;
LEAVE the_loop;
ELSE
--Накапливаем сумму количества записей по всем таблицам.
SET records_count = records_count + @part;
--Это просто отладочный вывод.
SELECT records_count;
END IF;
END LOOP the_loop;
SET ResultCount = records_count;
END
//
delimiter ;
Стр: 245/248
Базы данных |
БГУИР, ПОИТ |
|
|
На уже известной нам базе данных интернет-магазина (см. ранее, был дан её дамп) выполним нашу процедуру.
CALL RecordsCount(1, 999, @a);
SELECT @a;
Результат работы:
+--------------- |
|
+ |
| records_count | |
||
+--------------- |
|
+ |
| |
2 |
| |
+--------------- |
|
+ |
1 |
row in set (0.09 sec) |
|
+--------------- |
|
+ |
| records_count | |
||
+--------------- |
|
+ |
| |
5 | |
|
+--------------- |
|
+ |
1 |
row in set (0.12 sec) |
|
Query OK, 1 row affected (0.12 sec)
+------ |
|
+ |
| @a |
| |
|
+------ |
|
+ |
| |
|
5 | |
+------ |
|
+ |
1 |
row in set (0.00 sec) |
|
При попытке вызвать процедуру из PhpMyAdmin, MySQL подвисает. Чтобы не подвисал, нужно убрать отладочный вывод внутри процедуры.
Стр: 246/248