

3.4.1. Функция линейн()
Чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные, используется статистическая функция ЛИНЕЙН(). Функция возвращает массив, который описывает полученную прямую. ЛИНЕЙН может также возвращать дополнительную регрессионную статистику. Отчет по регрессии располагается в заранее выделенном диапазоне ячеек следующим образом:
|
n |
n-1 |
… |
1 |
0 |
|
n |
n-1 |
… |
1 |
0 |
|
R2 |
sey |
|
|
|
|
F |
k |
|
|
|
|
SSreg |
SSresid |
|
|
|
sey- Стандартная ошибка для оценки y.
F- F-статистика, или F-наблюдаемое значение. F-статистика используется для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет.
k- Степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели нужно сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН.
SSreg- Регрессионная сумма квадратов.
SSresid- Остаточная сумма квадратов.
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов. Затем Microsoft Excel подсчитывает сумму квадратов разностей между фактическими значениями y и средним значением y, которая называется общей суммой квадратов (регрессионная сумма квадратов + остаточная сумма квадратов). Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем больше значение коэффициента детерминации R2, который показывает, насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязи между переменными.
3.4.2. Сравнение истинных и оцененных зависимостей
Соотношение между истинной зависимостью между переменными (в генеральной совокупности) и зависимостью, оцененной по выборочным данным проще всего показать на примере соотношения между доходами и расходами. Пусть, к примеру, в небольшом городке проживают сто семей (генеральная совокупность), доходы которых (Хk)можно отнести к одной из пяти групп (k= 1,...,5). Предположим также для простоты, что распределение людей по доходам - равномерное, то есть в каждую группу входят 20 семей. Собрав данные по расходам на члена семьи, нанесем их в виде точек на график, по вертикальной оси которого отложим расходы, а по горизонтальной - доходы.
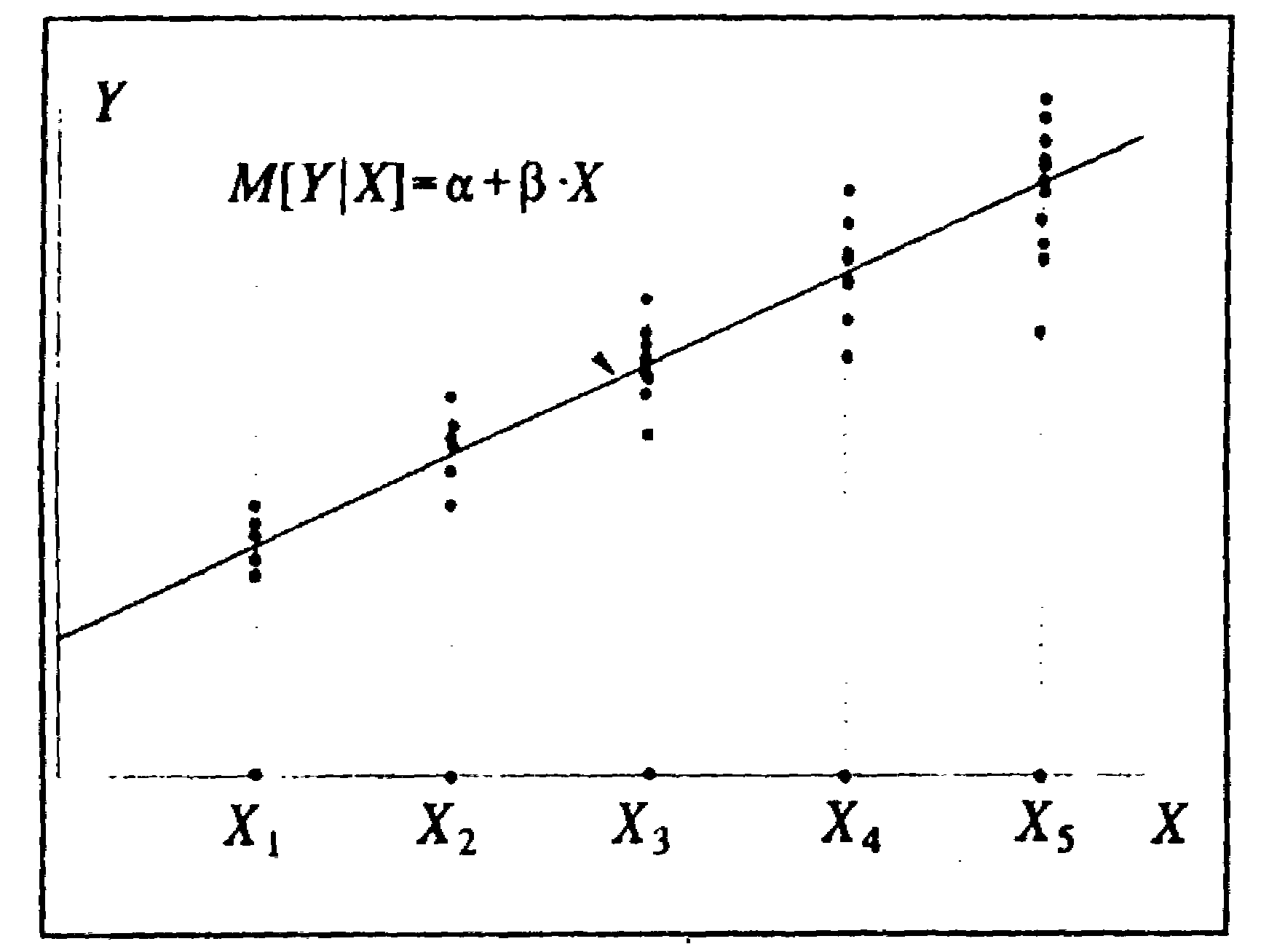
Рис. 3.10
На рис. 3.10 видно, что, во-первых, даже внутри группы с одним доходом расходы людей различны, что объясняется различием вкусов, потребностей, количеством членов в семье и другими факторами, которые не входят в число переменных, объясняющих расходы, и представляемыми в виде случайного (по отношению к доходам) компонента расходов. Во-вторых, можно заметить, что, в среднем, расходы растут с увеличением доходов.
Обозначая средние по k-й группе дохода (в генеральной совокупности) расходыМ[Y|Xk]], можно представить тенденцию увеличения расходов с доходами в виде положительной линейной зависимостиM[Y|X]=+X, которая предполагается истинной зависимостью между средними расходами и доходами.
Для неусредненных расходов в эту зависимость следует добавить случайный член , описывающий разброс расходов внутри группы с одним доходом, обусловленный действием всех остальных факторов, кроме доходов.
Y=+X+
Эта зависимость предполагается истинной зависимостью между индивидуальными расходами и доходами (в генеральной совокупности).
Таким образом, мы имеем две линейных регрессии: одну для генеральной совокупности, коэффициенты в которой обычно обозначаются греческими буквами, и другую для выборки, коэффициенты в которой обычно обозначаются латинскими буквами. Коэффициенты линейной зависимости для генеральной совокупности
Теперь обратимся к выборочным данным о расходах, собранным путем выборочного опроса части жителей городка. Считая выборку репрезентативной, предположим, для простоты, она включает по одному человеку из каждой группы дохода. Отображая выборочные точки на графике, мы можем провести через них линию регрессии, соответствующую уравнению Y=a + bX,коэффициентыa и bи в котором рассчитываются по обычным формулам линейной регрессии. Если учесть, что наблюдаемые значенияYkне лежат на линии регрессии( a + bXk),то в это уравнение надо добавить выборочные случайные возмущенияе (еk = Yk-а- bXk),являющиеся аналогами случайных возмущенийв генеральной совокупности:
![]()
Таким образом, мы имеем две линейных регрессии: одну для генеральной совокупности, коэффициенты в которой обычно обозначаются греческими буквами, и другую для выборки, коэффициенты в которой обозначаются латинскими буквами. Коэффициенты линейной зависимости для генеральной совокупности нам не известны, и мы должны их оценить, пользуясь выборочными данными. Коэффициенты выборочной линейной регрессии aиbявляются выборочными оценками коэффициентовив генеральной совокупности.
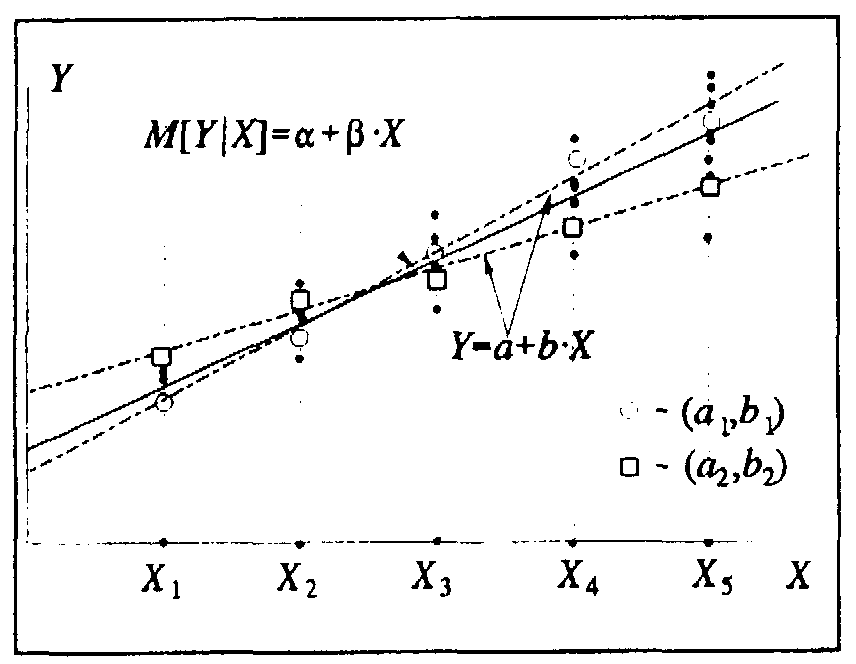
Рис. 3.11
Из рис. 3.11 видно, что выборочные линии регрессии имеют разный наклон и разные точки пересечения с осью Yдля различных выборок. Более того, при положительном наклоне генеральной регрессии наклон выборочной линии регрессии может оказаться для некоторых выборок отрицательным, что, однако, не будет свидетельствовать об истинной отрицательной связи исследуемых величин. Для того чтобы убедиться в этом, следует помимо коэффициентов регрессии находить их стандартные отклонения и t-статистики, по которым можно судить о статистической значимости полученных выборочных коэффициентов регрессии.