

ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ – ВЫСШАЯ ШКОЛА ЭКОНОМИКИ
Отделение статистики, анализа данных и демографии факультета экономики
КАФЕДРА СТАТИСТИЧЕСКИХ МЕТОДОВ
Домашняя работа №2
по многомерным статистическим методам
«Компонентный, кластерный и дискриминантный анализы»
Подготовила: студентка группы С31
Нарышкина Д.М.
Проверила:
Архипова М.Ю.
Москва – 2011
Оглавление
Постановка задачи 3
Глава 1. Компонентный анализ 4
§1. Проверка гипотезы: сколько факторов следует выделять? 4
§2. Интерпретация факторов (главных компонент) 5
§3. Построение диаграммы рассеивания 6
§4. Построение уравнения регрессии на главных компонентах 7
Глава 2. Кластерный анализ 12
§1. Построение и анализ дендрограмм 12
§2. Использование метода k-средних для классификации объектов 16
§3. Создание таблицы «состав кластеров 18
§4. Описание кластеров с помощью графических средств 18
Глава3. Дискриминантный анализ 21
§1. Уточнение результатов классификации 21
§2. Построение дискриминантной функции с помощью включения всех переменны 21
2.1. Исследование качества классификации 21
2.2. Построение дискриминантной функции 23
2.3. Графический анализ результатов классификации 24
§3. Построение дискриминантной функции с помощью пошагового алгоритма 26
Заключение 28
Список литературы 29
Приложения 30
Постановка задачи
Процедура компонентного (факторного) анализа сжимает матрицу исходных признаков, относящихся к имеющимся наблюдениям, в матрицу с меньшим числом переменных, позволяя выявить скрытые закономерности между рассматриваемыми показателями. При этом в один фактор объединяются переменные, сильно коррелирующие между собой. Примем гипотезу Н1: В один фактор объединятся следующие переменные – число предприятий и организаций (x1) в регионе, число зарегистрированных преступлений в сфере экономики (x2) и объем денежных средств, расходуемых в регионе на научные исследования и разработки (x5), так как, как было выяснено нами в ходе корреляционного анализа, между этими переменными наблюдается тесная связь.
В результате кластерного анализа при помощи предварительно заданных переменных формируются группы единиц анализа. Члены одного кластера должны обладать схожими проявлениями показателями, а члены разных групп различными. Выдвинем следующую гипотезу Н2: Регионы России будут разделены на два кластера по уровню экономического развития: высокоразвитые регионы и, соответственно, менее развитые субъекты Федерации. Альтернативная гипотеза Н3: в ходе кластерного анализа нами будет выделено три группы регионов России: с высоким, средним и низким уровнем экономического развития.
С помощью аппарата дискриминантного анализа мы уточним результаты классификации, полученной в ходе кластерного анализа, выявив некорректно классифицированные наблюдения.
Глава 1. «Компонентный анализ»
§1. «Проверка гипотезы: сколько факторов следует выделять?»
Для ответа на поставленный в заголовке параграфа вопрос воспользуемся критерием Кайзера, согласно которому отбираются только те факторы, собственные значения которых больше единицы. Это означает, что если фактор не выделяет дисперсию, эквивалентную, по крайней мере, дисперсии одной переменной, то он опускается.
Таблица 1 «Объясненная суммарная дисперсия»
Полная объясненная дисперсия |
||||||
Компонента |
Начальные собственные значения |
Суммы квадратов нагрузок извлечения |
||||
Итого |
% Дисперсии |
Кумулятивный % |
Итого |
% Дисперсии |
Кумулятивный % |
|
Z1 |
2,423 |
48,467 |
48,467 |
2,423 |
48,467 |
48,467 |
Z2 |
1,047 |
20,932 |
69,399 |
1,047 |
20,932 |
69,399 |
Z3 |
,963 |
19,252 |
88,651 |
|
|
|
Z4 |
,469 |
9,389 |
98,040 |
|
|
|
Z5 |
,098 |
1,960 |
100,000 |
|
|
|
Метод выделения: Анализ главных компонент. |
||||||
Таблица 1 содержит информацию о дисперсии, объясненной моделью. Из таблицы видно, что в представленной факторной модели два собственных числа корреляционной матрицы, превышающих единицу, и потому было отобрано две главных компоненты (фактора), которые в совокупности объясняют 69,4% общей дисперсии. Первая главная компонента объясняет 48,5% общей дисперсии, вторая – 20,9% общей дисперсии.
Рисунок 1 «График каменной осыпи для факторной модели»
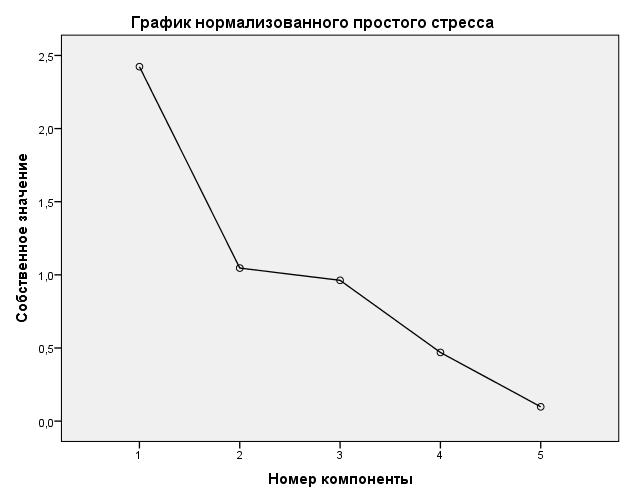
На Рисунке 1, иллюстрирующем критерий каменной осыпи, по оси абсцисс откладываются номера главных компонент, а по оси ординат – собственные значения для каждого из факторов. Убывание собственных значений слева направо максимально замедляется при переходе от второго к третьему фактору. До момента резкого понижения на графике расположено две точки, следовательно, в нашем случае лучше брать два фактора, а не три.