

§2. «Использование метода k-средних для классификации объектов»
Перед кластеризацией необходимо стандартизировать переменные. Воспользуемся командой Описательные из блока команд Описательные статистики, с помощью которой можно провести Z-стандартизацию для отобранных переменных.
В Таблице 6 представлены показатели количества наблюдений, относящихся к каждому кластеру. Кластер 2 более многочисленный по сравнению Кластером 1, который включает в себя Краснодарский край, Ставропольский край, Волгоградская область, Ростовская область, Республика Башкортостан, Республика Татарстан, Пермский край, Самарская область, Челябинская область, Красноярский край, Иркутская область, Приморский край.
Таблица 6 «Количество регионов РФ в каждом кластере»
Число наблюдений в каждом кластере |
||
Кластер |
1 |
12,000 |
2 |
32,000 |
|
Валидные |
44,000 |
|
Пропущенные значения |
,000 |
|
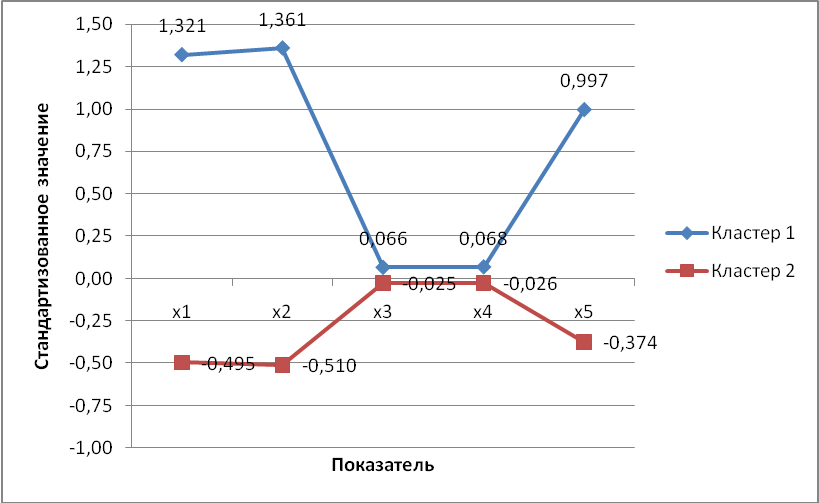
Таблица 7 «Кластерные центры окончательного решения»
Конечные центры кластеров |
||
|
Кластер |
|
1 |
2 |
|
Z-значение(x1) |
1,32099 |
-,49537 |
Z-значение(x2) |
1,36090 |
-,51034 |
Z-значение(x3) |
,06565 |
-,02462 |
Z-значение(x4) |
,06850 |
-,02569 |
Z-значение(x5) |
,99696 |
-,37386 |
Рисунок 5 «График средних значений показателей в кластерах»
Вычисление
стандартизованной величины Z(xi)
для значений каждой из пяти переменных
проводилось по формуле
![]() ,
следовательно, отрицательные значения
средних показателей свидетельствуют
о том, что во втором кластере все
переменные имеют относительно невысокие
абсолютные значения по сравнению с
первым кластером. На основании анализа
Таблицы
7
и Рисунка
5
имеем следующую интерпретацию полученных
кластеров:
,
следовательно, отрицательные значения
средних показателей свидетельствуют
о том, что во втором кластере все
переменные имеют относительно невысокие
абсолютные значения по сравнению с
первым кластером. На основании анализа
Таблицы
7
и Рисунка
5
имеем следующую интерпретацию полученных
кластеров:
Кластер 1 – наиболее развитые регионы России с большим количеством предприятий и организаций, большим объемом внутренних затрат на научные исследования и разработки, поэтому они и лидируют по числу совершаемых преступлений в сфере экономики. Также данная группа регионов отличается от второй группы (однако уже в меньшей степени) более высоким показателем просроченной задолженности по заработной плате, что не представляется удивительным, учитывая число зарегистрированных в регионах первого кластера предприятий, среди которых могут встречаться и весьма прибыльные, и неизменно убыточные, и более высокими темпами инфляции, что затрудняет деятельность предприятий регионов, чей уровень рентабельности дольно низок.
Кластер 2 – регионы России, характеризующиеся более низким уровнем экономического развития.