

25. Методы прогнозирования в статистике.
Статистические методы прогнозирования охватывают разработку, изучение и применение современных математико-статистических методов прогнозирования на основе объективных данных (в том числе непараметрических методов наименьших квадратов с оцениванием точности прогноза, адаптивных методов, методов авторегрессии и других); развитие теории и практики вероятностно-статистического моделирования экспертных методов прогнозирования, в том числе методов анализа субъективных экспертных оценок на основе статистики нечисловых данных; разработку, изучение и применение методов прогнозирования в условиях риска и комбинированных методов прогнозирования с использованием совместно экономико-математических и эконометрических (как математико-статистических, так и экспертных) моделей. Научная база статистических методов прогнозирования — прикладная статистика и теория принятия решений. Простейшие методы восстановления используемых для прогнозирования зависимостей исходят из заданного временного ряда, то есть функции, определенной в конечном числе точек на оси времени. При этом временной ряд часто рассматривается в рамках той или иной вероятностной модели, вводятся другие факторы (независимые переменные) помимо времени, напр., объем денежной массы. Временной ряд может быть многомерным. Основные решаемые задачи — интерполяция и экстраполяция. Метод наименьших квадратов в простейшем случае (линейная функция от одного фактора) был разработан К. Гауссом в 1794—1795 гг. Могут оказаться полезными предварительные преобразования переменных, например, логарифмирование. Наиболее часто используется метод наименьших квадратов при нескольких факторах. Метод наименьших модулей, сплайны и другие методы экстраполяции применяются реже, хотя их статистические свойства зачастую лучше. Накоплен опыт прогнозирования индекса инфляции и стоимости потребительской корзины. Оказалось полезным преобразование (логарифмирование) переменной — текущего индекса инфляции. Оценивание точности прогноза (в частности, с помощью доверительных интервалов) — необходимая часть процедуры прогнозирования. Обычно используют вероятностно-статистические модели восстановления зависимости, напр., строят наилучший прогноз по методу максимального правдоподобия. Разработаны параметрические (обычно на основе модели нормальных ошибок) и непараметрические оценки точности прогноза и доверительные границы для него (на основе Центральной Предельной Теоремы теории вероятностей). Так, предложены непараметрические методы доверительного оценивания точки наложения (встречи) двух временных рядов для оценки динамики технического уровня собственной продукции и продукции конкурентов, представленной на мировом рынке. Применяются также эвристические приемы, не основанные на вероятностно статистической теории: метод скользящих средних, метод экспоненциального сглаживания. К современным статистическим методам прогнозирования относятся также модели авторегрессии, модель Бокса Дженкинса, системы эконометрических уравнений, основанные как на параметрических, так и на непараметрических подходах. Для установления возможности применения асимптотических результатов при конечных (т.н. «малых») объемах выборок полезны компьютерные статистические технологии. Они позволяют также строить различные имитационные модели. Отметим полезность методов размножения данных (бутстрепметодов). Системы прогнозирования с интенсивным использованием компьютеров объединяют различные методы прогнозирования в рамках единого автоматизированного рабочего места прогнозиста. Прогнозирование на основе данных, имеющих нечисловую природу, например, прогнозирование качественных признаков основано на результатах статистики нечисловых данных. Весьма перспективными для прогнозирования представляются регрессионный анализ на основе интервальных данных, включающий, в частности, определение и расчет рационального объема выборки, а также регрессионный анализ нечетких данных. Общая постановка регрессионного анализа в рамках статистики нечисловых данных и ее частные случаи — дисперсионный анализ и дискриминантный анализ (распознавание образов с учителем), — давая единый подход к формально различным методам, полезны при программной реализации современных статистических методах прогнозирования. Основные процедуры обработки прогностических экспертных оценок — проверка согласованности, кластер анализ и нахождение группового мнения. Проверка согласованности мнений экспертов, выраженных ранжировками, проводится с помощью коэффициентов ранговой корреляции Кендалла и Спирмена, коэффициента ранговой конкордации Кендалла и Смита. Используются параметрические модели парных сравнений — Терстоуна, БредлиТерриЛьюса — и непараметрические модели теории люсианов. Полезна процедура согласования ранжировок и классификаций путем построения согласующих бинарных отношений. При отсутствии согласованности разбиение мнений экспертов на группы сходных между собой проводят методом ближайшего соседа или другими методами кластерного анализа (автоматического построения классификаций, распознавания образов без учителя). Классификация люсианов осуществляется на основе вероятностно-статистической модели. Используют также различные методы построения итогового мнения комиссии экспертов. Своей простотой выделяются методы средних арифметических и медиан рангов. Компьютерное моделирование позволило установить ряд свойств медианы Кемени, часто рекомендуемой для использования в качестве итогового (обобщенного, среднего) мнения комиссии экспертов в случае, когда их оценки даны в виде ранжировки. Интерпретация закона больших чисел для нечисловых данных в терминах теории экспертного опроса такова: итоговое мнение устойчиво, т.е. мало меняется при изменении состава экспертной комиссии, и при росте числа экспертов приближается к «истине». При этом предполагается, что ответы экспертов можно рассматривать как результаты измерений с ошибками, все они — независимые одинаково распределенные случайные элементы, вероятность принятия определенного значения убывает по мере удаления от некоторого центра — «истины», а общее количество экспертов достаточно велико. В конкретных задачах прогнозирования необходимо провести классификацию рисков, поставить задачу оценивания конкретного риска, провести структуризацию риска, в частности, построить деревья причин (в другой терминологии, деревья отказов) и деревья последствий (деревья событий). Центральной задачей является построение групповых и обобщенных показателей, например, показателей конкурентоспособности и качества. Риски необходимо учитывать при прогнозировании экономических последствий принимаемых решений, поведения потребителей и конкурентного окружения, внешнеэкономических условий и макроэкономического развития России, экологического состояния окружающей среды, безопасности технологий, экологической опасности промышленных и иных объектов. Современные компьютерные технологии прогнозирования основаны на интерактивных Статистические методы прогнозирования и использовании баз эконометрических данных, имитационных (в том числе на основе применения метода статистических испытаний) и экономико-математических динамических моделей, сочетающих экспертные, математико-статистические и моделирующие блоки.
Показатели размера и интенсивности вариации.
Показатели вариации делятся на две группы: абсолютные и относительные.
К
абсолютным
относятся размах вариации (R),
среднее линейное отклонение ( ),
дисперсия (δ2),
среднее квадратическое отклонение
(δ), квартильное отклонение Q.
),
дисперсия (δ2),
среднее квадратическое отклонение
(δ), квартильное отклонение Q.
Относительными показателями вариации являются коэффициент осцилляции, вариации, относительное линейное отклонение, относительный показатель квартильной вариации и др. Они вычисляются как отношение абсолютных показателей вариации к средней арифметической или медиане.
Самым простым абсолютным показателем является размах вариации. Его исчисляют как разность между наибольшим и наименьшим значениями варьирующего признака.

Величина R всецело зависит от крайних значений признака, и он не учитывает всех изменений варьирующего признака в пределах совокупности
Более точно характеризуют вариацию признака показатели, основанные на учете колеблемости всех значений признака, - среднее линейное отклонение (d) и среднее квадратическое отклонение (δ).
Распределение
отклонений можно уловить, исчислив
отклонения
всех вариант
от средней.
Отклонение от средней - это разность
между вариантой (х) и средней арифметической
( )
в данной совокупности.
)
в данной совокупности.
Чтобы исчислить среднее арифметическое из отклонений нужно применить формулу средней арифметической:
а)
простую
 ;
б) взвешенную
;
б) взвешенную .
.
 -
среднее арифметическое или среднее
линейное отклонение,
дает абсолютную
меру вариации.
-
среднее арифметическое или среднее
линейное отклонение,
дает абсолютную
меру вариации.
Среднее
арифметическое отклонение как мера
вариации применяется редко. Чаще
отклонения от средней возводят в квадрат
и из квадратов исчисляют среднюю
величину. Эта мера вариации называется
дисперсией
( -
средний квадрат отклонений), а корень
квадратный из
-
средний квадрат отклонений), а корень
квадратный из -
- -
естьсреднее
квадратическое отклонение.
-
естьсреднее
квадратическое отклонение.
Чтобы
вычислить среднее квадратическое
отклонение нужно найти отклонение
каждой варианты от средней ( ),
затем возвести отклонения в квадрат,
умножить каждый квадрат отклонения на
свою частоту и просуммировать. Полученную
сумму разделить на сумму частот.
),
затем возвести отклонения в квадрат,
умножить каждый квадрат отклонения на
свою частоту и просуммировать. Полученную
сумму разделить на сумму частот.
 =
=
Корень квадратный из этой величины и будет среднее квадратическое отклонение.
 =
=
Помимо
абсолютных
величин представляют интерес и
относительные
величины. Для
оценки
интенсивности вариации,
а так же для
сравнения ее величины в разных
совокупностях или по разным признакам
используют относительные показатели
вариации.
Базой
для сравнения является средняя
арифметическая ( ).
Они вычисляются как отношениеR,
).
Они вычисляются как отношениеR,
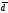 (среднее
линейное отклонение) и
(среднее
линейное отклонение) и (среднее
квадратическое отклонение) к
(среднее
квадратическое отклонение) к или медиане.Выражаются
в %; дают оценку вариации и характеризуют
однородность совокупности.
или медиане.Выражаются
в %; дают оценку вариации и характеризуют
однородность совокупности.
Различают следующие относительные показатели вариации:
коэффициент осцилляции
 =
=
линейный коэффициент вариации
 =
=
коэффициент вариации
 =
=
коэффициент квартильной вариации
 ;
;

Показатели и формы распределения.
Любое реальное распределение можно изобразить схематически в виде кривой, воспроизводящей основные особенности данного распределения. Под кривой распределения понимается графическое изображение в виде непрерывной линии изменения частот, функционально связанных с изменением вариант.
Элементами распределения являются:
варианта
частота
В зависимости от вида кривых, изображающих распределение, выделяют несколько основных типов распределения:
одновершинные
многовершинные
К одновершинным относятся те, в которых один, обычно центральный вариант, имеет наибольшую частоту (плотность распределения). Частоты же остальных вариантов убывают по мере удаления от центрального.
Если частоты убывают слева и справа от центрального значения одинаково, то такие распределения называются симметричными.
Если частоты убывают слева и справа от центра распределения с разной скоростью, то такие распределения называют асимметричными.
Многовершинные распределения — это распределения, в которых несколько центров, т. е. такие, у которых несколько максимумов частот.
Для однородных совокупностей, как правило, характерны одновершинные распределения.
Многовершинность распределения свидетельствует о неоднородности изучаемого явления. В этом случае необходимо произвести перегруппировку данных с целью выделения более однородных групп.
Выяснение общего характера распределения предполагает, наряду с оценкой его однородности, вычисление показателей асимметрии и эксцесса.
Кривые распределения бывают:
симметричными
асимметричными.
В зависимости от того, какая ветвь кривой распределения вытянута, различают:
правостороннюю асимметрию
левостороннюю асимметрию.
Для характеристики степени асимметрии двух или нескольких рядов пользуются коэффициентом асимметрии.
Для одновершинных распределений:
![]()
Более точным является коэффициент асимметрии, рассчитанный как отношение центрального момента третьего порядка (μ3) к среднеквадратическому отклонению в 3-й степени (Ϭ3):

1. Для симметричного распределения:
![]()
Соответственно, в симметричном распределении центральный момент 3-го порядка равен нулю (μ3=0), т. е. алгебраическая сумма отклонений отдельных значений признака (вариант), расположенных слева и справа от средней, равна нулю. График симметричного распределения симметричен относительно точки максимума.

Для несимметричных распределений центральные моменты нечетного порядка отличны от нуля:
2. Асимметрия положительна (As>0), если длинная часть кривой распределения расположена справа от моды (Мо). В этом случае соотношение между средней, медианой и модой нарушено:
![]()

3. Асимметрия отрицательна (As<0), если длинная часть кривой распределения расположена слева от моды (Мо).
![]()

As< 0.25 – слабая асимметрия
As= 0.25-0.5 – умеренная асимметрия
As> 0.5 – крайне асимметричное распределение
Для оценки «крутизны» (островершинности) распределения пользуются характеристикой – эксцессом.
Коэффициент эксцесса:


1. Для нормального распределения:
![]()
2. Выше нормального (островершинное распределение):
![]()
3.
Ниже нормального (плосковершинное
распределение):
![]()