

Базы данных |
БГУИР, ПОИТ |
|
|
6.2. «Подсказки» по индексам
6.2.1. Обзор структуры и краткие пояснения
Оптимизатор запросов всегда пытается найти лучший (самый быстрый и не затратный по расходу памяти) способ выполнения запроса.
В сложных случаях оптимизатор может ошибаться и выбирать плохой (не устраивающий нас) вариант.
Мы можем подсказать оптимизатору, какие индексы использовать, а какие –
нет.
Итак, вся структура «подсказок» по индексам выглядит следующим обра-
зом:
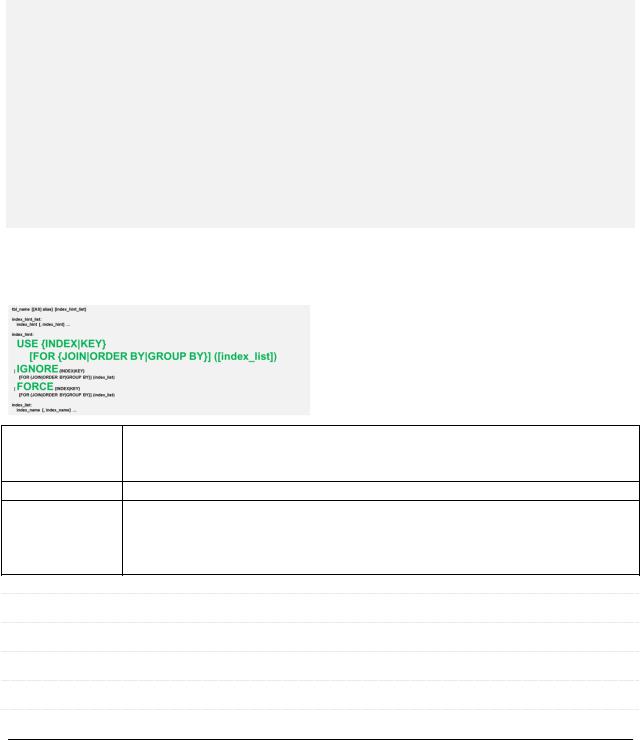
tbl_name [[AS] alias] [index_hint_list]
index_hint_list:
index_hint [, index_hint] ...
index_hint:
USE {INDEX|KEY}
[FOR {JOIN|ORDER BY|GROUP BY}] ([index_list]) | IGNORE {INDEX|KEY}
[FOR {JOIN|ORDER BY|GROUP BY}] (index_list) | FORCE {INDEX|KEY}
[FOR {JOIN|ORDER BY|GROUP BY}] (index_list)
index_list:
index_name [, index_name] ...
6.2.2. index_hint: USE | IGNORE | FORCE
Поскольку общий синтаксис работы с таблицами мы рассмотрели в разделе, посвящённом SELECT, здесь мы сконцентрируется на ключевых словах
USE, IGNORE, FORCE и указании обла-
сти действия «подсказки» (FOR …).
USE Использовать только перечисленные индексы. Можно указать пустой список, что эквивалентно IGNORE с перечислением всех индексов.
IGNORE НЕ использовать перечисленные индексы.
FORCE Указание того факта, что полный просмотр таблицы разрешается использовать ТОЛЬКО в случае, если ни один из указанных индексов не может быть использован для поиска требуемых записей.
Стр: 175/248

Базы данных |
БГУИР, ПОИТ |
|
|
Q: Как узнать, какие у таблицы есть индексы?
A: SHOW INDEX FROM `tablename`
SHOW INDEX FROM `computers`
Q: Как узнать, какие индексы и для чего используются при выполнении запроса? A: EXPLAIN ваш_запрос
EXPLAIN SELECT * FROM `computers` WHERE `c_id`=1
Q: Как в списке индексов указать первичный ключ таблицы?
A: PRIMARY
EXPLAIN SELECT * FROM `computers` IGNORE INDEX (PRIMARY)
WHERE `c_id`=1
Стр: 176/248

Базы данных |
БГУИР, ПОИТ |
|
|
6.2.3. index_hint: [FOR {JOIN|ORDER BY|GROUP BY}]
|
Поскольку общий синтаксис работы с |
|
таблицами мы рассмотрели в разделе, |
|
посвящённом SELECT, здесь мы скон- |
|
центрируется на ключевых словах USE, |
|
IGNORE, FORCE и указании области |
|
действия «подсказки» (FOR …). |
|
|
JOIN |
«Подсказка» относится к JOIN-части запроса. |
ORDER BY |
«Подсказка» относится к ORDER BY части запроса. |
GROUP BY |
«Подсказка» относится к GROUP BY части запроса. |
Таким образом мы можем более тонко управлять поведением оптимизатора относительно отдельных частей запроса.
Создадим таблицу:
CREATE TABLE `idxtbl`
(`id` int(11) NOT NULL AUTO_INCREMENT, `status` enum('0','1') NOT NULL, `name` varchar(100) NOT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1
DEFAULT CHARSET=utf8
Добавим в неё 10+ миллионов записей и создадим индексы:
CREATE INDEX `idx1` ON `idxtbl` (`status`, `name`)
CREATE INDEX `idx2` ON `idxtbl` (`name`)
Проверим, как будут выполняться запросы:
EXPLAIN SELECT * FROM `idxtbl` WHERE `status` = '1'
EXPLAIN SELECT * FROM `idxtbl` IGNORE INDEX (`idx1`) WHERE `status`='1'
EXPLAIN SELECT * FROM `idxtbl` FORCE INDEX (`idx2`) WHERE `status`='1'
Стр: 177/248

Базы данных |
БГУИР, ПОИТ |
|
|
6.2.4.Краткие итоги
1.В общем случае оптимизатор достаточно хорошо «угадывает», какие индексы использовать.
2.Если оптимизатор сам решает не использовать индексы, его можно «заставить», но далеко не факт, что это даст эффект (как правило, прирост производительности оказывается в районе долей процентов).
3.Реальную пользу «подсказки» по индексам приносят в случае действительно сложных запросов, которые нужно многократно проверять через EXPLAIN и реальными тестами.
Стр: 178/248