

31.Ожидаемое значение случайной переменной, её дисперсия и среднее квадратическое отклонение.
Математическое
ожидание (ожидаемое или среднее значение)
Е(х) находится по формуле: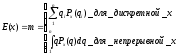
Где Px(qi) – это вероятность появления в опыте значения qi случайной переменной х.
Е(х) – это константа, вокруг которой рассеяны возможные значения q случайной переменной х.
Дисперсия Var (x) – это средний квадрат разброса возможных значений случайной переменной х относительно ее ожидаемого значения:
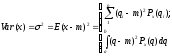
Либо по формуле: σ2 = Е(х2) – m2
Так что Var (x) – это тоже константа, физическая размерность которой равна квадрату физической размерности значений х.
Положительный квадратный корень из дисперсии именуется средним квадратическим отклонением (СКО): σ = (Var (x))^(1/2). Размерность σ и х совпадают. Константа σ (как и σ2) служит характеристикой неопределенности (изменчивости) х.
Для отыскания величин σ2, m нужно знать закон распределения Px(q) случайной переменной х. Часто этот закон неизвестен, и тогда можно оценить (приближенно определить) характеристики σ2, m по результатам n независимых наблюдений (опытов) над х (х1, х2,…, хn), где xi – это случайная переменная с одним и тем же законом распределения Px(q), при этом величины xi – независимы. Кроме того, с ростом количества наблюдений n точность следующих формул, используемых в данном случае, возрастает:
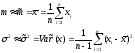
32.Основные числовые характеристики вектора остатков в классической множественной регрессионной модели
Классическая линейная модель множественной регрессии (КЛММР) представляет собой простейшую версию конкретизации требований к общему виду функции регрессии f(X), природе объясняющих переменных X и статистических регрессионных остатков (Х) в общих уравнениях регрессионной связи. В рамках КЛММР эти требования формулируются следующим образом:

Из (2.5) следует, что
в рамках КЛММР рассматриваются только
линейные
функции регрессии, т.е.
![]()
где объясняющие переменные x(1), x(2),…, x(p) играют роль неслучайных параметров, от которых зависит закон распределения вероятностей результирующей переменной y. Это, в частности, означает, что в повторяющихся выборочных наблюдениях (xi(1), xi(2),..., хi(p); yi) единственным источником случайных возмущений значений yi являются случайные возмущения регрессионных остатков i.
Кроме того, постулируется взаимная некоррелированность случайных регрессионных остатков (E(ij) = 0 для i j). Это требование к регрессионным остаткам 1,...,n относится к основным предположениям классической модели и оказывается вполне естественным в широком классе реальных ситуаций, особенно, если речь идет о пространственных выборках (2.4а)-(2.4б), т.е. о ситуациях, когда значения анализируемых переменных регистрируются на различных объектах (индивидуумах, семьях, предприятиях, банках, регионах и т. п.). В этом случае данное предположение означает, что «возмущения» (регрессионные остатки), получающиеся при наблюдении одного какого-либо обследуемого объекта, не влияют на «возмущения», характеризующие наблюдения над другими объектами, и наоборот.
Тот факт, что для всех остатков 1,2,...,n выполняется соотношение Ei2; =2 , где величина 2 от номера наблюдения i не зависит, означает неизменность (постоянство, независимость от того, при каких значениях объясняющих переменных производятся наблюдения) дисперсий регрессионных остатков. Последнее свойство принято называть гомоскедастичностью регрессионных остатков.