

Базы данных |
БГУИР, ПОИТ |
|
|
6.5.4. Подзапросы, возвращающие ряды
Подзапросы, возвращающие ряды, позволяют выполнять сравнение сразу по нескольким полям.
Это эквивалентно выражению вида:
`field1a`=`field1b` AND `field2a`=`field2b`
Некоторые дополнительные подробности – здесь: http://dev.mysql.com/doc/refman/5.5/en/row-subqueries.html
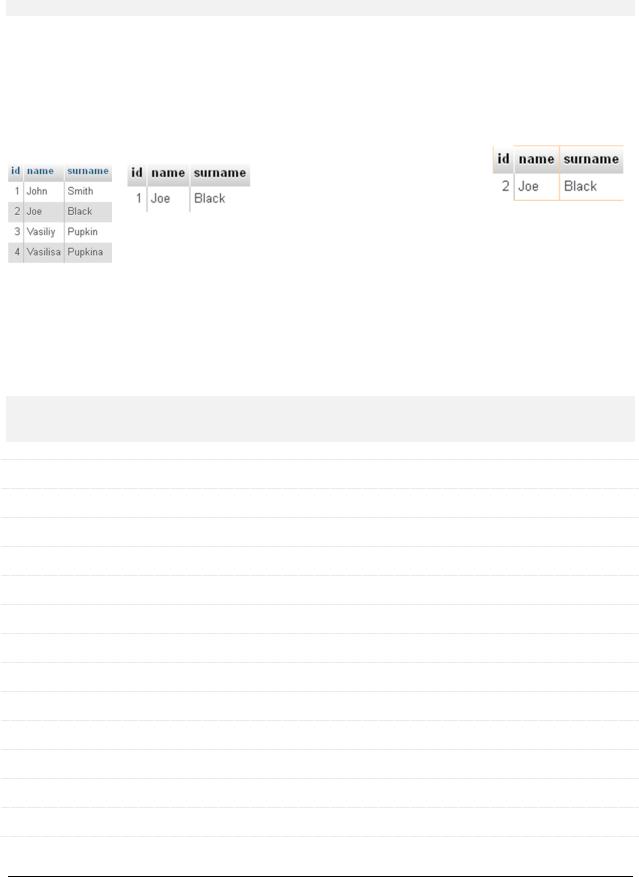
Пример 1: показать всех соискателей, находящихся в списке рекомендованных.
Исходные таблицы |
|
Запрос |
|
Результат |
|
`candidates` |
`recommended` |
|
SELECT * FROM |
|
|
|
|
|
`candidates` WHERE |
|
|
|
|
|
(`name`, `surname`) = |
|
|
|
|
|
(SELECT `name`, `surname` |
|
|
|
|
|
FROM `recommended`) |
|
|
|
|
|
|
|
|
Пример 2 (редкий случай, но пример интересный): показать все строки первой таблицы, которые по данному набору полей совпадают со строками другой таблицы. Пример таблиц и результатов не приводим в силу их самоочевидности.
SELECT `col1`, `col2`, `col3` FROM `FirstTable` WHERE (`col1`, `col2`, `col3`) IN
(SELECT `col1`, `col2`, `col3` FROM `SecondTable`)
Стр: 214/248
Базы данных |
БГУИР, ПОИТ |
|
|
6.5.5. Подзапросы с ключевым словом [NOT] EXISTS
Такие подзапросы используются для различения всего лишь двух вариан-
тов:
подзапрос вернул пустой (EXISTS == false) результат или
подзапрос вернул непустой (EXISTS == true) результат..
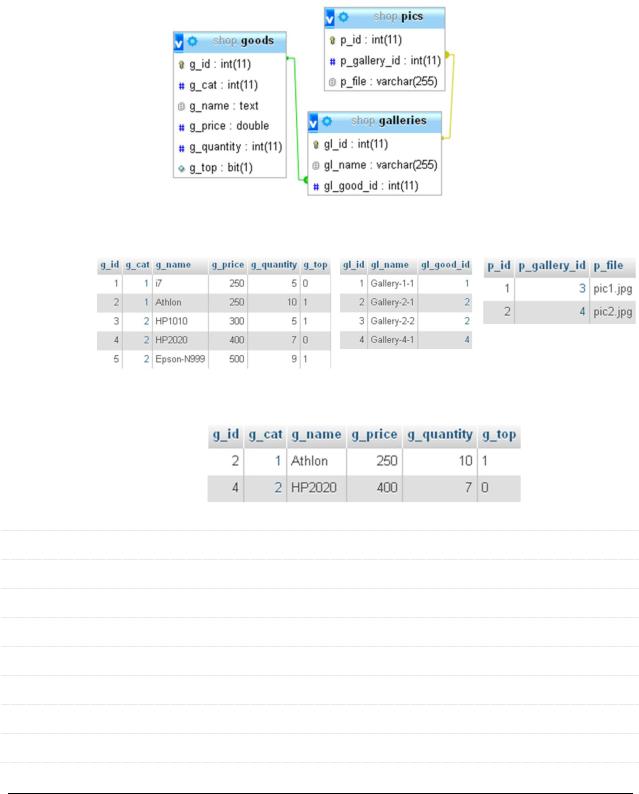
Рассмотрим на простом примере. Пусть фрагмент базы данных интернетмагазина имеет следующий вид:
Необходимо показать все товары, в галереях которых есть картинки.
Исход- |
|
`goods` |
`galleries` |
`pics` |
|
ные таб- |
|
|
|
|
|
лицы |
|
|
|
|
|
|
|
|
|
|
|
Запрос |
|
SELECT * FROM `goods` where EXISTS |
|
|
|
|
|
(SELECT `galleries`.`gl_good_id` FROM `galleries` JOIN `pics` |
|
||
|
|
ON `gl_id`=`p_gallery_id` HAVING `galleries`.`gl_good_id`=`g_id`) |
|
||
Резуль- |
|
|
|
|
|
тат |
|
|
|
|
|
|
|
|
|
|
|
Стр: 215/248

Базы данных |
БГУИР, ПОИТ |
|
|
6.5.6. Взаимосвязанные запросы и подзапросы
Запрос и подзапрос считаются взаимосвязанными, если подзапрос обращается к таблице (или таблицам), которая используется во внешнем запросе.
Иллюстрацию такой ситуации мы только что рассматривали в примере про показ товаров, в галереях которых есть картинки.
SELECT * FROM `goods` where EXISTS
(SELECT `galleries`.`gl_good_id` FROM `galleries` JOIN `pics` ON `galleries`.`gl_id`=`pics`.`p_gallery_id`
HAVING `galleries`.`gl_good_id`= `goods`.`g_id`)
6.5.7. Подзапросы как источник данных
В некоторых случаях необходимый результат нельзя получить «за один раз», т.е. необходимо подготовить промежуточный результат, а уже на его основе
– конечный. В таких случаях промежуточный результат обычно генерируется подзапросами.
Рассмотрим пример. Необходимо выяснить «среднюю стоимость категорий товаров» (где «стоимость категории» определяется как сумма стоимости всех её товаров). Схема базы данных имеет вид:
|
Исходные таблицы |
`goods` |
`categories` |
Стр: 216/248
Базы данных БГУИР, ПОИТ
|
Запрос |
|
Результат |
|
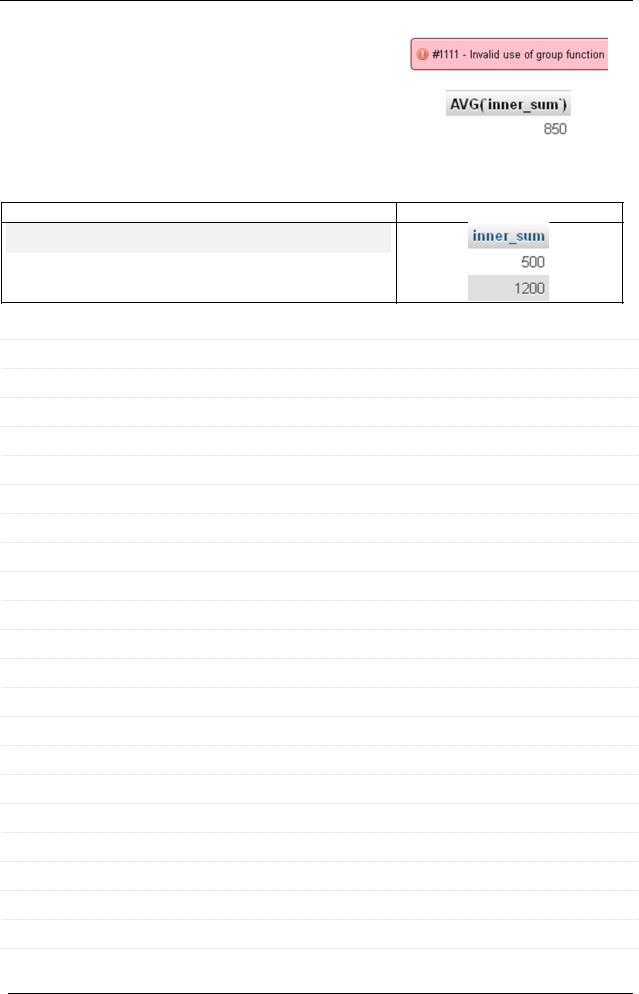
SELECT AVG(SUM(`g_price`)) FROM `goods` |
|
|
|
GROUP BY `g_cat` |
|
|
|
|
|
|
|
SELECT AVG(`inner_sum`) FROM |
|
|
|
(SELECT SUM(`g_price`) AS `inner_sum` FROM |
|
|
|
`goods` GROUP BY `g_cat`) AS `inner_result` |
|
|
|
|
|
|
Для наглядности посмотрим, что возвращает подзапрос:
Подзапрос |
Результат |
SELECT SUM(`g_price`) AS `inner_sum` FROM
`goods` GROUP BY `g_cat`
Стр: 217/248