

- •Предисловие
- •Тема 1: Основы баз данных
- •1.1. Данные и базы данных
- •1.2. Модели баз данных
- •1.2.1. Понятие модели базы данных
- •1.2.2. Инфологические модели
- •1.2.3. Даталогические модели
- •1.2.4. Физические модели
- •1.3. Виды баз данных
- •1.4. Реляционная модель данных
- •1.4.1. Определение
- •1.4.2. Основные факты о реляционной модели данных
- •1.4.3. Достоинства реляционной модели данных
- •1.4.4. Недостатки реляционной модели данных
- •1.4.5. Реляционные базы данных
- •1.5. Реляционные системы управления базами данных
- •1.6. История развития баз данных
- •Тема 2: Отношения, ключи, связи
- •2.1. Отношения
- •2.1.1. Определение
- •2.1.2. Отношения в реляционной теории и в реальности
- •2.2. Ключи
- •2.2.1. Определение
- •2.2.2. Виды ключей
- •2.3. Индексы
- •2.3.1. Определение
- •2.3.2. Виды индексов
- •2.3.3. Управление индексами в MySQL
- •2.4. Связи
- •2.4.1. Определение
- •2.4.2. Виды связей
- •2.4.3. Идентифицирующая и неидентифицирующая связи
- •2.5. Ссылочная целостность данных
- •2.5.1. Определение
- •2.5.2. Каскадные операции
- •2.5.3. Консистентность данных
- •2.6. Триггеры
- •Тема 3: Нормальные формы
- •3.1. Аномалии операций с БД
- •3.1.1. Важно помнить
- •3.1.2. Аномалии и их опасность
- •3.2. Теория зависимостей
- •3.2.1. Функциональная зависимость
- •3.2.2. Избыточная функциональная зависимость
- •3.2.3. Полная функциональная зависимость
- •3.2.4. Частичная функциональная зависимость
- •3.2.5. Транзитивная функциональная зависимость
- •3.2.6. Многозначная зависимость
- •3.2.7. Тривиальная и нетривиальная многозначная зависимость
- •3.3. Нормализация и нормальные формы
- •3.3.1. Определение
- •3.3.2. Требования нормализации
- •3.3.3. Нормальные формы низких порядков
- •3.3.4. Нормальные формы высоких порядков
- •3.3.5. Краткий справочник по нормальным формам
- •3.3.6. Пример применения нормализации
- •3.4. Денормализация
- •Тема 4: Проектирование баз данных
- •4.1. Оценка сложности БД
- •4.1.1. Быстрая оценка
- •4.1.2. Навыки, необходимые для успешного проектирования базы данных
- •4.2. Проектирование БД на инфологическом уровне
- •4.3. Проектирование БД на даталогическом уровне
- •4.4. Проектирование БД на физическом уровне
- •4.5. Основы использования Sparx EA
- •4.5.1. Создание модели и работа с инфологическим уровнем
- •4.5.2. Работа с даталогическим и физическим уровнем
- •4.5.3. Создание скрипта генерации БД
- •Тема 5: Основы языка SQL (на базе MySQL)
- •5.1. Общие сведения об SQL
- •5.2. Именование структур в MySQL
- •5.3. Типы данных в MySQL
- •5.4. Элементарное управление данными в MySQL
- •5.4.1. Выборка данных
- •5.4.2. Вставка данных
- •5.4.3. Удаление данных
- •5.5. Основы использования MySQL Workbench
- •5.6. Основы использования phpMyAdmin
- •Тема 6: Язык управления данными в MySQL
- •6.1. Оператор SELECT, общая структура
- •6.1.1. Обзор структуры и краткие пояснения
- •6.1.2. SELECT: [ALL | DISTINCT | DISTINCTROW ]
- •6.1.3. SELECT: [HIGH_PRIORITY]
- •6.1.4. SELECT: [STRAIGHT_JOIN]
- •6.1.5. SELECT: [SQL_SMALL_RESULT] [SQL_BIG_RESULT]
- •6.1.6. SELECT: [SQL_BUFFER_RESULT]
- •6.1.7. SELECT: [SQL_CACHE | SQL_NO_CACHE]
- •6.1.8. SELECT: [SQL_CALC_FOUND_ROWS]
- •6.1.9. SELECT: select_expr [, select_expr ...]
- •6.1.10. SELECT: FROM table_references
- •6.1.11. SELECT: [WHERE where_condition]
- •6.1.12. SELECT: [GROUP BY …]
- •6.1.13. SELECT: [HAVING where_condition]
- •6.1.14. SELECT: [ORDER BY …]
- •6.1.15. SELECT: [LIMIT …]
- •6.1.16. SELECT: [PROCEDURE procedure_name(argument_list)]
- •6.1.17. SELECT: [INTO OUTFILE …]
- •6.1.18. SELECT: [INTO DUMPFILE …]
- •6.1.19. SELECT: [INTO var_name [, var_name]]]
- •6.1.20. SELECT: [FOR UPDATE | LOCK IN SHARE MODE]]
- •6.2. «Подсказки» по индексам
- •6.2.1. Обзор структуры и краткие пояснения
- •6.2.2. index_hint: USE | IGNORE | FORCE
- •6.2.3. index_hint: [FOR {JOIN|ORDER BY|GROUP BY}]
- •6.2.4. Краткие итоги
- •6.3. Объединение запросов (UNION)
- •6.3.1. Обзор структуры и краткие пояснения
- •6.3.2. SELECT … UNION
- •6.3.3. Пример использования UNION
- •6.3.4. Краткие итоги
- •6.4. Запросы на объединение (JOIN)
- •6.4.1. Назначение и общая структура JOIN
- •6.4.2. Принципы работы JOIN
- •6.4.3. Три простых примера использования JOIN
- •6.4.4. Основные разновидности JOIN
- •6.4.5. ВСЕ разновидности JOIN
- •6.4.6. Условия объединения и дополнительные условия
- •6.4.7. Все виды JOIN в примерах
- •6.4.8. JOIN’ы и NULL’ы
- •6.4.9. JOIN’ы и дублирование имён полей
- •6.4.10. Нетривиальные случаи, вопросы и примеры
- •6.5. Подзапросы (SUBQUERIES)
- •6.5.1. Общие сведения о подзапросах
- •6.5.2. Скалярные подзапросы и сравнение с использованием подзапросов
- •6.5.3. Подзапросы с ключевыми словами ANY, IN, SOME, ALL
- •6.5.4. Подзапросы, возвращающие ряды
- •6.5.5. Подзапросы с ключевым словом [NOT] EXISTS
- •6.5.6. Взаимосвязанные запросы и подзапросы
- •6.5.7. Подзапросы как источник данных
- •6.5.8. Анализ ошибок в подзапросах, оптимизация подзапросов и преобразование подзапросов в запросы с JOIN
- •6.5.9. Промежуточный итог
- •6.6. Оператор UPDATE
- •6.6.1. Общая структура оператора UPDATE
- •6.6.2. UPDATE: [LOW_PRIORITY]
- •6.6.3. UPDATE: [IGNORE]
- •6.6.4. UPDATE: SET
- •6.6.5. UPDATE: [WHERE where_condition]
- •6.6.6. UPDATE: [ORDER BY …]
- •6.6.7. UPDATE: [LIMIT row_count]
- •6.6.8. UPDATE: работа с несколькими таблицами
- •6.7. Оператор INSERT
- •6.7.1. Общая структура оператора INSERT
- •6.7.2. Классический вариант синтаксиса INSERT
- •6.7.3. INSERT: DELAYED
- •6.7.4. INSERT: [INTO] …
- •6.7.5. INSERT: ON DUPLICATE KEY UPDATE
- •6.7.6. INSERT: [IGNORE]
- •6.7.7. Синтаксис INSERT в стиле UPDATE
- •6.7.8. Синтаксис INSERT … SELECT
- •6.7.9. INSERT: важное напоминание, вопросы и ответы
- •6.8. Оператор REPLACE
- •6.8.1. Общая структура и назначение оператора REPLACE
- •6.8.2. Области применения и пример использования REPLACE
- •6.8.3. Области применения и пример использования REPLACE
- •6.8.4. Краткий итог по REPLACE
- •6.9. Оператор DELETE
- •6.9.1. Общая структура оператора DELETE
- •6.9.2. DELETE: [QUICK]
- •6.9.3. DELETE: [IGNORE]
- •6.9.4. DELETE: пример и важное напоминание
- •6.9.5. DELETE: работа с несколькими таблицами
- •6.9.6. Способ быстрой полной очистки таблицы
- •6.10. Оператор LOAD DATA INFILE
- •6.10.2. LOAD DATA INFILE: [CONCURRENT]
- •6.10.3. LOAD DATA INFILE: [CONCURRENT]
- •6.10.4. LOAD DATA INFILE: [REPLACE | IGNORE]
- •6.10.5. LOAD DATA INFILE: [CHARACTER SET charset_name]
- •6.10.6. LOAD DATA INFILE: [FIELDS TERMINATED … ENCLOSED …]
- •6.10.7. LOAD DATA INFILE: [LINES STARTING … TERMINATED BY …]
- •6.10.8. LOAD DATA INFILE: [IGNORE number {LINES|ROWS}]
- •6.10.9. LOAD DATA INFILE: [SET col_name = expr]
- •6.10.10. LOAD DATA INFILE: пример использования
- •6.11. Оператор LOAD XML
- •6.11.2. LOAD XML: пример использования
- •6.11.3. LOAD XML: краткий итог
- •6.12. Оператор CALL
- •6.13. Оператор DO
- •6.14. Оператор HANDLER
- •6.14.1. Общая структура оператора HANDLER
- •6.14.2. Пример использования HANDLER
- •6.14.3. Краткий итог по оператору HANDLER
- •6.15. Итог по всем выражениям управления данными
Базы данных |
БГУИР, ПОИТ |
|
|
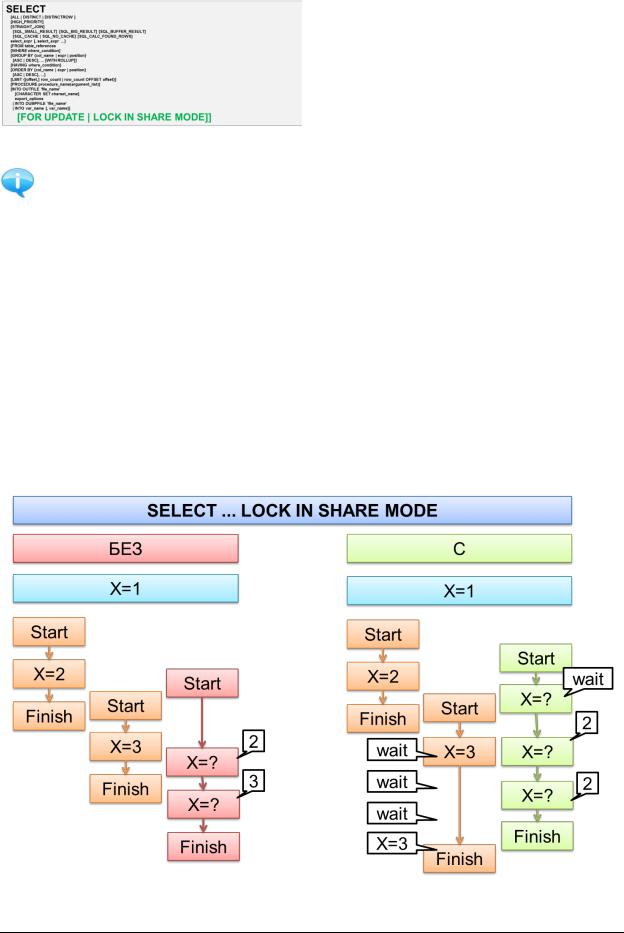
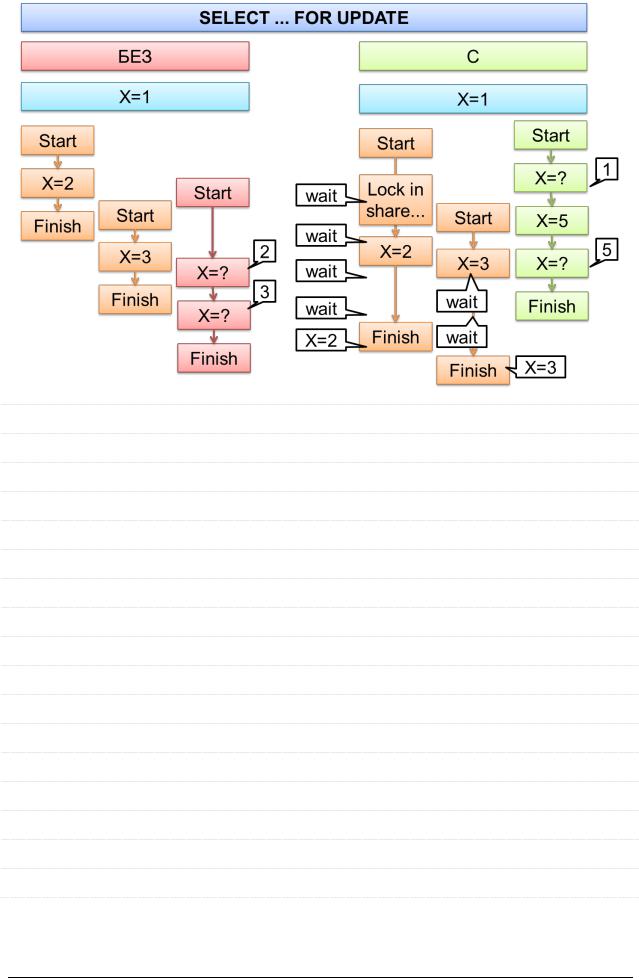
6.1.20.SELECT: [FOR UPDATE | LOCK IN SHARE MODE]]
Данные команды позволяют управлять степенью изолированности выполняемой транзакции от вмешательства других транзакций.
Подробности: http://dev.mysql.com/doc/refman/5.5/en/innodb-locking-reads.html
В руководстве сказано…
При SELECT ... LOCK IN SHARE MODE другие транзакции могут читать обрабатываемые вашей транзакцией ряды, но не могут их модифицировать. Если в момент старта вашей транзакции какие-то нужные ей ряды модифицировались, она ожидает завершения модифицирующей транзакции, а затем использует новые значения.
Применение SELECT ... FOR UPDATE блокирует ряды так, что другие транзакции не могут их модифицировать, выставлять на них LOCK IN SHARE MODE или даже читать их (зависит от уровня изолированности транзакций). Этот режим доступен
только в случае, если автокоммит транзакций отключён через START TRANSACTION или SET autocommit=0.
Рекомендуется использовать при обработке любых иерархических данных (деревья, графы и т.д.)
Поясним логику работы этих конструкций на картинках.
Стр: 173/248
Базы данных |
БГУИР, ПОИТ |
|
|
На этом мы заканчиваем рассмотрение общего синтаксиса оператора SELECT и переходим к частным случаям .
Стр: 174/248