

ЭУМК_КИТ2012
.pdfДокумент – это материальный объект, содержащий информацию, оформленную в установленном порядке, и имеющий в соответствии с действующим законодательством правовое значение. Экономические объекты широко применяют различные документы (платежные поручения, акты, сводки, ведомости и т. д.) для отражения своей деятельности.
Совокупность документов, объединенных по определенному признаку, образует массив. Пример массива – множество финансовых отчетов предприятий некоторой отрасли.
2. ВНЕМАШИННАЯ ОРГАНИЗАЦИЯ ЭКОНОМИЧЕСКОЙ ИНФОРМАЦИИ Документы, их виды, структура
Информация, накопленная, подлежащая обработке, фиксируется на различных носителях. Это может быть бумага, магнитные или оптические диски и др. Их назначение:
·запись первичных данных;
·подготовка к обработке;
·ввод, фиксация результатов обработки.
Применение вычислительной техники в системах управления обусловило деление информации на внутримашинную и внемашинную.
Внемашинная информация – это та часть экономической информации, которая представлена и может быть воспринята пользователем без использования технических средств. Внутримашинная информация содержится на машинных носителях и может состоять из отдельных независимых файлов или представлять собой базу данных.
Формой представления внемашинной информации являются документы.
Под документом понимается информационное сообщение на естественном языке, зафиксированное ручным или печатным способом на бланке установленной формы и имеющем юридическую силу.
Документы классифицируются по сфере деятельности, отношению к объекту управления, содержанию хозяйственных операций, назначению, способу использования, способу заполнения.
По сфере деятельности документы делятся на плановые, учетные, статистические, банковские, финансовые, банковские и т.д.
По отношению к объекту управления – на входящие, исходящие, промежуточные, архивные.
По содержанию хозяйственных операций – на материальные, денежные, расчетные.
По назначению – распорядительные, исполнительные, комбинированные.
По способу заполнения – на заполняемые с помощью технических средств и вручную.
По отношению к машинной обработке экономической информации документы делятся на первичные и сводные, получаемые в результате машинной обработки первичных документов. В структуру документа должны включаться следующие разделы:
·заголовочная часть – наименование и характеристика документа, зона для проставления кодов, постоянные реквизиты признаки;
·содержательная часть – где располагаются показатели;
·оформляющая часть – содержит подписи юридических лиц, а также дату составления.
Классификация и кодирование информации
Развитие АИС потребовало достижения единства информационного обеспечения путем создания единой системы классификации и кодирования информации.
Под системой классификации понимается совокупность правил распределения элементов заданного множества на подмножества в соответствии с установленными признаками сходства или различия, называемыми основанием.
В настоящее время наиболее распространенными являются иерархическая и фасетная
(многоаспектная) системы классификации.
91
Иерархическая система классификации предполагает деление объектов на некоторые группы, каждая из которых, в свою очередь, делится на более мелкие подгруппы, постепенно конкретизируя объект классификации. Преимуществом такой системы классификации является ее традиционность и приспособленность для внемашинной обработки информации. Недостатком – сложности при внесении изменений, из–за слабой гибкости структуры, связанной с заранее установленным порядком группировки информации.
В фасетной системе объекты делятся на группировки одновременно по нескольким независимым признакам (фасетам). В качестве примера можно привести указанную выше систему классификации документов, где классификация ведется по различным классификационным признакам. К достоинствам такой системы относят гибкость структуры, легкость внесения изменений, что влечет за собой возможность автоматического кодирования информации. Недостатком фасетной системы является сложность ее применения при внемашинной обработке информации.
Для записи информации на носители и ее обработки используется кодирование информации, т.е. перевод сообщений с исходного языка на формализованный с помощью кодов. В процессе кодирования объектам классификации присваиваются цифровые, буквенные или буквенноцифровые кодовые обозначения. Кодирование облегчает ввод и обработку данных, а также увеличивает плотность записи информации на носителях. Коды принято делить на следующие виды:
1) по методу образования:
· порядковые – при которых объектам присваиваются порядковые номера; · серийно-порядковые – выделяется серия, а внутри серии присваиваются порядковые номера;
· разрядные – при которых каждому признаку классификации отводится определенное число разрядов; · комбинированные.
2) по количеству разрядов:
· замкнутые системы кодирования – при которых строго ограничено количество символов. Например: ТАБ№ - 4 символа, №ЗАЧЕТКИ – 8 символов; · открытые – с неограниченным количеством символов.
3) по форме отображения:
· цифровая форма кодирования; · буквенная; · буквенно-цифровая.
4)позиционная форма кодирования (позиция числа имеет значение);
5)штриховое кодирование.
Реквизиты-основания имеют цифровое кодирование, реквизиты-признаки имеют буквенноцифровое кодирование.
Систематизация экономической информации вызывает необходимость применения классификаторов:
·общегосударственных, – разрабатываемых в централизованном порядке;
·отраслевых – единых для определенных отраслей;
·локальных – характерных для данного предприятия.
Классификатор – систематизированный свод однородных наименований и их кодовых обозначений. Применяются для разного рода проставления кодов в документах и для размещения в памяти машины в качестве словарного фонда.
3. ВНУТРИМАШИННАЯ ОБРАБОТКА ЭКОНОМИЧЕСКОЙ ИНФОРМАЦИИ Файловая организация данных, ее недостатки
В первые годы автоматизированной обработки информации, в 50 –х, начале 60–х годов, использовалась файловая организация данных. Данные хранились в файлах последовательного доступа. Это заставляло прикладную программу обрабатывать файл целиком, когда
92
необходимо было обратиться к определенной записи, что, конечно же, существенно замедляло скорость обработки данных. С появлением в 60–е годы устройств прямого метода доступа к данным – магнитных дисков – появилась возможность напрямую обратиться к нужной записи. Однако и это не дало существенного повышения скорости обработки и достоверности данных.
К недостаткам файловой организации данных относятся также:
-структура записей в файле задается в программе (приложении), которая работает с этим файлом;
-при изменении структуры файла необходимо изменять программу (приложение), т.е. наблюдается сильная зависимость программы от данных;
-если с файлом работают несколько приложений, то необходимо менять все приложения;
-невозможность нескольким пользователям изменить одновременно содержание файла, т.е. следующий пользователь может изменить файл, если предыдущий закончил изменения и закрыл этот файл.
Эти недостатки файловой организации данных обусловили появление баз данных (БД), которые позволяют обеспечивать более эффективный доступ к данным и их обработку.
Понятие БД. Преимущества БД
База данных – это компьютерный термин, употребляемый для обозначения совокупности информации по определенной тематике, используемой в определенной прикладной области. Компьютерная БД – это автоматизированная версия системы заполнения, хранения и извлечения информации любой структуры – от простого текста до сложной структуры данных, включая рисунки, звуки и видеоизображения.
Дадим определение БД.
База данных – поименованная и структурированная совокупность взаимосвязанных данных, которые отражают состояние объектов конкретной предметной области, их свойства и взаимоотношения и находятся под общим программным управлением.
Преимущества использования БД заключаются в следующем: 1. Возможность расширения и модификации данных.
2. Возможность обеспечения независимости данных в БД от программ их обрабатывающих. 3. Возможность вести быстрый поиск необходимых данных по запросам пользователя.
4. Возможность обеспечения защиты секретных данных от постороннего вмешательства. 5. Возможность обеспечения целостности данных и др.
Приложения БД. Компоненты БД Приложения БД
Приложения базы данных включают такие объекты для работы с базой данных как формы, отчеты, Web-страницы и прикладные программы. Формы, отчеты и Web-страницы можно создавать с помощью средств, поставляемых в комплекте с СУБД (например, в СУБД Access имеются средства конструирования таких объектов, называемые элементами управления). Прикладные программы должны быть написаны либо на входном языке СУБД (например, модули в Access), либо на одном из стандартных языков программирования и затем с помощью СУБД соединены с базой данных.
Дадим краткую характеристику объектов приложений баз данных, т.к. далее, на примере СУБД Access, мы рассмотрим их более детально.
Формы являются основным средством создания диалогового интерфейса приложения пользователя. Формы могут служить удобным средством для экранного представления данных, использоваться для ввода данных, а также для создания панелей управления в приложениях.
Отчеты - это форматированное отображение информации из базы данных при выводе на печать.
Web-страницы используются для просмотра, редактирования, обновления, удаления, отбора, группировки и сортировки изменяющихся данных базы данных в Microsoft Internet Explorer .
Компоненты БД
93
Любая база данных состоит из четырех основных компонент: данных пользователя, метаданных, индексов и метаданных приложений.
Данные пользователя в большинстве современных баз данных представляются в виде набора таблиц, состоящих из строк (записей) и столбцов (полей).
Метаданные представляют собой описание структуры базы данных с помощью так называемых системных таблиц.
Индексы являются средством ускорения операций поиска необходимой информации в базах данных, а также используются при извлечении, модификации и сортировке данных. Метаданные приложений описывают структуру и формат пользовательских форм, отчетов и других компонентов приложений базы данных.
94
2.МОДЕЛИ ДАННЫХ
1.Трехуровневая модель организации баз данных
2.Иерархические и сетевые модели данных
3.Реляционная модель данных
4.Постреляционная, многомерная, объектно-ориентированная и объектно-реляционная модели данных.
1. ТРЕХУРОВНЕВАЯ МОДЕЛЬ ОРГАНИЗАЦИИ БАЗ ДАННЫХ
После того, как была выработана концепция базы данных и системы управления ее, специалисты, начиная с 1971 года, стали работать над общей архитектурой и терминологией базы данных. Вопросы, касающиеся того, как должна быть устроена база данных, были решены не сразу. В течение ряда лет велись научные исследования в этом направлении, предлагались различные способы реализации. В результате многократных обсуждений предлагаемых решений в 1978 году учеными была принята трехуровневая система организации данных, предложенная Национальным Институтом стандартизации – ANSI (American National Standards Institute) и Комитетом по планированию выпуска стандартов и технических условий – SPARC Соединенных штатов Америки.
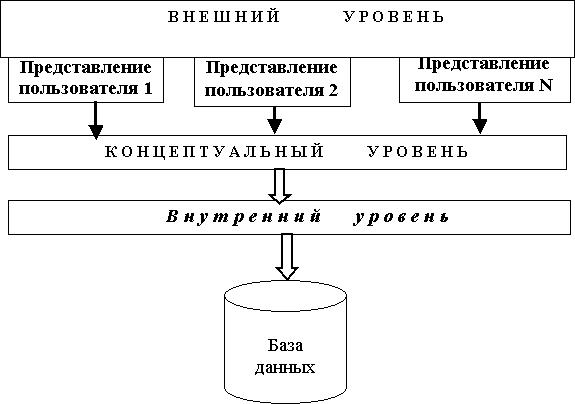
Рис. 1. Трехуровневая модель организации баз данных Фундаментальным моментом в этом подходе является выделение трех уровней
абстракции, то есть трех различных уровней абстракции описания элементов данных:
95
 внешний уровень – это тот, на котором представляют данные пользователи;
внешний уровень – это тот, на котором представляют данные пользователи;
 концептуальный уровень служит для отображения данных внешнего уровня на внутренний и обеспечивает необходимую независимость данных разных уровней друг от друга;
концептуальный уровень служит для отображения данных внешнего уровня на внутренний и обеспечивает необходимую независимость данных разных уровней друг от друга;
 на внутреннем уровне данные воспринимаются СУБД и операционной системой.
на внутреннем уровне данные воспринимаются СУБД и операционной системой.
Внешний уровень – это самый верхний уровень, который отражает представление конечного пользователя о конфигурации данных (более подробно о типах пользователей баз данных будет изложено в последней лекции). Каждый пользователь представляет реальный мир по-своему, исходя из того вида работы, которую он выполняет. Остальная часть реального мира его не интересует. Некоторые представления пользователя не являются исходными, а потому в базе данных их не следует сохранять, так как они могут быть вычислены, например, вместо данных о возрасте, которые надо часто менять, следует внести в базу данные о дате рождения, и из них вычислять возраст.
Концептуальный уровень – это объединяющее представление данных, используемых всеми пользовательскими приложениями, работающими с данной базой. На этом уровне база данных представляет собой общий взгляд пользователя на данные проектируемой базы. Это, например, представление с точки зрения менеджера высшего уровня о данных всего предприятия. Здесь описывается: какие данные хранятся в базе, и каковы связи между ними. Этот уровень отражает логическую структуру всей базы с точки зрения администратора базы данных. В действительности концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создается база данных.
Концептуальный уровень – это попытка представить требования к базе со стороны организации. И этот уровень не должен содержать никаких сведений о методах хранения данных. Здесь должны быть отражены:
 все сущности, включаемые в базу, их атрибуты и связи;
все сущности, включаемые в базу, их атрибуты и связи;
 накладываемые на данные ограничения;
накладываемые на данные ограничения;
 семантическая информация о данных;
семантическая информация о данных;
 информация о мерах обеспечения безопасности и поддержки целостности данных.
информация о мерах обеспечения безопасности и поддержки целостности данных.
База данных на концептуальном уровне имеет высокую степень абстракции и характеризуется аппаратной и программной независимостью. Создаваемая на
96
этом уровне концептуальная модель служит основой для идентификации и описания основных объектов данных.
Внутренний уровень служит для адаптации концептуальной модели к конкретной СУБД. Другими словами, внутренняя уровень – это представление базы данных со стороны СУБД, и на этом уровне описывается, как данные должны храниться в компьютере. А потому на этом уровне требуется, чтобы проектировщик привел свойства и ограничения концептуальной модели в соответствие с выбранной моделью реализации базы данных. Внутренний уровень предназначен для достижения оптимальной производительности и обеспечения оптимального использования дискового пространства. На этом уровне осуществляется взаимодействие СУБД с методами доступа операционной системы. Здесь хранится такая информация:
 распределение дискового пространства для хранения данных и индексов;
распределение дискового пространства для хранения данных и индексов;
 описание подробностей хранения данных;
описание подробностей хранения данных;
 сведения о размещении записей;
сведения о размещении записей;
 сведения о сжатии данных и методах их шифрования.
сведения о сжатии данных и методах их шифрования.
База данных, создаваемая на этом уровне, имеет средний уровень абстракции и характеризуется аппаратной независимостью и программной зависимостью, то есть она зависит от программного обеспечения базы данных. А потому любые изменения в программном обеспечении СУБД потребуют изменений во внутренней модели, для того чтобы она соответствовала требованиям СУБД.
В действительности ниже внутреннего уровня находится еще уровень физического представления данных, то есть физический уровень, на котором описываются способы хранения информации на носителях, например, на винчестерах. Другими словами, физический уровень – это собственно данные, хранящиеся на внешних носителях информации и расположенные в файлах или страничных структурах. Этот уровень контролируется операционной системой, но под управлением СУБД. Здесь требуется определить, как устройства физического хранения, так и методы доступа, необходимые для извлечения данных с физического носителя. База данных, создаваемая на этом уровне, имеет самый низкий уровень абстракции и характеризуется аппаратной и программной зависимостью.
В соответствии с трехуровневой архитектурой существует три различных типа схем базы данных. На самом высоком уровне имеется несколько внешних схем данных, которые соответствуют разным представлениям пользователей. На концептуальном уровне описываются все элементы и связи между ними. Для каждой базы данных имеется только одна концептуальная схема. Внутренняя схема является полным описанием данных внутреннего уровня и содержит определение хранимых записей: методы представления, описание полей данных, сведения об индексах и схемах хеширования данных. СУБД отвечает за
97
установление соответствия между этими тремя типами схем, а также за проверку их непротиворечивости.
2. Иерархические и сетевые модели ДаННЫХ
Одними из основополагающих в концепции баз данных являются категории «данные» и «модель данных». Данные – это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию и др., например: 200 руб., Петров Петр Петрович и т.п. Данные не обладают определенной структурой, они становятся информацией лишь тогда, когда пользователь задает им определенную структуру, то есть наделяет их смысловым содержанием. Поэтому центральным понятием в области баз данных является понятие модели. Не существует однозначного определения этого термина, но можно выделить нечто общее в существующих определениях.
Модель данных – это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие осмысленные данные и взаимосвязь между ними.
С другой стороны, любая база данных состоит из элементов данных (реквизитов) и связей между ними. Значит, чтобы организовать данные в базу, необходим предварительный процесс моделирования, то есть должна быть разработана схема, позволяющая изобразить связи между элементами данных. Такую схему принято называть моделью данных. Таким образом, модель данных – это систематизация разнообразной информации и отражение ее свойств по содержанию, структуре, объему, связям, динамике с учетом удовлетворения информационных потребностей всех категорий пользователей. Модель данных является ядром базы данных.
В настоящее время в результате теоретических изысканий, рожденных реальными потребностями практики обработки данных, разработано много моделей данных, которые различаются по способу связи между данными. Однако наибольшее практическое применение нашли три модели: иерархическая, сетевая, реляционная. Их иногда называют традиционными моделями данных. В последние годы ведутся работы по созданию баз данных, построенных на постреляционной, многомерной, объектно-ориентированной и других моделях, которые называют нетрадиционными моделями.
2.1. Иерархическая модель
Иерархическая модель появилась впервые в результате обобщения структур данных языка Кобол. В иерархических моделях основная структура представления данных имеет форму дерева. На самом высшем (первом) уровне иерархии находится только одна вершина, которая называется корнем дерева. Эта вершина имеет связи с вершинами второго уровня, вершины второго уровня имеют связи с вершинами третьего уровня и т.д. Связи между вершинами одного уровня отсутствуют. Следовательно, данные в иерархической структуре не равноправны – одни жестко подчинены другим. Доступ к информации возможен только по вертикальной схеме, начиная с корня, так как каждый элемент связан
98
только с одним элементом на верхнем уровне и с одним или несколькими на низком.
Примером иерархической структуры может служить книга, как иерархическая последовательность букв, которые объединяются в слова, слова – в предложения, предложения – в параграфы, затем в главы и т.д.
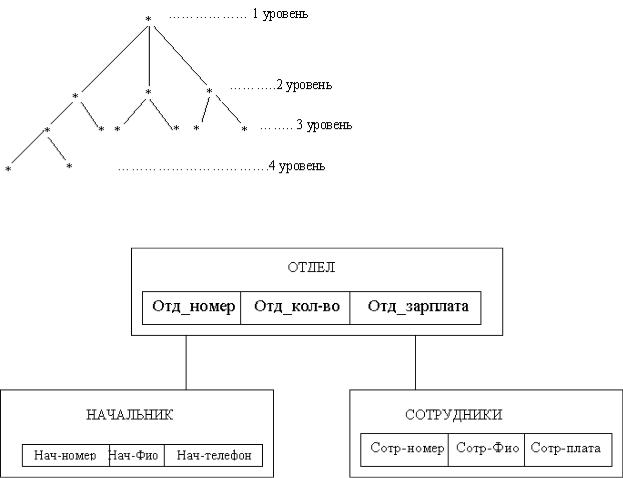
С точки зрения теории графов иерархическая модель представляет собой древовидный граф (перевернутое дерево), упрощенный вид которого показан на рис. 2.
Рис. 2. Древовидный граф Реальный пример иерархической модели данных представлен на рис. 3 и 4.
Рис. 3. Пример иерархической модели данных
99
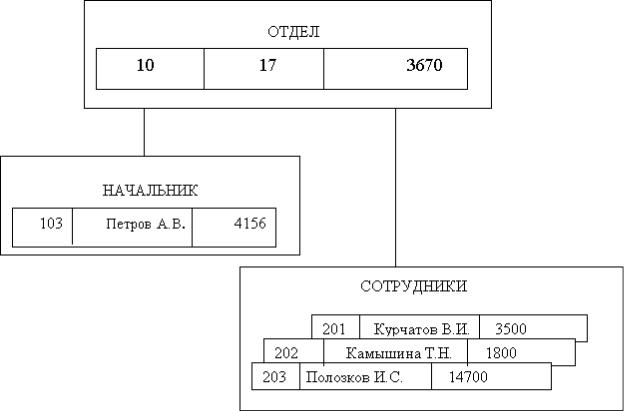
Рис. 4. Пример иерархической модели данных Над иерархически организованными данными определенны следующие операции:
·Добавить в базу данных новую запись.
·Изменить значение данных предварительно извлеченной записи.
·Удалить некоторую запись и все подчиненные ей записи.
·Извлечь запись; в этой операции допускается задание условий выборки, например, извлечь сотрудников с окладом более 200 тысяч руб.
Иерархическая модель является наиболее простой, поэтому исторически она появилась первой. К достоинствам иерархической модели данных относится: достаточно эффективное использование памяти и неплохие временные показатели выполнения операций над данными. Однако, удобна эта модель в основном для работы с иерархически организованной информацией. Недостатками иерархической модели являются достаточно сложные логические связи и соответствующая громоздкость в обработке данных.
Первые системы управления базами данных, появившиеся в середине 60-х годов, позволяли работать с иерархической базой данных. Наиболее известной была иерархическая система IMS фирмы IBM. Известны также другие системы: PC/Focus, Team-Up, Data Edge и наши: Ока, ИНЭС, МИРИС.
2.2. Сетевая модель
Дальнейшим развитием иерархической модели является сетевая. Сетевая модель
– это структура, у которой любой элемент может быть связан с любым другим элементом (рис. 5). Реальный пример иерархической модели представлен на рис.
6.
100