

Базовые функции. Рассмотрим две одинаковые числовые оси.






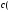









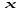


 -
числовая функция от х.
-
числовая функция от х.
Если каждому значению х из (a; b) по какому- нибудь закону или правилу f
поставлено в соответствие одно определенное значение другой величины
 ,
то говорят, что
,
то говорят, что
 –
естьчисловая
функция от х.
–
естьчисловая
функция от х.
х – аргумент;
(a, b) – область определения функции;
(c,d) – область значений функций.
Например: y = sinx; y = x²;
х – независимая переменная,

у – зависимая переменная от х.


Множество
точек М (х; у), где
 ,
,
 называется
графиком функции
называется
графиком функции
 .
.
Простейший вид заданного типа функции называется базовой функцией.
Пример,
 - линейная функция. Базовой функцией
будет являться функция
- линейная функция. Базовой функцией
будет являться функция .
.
При построении функции заданного типа предварительно строим график базовой функции.
Пример:
Построить график функции
 .
.
Перед
нами – квадратичная функция. Ее графиком
является парабола. Базовой функцией
будет являться функция
 .
.


Для построения нашей функции выделим полный квадрат:


График нашей функции строится в три этапа:
Строим график базовой функции
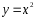
Сдвигаем нашу функцию на
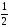 влево:
влево:
Опускаем график полученной функции на
 вниз.
вниз.
График
функции


Понятие сложной функции
Для освоения понятия сложной функции введем в рассмотрение промежуточную числовую ось z.
Для
примера рассмотрим функцию
 .
Для этой функции, для заданногох,
предварительно вычисляется
.
Для этой функции, для заданногох,
предварительно вычисляется
 .
Для полученного значенияz
вычисляется
.
Для полученного значенияz
вычисляется
 .
Таким образом, в два приема для заданногох,
мы получили значение
.
Таким образом, в два приема для заданногох,
мы получили значение
 .
Такое задание
.
Такое задание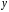 от
х
называется
сложной функцией.
от
х
называется
сложной функцией.


 –сложная
функция от х.
–сложная
функция от х.

Промежуточных числовых осей может быть несколько.
Например:

Обратная функция




















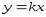







Элементарной функцией будем называть базовую функцию или функцию,
полученную путем четырех арифметических действий из базовых функций, или
взятия сложной функции, последовательно применяемых конечное число раз
 .
.
Говорят,
что функция
 непрерывна
в точке
непрерывна
в точке
 ,
если
выполнены следующие условия:
,
если
выполнены следующие условия:
 –существует
значение функции в точке
–существует
значение функции в точке

существуют пределы функции слева и справа при


все полученные нами числа должны быть равны между собой.
И записывается это так:

Так
как,
 ,то
условие непрерывности примет вид
,то
условие непрерывности примет вид



Для непрерывной функции знак предела и знак функции можно переставлять местами.
Разрывная функция





}
скачок
Конечный скачок








Бесконечный скачок


Устранимый
скачок: предел
слева равен пределу справа, а в точке

 значение
значение не
существует, или не совпадает с пределами.
не
существует, или не совпадает с пределами.


В
точке
 значение функции вычислить нельзя, так
как на 0 делить нельзя.
значение функции вычислить нельзя, так
как на 0 делить нельзя.
Теорема
Всякая элементарная функция непрерывна в области своего определения:

Мера и нечеткая мера
Понятие меры было введено для частных случаев Э. Борелем К. [18], К. Жорданом [19] и А. Лебегом [20]. В современной теории меры Banon G. формулирует его следующим образом, [11].
Пусть
заданы области определения: аддитивный
класс 2x
в
пространстве X
на универсальном множестве X;
значения – множество действительных
чисел R.
Функция множества называется мерой
 ,
если выполняются условия {1,2,3}:
,
если выполняются условия {1,2,3}:
ограниченность -
 ;
;неотрицательность -
 ;
;аддитивность -
 .
.
В теории нечётких множеств используется понятие «нечеткая мера», на основе которой определяется функция доверия.
Пусть теперь заданы области определения, аддитивный класс 2А в пространстве А на универсальном множестве X; значения - отрезок [0,1] на множестве действительных чисел.
Функция множества называется нечеткой мерой g:
 ,
если выполняются условия {1,2,3}:
,
если выполняются условия {1,2,3}:
ограниченность – g (Ø) = 0, g(x)=1;
монотонность – для

непрерывность – для An
 2A
и
монотонной последовательности
2A
и
монотонной последовательности

Тройка
 называется
пространством с нечеткой мерой.
называется
пространством с нечеткой мерой.
Задача построения нечетких мер
Пусть
в результате некоторого наблюдения
или эксперимента в
 для
для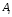 ,
, стали
известны (измерены) значения функции
стали
известны (измерены) значения функции .
.
Задача
построения нечеткой меры заключается
в том, чтобы по с помощью какого-либо правила, определить
с помощью какого-либо правила, определить .
.
В
отличие от меры m,
нечеткая мера
 ,
по определению, не является аддитивной,
т.е.
,
по определению, не является аддитивной,
т.е. ≠
≠ .
.
Поэтому М. Сугэно [21] постулировал λ-правило для построения нечетких мер с параметром нормировки λ:
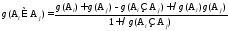
В
частном случае, при
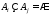 ,λ
-
правило запишем следующим образом:
,λ
-
правило запишем следующим образом:

Если
теперь так задать ,
чтобы
,
чтобы ,
то, с учётом
,
то, с учётом
 ,
получим выражение для параметра
нормировки λ:
,
получим выражение для параметра
нормировки λ:
 (1.9)
(1.9)
Дальнейшее рассмотрение построения нечетких мер требует их аппроксимации с применением (L-R) функции по Д. Дюбуа и А. Праду [22].
Это может быть выполнено для конкретных нечетких мер из их классификации.
Представим классификацию нечетких мер по Banon G. [11]:

 НЕЧЕТКИЕ
МЕРЫ
НЕЧЕТКИЕ
МЕРЫ

Функция
доверия. Мера необходимости Функция
правдоподобия. Мера возможности


λ>0
λ=0
λ<0
Рис.1.4. Классификация нечетких мер.
Нечеткие множества: определение и формы записи в операциях и
методах представления знаний
Заданы: дискретная область определения – аддитивный класс 2Х в пространстве Х на универсальном множестве Х; область значения – отрезок [0,1] на множестве действительных чисел.
Аксиома
4: функция множества А
называется функцией принадлежности μ,
если для любых
 она
отображает область определения на
область значения:
она
отображает область определения на
область значения:
μ:
2X [0,1].
(1.10)
[0,1].
(1.10)
Каждому значению μ(xi) дается одна из следующих понятийных интерпретаций {1,2,3}:
нечеткость суждения
 ;
;субъективная совместимость xi и A;
мера нечеткости xi.
Обобщением данных свойств является понятие «нечеткость» (fuzzy) или принадлежность элемента xi множеству A.
Аксиома 5: нечеткое множество НМ есть совокупность упорядоченных пар- элементов множества А и соответствующих им значений функции принадлежности:
{|xi, μ(xi)|}, (1.11)
где
А ={ {xi}},
i
{xi}},
i I
I {1,2,…n}.
{1,2,…n}.
Множество А называется носителем нечеткого множества.
На
примере носителя А ={x1,x2,x3}
и значений функций принадлежности
μ(x1)= ,μ(x2)=μ2,
μ(x3)=μ3
приведем основные формы записи нечётких
множеств:
,μ(x2)=μ2,
μ(x3)=μ3
приведем основные формы записи нечётких
множеств:
А = {x1, x2, x3}, (1.12)
μA = μ1, μ2, μ3.
μ1/x1+μ2/x2+μ3/x3=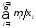 ,
(1.13)
,
(1.13)
 .
(1.14)
.
(1.14)
Каждое нечеткое множество может иметь многоуровневое представление в виде набора носителей, определенных для заданных значений μ:
 ,
(1.15)
,
(1.15)
где
Аα
–
носитель уровня α,
т.е. подмножество на области определения,
для элементов которого ,i
,i {1,2,..n},
/- связка «при».
{1,2,..n},
/- связка «при».
Например, если для нечетких множеств = {(x1, 0.2), (x2, 0.3), (x3, 0.5)} заданы уровни представления α=0,2 и α=0,3, то получим А0,2 = {x1,x2,x3} и A0,3 ={x2, x3}. Таким образом, данное нечеткое множество на уровнях 0,2 и 0,3 представлено 2-мя носителями: А0,2 = {x1,x2,x3} и A0,3 = {x2,x3}.
К
любому нечеткому множеству, равному
{(xi,
μi)}
с носителем А = { {xi}}
и
{xi}}
и
i I
I {1,2,…n},
можно добавить пару вида (xk,
0), k
{1,2,…n},
можно добавить пару вида (xk,
0), k {1,2,…n}
и k≠i.
{1,2,…n}
и k≠i.
Такая процедура называется модификацией мощности носителя.
Базовые операции над нечеткими множествами с модифицированными носителями: нечеткое множество 1 есть {(xi, μi)} и нечеткое множество 2 равное
{(xi, )},i
)},i {1,2,…n},
сводятся к вычислению функции
принадлежности результата {1,2,3,4}:
{1,2,…n},
сводятся к вычислению функции
принадлежности результата {1,2,3,4}:
дополнение
 ,
γ=1-μi;
,
γ=1-μi;разность НМ1\НМ2, γ=MIN(μi,1-
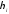 );
);пересечение (произведение)
 ∩
∩ ,
γ=MIN
(μi,
,
γ=MIN
(μi, );
);объединение (сумма)


 ,
γ=
,
γ= (μi,
(μi, ).
).
1.7.Функции доверия и правило Демпстера а.Р.,[23]
Заданы
области: определения – аддитивный
класс
 в пространстве
в пространстве на универсальном множествеX;
значения – отрезок [0;1] на множестве
действительных чисел.
на универсальном множествеX;
значения – отрезок [0;1] на множестве
действительных чисел.
Ограниченность – Bel(ø)=0, Bel(X)=1;
Супераддитивность – для m множеств

 X.
X.
 (1.16)
(1.16)
Понятийно Bel – это, по Г. Шеферу (G. Shafer) [24], мера доверия гипотезе, которой соответствует множество в аргументе функции.
Например,
если имеется гипотеза: A
есть одиночное множество {x1}
или {x2},
или {x3},
то A={x1} {x2}
{x2} {x3}
и мера доверия этой гипотезе будет равна
Bel(A).
{x3}
и мера доверия этой гипотезе будет равна
Bel(A).
Рассмотрим
частный случай: на множестве
 ={x1,x2}
определены
={x1,x2}
определены
 и
и
 .
Из
супераддитивности функции доверия при
m
=2
следует:
.
Из
супераддитивности функции доверия при
m
=2
следует:
Bel({x1} {x2})
{x2}) Bel({x1})+Bel({x2})-({x1}
Bel({x1})+Bel({x2})-({x1} {x2}).
(1.17)
{x2}).
(1.17)
Из ограниченности функции доверия следует:
Bel({x1} {x2})=Bel(ø)=0,
{x2})=Bel(ø)=0,
Bel({x1} {x2})=Bel(
{x2})=Bel( )=1.
(1.18)
)=1.
(1.18)
Используя формулу (1.17), в случае равенства и (1.18), получим:
Bel({x1})+Bel({x2})=1. (1.19)
Из
(1.19), с учётом {x2}= {x1},
вытекает:
{x1},
вытекает:
Bel( {x1})=1-Bel({x1})
. (1.20)
{x1})=1-Bel({x1})
. (1.20)
Соотношение (1.20) называется нормирокой Bel.
Рассмотрим применение нормированной функции доверия для обработки данных.
В
 наx={x1,x2,…,xi,…,xn}
определена Bel
и результатом некоторого эксперимента
или наблюдения в
наx={x1,x2,…,xi,…,xn}
определена Bel
и результатом некоторого эксперимента
или наблюдения в
 является факт, который известен в виде
элементаxi
и его значения функции принадлежности
μi,
то есть, как нечёткое множество НМ={(xi,
μi)}
с носителем {xi},
является факт, который известен в виде
элементаxi
и его значения функции принадлежности
μi,
то есть, как нечёткое множество НМ={(xi,
μi)}
с носителем {xi},
 принадлежит
{1,2,…,n}.
принадлежит
{1,2,…,n}.
Аксиома 7. Функция доверия с простым носителем:
Bel={0, при A не включаемом в {xi};
μi
при
A,
включенном в {xi};
1- при A=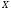 },
где
},
где
 -
множество из гипотез {1,2,3}:
-
множество из гипотез {1,2,3}:
(1.21)
A есть любой элемент {xj}, кроме {xi};
A есть {xi}, или любой другой элемент {xj};
A есть универсальное множество X.
Рассмотрим
теперь простейшую гипотезу: A
есть однозначное множество {xi}.
Дополнительно к свойствам нечёткого
множества, эта гипотеза интерпретируется
как определение меры доверия факту с
помощью соотношения (1.21): Bel
({xi})= .
.
Пусть теперь все экспериментальные данные сосредоточены на наборе, состоящем из двух фактов:
НМ={(xi,
μi),(xj,
μj)}с
носителем {xi} {xj},
{xj},
 принадлежит{1,2,…,n}.
принадлежит{1,2,…,n}.
Аксиома 8:
Правило
Демпстера: (композиция Bel({xi})
и Bel({xj}))
при их объединении ({xi} {xj}),
не равна X:
{xj}),
не равна X:
Bel({xi}) Bel({xj})
=
Bel({xj})
=
 . (1.22)
. (1.22)
Выражение (1.22) определяет меру доверия двум фактам.
Если
все экспериментальные данные сосредоточены
на наборе, состоящем из m
фактов НМ={(xi, )}
с носителем {
)}
с носителем { {xi}},
i
{xi}},
i I
I {1,2,…,n},
m=#I,
то получаем композицию:
{1,2,…,n},
m=#I,
то получаем композицию:
 ,
(1.23)
,
(1.23)
Выражение (1.23) определяет меру доверия набору из m фактов.
1.8. Нормировка функций в теории нечётких множеств
В
 на
на определена и нормирована
определена и нормирована :
:
 .
(1.24)
.
(1.24)
Опыт системных аналитиков говорит: использование только нормированных функций приводит к тривиальным результатам.
Для устранения тривиальности в теории нечётких множеств изначально заложена ненормированность функции принадлежности:
 (1.25)
(1.25)
Таким
образом, в нечётких технологиях
используется ненормированная входная
функция
 ,
а внутренние (например,Bel)
и выходные – нормированы.
,
а внутренние (например,Bel)
и выходные – нормированы.
Это позволяет учитывать все особенности и противоречия внешнего (физического) мира, а на выходе из технологии (дефаззификация) получать результаты в привычном диапазоне, например от 0 до 1, или в процентах.
1.9. Нечёткие отношения: прямая и обратная задачи
В
 на
на определены
нечёткие множества.
определены
нечёткие множества.
 ,
(1.26)
,
(1.26)
Аксиома 9:
Нечёткие
отношения (НО) двух нечётких множеств
есть совокупность упорядоченных пар
{xi,
xj}
и соответствующих им значений функции
принадлежности :
:
 .
(1.27)
.
(1.27)
Нечёткое отношение между НМ1 и НМ2 есть частный случай использования композиционных правил нечёткого ввода НМ1 => НМ2.
Пусть
имеется два набора факторов НМ1=
{(xi,
μi)},
где i
равно от 1
до n,
НМ2=
{xj,
μj},
где j
равно от 1
до n
и установлена зависимость между ними
в виде правила: НМ1
=> НМ2,
которому соответствует нечёткое
отношение {(xi,xj),
(μi,
μj)}.
Теперь, если известен набор фактов НМ1’=
{xi’,
μi’},
где i
принадлежит от 1 до n,
то можно сделать нечёткий вывод, что
 или
по
или
по определить
определить ,
используя правило композиции:
,
используя правило композиции:
 (1.28)
(1.28)
перебором
 ,
или методом С.Ю. Маслова, [25]. Приближённое
решение
,
или методом С.Ю. Маслова, [25]. Приближённое
решение
(в сторону уменьшения Bel):
 ,
(1.29)
,
(1.29)
где μji - матрица транспонирования относительно μij.
Глава 2. Методы представления знаний с использованием приближенных и нечетких множеств
2.1.Нечеткие вычислительные технологии
Обобщенная схема нечетких технологий (НТ) есть преобразование:
Данные
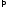 Знания
Знания
|
Результаты измерений по шкалам {1, 2, 3, 4}:
|
Результаты расчётов (косвенных измерений) со свойствами {1,2}:
|
Такое преобразование использует материальный аппарат теории нечетких множеств и минимальную технологию, состоящую из следующих фрагментов:
семантика объекта,
создание базы знаний,
распознавание объектов,
управление процессом.
2.2.Семантика объекта: определение и типизация
При описании физического объекта, т.е. при создании его семантики, разделим набор показателей, параметров, характеристик объекта на 2 множества:
Наблюдения над объектом и состояния природы объекта
Множество наблюдений над объектом – совокупность показателей, параметров, характеристик и их значений, полученных в результате измерений (прямых или косвенных, либо иным объективным способом, например, от экспертов).
Множество состояний природы объекта – это совокупность субъективных оценок, показателей, параметров, характеристик, либо интегральная, то есть суммарная оценка объекта по некоторому набору признаков или параметров, характеристик.
Множества наблюдений над объектом и состояний природы объекта равны соответственно:
D={d1,d2,d3, …, dn}, C={c1,d2,d3, …, cm}.
Причинно-следственная связь между наблюдениями и состояниями природы объекта учитывается путём формирования универсального множества:
X = { d1,d2,d3, …, xe, …, xn}, xe= {di, cj}, где i=1, … n, j=1, … nm.
Область определения функции в семантике объекта есть аддитивный класс 2x в X на X, то есть:
2x
= { },
гдеk
},
гдеk ,
L
= 2{1,2,
… n}
.
,
L
= 2{1,2,
… n}
.
В
этом классе выбран носитель нечеткого
множества ,
гдеi
принадлежит от 1
до n,
j
принадлежит
от 1
до n
и для каждого его элемента
,
гдеi
принадлежит от 1
до n,
j
принадлежит
от 1
до n
и для каждого его элемента
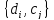 получено значение функции принадлежностиμij.
Итак, семантика объекта – это набор
нечетких множеств по числу его состояний
природы #J
с носителем равной мощности #I.
Семантика объекта может быть общей,
типичной и простой.
получено значение функции принадлежностиμij.
Итак, семантика объекта – это набор
нечетких множеств по числу его состояний
природы #J
с носителем равной мощности #I.
Семантика объекта может быть общей,
типичной и простой.
Общая семантика:
НМj={((di, cj), μij)}, где i принадлежит от 1 до n, j принадлежит от 1 до m.
Типичная семантика:
НМj={((di, cj), μij)}, где i принадлежит от 1 до n, j принадлежит от 1 до m.
Простая семантика:
НМj={((di, cj), μij)}, где i принадлежит от 1 до n, j принадлежит от 1 до m, #I = 2.
Таким образом, семантика объекта есть переход из физического мира в семантический мир. Обратный переход от нечетких множеств к показателям, параметрам и характеристикам объекта неоднозначен. Он выполняется по следующей схеме:
- имеется общая семантика объекта НМj={((di, cj), μij)}, где i принадлежит от 1 до n,
j принадлежит от 1 до m. Для каждого состояния, j принадлежит от 1 до m, находим условие imax,
MAX({μij }/i= imax), здесь / - связка «при», где i принадлежит от 1 до n,
j принадлежит от 1 до m и imax от 1 до n. (2.1)
Соотношение (2.1) определяет номер того наблюдения, которому соответствует максимальное значение функции принадлежности из всех наблюдений текущего состояния. Исходя из свойств нечёткого множества, полагаем, что объект имеет состояние природы Cj при наблюдении dimax.
Если соотношение (2.1) дает несколько значений imax, то имеет место неоднозначность переходов к функции меры.
Она не устранима в рамках семантики, но прагматики технологии, фрагменту «Управление процессом», позволяют устранить неоднозначность настройкой начальных и граничных условий.
2.3.Создание Базы знаний: постановка, семантика, прагматика
Имеется объект со следующей семантикой:
 .
.
Здесь:
 – значение функции принадлежности,
полученное в результате
эксперимента;
– значение функции принадлежности,
полученное в результате
эксперимента; наблюдение;
наблюдение; состояние;
состояние;
 ,
, Таким
образом, объекту, с состоянием
Таким
образом, объекту, с состоянием

Из нескольких объектов, при заданной семантике пустой БЗ, в прагматике можно получить непустую БЗ.
Семантика пустой БЗ:

 ,
,

Таким
образом, пустая БЗ-это m
НМj, Семантика
непустой БЗ:
Семантика
непустой БЗ:
НМj,
где
 – значение функции принадлежности,
находящейся в непустой БЗ. Таким образом,
непустая база знаний – этоm
НМj
– значение функции принадлежности,
находящейся в непустой БЗ. Таким образом,
непустая база знаний – этоm
НМj
Каждое
НМj
будем
называть эталоном с состоянием

Прагматика БЗ содержит 2 процедуры {1,2}:
формирование БЗ – это присоединение экспериментальных данных, содержащихся в семантике объекта, к пустой БЗ;
обновление БЗ – это замена в непустой БЗ одного, нескольких, либо всех эталонов.
В прагматике используется функция доверия Bel, которая является мерой доверия экспериментальным данным (фактам), содержащимся в семантике объекта. Факты считаются приемлемыми, если мера доверия им не менее порогового значения Bel0, определенного на [0,1].
Для объекта с j-м состоянием мера доверия:
 (2.2)
(2.2)
Прагматика формирования БЗ:
 (2.3)
(2.3)
В результате применения такой процедуры сформирована непустая БЗ из
m – эталонов.
Для эталона с j-м состоянием мера доверия:
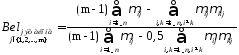 (2.4)
(2.4)
Новый объект можно использовать для обновления БЗ.
Прагматика обновления БЗ:
 .
(2.5)
.
(2.5)
2.4. Сопоставление объектов: постановка, семантика, прагматика
Сопоставление объектов, по Аткинсону Р. [27, 28], основано на сопоставлении образов центральной нервной системой человека, выполняющей операции 1,2, 3:
зрительное совмещение исходных образов;
выделение в совмещённом образе ядра;
сравнение совмещённого образа и ядра по известным и уже апробированным ранее геометрическим яркостным и цветовым признакам.
Исходы по сопоставлению образов 1, 2, 3:
отсутствие сходства - образы не похожи друг на друга;
многозначное сходство - один образ похож на несколько образов;
однозначное сходство - один образ похож на другой и не похож на остальные.
Имеется
семантика двух объектов:
 (2.6)
(2.6)
 .
.
По
аналогии сопоставления образов
центральной нервной системой человека,
в прагматике сопоставления объектов
выполняются следующие операции над

совмещение образов
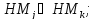
выделение ядра

сравнение совмещённого образа и ядра, то есть вычисление степени сходства:
L
= Bel( )/Bel(
)/Bel( ),или
),или
L=Bel[MAX( )]/Bel[MIN(
)]/Bel[MIN( )],
)], (2.7)
(2.7)

Выражение
L
определяет степень сходства
 .
.
Имеется семантика набора m эталонных объектов и одного k опытного объекта:
 =
{(
=
{( )},
)},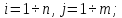
 (2.8)
(2.8)
В прагматике проведем экспертизу эталонов – то есть, сравним между собой p-й и q-й эталоны –
 ={(
={( )}
и
)}
и =
= ,
, p,q
p,q ,
по степени сходства
,
по степени сходства
 Bel[MAX
(
Bel[MAX
( )]/Bel[MIN(
)]/Bel[MIN( )]
)] p,q
p,q (2.9)
(2.9)
Выражение
 определяет степень сходства p-го
и q-го
эталонов.
определяет степень сходства p-го
и q-го
эталонов.
По
матрице
 определим
порог степени сходства
определим
порог степени сходства
L0
= MIN( ),
p
),
p ,
q = (p +1
,
q = (p +1 .(2.10)
.(2.10)
В результате экспертизы эталонов определён порог степени сходства L0, при котором сходство не противоречит исходным данным в наборе эталонов. Теперь НМk сравним с каждым эталоном НМj и получим набор степеней сходства {Lj}:
{Lj}
=Bel[MAX( )]/Bel[MIN(
)]/Bel[MIN( )]
)]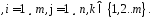 (2.11)
(2.11)
Выражение
{Lj}
определяет степень сходства НМk
с каждым эталоном из набора НМj,
 .
Затем найдём максимумы - глобальныйLmax
= MAX({Lj})
и локальный Lmax2
= {{Lj}\
Lmax},
.
Затем найдём максимумы - глобальныйLmax
= MAX({Lj})
и локальный Lmax2
= {{Lj}\
Lmax}, .
По этим результатам определены условия
исходов по сходству:
.
По этим результатам определены условия
исходов по сходству:
Отсутствие сходства – объект НМk не похож ни на один эталон из набора НМj: {Lj}<L0,
 ;
;Многозначное сходство - объект НМk похож на несколько эталонов из набора НМj: Lmax2
 L0;
L0;Однозначное сходство, объект НМk похож на один из эталонов из набора НМj: Lmax
 L0,Lmax>Lmax2.
L0,Lmax>Lmax2.
Предельно
допустимая ошибка сходства
 равна:
равна:
 =
Lmax
– MAX(Lmax2,
L0).
(2.12)
=
Lmax
– MAX(Lmax2,
L0).
(2.12)
2.5.Распознавание объектов: постановка, семантика, прагматика
Имеется
семантика объекта с неизвестным
состоянием при известных наблюдениях:
 (2.13)
(2.13)
Имеется также семантика непустой базы, созданной по прагматике формирования или обновления, то есть:
 =
{(
=
{( )},
)}, (2.14)
(2.14)
Распознавание объекта-это определение его состояния ck или значения
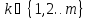 в
прагматике сопоставления объекта и
базы знаний.
в
прагматике сопоставления объекта и
базы знаний.
Используем частный случай прагматики сопоставления объектов:
исход - однозначное сходство.
Прагматика
распознавания состояния объекта
выполняется по схеме:
1 2
2 3
3 4
4 5
5 6
6 7
7
 8
8 9:
(2.15)
9:
(2.15)
1 –по
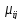 выполним экспертизу эталонов и получим
матрицу степеней сходства между
эталонамиLpq
выполним экспертизу эталонов и получим
матрицу степеней сходства между
эталонамиLpq
Lpq
= Bel[MAX( )]/Bel[MIN(
)]/Bel[MIN(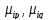 )],
)], ;
;
2 – по полученной матрице Lpq определим порог степени сходства L0:
L0
= MIN( ),
p
),
p ,
q = (p + 1
,
q = (p + 1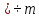 ;
;
3 – по
 определим
набор степеней сходства {Lj}:
определим
набор степеней сходства {Lj}:
{Lj}
=Bel[MAX( )]/Bel[MIN(
)]/Bel[MIN( )]
)]
4 – по {Lj} определим глобальный максимум Lmax из этого набора и его условие r:
Lmax
= MAX({Lj}),
при j=r,
 };
};
5 – по {Lj} и Lmax определим локальный максимум Lmax2 из этого набора:
Lmax2
= MAX({Lj}
\ Lmax),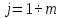 ;
;
6 – по Lmax,L0, Lmax2 проверяем условие однозначного сходства:
Lmax L0,
Lmax>Lmax2;
L0,
Lmax>Lmax2;
 7
– Если условия пункта 6 не выполняются,
заключаем, что однозначное
7
– Если условия пункта 6 не выполняются,
заключаем, что однозначное
распознавание невозможно и его завершаем. Иначе, по результатам
пункта
4 определяем распознаваемое состояние
k:
k=r,
k,r };
};
8 - по Lmax,L0, Lmax2 определяем предельно допустимую ошибку сходства
 :
:
 Lmax
– MAX(Lmax2,
L0);
Lmax
– MAX(Lmax2,
L0);
9 – заключаем, что с ошибкой, меньшей предельно допустимой, однозначное сходство объекта и r-го эталона не противоречит БЗ [28, 29].
2.6. Управление процессом представления знаний
В семантике объекта множества наблюдений и состояний природы связаны между собой и зависят от времени, т.е. образуют параметрическое пространство, в котором объект перемещается по стационарной траектории с нестационарными возмущениями. Такое перемещение называется процессом, а его реализация – движением объекта в заданных границах отсчета времени. Управление процессом означает, что в ответ на возмущение вырабатывается такое управляющее воздействие на объект, чтобы его отклонение от стационарной траектории не превышало заданную величину при любых реализациях процесса, [30-33].
Объект характеризуется следующими параметрами:
-
t
– время с шагом квантования
 t,
числом шагов T
и числом квантов запаздывания τ
[28,
29];
t,
числом шагов T
и числом квантов запаздывания τ
[28,
29];
-
y
– возмущение с шагом квантования
 ,
диапозономymax
и граничным значением y0;
,
диапозономymax
и граничным значением y0;
-
 -
управляющее воздействие с шагом
квантования
-
управляющее воздействие с шагом
квантования и диапазоном
и диапазоном max.
max.
Тогда нечёткое нестационарное возмущение (или просто возмущение) определим как НМ1, а нечёткое управляющее воздействие - как НМ2.
НМ1={[di,
 (t/
(t/ t)]},
t)]}, ;
;
НМ2={[cj,
 (t/
(t/ t)]},
t)]}, ,
,
где
di
– наблюдение, соответствующее текущему
значению относительно возмущения y/ ;
; /
/ y+1;
i=
y/
y+1;
i=
y/ +(n+1)/2+1;
+(n+1)/2+1;
cj–состояние,
соответствующее текущему значению,
относительно управляющего воздействия
 ;
;
m=2| max
|
max
| +
1;j
=
+
1;j
=
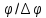 +
(m-1)/2+1;
+
(m-1)/2+1;
 (t/
(t/ t)
и
t)
и
 (t/
(t/ t)
– функции принадлежности возмущения
и управляющего воздействия, соответственно;
t)
– функции принадлежности возмущения
и управляющего воздействия, соответственно;
t/ t
- номер шага квантования (1
t
- номер шага квантования (1
 t/
t/ t
t T).
T).
Функции
принадлежности определяются в
предположении о переходах, между
ближайшими соседями (пересечениями
линий квантования) при t/ t=
t= ,
следующим образом:
,
следующим образом:
 (t/
(t/ t)
=
t)
=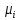 (t/
(t/ t-1)+1/n
t-1)+1/n ,
,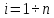 ,
, (0)=
(0)= ;
;
 (t/
(t/ t)
=
t)
= (t/
(t/ t-1)-1/[n(n-1)]
t-1)-1/[n(n-1)] ,
, ,
p
,
p (0)=
(0)= ;
;
 (t/
(t/ t)
=
t)
=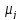 (t/
(t/ t-1)+1/m
t-1)+1/m ,
j
,
j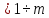 ,
, (0)=
(0)=
 (t/
(t/ t)
=
t)
= (t/
(t/ t-1)-1/[m(m-1)]
t-1)-1/[m(m-1)] ,
q
,
q ,
, (0)=
(0)= ,
q
,
q j,
j,
где
 (t/
(t/ t)
– функция принадлежности для наблюдения
di,
наблюдение, соответствующее текущему
значению y/
t)
– функция принадлежности для наблюдения
di,
наблюдение, соответствующее текущему
значению y/
 (t/
(t/ t)
– функция принадлежности для остальных
наблюдений dp;
t)
– функция принадлежности для остальных
наблюдений dp;
 (t/
(t/ t)-функция
принадлежности для состояния cj,
которое соответствует текущему значению
t)-функция
принадлежности для состояния cj,
которое соответствует текущему значению
 ;
;
 (t/
(t/ t)
– функция принадлежности для остальных
состояний сq;
t)
– функция принадлежности для остальных
состояний сq;
 ,
,
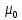 - максимальное, минимальное и начальное
значения функции принадлежности,
соответственно.
- максимальное, минимальное и начальное
значения функции принадлежности,
соответственно.
Взаимная
связь возмущения и управляющего
воздействия при каждом t/ t
является нечётким отношением (НО):
t
является нечётким отношением (НО):
 .(2.16)
.(2.16)
Взаимная
связь возмущения НМ1
и управляющего воздействия НМ2,
усреднённая по отношению t/ t,
определяется нечётким отношением:
t,
определяется нечётким отношением:
 (2.17)
(2.17)
где
Если
в реализации процесса на некотором шаге
 появится возмущение
появится возмущение
НМ1эксп={[dj,
 (
( )]},
то, с помощью нечёткого вывода
НМ1эксп=>НМ2расч,
определяем управляющее воздействие:
)]},
то, с помощью нечёткого вывода
НМ1эксп=>НМ2расч,
определяем управляющее воздействие:
НМ2расч={[{cj, (
( +τ)}]},
+τ)}]}, (
( +τ)=MAX[
+τ)=MAX[ (
( ),
), ].
(2.18)
].
(2.18)
С помощью нечёткого вывода, НМ2расч => НМ1расч, определяем отклонение от траектории:
НМ1расч={[ci,
 (
( +τ)]},
+τ)]},
 (
( +τ)
= MAX{MIN[
+τ)
= MAX{MIN[ (
( +τ),
+τ),
 ]}.
(2.19)
]}.
(2.19)
Матрица
 является транспонированной относительно
является транспонированной относительно .
.
Нечёткие множества: субъективность и неточность
Излагается общая точка зрения, основанная на понятии субъективности и неточности. Применение теории нечётких множеств к представлению неточных понятий было изложено в работах Goguena J.A., [34].
Наиболее убедительным аргументом Goguena J.A. является теорема представимости из его диссертации, утверждающая, что любая система, удовлетворяющая определённым аксиомам, эквивалентна некоторой системе нечётких множеств. Интуитивно кажется, что система всех неточных понятий удовлетворяет этим аксиомам. Поэтому, на основании теоремы, можно заключить: неточные понятия представимы нечёткими множествами. Теорема представимости математически строго доказывается теорией категорий [35], поэтому понятиям «система», «эквивалентно», «представлено» - придан самый точный смысл.
Множество, рассматриваемое в абстрактной, то есть классической, нечёткой теории множеств, определяется, как совокупности объектов, имеющих, некоторое общее свойство Р. Относительно природы каждого объекта в ней не делается никаких специальных предположений. Например, множество A можно определить как множество улиц: А = {x|x есть улица}.
Что можно сказать о классе длинных улиц, является ли оно множеством в обычном смысле. Для этого нужно спросить - какова длина длинной улицы. Если улица длиной в милю, то чем она отличается от улицы в 0.5 мили, то есть, мы не знаем, как ответить на эти вопросы. Потому что выражение «улица длинная», относящееся к классу длинных улиц, не образует множество в обычном смысле. Фактически к такому размытому, нечетко определенному типу, относится большинство классов объектов реального физического мира. То есть, четких критериев принадлежности реальных объектов к тому или иному классу - не существует. Реальный объект не обязательно должен либо принадлежать, либо не принадлежать какому-либо классу, но возможны и промежуточные степени принадлежности. Отсюда и возникает понятие о нечетком множестве как о классе с континуумом (мощность множества) степеней принадлежности. Теория нечетких множеств ЗадеЛ. является обобщением ТНМ, [12-17]. Другими словами, она включает в себя абстрактную теорию - как частный случай. Все определения, теоремы, доказательства и т.д., ТНМ, всегда справедливы и для четких множеств. Поэтому, по сравнению с теорией абстрактных множеств, теория нечетких множеств имеет более широкую область применения при решении задач, в той или иной степени, включающих субъективную оценку. Интуитивно, НМ - это класс, к которому имеется возможность принадлежать.
Пусть
Ω = {x}
– это пространство объектов. Тогда НМ
А в пространстве Ω называется множество
упорядоченных пар A
= {(x,
µA(x))},
x Ω,
где µA(x)
- называется «степенью принадлежности
объекта x
к множеству А». Для простоты будем
предполагать, что µA(x)
- это число, принадлежащее отрезку
Ω,
где µA(x)
- называется «степенью принадлежности
объекта x
к множеству А». Для простоты будем
предполагать, что µA(x)
- это число, принадлежащее отрезку
 ,
причем 1 соответствует полной
принадлежности к НМ, а 0 - тому, что объект
к нему не принадлежит. Предположим так
же, что мы располагаем возможностью
сравнения истинности двух нечетких
утверждений: «x
,
причем 1 соответствует полной
принадлежности к НМ, а 0 - тому, что объект
к нему не принадлежит. Предположим так
же, что мы располагаем возможностью
сравнения истинности двух нечетких
утверждений: «x А»
и «y
А»
и «y А»
и что точное отношение, полученное в
результате такого сравнения, удовлетворяет
минимальным требованиям согласованности
– рефлексивности и транзитивности;
при этом знак >= имеет смысл, по крайней
мере «столь же истинно, как и», а знак
<= - «не так истинно, как». В своей
философской работе Black
M.
[36] различает 3 типа неточности:
А»
и что точное отношение, полученное в
результате такого сравнения, удовлетворяет
минимальным требованиям согласованности
– рефлексивности и транзитивности;
при этом знак >= имеет смысл, по крайней
мере «столь же истинно, как и», а знак
<= - «не так истинно, как». В своей
философской работе Black
M.
[36] различает 3 типа неточности:
неопределенность, когда некоторое понятие применимо к множеству разнообразных ситуаций;
неоднозначность, когда оно описывает насколько различимых подпонятий;
неясность, когда нет точно определенной границы понятия.
НМ, таким образом, служит представлением всех 3 типов неточности. Неопределённость имеет место, когда универсальное множество состоит более чем из одной точки. Неоднозначность присутствует всякий раз, когда функция принадлежности имеет более одного локального максимума. Неясность соответствует тому факту, что функция принадлежности принимает значения отличные от 0 и 1. Таким образом, неоднозначность и неясность предполагают существование в универсальном множестве некоторого понятия близости или соседства. Рассмотрим несколько примеров НМ.
Пример 1:
Рассмотрим класс всех действительных чисел, много больших 1. Это множество можно определить как:
A
= {x|x
– действительное число и x 1}.
1}.
Однако
по упомянутым выше причинам такое
множество нельзя считать вполне четко
определенным. Субъективно это множество
можно задать с помощью функции
принадлежности µA(x),
такой что µA(x)
= 0, при x<=
1 и µA(x)
=
 ,
приx>
1, которая показана на рис. 2.1:
,
приx>
1, которая показана на рис. 2.1:
1


 µA
µA

log xi
Рис. 2.1.Функция принадлежности µA(x).
По своему существу задание функции принадлежности к НМ субъективно и отражает контекст, в котором рассматривается задача. Однако, несмотря на эту субъективность, функция принадлежности к НМ А не может быть произвольной. Будет полнейшей ошибкой задавать функцию принадлежности в виде:
µA(x)
=
 ,
гдеx<=
1 и µA(x)
= 0, при x>
1.
,
гдеx<=
1 и µA(x)
= 0, при x>
1.
Точно так же непригодна функция
µA(x)
= 0, где x<=
1 и µA(x)
=
 ,
приx>
1, которая монотонно убывает с ростом x
при x>
1 и функция µA(x)
= 0 x<=
1 и µA(x)
=
,
приx>
1, которая монотонно убывает с ростом x
при x>
1 и функция µA(x)
= 0 x<=
1 и µA(x)
=
 , приx>
1, которая, хотя монотонно и возрастает,
становится ~ 1 уже при x=1,1.
Которая удовлетворяет неравенству µA
, приx>
1, которая, хотя монотонно и возрастает,
становится ~ 1 уже при x=1,1.
Которая удовлетворяет неравенству µA [0,1] при всех x
[0,1] при всех x Ω
и находится в согласии с определением
множества А. Такие функции называют
недопустимыми
функциями
для нечеткого множества А.
Ω
и находится в согласии с определением
множества А. Такие функции называют
недопустимыми
функциями
для нечеткого множества А.
Из предыдущего обсуждения вытекает, что при задании функции принадлежности не следует придавать числовым значениям (кроме 0 и 1) таких признаков как, «короткий», какого либо особого смысла; важным здесь является самоупорядочивание этих значений. Наблюдательные люди согласятся друг с другими, что 1 человек меньше другого, однако и в этом случае слово короткий никогда не будет иметь четко определенного смысла. По терминологии Суппеса П. и Зинеса Дж. [37] степень принадлежности может быть измерена в порядковой шкале.
Морфизм категорий [38] также используется как метод описания измерений соотношений между точностью (мера правильности и важности) (мера ожидаемой
полезности) в теории принятия решений, прогнозов погоды, а также соотношений между мнениями нескольких экспертов метеорологов.
Морфизм
категорий – термин, используемый для
элементов произвольной категории,
играющих роль отображений множеств
друг в друга, гомоморфизмов групп, колец,
алгебр, непрерывных отображений
топологических пространств и т.п. Морфизм
категории – неоределяемое понятие.
Каждая категория состоит из элементов
двух классов, называемых классом объектов
и классом морфизмов соответственно.
Класс морфизмов категории
 обозначается
обозначается .
Любой морфизм
.
Любой морфизм категории имеет однозначно определенное
начало – объект
категории имеет однозначно определенное
начало – объект и однозначно определенный конец –
объект
и однозначно определенный конец –
объект .
Все морфизмы с общим началом
.
Все морфизмы с общим началом и концом
и концом образуют
подмножество
образуют
подмножество класса
класса .
Тот факт, что
.
Тот факт, что имеет начало
имеет начало и конец
и конец ,
можно записать обычным образом:
,
можно записать обычным образом: ,
или с помощью стрелок
,
или с помощью стрелок и т.п. Деление элементов категории на
морфизмы и объекты имеет смысл только
в пределах фиксированной категории,
т.к. морфизмы одной категории могут быть
объектами другой и наоборот. Морфизмы
любой категории образуют систему,
замкнутую относительно частичной
бинарной операции – умножения. В
зависимости от свойств морфизма по
отношению к этой операции выделяются
специальные классы морфизмов, например:
мономорфизм, эпиморфизм, биморфизм,
изоморфизм, нулевой морфизм, нормальный
монорфизм, нормальный эпиморфизм и
т.д. Эпиморфизм – понятие, отражающее
алгебраические свойства сюръективных
отображений множеств.
и т.п. Деление элементов категории на
морфизмы и объекты имеет смысл только
в пределах фиксированной категории,
т.к. морфизмы одной категории могут быть
объектами другой и наоборот. Морфизмы
любой категории образуют систему,
замкнутую относительно частичной
бинарной операции – умножения. В
зависимости от свойств морфизма по
отношению к этой операции выделяются
специальные классы морфизмов, например:
мономорфизм, эпиморфизм, биморфизм,
изоморфизм, нулевой морфизм, нормальный
монорфизм, нормальный эпиморфизм и
т.д. Эпиморфизм – понятие, отражающее
алгебраические свойства сюръективных
отображений множеств.
2.8.Нечеткая алгебра
Определение 1: Нечеткой алгеброй называется система:
Z
= <Z,+,*, >
, гдеZ
– множество, имеющее хотя бы 2 различных
элемента и
>
, гдеZ
– множество, имеющее хотя бы 2 различных
элемента и
 системаZ
удовлетворяет следующему набору аксиом:
системаZ
удовлетворяет следующему набору аксиом:
идемпотентность:
 ;
;коммутативность:
 ;
;ассоциативность:
 ;
;поглощение:
 ;
;дистрибутивность:


дополнение: если
 то существует дополнение
то существует дополнение элементах
такое, что
элементах
такое, что
 ;
;единичные элементы:
 такой, что
такой, что
закон Де Моргана, [39]:
 ,
, (2.20)
(2.20)
Эта
система, из 8 аксиом, образует дистрибутивную
структуру с единственными единичными
элементами относительно операций
суммирования (+) и умножения( ).
К сведению, булева алгебра [40] так
же является дистрибутивной структурой
с дополнениями и с единственными
единичными элементами, относительно
этих же операций. Однако для любого
элементах
в булевой алгебре справедливы равенства:
).
К сведению, булева алгебра [40] так
же является дистрибутивной структурой
с дополнениями и с единственными
единичными элементами, относительно
этих же операций. Однако для любого
элементах
в булевой алгебре справедливы равенства:
 .
(2.21)
.
(2.21)
Данные соотношения для нечеткой алгебры, вообще говоря, не верны. Таким образом, любая булева алгебра является нечеткой, но не наоборот.
В
данном изложении мы будем пользоваться
конкретной нечеткой алгеброй, которая
определяется системой: Z
= <[0,1],+,*, >
, где в качестве операций сложения и
умножения служат соответственно операция
взятия максимума и минимума, а дополнение
определяется как
>
, где в качестве операций сложения и
умножения служат соответственно операция
взятия максимума и минимума, а дополнение
определяется как
 .
.
Единственными
единичными элементами
 служат соответственно 0 и 1, которые при
любыхx
удовлетворяют равенствам:
служат соответственно 0 и 1, которые при
любыхx
удовлетворяют равенствам:
 .
.
Пусть, как и ранее, Ω = {x} – пространство объектов, а А и В – два нечетких множества в Ω.
В близком соответствии с терминологией Заде, введем следующие понятия:
Равенство
А=В
определим как А=В .
.
Нечеткое
множествоА
содержится в множестве В*(А ),
тогда и только тогда, когда
),
тогда и только тогда, когда

Нечеткое
множество являетсядополнением
нечеткого множества А,
тогда и только тогда, когда
являетсядополнением
нечеткого множества А,
тогда и только тогда, когда

Объединением
двух нечетких множеств А
и В
из Ω назовем множество А+В
с функцией принадлежности
 .
.
Пересечением
двух множеств А
и В
из Ω назовем множество А В
с функцией принадлежности
В
с функцией принадлежности .
.
Далее,
вместо термина,«степень принадлежности
переменной к множеству», будем употреблять
- термин «нечеткая переменная». Условимся
так же опускать символ
 ,
то есть, вместо
,
то есть, вместо ,
будем писатьx
,
будем писатьx y.
y.
Совершенно
очевидно, что, среди бесконечного числа
разных способов присвоения переменным
степени принадлежности конечному
множеству, существует лишь конечное
число двоичных способов (то есть,
присвоения всем переменным значения 0
и 1). Л. Заде определяет нечеткое отношение
R
как нечеткое множество упорядоченных
пар. Таким образом, если
 совокупности
объектовx
и
y,
то нечеткое отношение из X
в Y
– это нечеткое подмножество прямого
произведения
совокупности
объектовx
и
y,
то нечеткое отношение из X
в Y
– это нечеткое подмножество прямого
произведения ,
характеризуемое функцией принадлежности
(характеристической функцией)
,
характеризуемое функцией принадлежности
(характеристической функцией) которая
каждой паре (x,
y)
ставит в соответствие «степень
принадлежности»
которая
каждой паре (x,
y)
ставит в соответствие «степень
принадлежности»
 кR.
Для простоты предположим, что областью
значения функции
кR.
Для простоты предположим, что областью
значения функции
 служит отрезок [0,1], а число
служит отрезок [0,1], а число будем
называть силой отношения междуx
и
y.
будем
называть силой отношения междуx
и
y.
Областью
определения,
(domain,
domR)
нечеткого отношения R,
назовем НМ с функцией принадлежности

 .
(2.22)
.
(2.22)
Аналогично,
областью
значений
(range,
ranR)
отношения R,
назовем нечеткое множество с функцией
принадлежности

 .
(2.23)
.
(2.23)
Высотой h(R) – называется число h(R):
 (2.24)
(2.24)
Нечеткое отношение называется нормальным, если h(R)=1, и субнормальным, если h(R)<1.
Носителем
S(R)
отношения
R
назовем четкое подмножество прямого
произведения X×Y,
на
котором
 .
.
Замечание
1:
если X
и Y
– конечные множества, то функцию
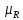 можно представить в виде матрицы, (x,y)
–й элемент которой равен
можно представить в виде матрицы, (x,y)
–й элемент которой равен

2.9.Нечеткие иерархические отношения
По существу обобщением понятия эквивалентности служит понятие «сходство» введенное Заде. Отношением сходства S в Ω называется нечеткое отношение, которое:
рефлексивно, то есть
 = 1, тогда и только тогда, когдаx
= 1, тогда и только тогда, когдаx
симметрично, то есть
 ,
, ;
;транзитивно, то есть

Отношение несходства D можно определить как дополнение к S с функцией

Если
функцию
 интерпретировать, какрасстояние
d(х,y),
то из транзитивности отношения S
следует:
интерпретировать, какрасстояние
d(х,y),
то из транзитивности отношения S
следует:
 .
(2.25)
.
(2.25)
Поскольку
 = 1-MAX[d(х,y),
= 1-MAX[d(х,y), то,
можнозаключить,
что d(x,z)
то,
можнозаключить,
что d(x,z) MAX,
MAX, ],
], ;
откуда следует неравенство треугольника.
;
откуда следует неравенство треугольника.
Определим отношение близости, описывающее субъективное сходство как рефлексивное, симметричное, но необязательно транзитивное, n-местное нечеткое отношение:
 ,
где (2.26)
,
где (2.26)
 кратное
декартово произведение X
на себя; x,y
кратное
декартово произведение X
на себя; x,y
Тогда,
для всех x,y и всех
и всех
 ,
0
,
0
Отсюда следует существование предела:

так
как, в соответствии с принципом монотонной
сходимости, для любого
 найдется
такое целое числоN,
что
найдется
такое целое числоN,
что
 ,
при всехn>N.
,
при всехn>N.
Поскольку последовательность не убывающая и ограничена, как сверху, так и снизу, указанный предел существует в силу следующей теоремы:
Теорема1: ограниченная, неубывающая последовательность {аi} имеет предел равный наименьшему из чисел, которое не меньше любого из аj;
Определение
2:
пусть x
и y
два элемента из множества Ω, а
 определенное
выше,n-местное
отношение.
определенное
выше,n-местное
отношение.
Назовем
близостью
этих элементов число
 из
отрезка [0,1], удовлетворяющее равенству:
из
отрезка [0,1], удовлетворяющее равенству:
 (2.27)
(2.27)
Определение
3:
пусть
 .
Тогда будем говорить, что
.
Тогда будем говорить, что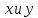 находятся
в пороговом отношении
находятся
в пороговом отношении ,
тогда и только тогда, когда
,
тогда и только тогда, когда

Теорема
2:
 [
[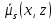 ]
]
Теорема доказана.
Теорема 3: Пороговое отношение является отношением сходства на Ω.
Доказательство:
xRTx
 ,
поскольку
,
поскольку
1= ,
,
xRTy, тогда и только тогда, когда yRTx, так как

Из xRTy и yRTz следует xRTz, так как
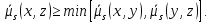
Теорема доказана.
Заметим, что введение описанных выше отношений аналогично представлению о множествах α-уровня Rα отношения R (обычные четкие множества из декартова произведения X×Y), развитому Заде Л.
Теорема
4: Пусть T1 тогда
отношение RT
порождает
подразбиение, порождаемое отношением
тогда
отношение RT
порождает
подразбиение, порождаемое отношением .
.
Доказательство:


Теорема доказана.
Легко
видеть, что если
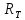 и
и - пороговые отношения, порожденные
соответственно функциями принадлежности
- пороговые отношения, порожденные
соответственно функциями принадлежности и
и и
и то
разбиение по
то
разбиение по является подразбиением разбиения
по
является подразбиением разбиения
по Функция
Функция служитфункцией
расстояния,
поскольку:
служитфункцией
расстояния,
поскольку:
 при
при


 ,
так как
,
так как

2.10.Естественность операций max и min
После
появления понятия о нечетком множестве
вышла работа Беллмана Р. и Гирца М. [41],
посвященная методологическому обоснованию
определений Заде Л. Там было показано,
что операции max
и min,
не только естественны, но, что при
достаточно разумных предположениях,
они и единственно возможны. В этой
превосходной работе показано, что
функция принадлежности, которая служит
количественным выражением степени
субъективного доверия к простым
высказываниям, налагает естественные
ограничения на субъективную истинность
составных высказываний. Так, например,
при возрастании субъективной оценки
 субъективная истинность таких высказываний
«
субъективная истинность таких высказываний
« »
и «
»
и « »,
не должна уменьшаться. Очевидно, что
для оценки высказывания «
»,
не должна уменьшаться. Очевидно, что
для оценки высказывания « »
требуется больше, а для оценки высказывания
«
»
требуется больше, а для оценки высказывания
« »
меньше данных, чем для оценки только
одного
»
меньше данных, чем для оценки только
одного .
Беллман Р. и Гирц М. показали, что в
субъективных оценках операцииmax
и min
не только естественны, но при разумных
предположениях и единственно возможны.
Следует отметить, что при ослаблении
условия «все или ничего», понятие
отрицания по необходимости становится
нечетким. При этом между высказываниями
«х и не x»
уже нет столь четкой границы. Отсюда
возникает вопрос, каким естественным
условиям должна удовлетворять функция
N,
связывающая истинность высказывания
«х и не x»?
Иными словами, как следует выбирать N
в равенстве
.
Беллман Р. и Гирц М. показали, что в
субъективных оценках операцииmax
и min
не только естественны, но при разумных
предположениях и единственно возможны.
Следует отметить, что при ослаблении
условия «все или ничего», понятие
отрицания по необходимости становится
нечетким. При этом между высказываниями
«х и не x»
уже нет столь четкой границы. Отсюда
возникает вопрос, каким естественным
условиям должна удовлетворять функция
N,
связывающая истинность высказывания
«х и не x»?
Иными словами, как следует выбирать N
в равенстве
 (
( )=N[
)=N[ ?
?
Для
того, чтобы обычная теория множеств
оставалась частным случаем теории
нечетких множеств, необходимо потребовать,
чтобы N(0)
стало равным 1, а N(1)
= 0 и N[N( =
= и, чтобы функцияN
была непрерывной и строго монотонно
убывающей, так как субъективная оценка
высказывания «не x»
должна уменьшаться с ростом оценки
высказывания «x».
В практических приложениях разумно
пользоваться определением
и, чтобы функцияN
была непрерывной и строго монотонно
убывающей, так как субъективная оценка
высказывания «не x»
должна уменьшаться с ростом оценки
высказывания «x».
В практических приложениях разумно
пользоваться определением
 .
Это определение и стало использоваться
в теории нечетких множеств. Следует
отметить, что специальные меры нечетких
множеств можно описывать и, так
называемыми, лингвистическими переменными
предложенными Заде Л. [15].
.
Это определение и стало использоваться
в теории нечетких множеств. Следует
отметить, что специальные меры нечетких
множеств можно описывать и, так
называемыми, лингвистическими переменными
предложенными Заде Л. [15].
2.11.Нечеткая статистика
Мотивировка - обычно неточность и неопределенность рассматривают, как случайные статистические характеристики и учитывают их с помощью методов теории вероятностей. В реальных ситуациях неточность, часто обусловлена не только наличием случайных переменных, но и принципиальной невозможностью работать с точными данными (их просто нет, или очень мало), из-за сложности системы или неточности ограничений и цели. Это возникло в связи с необходимостью решения труднорешаемых проблем и задач. Сегодня в реальных задачах стали обращать внимания на классы объектов с нечетко определенными границами. В связи с появлением теории Заде, неточность стали выражать таким образом, что объект может либо принадлежать, либо не принадлежать какому-то определенному классу, или же иметь к нему некоторую промежуточную степень принадлежности. Отрезок [0,1] позволил ученым решать задачи именно в этом интервале, то, что раньше мы не могли себе позволить.
Интуитивно
понятия неточности и вероятности кажутся
сходными. Это сходство подчеркивается
и подтверждается тем обстоятельством,
что интервал, изменяющий степени
принадлежности
 к
нечетким множествам, совпадает с отрезком
[0….1]. Однако, между понятиями «нечеткость»
и «вероятность» имеются существенные
отличия, вероятность – объективная
характеристика и выводы теории
вероятностей могут быть экспериментально
обоснованы, с другой стороны степень
принадлежности является субъективной
характеристикой. Т.е., маловероятно, с
позиции теории вероятностей, чтобы
событие имело малую вероятность, точнее,
имело малую степень принадлежности. На
самом деле тщательный анализ нечетких
переменных показывает, что их можно
разбить на два класса: статистический
и не статистический. Отличие теории
нечетких множеств состоит также и в
том, что в ней, в отличие от теории
вероятностей, в качестве основных
операций, используются операции
нахождения минимумов и максимумов,
поэтому возможным обоснованием
эффективности методов теории нечетких
множеств может послужить решение на
основе этой теории достаточно большего
числа практических задач. Как известно,
теорию вероятностей, как систематическую
науку, можно построить на базе 3-х аксиом,
совпадающих с соответствующими аксиомами
теории меры. Необходимость развития
нечеткой статистики обусловлена её
методологической и содержательной
связью с субъективной вероятностью. С
субъективной точки зрения вероятность
представляет собой степень уверенности
в данном событии, которая возникает у
индивидуума, на основе известных ему
данных. Такая точка зрения (известная
как индивидуальная или оценочная
вероятность) описана Яковом Бернулли
[42], который определил вероятность, как
степень доверия высказыванию, в истинности
которого мы не можем быть полностью
убеждены. Эта степень доверия зависит
от тех знаний, которыми может располагать
индивидуум и, следовательно, различна
для разных индивидуумов. Операции с
такой вероятностью лучше всего описывать,
как искусство угадывать, точнее,
описывать, как искусство угадывания.
Неясность суждений, основанных на
субъективном анализе, обусловливает и
те трудности, которые возникают в
применениях субъективной вероятности.
Общепризнано, что постулаты субъективной
вероятности не применимы во многих
интересных и полезных, но не точных,
теориях современной науки. Субъективную
вероятность можно рассматривать, как
индивидуальный способ трактовки тех
аспектов объективных данных, которые
доступны индивидуальному суждению.
Однако такие суждения не аддитивны, так
как поведение человека часто находится
в противоречии с предположением теории
субъективной вероятности об аддитивности
мер, используемых человеком в критериях
оценки событий.
к
нечетким множествам, совпадает с отрезком
[0….1]. Однако, между понятиями «нечеткость»
и «вероятность» имеются существенные
отличия, вероятность – объективная
характеристика и выводы теории
вероятностей могут быть экспериментально
обоснованы, с другой стороны степень
принадлежности является субъективной
характеристикой. Т.е., маловероятно, с
позиции теории вероятностей, чтобы
событие имело малую вероятность, точнее,
имело малую степень принадлежности. На
самом деле тщательный анализ нечетких
переменных показывает, что их можно
разбить на два класса: статистический
и не статистический. Отличие теории
нечетких множеств состоит также и в
том, что в ней, в отличие от теории
вероятностей, в качестве основных
операций, используются операции
нахождения минимумов и максимумов,
поэтому возможным обоснованием
эффективности методов теории нечетких
множеств может послужить решение на
основе этой теории достаточно большего
числа практических задач. Как известно,
теорию вероятностей, как систематическую
науку, можно построить на базе 3-х аксиом,
совпадающих с соответствующими аксиомами
теории меры. Необходимость развития
нечеткой статистики обусловлена её
методологической и содержательной
связью с субъективной вероятностью. С
субъективной точки зрения вероятность
представляет собой степень уверенности
в данном событии, которая возникает у
индивидуума, на основе известных ему
данных. Такая точка зрения (известная
как индивидуальная или оценочная
вероятность) описана Яковом Бернулли
[42], который определил вероятность, как
степень доверия высказыванию, в истинности
которого мы не можем быть полностью
убеждены. Эта степень доверия зависит
от тех знаний, которыми может располагать
индивидуум и, следовательно, различна
для разных индивидуумов. Операции с
такой вероятностью лучше всего описывать,
как искусство угадывать, точнее,
описывать, как искусство угадывания.
Неясность суждений, основанных на
субъективном анализе, обусловливает и
те трудности, которые возникают в
применениях субъективной вероятности.
Общепризнано, что постулаты субъективной
вероятности не применимы во многих
интересных и полезных, но не точных,
теориях современной науки. Субъективную
вероятность можно рассматривать, как
индивидуальный способ трактовки тех
аспектов объективных данных, которые
доступны индивидуальному суждению.
Однако такие суждения не аддитивны, так
как поведение человека часто находится
в противоречии с предположением теории
субъективной вероятности об аддитивности
мер, используемых человеком в критериях
оценки событий.
2.12. Совместимость и нечеткое ожидание
В
классической теории вероятностная
система описывается тройкой (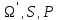 ),
где
),
где -
произвольное множество исходов,S
– множество событий, P
–вещественная функция, определенная
-
произвольное множество исходов,S
– множество событий, P
–вещественная функция, определенная
 и такая, что:
и такая, что:
 ;
;
2)
P( )
= 1;
)
= 1;
3)
Если A1,A2
....An
-
любая последовательность попарно не
пересекающихся множеств из
 ,
то:
,
то:
 (2.28)
(2.28)
Функция Р, удовлетворяющая этим трем условиям, называется вероятностной мерой, а элементы множества S- событиями.
Свойство 3) известно, как аксиома счетной аддитивности:
во-первых, событие может быть неточным, нечетким событием в том смысле, что оно принадлежит нечеткому множеству;
во-вторых, если A четкое, т.е. вполне определенное событие, функция P(A) может быть плохо определена, т.е., например: неясные оценки точных событий, расплывчатые предсказания.
Обсудим полноту вероятностной системы. Очевидно, что в конечных пространствах вероятность P(A) события A равна сумме вероятностей всех выборочных точек, составляющих множество A. Однако следует иметь в виду, что полнота классической структуры ограничивает каждую выборочную точку вполне определенным множеством. Поэтому в предлагаемых здесь мере и исчислении требование полноты, в конечном счете, не выполняется.
Среди
теоретиков постоянно ведутся споры о
природе соотношений между вероятностной
математикой и теми событиями, в описании
которых она применяется. Наиболее
употребительным является частотный
подход, основанный на эксперименте с
повторяющимися испытаниями, в которых
регистрируют отношения числа испытаний
с желательным исходом к общему числу
испытаний. Предельное значение этого
отношения при неограниченном увеличении
числа испытаний и считают вероятностью
события. Если z-
один элемент из полной группы несовместимых
исходов,
 -
число испытаний с этим исходом, аn
– общее число испытаний, то вероятность
z
равна:
-
число испытаний с этим исходом, аn
– общее число испытаний, то вероятность
z
равна:
 ,
, равно
по определению. (2.29)
равно
по определению. (2.29)
Если
предела нет, то величина
 считается неопределенной.
считается неопределенной.
Одна из принципиальных трудностей частотного подхода состоит в том, что ситуации, которые случаются лишь однажды, в рамках этого подхода, не имеют никакого смысла, т.к. для определения вероятности необходимы совокупности или последовательности событий. С этой точки зрения вероятность одиночного события, например, выпадение орла при конкретном бросании монеты должна быть либо неопределённой, либо равной 0 или 1, в зависимости от того, как падает монета. Аналогично, если последовательно придерживаться частотного подхода, то следует отвергнуть и априорные вероятности, поскольку они определяются не на основе испытаний, а из дополнительных соображений, например, по данным о числе граней игральной кости.
В рамках еще одного из известных подходов рассматривают меру того, в какой степени одно утверждение подтверждается другими утверждениями. Эта мера называется логической вероятностью. Она определена даже для ложных утверждений, поскольку описывает взаимосвязи между утверждениями, а не сами эти утверждения. Логический подход правомерен, когда ситуацию можно свести к множеству одинаково очевидных случаев.
В настоящее время, среди специалистов по принятию решений, устанавливается некоторый единый взгляд на вероятность, который явно допускает в ней наличие субъективной компоненты. Элемент человеческого суждения присутствует даже, казалось бы, в наиболее эффективных процедурах количественного определения вероятностей. При таком подходе не требуется, чтобы вероятность имела одно правильное значение, если это логически не очевидно. Суть субъективной точки зрения заключается в том, что вероятность тесно связана с индивидуальным принятием решения и отражает степень уверенности индивидуума в том, что данное событие действительно произойдёт. В этом смысле степень уверенности интерпретируется скорее как нечто, способствующее склонности к действию, а не как интенсивность ощущений (Бехтерева Н.П.), [43].
Некоторая субъективность присутствует и в частотном подходе, она связана с необходимостью предположения о существовании предела относительно частоты и с переоценкой вероятности, если для этого есть очевидные основания. Все это равносильно некоторому индивидуальному решению.
В каких случая стоит оценивать вероятность? Предполагается, что это необходимо, при наличии соответствующих данных, при этом их следует использовать для корректировки вероятностей, т.е., по существу, для количественного представления связанной с этим субъективной оценкой. Для описания этого процесса мы вводим понятие степень принадлежности, которая характеризует величину, зависящую от параметра подлежащего субъективной человеческой оценке. Следует отметить, что Сугэно М. [21] и Терано Т. [44] уже использовали нечеткие интегралы на отрезке [0,1], для представления своих оценок субъективных нечетких объектов. Кроме того, в настоящее время применяют это понятие для идентификации человеческих характеристик, а так же для макрооптимизации с использованием условных моделей и оценивания нечетких объектов.
Определение
4:
Пусть B
– борелевское поле ( подмножеств действительной числовой
оси Ω.
подмножеств действительной числовой
оси Ω.
Функция
множеств
 ,
определенная наВ,
называется нечеткой мерой, если она
удовлетворяет следующим условиям:
,
определенная наВ,
называется нечеткой мерой, если она
удовлетворяет следующим условиям:


если

если {
 }
– монотонная последовательность, то
}
– монотонная последовательность, то .
.
Очевидно,
что
 ,
кроме того, если
,
кроме того, если ,
а {
,
а {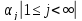 }
– монотонная последовательность, то
}
– монотонная последовательность, то .
.
Условия 1 и 2 означают, что нечеткая мера – ограниченная и отрицательная функции. Из условия 3 следует, что она монотонна (аналогично конечно-аддитивным мерам теории вероятностей), а из условия 4 следует непрерывность, если Ω - конечное множество, то непрерывность необязательна.
Определение
5:
Система { }
называется пространством с нечеткой
мерой; ее аналогом в теории вероятностей
служит система
}
называется пространством с нечеткой
мерой; ее аналогом в теории вероятностей
служит система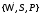 .
.
Функция
 называется
нечеткой мерой на (
называется
нечеткой мерой на ( Нечеткая мера определена на интервалах
действительной оси. Ясно, что, если
Нечеткая мера определена на интервалах
действительной оси. Ясно, что, если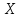 - функция принадлежности множеству А,
то для описания функции
- функция принадлежности множеству А,
то для описания функции
 [
[ необходимо использовать некоторую
функцию
необходимо использовать некоторую
функцию
Далее
рассматривается лишь случай, когда А –
четко определенное множество, поэтому
вместо
 будем
использовать функцию
будем
использовать функцию
Пусть
задано отображение
 и множество
и множество

Функция
 - называется В-измеримой (или измеримой
по Э.Борелю [18]), если
- называется В-измеримой (или измеримой
по Э.Борелю [18]), если при
всехT
при
всехT
Определение
6:
пусть
 - В-измеримая функция. Нечетким ожиданием
FEV
(fuzzyexpectedvalue)
функции
- В-измеримая функция. Нечетким ожиданием
FEV
(fuzzyexpectedvalue)
функции
 на множестве А, по мере
на множестве А, по мере называется
Sup{min[T,
называется
Sup{min[T, ]},
]}, .
.
Замечание
2:
В-измеримая функция
 называется функцией совместимости.
называется функцией совместимости.
Нечеткое
ограничение (разумеется, субъективное)
описывается функцией совместимости
 которая
каждому значению базовой переменной
ставит в соответствие число из отрезка
которая
каждому значению базовой переменной
ставит в соответствие число из отрезка ,
характеризующее совместимость этого
значения с данным нечетким ограничением.
,
характеризующее совместимость этого
значения с данным нечетким ограничением.
Контрольные вопросы и задания для самостоятельной работы по главам 1 и 2
2.1. Понятие знаний, место и роль, которую играют языки представления знаний в системах, основанных на использовании знаний?
2.2.Экспертная система-это интеллектуальная программа, способная делать логические выводы на основании знаний в конкретной предметной области?
2.3. Перечислите требования к экспертным системам, качествам экспертов и функции, которые должны выполнять ее структурные элементы?
2.4.Кто ввел понятие инженерии знаний и что такое язык представления знаний?
2.5.Каким образом представляются и используются знания в системах, основанных на концепциях искусственного интеллекта и инженерии знаний?
2.6. Каким образом и с помощью чего представляются модели представления знаний?
2.7. Как объяснить особенности преимуществ человеческой логики в разработке интеллектуальных моделей с нечеткой структурой?
2.8. От чего зависит и каким образом происходит восприятие и обработка информации у человека. Что понимается под знанием?
2.9. Объясните основные методы и средства обработки, хранения, передачи и накопления знаний?
2.10. Как ВЫ понимаете и представляете обработку, хранение, передачу и накопление знаний?
2.11. Как ВЫ понимаете и представляете систему с базами знаний, основанные на совокупности правил вида «ЕСЛИ-ТО»?
2.12. Синтаксис и семантика логики первого порядка?
2.13. Теория нечетких множеств - основа псевдофизических логик?
2.14. Нечеткая логика?
2.15. Логика смысла?
2.16. Понятие лингвистической переменной?
2.17. Примеры псевдофизических логик: пространственная и временная логики (как средства представления пространственной и временной информации)?
2.18. Модели для логики первого порядка?
2.19. Использование логики первого порядка?
2.20. Инженерия знаний с применением логики первого порядка?
2.21. Классификация задач анализа данных?
2.22. Базовые гипотезы, лежащие в основе методов анализа данных?
2.23. Статистические решающие правила?
2.24. Построение решающих правил по конечной выборке?
2.25. Выбор системы информативных признаков?
2.26. Согласование разнотипных шкал?
2.27. Распознавание образов в пространстве знаний?
2.28. Анализ мер сходства?
Глава 3. Нечеткие технологии создания информационных систем. Способы получения информации и ее реализации для оценивания состояния агрегатов
Формализация диагностического эксперимента и требования к измерениям
Пусть система измерений организована правильно, тогда каждому испытываемому объекту (например, это энергоустановка) можно сопоставить некоторую функцию f обобщенного аргумента X (координаты состояний, времени, пространства, физические параметры и т.д.), заключающую в себе некоторую информацию об объекте, которую необходимо извлечь в процессе эксперимента. На уровне понятия «черного ящика» эту процедуру можно назвать эпизодом «заглянуть в черный ящик» [45]. Пусть
f(X)F, (3.1)
где F- признаковое пространство.
Предположим также, что имеется эталонная (базовая или нормативная) функция состояния данного объекта:
m(X)Ф. (3.2)
Введем, далее, некоторый оператор W, такой, что
f=W[m(X)] (3.3)
где функции f и f~ являются «близкими» в F (в дальнейшем, по тексту и в расчетах будем использовать слово «похожесть» [9,46], соответствующее слову «близкие» и подтверждаемое его метрикой).
Критерий близости (похожести) [46] в принципе должен выбираться и подтверждаться исследователем решаемой задачи, исходя из конкретных условий задачи (или проблемы). Это условие характерно для решения задач диагностики различных агрегатов (или других объектов).
Агрегатами мы называем здесь самостоятельно функционирующие технологические операционные узлы (блоки энергоустановки), например:
- система автоматического регулирования и защиты турбины (САРиЗ), котла, генератора, вакуумной системы (точнее, низко потенциальный комплекс, НПК турбоустановки) или любого другого механизма объекта.
Если ввести в F определенную метрику, то тогда можно будет эту меру близости (похожести) между элементами множеств определить как расстояние между f и f~ в F, т.е. величину
f,W(m)]. (3.4)
Таким образом, математический смысл операции измерения заключается в определении оператора W удовлетворяющего неравенству
f,W(m)]F, (3.5)
где F – величина ошибки.
В частном случае, если «расстояние» определено как максимум модуля разности между f и f~ , получаем:
maxf-W(m)]F. (3.6)
Так
как любая измерительная система должна
быть конечной, то оператор W должен
определяться конечным числом характеристик,
являющихся функционалами от f
и
W.
В результате, измерение f,
по отношению к m,
будет сводиться к получению некоторой
совокупности чисел
 ,
определяющихf
с
точностью до F
по
критерию
,
определяющихf
с
точностью до F
по
критерию .
.
В представленной таким образом формализации, оператор W будет выражать всю совокупность действий, которые нужно выполнять, чтобы установить взаимно-однозначное соответствие, между измеряемой величиной f и эталонной m. Однако, как известно, экспериментатор или эксперт-диагност, имеют дело не с f, а с некоторой промежуточной величиной Z, являющейся результатом взаимодействия исследуемого состояния агрегата и измерительными приборами. В связи с этим разделим оператор W на два последовательных оператора, отображающих основные характеристики проводимого диагностического эксперимента: наблюдение и обработку данных.
Сигнал Z(X) на выходе первичного преобразователя (датчика) является результатом наблюдения. Оператор преобразования H будет связывать экспериментальные данные Z(X) с измеряемой величиной f соотношением
Z=Hf. (3.7)
Массив данных (в векторной форме) поступает на обработку в некоторое устройство, вычисляющее оператор G из уравнения
 Gm]
F
(3.8)
Gm]
F
(3.8)
и обрабатывается по специальной программе интеллектуального анализа данных из программного комплекса SKAIS, (рис. 3.1-3.4), [9].

Рис. 3.1. Функционально – структурная модель диагностики энергоустановок
ТЭС.
Так как Н является оператором первичного преобразователя, что считается условно известным, а измерительная система тарирована (и проверена), т.е. выполняет измерения достоверно, не отклоняясь от заданной погрешности, то задача измерения f будет сводиться к определению оператора G и последующему решению обратной задачи следующего вида
Hf= =Gm.
(3.9)
=Gm.
(3.9)

Рис. 3.2. Модульная блок-схема статистической обработки
диагностической информации, снятой с энергоустановки.

Рис. 3.3. Блок – схема программы BRAK1: Расчет и отбраковка
диагностической информации снятой с энергоустановки.

Рис. 3.4.Блок-схема алгоритма обработки информации для определения
диагностических признаков и оценки состояния агрегата.
Методология моделирования и программная среда SKAIS [9]– система анализа, обработки и использования четких и размытых знаний для оценивания технического состояния энергоустановок (или других объектов) и перевода их на «мягкую» эксплуатацию, т.е. обслуживание по фактическому состоянию, выполняется на основе системного подхода к анализу и моделированию сложных систем (рис. 3.5, 3.6):

Рис. 3.5. SKAIS - подсистема диагностики состояния
турбоустановки в контуре управления электростанции.
3.2. Обработка нечетких данных как неопределенных чисел
Методология представления агрегата в виде комплексного механизма
Прогрессивным и предлагаемым новым в диагностировании энергоустановок электростанций (или любого другого сложного агрегата) является отказ от рассмотрения ее в виде совокупности элементов и узлов, которые по разным причинам (зависимым и независимым) могут выйти из строя. Для этого автором разработана и предложена методология представления энергоустановки (так же возможно и для другого сложного агрегата) в виде комплексного механизма[9, 46]. Работа механизма моделируется в разрезе четырех полей состояний: колебаний, температур, режимов и времени, которые определяют его диагностические состояния (рис. 3.6). Это позволяет рассматривать происходящий или развивающийся отказ в работе механизма в целом как явление прецессии (лат. praecessio–предшествование), вследствие которого механизм переходит из одного состояния (состояние устойчивого равновесия) в другое (пред - и дефектное) состояние. При этом становится понятным физический процесс развития и возникновения дефекта, распознаваемый по предшествующим ему событиям и признакам, т.е. текущему состоянию механизма. В результате, вместо поиска отдельных повреждений элементов и узлов механизма, основное внимание сосредоточивается на изучении возмущающих воздействий со стороны дефектов, под влиянием которых механизм (его структура) переходит из одного состояния в другое (явление прецессии).

Рис.
3.6. Интерпретация структуры механизма
системы :
:
 .
(3.10)
.
(3.10)
Таким образом, диагностирование становится динамическим методом определения состояния, связанным с исследованием протекающих в нем процессов и причин, вызывающих появление и развитие дефектов. Такой подход позволяет представлять в виде сложной, открытой, но распределенной и хорошо моделируемой, системы весь механизм с его повреждениями и развивающимися дефектными состояниями и отказами.
Это существенно расширяет объем знаний и представление оперативного и обслуживающего персонала информацией о работе механизма, его предельных возможностях и ограничениях, при выполнении диспетчерского графика нагрузки и, в результате, оценить и продлить «срок жизни» в щадящем режиме, определить его фактический ресурс с необходимой степенью вероятности. При использовании известных методов обнаружения, распознавания, оценивания и восстановления разработана эффективная методология моделирования и программная среда (SKAIS) – система анализа, обработки и использования четких и размытых знаний для оценивания технического состояния энергоустановок и перевода их на «мягкую» эксплуатацию, т.е. обслуживание по фактическому состоянию.
В
соответствии с этим, механизм (рис. 3.6)
следует рассматривать, как неизолированную,
открытую, техническую систему
 ,
которая характеризуется: входом
,
которая характеризуется: входом ,
выходом
,
выходом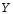 ,
внешней средой
,
внешней средой и внутренней структурой
и внутренней структурой .
Такой механизм включает: полную
информацию о состоянии
.
Такой механизм включает: полную
информацию о состоянии ,
работоспособности
,
работоспособности ,
признаках состояния
,
признаках состояния ,
неисправностях
,
неисправностях ,
(рис.3.6,3.7). Изменение состояния такой
технической системы происходит во
времени
,
(рис.3.6,3.7). Изменение состояния такой
технической системы происходит во
времени ,(3.10).
Новая методология позволяет использовать
при идентификации состояний четкие и
размытые знания с целью предупреждения
отказа. Решение уравнений связей
механизма как системы, моделирование
зависимости технико-экономического
уровня системы от различных параметров
и времени - конечная цель разработки и
прогноза эволюции механизма энергоустановки,
вплоть до его утилизации. Для этого
анализируются два основных состояния
механизма - как объекта эксплуатации и
как объекта производства. Далее, для
анализа, выделяется определенная часть
системы и выполняется её оптимизация,
т.е. приведение объекта в оптимальное
состояние в соответствии с
целевой функцией работы.
При этом решаются как минимум две
задачи оптимизации:
,(3.10).
Новая методология позволяет использовать
при идентификации состояний четкие и
размытые знания с целью предупреждения
отказа. Решение уравнений связей
механизма как системы, моделирование
зависимости технико-экономического
уровня системы от различных параметров
и времени - конечная цель разработки и
прогноза эволюции механизма энергоустановки,
вплоть до его утилизации. Для этого
анализируются два основных состояния
механизма - как объекта эксплуатации и
как объекта производства. Далее, для
анализа, выделяется определенная часть
системы и выполняется её оптимизация,
т.е. приведение объекта в оптимальное
состояние в соответствии с
целевой функцией работы.
При этом решаются как минимум две
задачи оптимизации:
1) выбор наилучшего варианта из возможных состояний системы;
2) выбор оптимального поведения системы.
Первая задача решается для статической системы, вторая задача- для динамической системы. Для такого сложного механизма, как турбоустановка, задача определения состояния решается как многокритериальная. В качестве новой концепции представления механизмов, как системы, на ТЭС рассматриваются важнейшие аспекты эволюции энергоустановки: «назначение механизма → эксплуатация по назначению → деградация → утилизация», (рис. 3.7). Эти аспекты (эксплуатация и деградация, вплоть до утилизации и, даже, разрушение) особенно характерны для тепловых машин, т.е. механизмов выполняющих огромную физическую и механическую работу при преобразовании тепловой формы энергии в электрическую.

Рис. 3.7. Концепция «мягкого регулирования» эксплуатации энергоустановки ТЭС, с учетом ее «времени жизни» в эксплуатации и отработке.
Общая постановка задачи «оценивание технического состояния энергоустановки и принятие решений по составленным диагнозам об управлении эффективной работы механизма, (рис.3.5-3.8), с использованием нечеткой информации в моделях идентификации», представляется нечеткими уравнениями в отношениях.

Рис. 3. 8. Зоны управления эффективной работы механизма.
Пусть
в результате предварительного анализа
получено некоторое множество классов
 технического состояния объекта контроля
(рис. 3.6),
технического состояния объекта контроля
(рис. 3.6),
 ,
,
 ,
(3.11) отображаемое в
виде нечеткого множества с соответствующими
функциями принадлежности
,
(3.11) отображаемое в
виде нечеткого множества с соответствующими
функциями принадлежности :
:
 .
(3.12)
.
(3.12)
Представление
энергоустановки в виде комплексного
механизма, (рис. 3.6, 3.7), как
уравнение связей объекта, выполнено
следующим образом:
в статике (3.13)
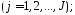
и
динамике: 
(3.14)

где

Математическая
модель эксплуатации механизма:
(3.15)
Здесь:-
-параметры внутренней структуры
механизма;

-параметры
на входе механизма;
-параметры
на выходе механизма;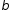

-параметры эффективности механизма;
-параметры
производительности механизма;
-количество
внутренних параметров;
-количество
внешних параметров;
-
индексы эффективности эксплуатации
механизма.
Тогда состояние объекта контроля диагностируемого механизма представим декартовым произведением пространств входа и выхода:
 ,
(3.16)
,
(3.16)
где
 - множество входных значений параметров
в объект
- множество входных значений параметров
в объект ;
;
 -
множество выходных значений параметров
из объекта
-
множество выходных значений параметров
из объекта
 ;
;
 -
параметры состояния объекта.
-
параметры состояния объекта.
Ввиду неопределенности знаний об объекте используем нечеткую модель его описания с заданной структурой. Структуру нечеткой модели будем представлять далее как совокупность терм-множеств лингвистических переменных входа и выхода системы, с соответствующими функциями принадлежности и варианта импликации, объединенных управляющим правилом функционирования системы.
При наличии неопределенности в знаниях об объекте его модель отобразим нечетким уравнением в отношениях вида:
 ,
(3.17)
,
(3.17)
где
 - нечеткое множество входа,
(3.18)
- нечеткое множество входа,
(3.18)
 -
нечеткое множество выхода,
(3.19)
-
нечеткое множество выхода,
(3.19)
(заданные
в форме лингвистических переменных с
мощностью множеств (размерностью
системы)
 );
); - отношения конечные входному и выходному
пространствам объекта моделирования;
- отношения конечные входному и выходному
пространствам объекта моделирования; ,
, -
элементы терм-множеств лингвистических
переменных;
-
элементы терм-множеств лингвистических
переменных; - соответствующие функции принадлежности;
- соответствующие функции принадлежности; - символ максиминной композиции Заде
Л. [12-17];
- символ максиминной композиции Заде
Л. [12-17]; -
нечеткое отношение
-
нечеткое отношение в виде управляющего правила “
в виде управляющего правила “ :
ЕСЛИ …, ТО …, “, выражаемого посредством
матрицы нечеткого отношения с элементами
:
ЕСЛИ …, ТО …, “, выражаемого посредством
матрицы нечеткого отношения с элементами
 ,
(3.20)
,
(3.20)
где
 -
операция объединения одноточечных
нечетких множеств
-
операция объединения одноточечных
нечетких множеств и
и ;
; -
вариант импликации;
-
вариант импликации; -
символ логического минимума.
-
символ логического минимума.
Модельное уравнение на языке функций принадлежности будет иметь вид
 (3.21)
(3.21)
Техническое
состояние объекта контроля оцениваем
по реализации определенных признаков
состояния
- диагностических признаков
 .
.
Так как значение диагностических признаков определяется параметрами модели (3.16) и по рис. 3.6, то при аппроксимации неопределенности функционирования объекта нечетким уравнением в отношениях в качестве диагностических признаков принимаем множество управляющих правил

 ,
(3.22)
,
(3.22)
представленных в форме эталонных матриц нечетких отношений
 ,
,
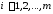 (3.23)
(3.23)
и
являющихся, собственно, параметрами
модели (в общем случае, так как отображение
 не является взаимно однозначным,
не является взаимно однозначным,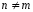 ).
).
Множества
классов технических состояний
 и диагностических признаков
и диагностических признаков находятся между собой в определенном
отношении
находятся между собой в определенном
отношении
 ,
(3.24)
,
(3.24)
то есть, каждое техническое состояние рассматриваемого объекта (турбоустановки) отображается в реализации диагностических признаков, рис. 3.6.
Такое
отношение формализуется далее в виде
соответствующей матрицы отношений.
Принимаем полученное отношение нечетким
и представляем его матрицей нечетких
отношений
 с элементами, идентифицируемыми по
знаниям экспертов. Тогда множество
диагностических признаков
с элементами, идентифицируемыми по
знаниям экспертов. Тогда множество
диагностических признаков также будет нечетким:
также будет нечетким:
 ,
(3.25)
,
(3.25)
 .
(3.26)
.
(3.26)
Здесь:
 - операторы формирования нечеткого
множества, определяемые в виде процедуры
вычисления функций принадлежности
- операторы формирования нечеткого
множества, определяемые в виде процедуры
вычисления функций принадлежности
 ;
(3.27)
;
(3.27)
 -
расстояние между априорно заданными
значениями диагностических признаков
-
расстояние между априорно заданными
значениями диагностических признаков
 и их оценками
и их оценками .
.
В качестве показателя эффективности решения задачи оценивания технического состояния механизма выбираем функцию:
 ,
(3.28)
,
(3.28)
где
 -
обобщенная функция принадлежностиI-го
технического состояния класса
-
обобщенная функция принадлежностиI-го
технического состояния класса
 по параметру
по параметру (мощность энергоустановки, ее КПД-нетто,
удельный расход тепла на отпущенный
кВт
(мощность энергоустановки, ее КПД-нетто,
удельный расход тепла на отпущенный
кВт час
и т.д.);
час
и т.д.);
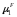 -
априорная функция принадлежности;
-
априорная функция принадлежности;
 -
апостериорная функция принадлежностиI-го
технического состояния, полученная по
результатам измерений путем решения
уравнения, обратного (3.17).
-
апостериорная функция принадлежностиI-го
технического состояния, полученная по
результатам измерений путем решения
уравнения, обратного (3.17).
Критерием максимальной эффективности решения задачи оптимизации оценивания технического состояния турбоустановки принимаем следующую функцию:
 .
(3.29)
.
(3.29)
По изложенной выше формализации определяются исходные данные для решения экстремальной задачи оценивания технического состояния.
Решение задачи оценивания состояния представляется согласно целевой функции вида:
 ,
(3.30)
,
(3.30)
которое
выполняется по алгоритму модели
программного модуля
 по схеме
по схеме (включающему методы: «Монте – Карло»,
случайного поиска, градиентные,
многокритериальные методы, методы
векторной оптимизации и методы нечеткой
оптимизации) из программно-диагностического
комплекса
(включающему методы: «Монте – Карло»,
случайного поиска, градиентные,
многокритериальные методы, методы
векторной оптимизации и методы нечеткой
оптимизации) из программно-диагностического
комплекса рис.3.9:
рис.3.9:

Рис.3.9.
Принципиальная блок-схема модуля
 «OPTIMIZATOR».
«OPTIMIZATOR».
Составляются управляющие правила, отражающие допускаемый диапазон изменения параметров входа и выхода контролируемого объекта.
В результате, получаются для базы знаний продукционные правила вида:
 .
(3.31)
.
(3.31)
Такое условие налагает определенные требования на организацию процедуры измерения параметров системы, по которым контрольные измерения для диагностики состояния следует выполнять в области определения крайних термов лингвистических переменных, как можно ближе к краям диапазонов регулирования (на краях интервалов энергетической характеристики), рис.3.10.
Анализ исходной информации, получаемой в диагностических экспериментах и в процессе контроля и оценивания состояния энергоустановок, и полученный в окончательном диагнозе, представляется в следующем виде:
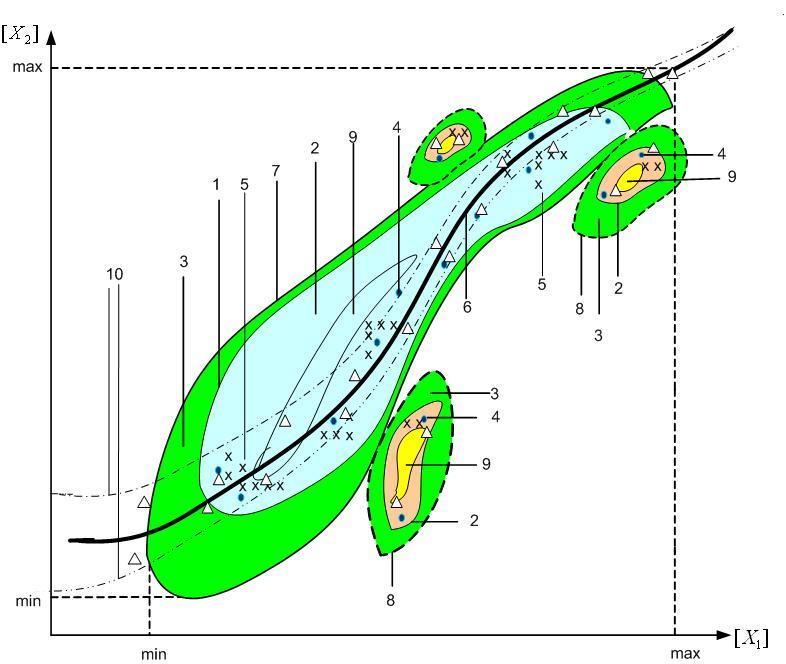
Рис.3.10. Анализ исходной информации с помощью системы распознавания образов для заданного интервала наблюдения за работой энергоустановки.
Здесь
представлен
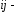 тый
интервал доверия на нагрузочной
характеристике в ее информационном
пространстве:
тый
интервал доверия на нагрузочной
характеристике в ее информационном
пространстве: вектор
наблюдаемых параметров состояния и
оценок суждений экспертов;
вектор
наблюдаемых параметров состояния и
оценок суждений экспертов; вектор
параметров предельных состояний работы
энергоустановки; 1,2 – границы изолированных
областей; 2 – изолированная внутри
интервала область результатов измерений;
3 – зоны неустойчивых подобластей
предельных состояний агрегата на
рассматриваемом интервале нагрузочной
характеристики; 1 - 7, 2 - 8 – границы
подобластей предельных состояний
агрегата; 4 – точки пространства
состояний, к которым сводятся все
численные решения задачи; 5 – точки
наблюдения; 6 – гиперкривая регрессии;
9 – области неопределенности информации;
10 – нечеткие области экспертной
информации; [min
÷ max]
- параметры экспериментального интервала
доверия на интервале наблюдения
нагрузочной характеристики агрегата
и экспертные данные.
вектор
параметров предельных состояний работы
энергоустановки; 1,2 – границы изолированных
областей; 2 – изолированная внутри
интервала область результатов измерений;
3 – зоны неустойчивых подобластей
предельных состояний агрегата на
рассматриваемом интервале нагрузочной
характеристики; 1 - 7, 2 - 8 – границы
подобластей предельных состояний
агрегата; 4 – точки пространства
состояний, к которым сводятся все
численные решения задачи; 5 – точки
наблюдения; 6 – гиперкривая регрессии;
9 – области неопределенности информации;
10 – нечеткие области экспертной
информации; [min
÷ max]
- параметры экспериментального интервала
доверия на интервале наблюдения
нагрузочной характеристики агрегата
и экспертные данные.
Практическое значение. Использование нечеткой информации и применение для ее формализации и обработки методологии искусственного интеллекта повышает качество моделей идентификации, прогнозирования, принятия решений и оптимизации при диагностике состояния и управления турбоустановкой, что позволяет сформировать новую интеллектуальную (экспертную) диагностическую среду, обеспечить представление объекта управления адекватной его состоянию моделью эксплуатации, встроенной в контур управления ТЭС. Это способствует увеличению срока службы оборудования, повышению его эффективности, надежности и готовности выполнять необходимый режим нагрузки, выработке на основе этого дополнительных электро - и теплоэнергии, и позволяют, в результате, получить народнохозяйственный эффект. Принятие эффективных решений и подготовленных рекомендаций для обслуживающего персонала ТЭС, при управлении энергетическими установками с помощью системы поддержки и мониторинга состояния в диагностическом комплексе SKAIS (рис.3.5), обеспечивают производство электро - и теплоэнергии необходимого количества и качества. Что и осуществляется в процессе внедрения за счет поддержки работоспособности, своевременного обнаружения неисправностей и предупреждения развития дефектов и отказов.
3.2.2. Описание исходной информации на языке размытых множеств
Проверка
всех элементов множеств
 и
и ,
с целью
определения их соответствия изложенным
выше требованиям, является одним из
этапов решения поставленной задачи.
Для этого предполагается определение
всех функциональных или статистических
зависимостей между элементами множеств
,
с целью
определения их соответствия изложенным
выше требованиям, является одним из
этапов решения поставленной задачи.
Для этого предполагается определение
всех функциональных или статистических
зависимостей между элементами множеств
 и
и ,
, и
и ,
(рис.3.6). Если известны составы подмножеств
,
(рис.3.6). Если известны составы подмножеств и
и ,
то можно определить зависимости между
,
то можно определить зависимости между и элементами
и элементами ,
между
,
между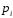 и элементами
и элементами .
Определение функциональных зависимостей
можно осуществлять способами пассивного
или активного экспериментов. В пассивном
эксперименте наблюдения ведутся за
работающим объектом, т.е. комплекс
измерительных операций производится
перед ремонтом или после него. При
проведении активного эксперимента
производится целенаправленное изменение
параметров элементов или ввод различных
неисправностей и измерение значений
определяющих и распознающих параметров.
Найденные зависимости позволяют с
большой достоверностью выделить
подмножества используемых параметров
.
Определение функциональных зависимостей
можно осуществлять способами пассивного
или активного экспериментов. В пассивном
эксперименте наблюдения ведутся за
работающим объектом, т.е. комплекс
измерительных операций производится
перед ремонтом или после него. При
проведении активного эксперимента
производится целенаправленное изменение
параметров элементов или ввод различных
неисправностей и измерение значений
определяющих и распознающих параметров.
Найденные зависимости позволяют с
большой достоверностью выделить
подмножества используемых параметров и
и ,
отвечающих предъявляемым требованиям.
Однако такая методика практически
применима только при небольших мощностях
множеств
,
отвечающих предъявляемым требованиям.
Однако такая методика практически
применима только при небольших мощностях
множеств ,
,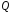 ,
, и
и ,
т.к. количество необходимых зависимостей
быстро растет с увеличением количества
элементов указанных множеств, особенно
при истинности выражений
,
т.к. количество необходимых зависимостей
быстро растет с увеличением количества
элементов указанных множеств, особенно
при истинности выражений и
и (рис.3.6,
3.7). Состав множеств
(рис.3.6,
3.7). Состав множеств и
и можно определять также параметрами,
выбранными эмпирически, с последующей
их проверкой [47, 48]. Однако параметры,
выбранные таким путем, часто функционально
слабо связаны с возникающими
неисправностями агрегатов. Поэтому
приходится искать другие способы, [49],
пока не будет найдено удовлетворительное
решение задачи. Энергетический объект
является сложным и труднодоступным
объектом, особенно в процессе работы
в режиме реального времени. В результате
обслуживания и контроля агрегата
возникает необходимость принятия
решения о состоянии на основе прямых
или косвенных измерений и с учетом
влияния системных связей, [50].
можно определять также параметрами,
выбранными эмпирически, с последующей
их проверкой [47, 48]. Однако параметры,
выбранные таким путем, часто функционально
слабо связаны с возникающими
неисправностями агрегатов. Поэтому
приходится искать другие способы, [49],
пока не будет найдено удовлетворительное
решение задачи. Энергетический объект
является сложным и труднодоступным
объектом, особенно в процессе работы
в режиме реального времени. В результате
обслуживания и контроля агрегата
возникает необходимость принятия
решения о состоянии на основе прямых
или косвенных измерений и с учетом
влияния системных связей, [50].
В
связи с этим автором предлагаются модели
и алгоритмы решения задач диагностики
энергоустановки с помощью методов и
средств теории распознавания образов
со случайно или эмпирически выбранным
(для некоторых элементов) информационным
подмножеством признаков. То, что множество
признаков
 определяется не в начале диагностики,
а является результатом применения
сложных способов оценки информативности
параметров, считается основным недостатком
современной теории распознавания
образов, [51, 52].
определяется не в начале диагностики,
а является результатом применения
сложных способов оценки информативности
параметров, считается основным недостатком
современной теории распознавания
образов, [51, 52].
Итак,
определение множества параметров
диагностики
 может трактоваться как предварительный
выбор методов и методик измерений
(признаков) образа.
может трактоваться как предварительный
выбор методов и методик измерений
(признаков) образа.
Решение
задачи технической диагностики
энергоустановки в данной работе
выполняется на основе ее математического
описания в виде граф – модели
 -конечный
ориентированный граф, (рис. 3.11).
-конечный
ориентированный граф, (рис. 3.11).
В
таком графе каждая вершина
 связана дугой с вершиной
связана дугой с вершиной ,
если параметр
,
если параметр отображается в параметре
отображается в параметре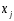 .
Неисправностью называется существенное
нарушение нормального функционирования
всего механизма (или отдельных его
узлов). Причиной возникновения
неисправности может быть либо один
серьезный дефект, либо комплекс дефектов.
.
Неисправностью называется существенное
нарушение нормального функционирования
всего механизма (или отдельных его
узлов). Причиной возникновения
неисправности может быть либо один
серьезный дефект, либо комплекс дефектов.
В алгоритм решения задачи выбора диагностических параметров положены методы оценки параметров, по их информативности и доступности, определение веса дуг и вершин граф – модели механизма энергоустановки.

Рис.
3.11. Исходная граф – модель (а) и матрица
смежности
 -
(б),
-
(б),
составленные для определения вероятной неисправности объекта.
Выбор состава множеств распознающих параметров
Принято считать неточность и неопределенность статистическими, случайными характеристиками и учитывать их при помощи методов теории вероятностей. Однако в реальных ситуациях источником неточности становятся помимо случайных величин, также и принципиальная невозможность оперировать точными данными из-за сложности системы, процессов, неточности, размытости ограничений, критериев и целей. Поэтому в задачах управления появляются классы объектов, не имеющие четких интервалов и границ в силу своей размытости. Нечеткость таких классов выражается тем, что элемент системы может не только принадлежать или не принадлежать некоторому классу, но возможны также и промежуточные степени принадлежности, особенно характерные для нестационарных режимов.
3.3.1.Методы группирования данных, классификации и кластеров
Размытость интервалов, ограничений, критериев и целей управления в эксплуатации и диагностике
В работах Zadeh L., Bellman R., Goguen J., Mizumoto M., Sugeno M., Dubois D., Prade H., Zimmermann H., Negoita C. и др. введены основные понятия, построены основы теории нечетких (или размытых) множеств и намечены основные направления приложений этой теории. Состоятельность этих рассуждений подтверждается также научными прогнозами в работах Айзермана М.А., Цыпкина Я.З., Красовского А.А., Моисеева Н.Н. [53-59] и положительными результатами, полученными в работах Язенина А.В., Борисова А.Н., Батыршина И.З., Алиева Р.А. [60-65] и др.
Заде Л. [12-17] определяет размытое множество как отображение множества Х на единичный интервал. При этом он рассуждает следующим образом:
-пусть Х - некоторое множество Х = {x}.
Тогда размытое множество S на Х будет задаваться функцией принадлежности
 ,
(3.32)
,
(3.32)
которая ставит в соответствие каждому хХ действительное число в интервале [0,1].
Goguen J. [66] расширил понятие размытого множества путем введения более общего понятия - «L - размытое множество», для которого
 .
(3.33)
.
(3.33)
Здесь интервал L может быть отличен от [0,1], т.е. принимать промежуточные значения внутри этого интервала.
Функция принадлежности является обобщением характеристической функции классической теории множеств, принимающей только два значения:
1 -для элементов, принадлежащих множеству S,
0 - для элементов, не принадлежащих множеству S.
Для дискретных множеств Х применяется запись размытого множества S как множества пар:
 .
(3.34)
.
(3.34)
В общем случае выбор функции s(Х) субъективен и основан на косвенной информации, имеющейся в каждом наблюдении, а также в каждой выборке исходных данных.
3.3.3. Размытые ограничения, цели и оптимизация работы агрегата в условиях нечеткой информации о состоянии
Результаты практических расчетов аппроксимации нечетких множеств, полученные автором в задачах оптимизации с нечеткими множествами при нечетких ограничениях, подтверждают возможность применения такого подхода [52]. Однако остается проблематичным выбор приемлемого множества уровня, аппроксимирующего данное нечеткое множество. Этот выбор необходимо выполнять ЛПР чисто субъективно, применяя утверждение:
«если»
 .
(3.35)
.
(3.35)
Это можно подтвердить следующим образом:

И,
в результате, так как
 A,
то получим:
A,
то получим:

 .
(3.36)
.
(3.36)
Для решения задач технического обслуживния используется специально разработанный автором программный комплекс SKAIS (рис. 3.5) с модулем OPTIMIZATOR (рис. 3.9).
OPTIMIZATOR подсистемы диагностики состояния энергоустановок SKAIS
Диагностический контроль энергоустановок тепловой электростанции (ТЭС) осуществляется с помощью экспертной диагностической системы функционально-гибридного типа с именем SKAIS. SKAIS - «Система контроля, анализа и слежения за изменением состояния энергоустановки» - управляемый в диалоговом режиме программный комплекс, ориентированный на диагностирование и экспертизу энергоустановок любых типов. SKAIS позволяет на ранней стадии (с использованием экспресс - испытаний) диагностировать снижение экономичности, определять величину, причины и опасность происходящих изменений, прогнозировать состояние, оценивать надежность, остаточный ресурс, долговечность, степень риска и ущерб от продолжения дальнейшей эксплуатации энергоустановки. Система SKAIS осуществляет принятие решений на выход из создавшейся конфликтной ситуации (вывод в ремонт или введение ограничения) с представлением подготовленных в базе знаний рекомендаций (в виде готовых продукций - решающих правил) оперативному и ремонтному персоналу тепловой электростанции. Для этого создается база данных и знаний (БД и З) обо всех вынужденных остановах и дефектах оборудования, отклонениях от правил его нормальной эксплуатации.
Объяснение
В
интеллектуальном центре подсистемы
контроля и диагностики энергоустановок
ТЭС –
 работает программный модуль
работает программный модуль по схеме
по схеме .
Основное назначение модуля – программное
решение задач минимизации функций цели,
имеющих несколько минимумов, но достаточно
гладких в окрестностях каждого из них.
Вдали от минимумов допускаются
неустранимые разрывы первого рода. Для
нахождения окрестности глобального
минимума используется из
.
Основное назначение модуля – программное
решение задач минимизации функций цели,
имеющих несколько минимумов, но достаточно
гладких в окрестностях каждого из них.
Вдали от минимумов допускаются
неустранимые разрывы первого рода. Для
нахождения окрестности глобального
минимума используется из метод случайного поиска (его комбинация).
Методом сопряженных градиентов минимум
уточняется. При появлении «оврагов»
градиентные методы отказываются
работать. В этом случае подключается к
метод случайного поиска (его комбинация).
Методом сопряженных градиентов минимум
уточняется. При появлении «оврагов»
градиентные методы отказываются
работать. В этом случае подключается к овражный
метод Гельфанда И.М., который позволяет
осуществить многомерный поиск минимума,
[Растригин Л.А.]. Из точки
овражный
метод Гельфанда И.М., который позволяет
осуществить многомерный поиск минимума,
[Растригин Л.А.]. Из точки по двум направлениям выполняется
наискорейший спуск на дно оврага,
(рис.123.9а).
по двум направлениям выполняется
наискорейший спуск на дно оврага,
(рис.123.9а).

Рис.3.9а.12
Элемент многомерного поиска оптимума
(по схеме
 )
) :
:
 -
где взять ближайшую точку – Эвристика!
– ближайшая точка совпадает с
-
где взять ближайшую точку – Эвристика!
– ближайшая точка совпадает с
 .
.
Но
срабатывает помеха! Для этого, при
вычислении градиента, вначале берем
шаг
 ,
а потом шаг
,
а потом шаг ,
получаем точки
,
получаем точки ,
определяющие прямую линию – «дно
оврага». По «дну оврага» выполняем еще
один многомерный поиск минимума. Получим
точку
,
определяющие прямую линию – «дно
оврага». По «дну оврага» выполняем еще
один многомерный поиск минимума. Получим
точку .
При необходимости этот элемент поиска
можно повторить. Последовательность
.
При необходимости этот элемент поиска
можно повторить. Последовательность задает
убывающую последовательность целевой
функции
задает
убывающую последовательность целевой
функции .
После срабатывания правила остановки,
когда реализуется заданный порог
похожести
.
После срабатывания правила остановки,
когда реализуется заданный порог
похожести ,
(рис.12
3.9а. и ПП с именем SIM),
последняя полученная точка
,
(рис.12
3.9а. и ПП с именем SIM),
последняя полученная точка
 и значение функции в этой точке будут
точкой глобального минимума
и значение функции в этой точке будут
точкой глобального минимума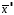 .
.
Результаты
анализа сравниваемых состояний
представляются визуально, в виде их
Порог похожести задается разработчиком
 -а.
Точки
-а.
Точки и
и считаются лежащими на дне оврага
(рис.123.9а).
Эти две точки определяют прямую линию,
по которой осуществляется одномерный
поиск минимума. Одно из направлений в
точке
считаются лежащими на дне оврага
(рис.123.9а).
Эти две точки определяют прямую линию,
по которой осуществляется одномерный
поиск минимума. Одно из направлений в
точке
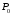 является градиентным. Второе направление
будет случайным. Эта комбинация,
детерминированного и случайного поиска,
приводит к желаемому результату.
Регулирующими параметрами элемента
поиска является пара (
является градиентным. Второе направление
будет случайным. Эта комбинация,
детерминированного и случайного поиска,
приводит к желаемому результату.
Регулирующими параметрами элемента
поиска является пара ( ),
где
),
где -
первоначальный шаг. В качестве правила
остановки, при наискорейшем спуске на
дно оврага и принятом механизме случайного
выбора решения из полученного набора
эвристик, используется принцип «похожести»
точек [55].
Одной из эвристик алгоритма является
предварительное знание об области
-
первоначальный шаг. В качестве правила
остановки, при наискорейшем спуске на
дно оврага и принятом механизме случайного
выбора решения из полученного набора
эвристик, используется принцип «похожести»
точек [55].
Одной из эвристик алгоритма является
предварительное знание об области
 и примерной зоне поиска
и примерной зоне поиска ,
в которой находится минимум функции
,
в которой находится минимум функции ,
а также знание об изменении параметров
технологического процесса по их
«похожести» (значения
,
а также знание об изменении параметров
технологического процесса по их
«похожести» (значения должны
быть одинаковыми, или близкими). Эта
информация позволит оценить первоначальный
шаг
должны
быть одинаковыми, или близкими). Эта
информация позволит оценить первоначальный
шаг и значения функции
и значения функции в выбранных точках. функциональных
значений
в выбранных точках. функциональных
значений на экране монитора (рис.135,
табл. П.1).
на экране монитора (рис.135,
табл. П.1).

Рис.
5. «Похожесть» диагностируемого состояния
(при сравнении с нормативным значением
 )
и определение фактического значения
)
и определение фактического значения (общее состояние энергоустановки) как
расстояния между ними, определяемое по
формуле [55]:
(общее состояние энергоустановки) как
расстояния между ними, определяемое по
формуле [55]:
 ,[55].
,[55].
Здесь
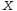 -
вектор измеренных параметров;
-
вектор измеренных параметров; -
вектор эталонных значений параметров;
-
вектор эталонных значений параметров; -
количество анализируемых параметров;
-
количество анализируемых параметров; - наборы значений признаков (параметров
состояния) для диагностируемого (
- наборы значений признаков (параметров
состояния) для диагностируемого ( )
и эталонного (
)
и эталонного ( )
объектов (агрегатов),
)
объектов (агрегатов), коэффициент Фехнера (см. закон
Вебера-Фехнера,
коэффициент Фехнера (см. закон
Вебера-Фехнера, ,
где
,
где -
оценка некоторой величины
-
оценка некоторой величины при «ощущении»
при «ощущении» ).
).
При
этом,
 .
Если известно
.
Если известно элементов – эталонов
элементов – эталонов ,
где
,
где ,
то, используя понятие «похожесть», можно
найти ближайший к данному объекту
,
то, используя понятие «похожесть», можно
найти ближайший к данному объекту (его
состоянию) эталон
(его
состоянию) эталон по максимуму значения коэффициента
по максимуму значения коэффициента ,
где
,
где .
.
Таблица П.1
Массив
«весов» параметров-признаков (отклонение
мощности турбины ΔNЭ
и ее экономичности
Δ от
гарантийного значения,DELTA
= ΔNЭ/Δ
от
гарантийного значения,DELTA
= ΔNЭ/Δ )
турбоустановки Т – 100 – 130 ТМЗ ст. №7 Н
ТЭЦ – 4 (в отдельных опытах до и после
ремонта) и сравнение параметров состояний
по мере «похожесть» (РОХ). Режим работы
– конденсационный.
)
турбоустановки Т – 100 – 130 ТМЗ ст. №7 Н
ТЭЦ – 4 (в отдельных опытах до и после
ремонта) и сравнение параметров состояний
по мере «похожесть» (РОХ). Режим работы
– конденсационный.
|
Номинальные (гарантийные) параметры |
|
|
|
|
|
|
|
|
РОХ
|
DELTA | |||||||||||
|
МВт |
МПа |
0С |
МПа |
т/ч |
0С |
м3/ч |
кДж/ кВтч |
-
|
МВт/кДж/кВтч | ||||||||||||
|
110,0 |
12,8 |
555,0 |
0,0049 |
480,0 |
5,8 |
16000 |
8918 |
1,00 |
- | ||||||||||||
|
Фактические параметры |
Перед ремонтом |
79,73 |
12,29 |
552,4 |
0,0218 |
392,6 |
22,5 |
13430 |
9245 |
0,52 |
| ||||||||||
|
75,09 |
12,29 |
549,8 |
0,0216 |
366,6 |
14,2 |
11762 |
9312 |
0,65 |
| ||||||||||||
|
64,5 |
12,87 |
546,0 |
0,019 |
326,6 |
12,6 |
10151 |
9513 |
0,61 |
| ||||||||||||
|
55,84 |
12,94 |
547,7 |
0,0156 |
302,2 |
13,4 |
9608 |
9689 |
0,57 |
| ||||||||||||
|
После ремонта |
83,1 |
12,8 |
550 |
0,0121 |
330,8 |
24,7 |
15300 |
8818 |
0,66 |
0,52/10,05 | |||||||||||
|
85,7 |
12,9 |
543 |
0,0059 |
339,7 |
22,2 |
15900 |
8843 |
0,64 |
0,61/15,9 | ||||||||||||
|
78,0 |
12,8 |
556 |
0,0052 |
323,6 |
22,2 |
14420 |
8819 |
0,67 |
0,39/14,2 | ||||||||||||
|
71,1 |
13,04 |
551 |
0,0056 |
289,0 |
24,3 |
15608 |
8887 |
0,61 |
0,92/10,9 | ||||||||||||
|
82,3 |
12,92 |
543 |
0,0061 |
332.7 |
17,1 |
15700 |
8829 |
0,66 |
0,63/15,9 | ||||||||||||








Здесь под РОХ («похожесть», Рис.5) понимается расстояние между признаками
(точнее их совокупностью образов) состояний энергоустановки близких номинальному (нормативному) состоянию. Похожесть фактического состояния энергоустановки номинальному состоянию определяется по формуле, [55]:
 .
.
Похожесть
диагностируемых состояний определяется
с помощью программы РОХ из.
 .
В геометрической интерпретации значения
.
В геометрической интерпретации значения отображают (представляют) собой
колебательную линию, построенную по
параметрам оцениваемого состояния
относительно его эталонного значения
отображают (представляют) собой
колебательную линию, построенную по
параметрам оцениваемого состояния
относительно его эталонного значения ,
(рис.5).
,
(рис.5).
Регулирование
этими параметрами с использованием
«меры похожести»
 позволяет эффективно (и визуально на
экране монитора) применять диалоговый
подход при оптимизации задач тепловой
электростанции (ТЭС). В этом случае лицу
принимающему решение (ЛПР) желательно
иметь не одно, а группу хороших решений
и возможности принятия решения по
времени
позволяет эффективно (и визуально на
экране монитора) применять диалоговый
подход при оптимизации задач тепловой
электростанции (ТЭС). В этом случае лицу
принимающему решение (ЛПР) желательно
иметь не одно, а группу хороших решений
и возможности принятия решения по
времени для последующего выбора окончательного
оптимального решения (например, при
базовом и переходном режимах работы
энергоустановки). Для реализации этого
в используемые эвристические правила
вводится неопределенность исходной
информации, благодаря чему и будет
порождаться класс субоптимальных
решений. Эвристические правила, обладающие
ограниченной неопределенностью, назовем
«размытыми» эвристиками [55]. Результатом
поиска будет единственное решение,
близость которого к оптимальному решению
определяется величиной максимальной
похожести
для последующего выбора окончательного
оптимального решения (например, при
базовом и переходном режимах работы
энергоустановки). Для реализации этого
в используемые эвристические правила
вводится неопределенность исходной
информации, благодаря чему и будет
порождаться класс субоптимальных
решений. Эвристические правила, обладающие
ограниченной неопределенностью, назовем
«размытыми» эвристиками [55]. Результатом
поиска будет единственное решение,
близость которого к оптимальному решению
определяется величиной максимальной
похожести ,
если мы имеем дело с тестовой задачей.
,
если мы имеем дело с тестовой задачей.
Тестовые
задачи сконструированы авторами работы
так, чтобы выделить особенности
теплоэнергетического процесса. При
опробовании
 а
по схеме
а
по схеме на тестовых примерах (использованы
функции Розенброка Х.Х. -
на тестовых примерах (использованы
функции Розенброка Х.Х. - и
РастригинаЛ.А.-
и
РастригинаЛ.А.-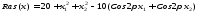 )
алгоритм сходится, т.е. минимум
осуществляется из любой начальной
точки. Использование механизма случайного
выбора решений позволяет расширять
область возможных реализаций или сужать
ее, в зависимости от ситуации и готовности
энергоустановки по состоянию к выполнению
режима.
)
алгоритм сходится, т.е. минимум
осуществляется из любой начальной
точки. Использование механизма случайного
выбора решений позволяет расширять
область возможных реализаций или сужать
ее, в зависимости от ситуации и готовности
энергоустановки по состоянию к выполнению
режима.
Задачи математического программирования при четкой постановке, в приложении к задачам технической диагностики энергоустановок ТЭС, решаем следующим образом.
Пусть
в области
 ,
определяемой ограничениями
,
определяемой ограничениями
 ,
,
 (1)
(1)
задана
целевая, в общем случае, нелинейная
функция
 .
Требуется найти такой
.
Требуется найти такой ,
для которого справедливо
,
для которого справедливо
 .
(2)
.
(2)
Здесь
условие (1) означает, что каждая компонента
 вектора (матрицы)
вектора (матрицы) изменяется в пределах от соответствующего
наименьшего допустимого значения
изменяется в пределах от соответствующего
наименьшего допустимого значения до наибольшего допустимого значения
до наибольшего допустимого значения .
Количество компонент -
.
Количество компонент - .
Любой вектор
.
Любой вектор называется допустимым. Вектор
называется допустимым. Вектор назовем оптимальным, если для любого
другого вектора
назовем оптимальным, если для любого
другого вектора выполняется условие:
выполняется условие:
 .
(3)
.
(3)
Как
известно из теории исследования операций,
[54], использование градиентных методов
для решения многоэкстремальных задач
затруднительно и малоэффективно, так
как необходимы полные исследования
целевой функции (определение, можно
приближенное, вида поверхности, начальные
приближения). Поэтому, как это подтверждает
практика, наиболее результативными
методами поиска минимума могут быть
различные модификации случайного
поиска. С этой целью в модуль
 включена модификация метода случайного
поиска – метод “Монте-Карло”, [55].
включена модификация метода случайного
поиска – метод “Монте-Карло”, [55].
Формула
изменения координат вектора
 имеет
следующий вид:
имеет
следующий вид:
 (4)
(4)
где
 - случайное число,
- случайное число,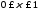 ;
;
 –нижние
и верхние ограничения на переменные.
–нижние
и верхние ограничения на переменные.
Из
(4) следует, что точка
 при любом
при любом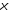 всегда находится в области
всегда находится в области (в ограничителях). Для определения
случайного числа
(в ограничителях). Для определения
случайного числа используется процедура RAND, вырабатывающая
случайные числа, необходимые при поиске
окрестности глобального минимума
функции цели. Попадание в окрестность
глобального минимума происходит с
некоторой вероятностью:
используется процедура RAND, вырабатывающая
случайные числа, необходимые при поиске
окрестности глобального минимума
функции цели. Попадание в окрестность
глобального минимума происходит с
некоторой вероятностью:
 (5)
(5)
где
 - объем зоны критерия глобального
минимума;
- объем зоны критерия глобального
минимума;
 -
объем зоны поиска;
-
объем зоны поиска;
 –количество
случайных бросков.
–количество
случайных бросков.
Работа
метода прекращается, если количество
случайных бросков превышает заданное
целое число
 .
Из совокупности точек, полученных в
результате случайных бросков, выбирается
точка
.
Из совокупности точек, полученных в
результате случайных бросков, выбирается
точка ,
которая соответствует наименьшему
значению функции цели
,
которая соответствует наименьшему
значению функции цели .
Однако метод Монте-Карло нецелесообразно
использовать для нахождения
.
Однако метод Монте-Карло нецелесообразно
использовать для нахождения ,
так как вероятность случайного попадания
в
,
так как вероятность случайного попадания
в - окрестность на одном шаге поиска,
определяемая отношением объемов
- окрестность на одном шаге поиска,
определяемая отношением объемов – мерных гиперсфер с радиусами
– мерных гиперсфер с радиусами и
и (начальным расстоянием до цели), равна:
(начальным расстоянием до цели), равна:
 (6)
(6)
Среднее
число шагов, необходимое для случайного
попадания в
 - окрестность цели
- окрестность цели
 (7)
(7)
имеет
экспоненциальный характер и, следовательно,
с ростом
 быстро растет и
быстро растет и .
В схеме
.
В схеме этот метод используется для двух целей:
этот метод используется для двух целей:
1) проведение статистических испытаний и расчетных экспериментов на ЭВМ;
2) оценки окрестности глобального экстремума функции цели.
В
последнем случае точка
 ,
найденная методом “Монте–Карло”,
улучшается постепенным приближением
к цели путем ограничения поиска зоной,
стягивающейся к наилучшей случайной
пробе. Это значит, что случайные пробы
производятся в объеме, центром которого
является точка с наименьшим значением
функции цели. По мере производства
случайных испытаний этот объем стягивается
к своему центру.
,
найденная методом “Монте–Карло”,
улучшается постепенным приближением
к цели путем ограничения поиска зоной,
стягивающейся к наилучшей случайной
пробе. Это значит, что случайные пробы
производятся в объеме, центром которого
является точка с наименьшим значением
функции цели. По мере производства
случайных испытаний этот объем стягивается
к своему центру.
Если
в процессе испытаний была найдена точка
с меньшим значением функции цели, то
объем испытаний устанавливается вокруг
этой новой точки. Таким образом, зона
испытаний перемещается в район цели,
причем на каждом шаге вероятность
случайного нахождения наилучшей точки
становится все большей. Этот принцип
лежит в основе второй модификации
случайного поиска – методе случайного
направленного поиска, [54, 55]. Из точки
 делается
случайный шаг
делается
случайный шаг
 ,
(8)
,
(8)
где
 .
(9)
.
(9)
Величина
 на
начальном шаге принимается равной
на
начальном шаге принимается равной .
Затем определяется координата новой
точки
.
Затем определяется координата новой
точки
 ,
(10)
,
(10)
и сравниваются значения
 .
. (11)
(11)
При
этом
 считается неудачной ситуацией,
а при
считается неудачной ситуацией,
а при проверяется условие
проверяется условие
 ,
(12)
,
(12)
при
выполнении которого ситуацию также
считают неудачной и удачной – в противном
случае. При неудаче предусмотрен возврат
в точку
 ,
из которой делается шаг в диаметрально
противоположном направлении с последующей
проверкой условия (12). В случае неудачи
вновь происходит возвращение в точку
,
из которой делается шаг в диаметрально
противоположном направлении с последующей
проверкой условия (12). В случае неудачи
вновь происходит возвращение в точку ,
из которой делается столько случайных
шагов, сколько потребуется для нахождения
удачной ситуации. Если такая точка
найдена, то через нее и
,
из которой делается столько случайных
шагов, сколько потребуется для нахождения
удачной ситуации. Если такая точка
найдена, то через нее и проводится вектор, в направлении которого
начинается движение с постоянным шагом.
проводится вектор, в направлении которого
начинается движение с постоянным шагом.
При движении по выбранному направлению проверяется относительное изменение функции цели
 .
(13)
.
(13)
В
случае
 предусмотрено возвращение в точку
предусмотрено возвращение в точку с последующим выбором (с помощью случайных
испытаний) нового направления.
с последующим выбором (с помощью случайных
испытаний) нового направления.
Значение
 меняется,
в процессе минимизации, следующим
образом.
меняется,
в процессе минимизации, следующим
образом.
Как
только число неудачных шагов фиксированной
точки окажется равным заданному целому
числу
 ,
то
,
то увеличивается на единицу.
увеличивается на единицу.
Эта операция позволяет осуществлять поиск и движение в выбранном направлении с все более и более уменьшающимися шагами.
Метод
случайного направленного поиска
прекращает свою работу, если выполняется
условие
 (заданное
целое число >>1). Если координаты точки
вдруг оказываются вне ограничений, то
функции присваивается число 1010
(или любое другое, определяемое на основе
расчетных экспериментов).
(заданное
целое число >>1). Если координаты точки
вдруг оказываются вне ограничений, то
функции присваивается число 1010
(или любое другое, определяемое на основе
расчетных экспериментов).
Предполагая,
что окрестность глобального минимума
найдена, продолжается дальнейшее
улучшение точки минимума. Для этого в
схеме
 используется метод сопряженных градиентов
с преобразованием координат, [55],
(рис.3.9а).
используется метод сопряженных градиентов
с преобразованием координат, [55],
(рис.3.9а).
Задачи математического программирования в нечетких условиях, в приложении к задачам технической диагностики энергоустановок, решаются следующим образом, [123]:
«Под ситуацией принятия решений, при выборе диагноза состояния энергоустановки, условимся понимать»:
- множество альтернатив, из которых лицо, принимающее решение (ЛПР), производит выбор;
- множество ограничений, накладываемых на этот выбор;
- целевую функцию, которая позволяет ЛПР ранжировать имеющиеся у него альтернативы.
В результате, каждое ЛПР, имея множество сформулированных целей, способно определить свои предпочтения.
Но
на практике, особенно при диагностике
в реальном масштабе времени, картина
принятия решений резко меняется, так
как ЛПР вынуждено применять следующее
утверждение: '' должно
быть в окрестности
должно
быть в окрестности ''!
А это уже подчеркивает появление
нечеткости в формулировании цели,
согласно [17, 123].
''!
А это уже подчеркивает появление
нечеткости в формулировании цели,
согласно [17, 123].
Выражение
«
в
окрестности…», представим
нечетким подмножеством
 ,
определяемым функцией (точнее, ее
отображением
,
определяемым функцией (точнее, ее
отображением ):
):
 ,
(14)
,
(14)
где
 - полная дистрибутивная решетка;
- полная дистрибутивная решетка; – множество альтернатив.
– множество альтернатив.
В
результате принятия решения по одному
из предлагаемых диагнозов, представим
возникшую нечеткую обстановку как
множество
 – альтернатив вместе с его нечеткими
подмножествами. Эти подмножества
представляют собой также нечетко
сформулированные критерии (цели и
ограничения), т.е. систему:
– альтернатив вместе с его нечеткими
подмножествами. Эти подмножества
представляют собой также нечетко
сформулированные критерии (цели и
ограничения), т.е. систему:
 .
(15)
.
(15)
Здесь
 – целевые функции.
– целевые функции.
Перебирая, по возможности, все критерии при выборе наиболее предположительного диагноза, можно построить функцию
 .
(16)
.
(16)
Оптимум,
в этом случае, будет соответствовать
той области
 ,
элементы которой максимизируют диагноз
,
элементы которой максимизируют диагноз .
В результате проведенных рассуждений
можно определить нечеткую обстановку
такой задачи тройкой
.
В результате проведенных рассуждений
можно определить нечеткую обстановку
такой задачи тройкой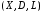 .
Предположим при этом, что решение задачи
диагноза в нечеткой постановке будет
определяться в виде нечеткого подмножества
универсального множества альтернатив.
Под оптимальным решением при этом будем
понимать элемент
.
Предположим при этом, что решение задачи
диагноза в нечеткой постановке будет
определяться в виде нечеткого подмножества
универсального множества альтернатив.
Под оптимальным решением при этом будем
понимать элемент (если такой существует), для которого,
согласно [123]:
(если такой существует), для которого,
согласно [123]:
 ,
(17)
,
(17)
где
 - нечеткое решение;
- нечеткое решение; означает
означает ,
, означает
означает .
Таким образом, задача минимизации
решений при выборе предположительного
диагноза сведена к задаче нечеткого
математического программирования
(НМП), т.е. к задаче многокритериальной
оптимизации.
.
Таким образом, задача минимизации
решений при выборе предположительного
диагноза сведена к задаче нечеткого
математического программирования
(НМП), т.е. к задаче многокритериальной
оптимизации.
Итак,
под задачей НМП будем понимать задачу
нахождения
 ,
или
,
или
 .
(18)
.
(18)
Результат решения задачи минимизации функции цели
В данной работе было уделено внимание на реализацию комплексного решения оптимального нахождения минимума различных функций цели с помощью среды MathCAD 14. Рассмотрены , при участии магистранта института прикладной информатики НГУЭУ А.Е. Некипелова, в комплексе метод «Монте-Карло» и градиентный метод наискорейшего спуска, позволяющие уточнить минимум функции, начальное приближение которого получается из случайного поиска методом Монте-Карло.
Метод «Монте-Карло»
Для минимизации функции многих переменных разработано множество численных методов, но большинство из них связано с подсчётом градиента функции, что со своей стороны может дать эффективные алгоритмы вычисления лишь, если удаётся аналитически подсчитать частные производные. Между тем, более универсальным методом минимизации функции многих переменных является метод перебора, при котором произвольным образом разбивается область определения функций на симплексы и в каждом узле симплекса вычисляется значение функции цели, причём происходит сравнение – перебор значений и на печать выводится точка минимума и значение функции в этой точке.
В
методе «Монте-Карло» зададим функцию
 .
Выбираем область поиска решения задачи:
.
Выбираем область поиска решения задачи:
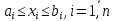 ;
;
а)
Производим случайные броски, т.е. выбираем
значения
 для каждой переменной
для каждой переменной по формуле:
по формуле:
 ;
;
б) Сравниваем значения функции:
 ,
,
если это неравенство выполняется, то
 ,
,
если не выполняется, то
 ;
;
в) Количество случайных бросков либо фиксировано, либо уточняется при достижении необходимой определенной погрешности.
Метод градиентного спуска
Строгий
аналитический метод не всегда приводит
к цели (случай, когда
 в критической точке). В подобных, и в
более сложных случаях применяют различные
приближённые аналитические методы,
которые в математическом смысле иногда
менее строго обоснованы, но, тем не
менее, порой приводят к желаемому
результату. К таким методам относятся
и градиентные методы наискорейшего
спуска.
в критической точке). В подобных, и в
более сложных случаях применяют различные
приближённые аналитические методы,
которые в математическом смысле иногда
менее строго обоснованы, но, тем не
менее, порой приводят к желаемому
результату. К таким методам относятся
и градиентные методы наискорейшего
спуска.
Пусть,
нам нужно найти
 .
Рассмотрим некоторую точку
.
Рассмотрим некоторую точку

 и вычислим в этой
точке градиент функции
и вычислим в этой
точке градиент функции
 :
:
 ,
,
где
 - ортонормированный базис в пространстве
- ортонормированный базис в пространстве .
.
Если
 ,
то полагаем:
,
то полагаем:
 ,
,
где
 ,
а
,
а выбирается из условия сходимости
итерационного процесса:
выбирается из условия сходимости
итерационного процесса:
 ,
,
где
 ,
а
,
а выбирается из условия сходимости.
выбирается из условия сходимости.
Формулу можно расписать в виде:


…………………………………………………………………

Здесь m – число итераций. Процесс итерации останавливается, когда достигается требуемая предельная погрешность, т.е. когда выполнены условия остановки итерации:
 .
.
Данный метод хорош лишь в том случае, когда имеется некое первое оптимальное приближение, в противном случае результат может быть совсем иной, не удовлетворяющий критериям. Поэтому в данной работе мы используем его в комплексе с методом «Монте-Карло», в дальнейшем, получив начальное приближение, уточним его до некоторой погрешности градиентным методом наискорейшего спуска.
ПРИМЕР РЕАЛИЗАЦИИ И РЕШЕНИЯ ЗАДАЧИ определЕНИЯ МИНИМУМА ФУНКЦИИ ЦЕЛИ В СРЕДЕ MATHCAD
Пусть задана многоэкстремальная функция:
 .
.
Рассмотрим
ее графики при различных изменениях
 .
Из первого графика видим, что глобальный
экстремум находится в районах
.
Из первого графика видим, что глобальный
экстремум находится в районах и равен примерно 75.
и равен примерно 75.
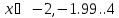

Если
смотреть другую область изменения, то
глобальный экстремум находится в районе
 .
Рассмотрим область изменения
.
Рассмотрим область изменения .
.

Используем
метод «Монте-Карло» для нахождения
глобального минимума функции. Сформируем
два вектора
 и
и ,
присвоив их нулевым элементам значение
нуль:
,
присвоив их нулевым элементам значение
нуль:

Зададим
количеством случайных чисел
 ,
которое мы будем использовать для
вычисления минимума. Чем больше это
количество, тем точнее будет результат
вычисления:
,
которое мы будем использовать для
вычисления минимума. Чем больше это
количество, тем точнее будет результат
вычисления:
 .
.
С
помощью функции
 создадим вектор случайных значений
элементов
создадим вектор случайных значений
элементов .
Функция
.
Функция генерирует равномерно распределенные
случайные числа в интервале 0…
генерирует равномерно распределенные
случайные числа в интервале 0… .
.
Из
графика видно, что нам достаточен
интервал
 .
.
 .
.
Теперь
в векторе
 помещено 100000 случайных чисел. Вычислим
значения функции от них и поместим их
в вектор
помещено 100000 случайных чисел. Вычислим
значения функции от них и поместим их
в вектор .
.
 .
.
Величину
минимального элемента этого вектора
найдем, используя функцию .
.

Величину
минимального элемента вектора
 найдем, используя небольшую программу
и вычислим по ней ответ:
найдем, используя небольшую программу
и вычислим по ней ответ:
 ,
,
 ,
,
 .
.
Получили первое приближенное значение минимума функции цели. Для уточнения значения используем градиентный метод. Поиск минимума ведется по следующим формулам:
 ,
,
 выбирается
из условия
выбирается
из условия
 .
.
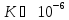 –параметр,
определяющий погрешность поиска
минимума.
–параметр,
определяющий погрешность поиска
минимума.
 -
отношение золотого сечения.
-
отношение золотого сечения.
 -
формула Бине
-
формула Бине
для
вычисления чисел Фибоначчи, где
 –
номер числа.
–
номер числа.
Сделаем
подпрограмму для вычисления частной
производной функции
 в точке заданной вектором
в точке заданной вектором по переменной
по переменной .
.
Подпрограмма выглядит следующим образом:

Сделаем подпрограмму для вычисления значений проекций градиента на оси координат. Подпрограмма возвращает вектор значений проекций и использует подпрограмму вычисления частной производной:
 .
.
Функция
 ,
используемая для выбора
,
используемая для выбора :
:
 .
.
Далее сделаем подпрограмму поиска минимума функции одной переменной по методу Фибоначчи (одномерной оптимизации функции цели).
Подпрограмма поиска минимума с помощью метода градиентного спуска:


Сформулируем
еще раз нашу многоэкстремальную
функцию:
 ,
,
 .
.
Находим,
в какой точке
 достигается минимум функции цели по
нашей программе:
достигается минимум функции цели по
нашей программе:
 .
.
Находим значение минимума функции цели:
 .
.
Отсюда можно сказать, что метод градиентного спуска подтвердил сходимость решения методом «Монте-Карло», [9, 10] .
Целью
нашего рассуждения и последующего
исследования в работе является сведение
полученной задачи НМП (18) к классической
задаче математического программирования
(2), для той же целевой функции
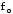 ,
[3, 5, 8-11].
,
[3, 5, 8-11].
Пример из расчетного эксперимента:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()


![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()


![]()
![]()
![]()
![]()
![]()





![]()
![]()

3.3.4. Распознавание образов и сходства
Анализ информации для диагностики и оценивания состояния механизмов
Пусть
техническое состояние объекта контроля
и диагностики определяется значениями
координат вектора параметров
 ,
размерность которого
,
размерность которого ,
характеризует объем контроля
энергоустановки. На области определения
,
характеризует объем контроля
энергоустановки. На области определения или
или параметров
параметров и признаков
и признаков заданы:
заданы:
-априорная плотность вероятности этих параметров
 ,(3.37)
,(3.37)
-область
работоспособности
 в
виде ограничений
в
виде ограничений на показатели (или критерий достигаемой
цели
на показатели (или критерий достигаемой
цели )
качества работы объекта контроля
)
качества работы объекта контроля
 ,(3.38)
,(3.38)
- условная плотность работоспособного состояния
 ,(3.39)
,(3.39)
- условная плотность частично работоспособного состояния
 ,(3.40)
,(3.40)
где
« »
- обозначает операцию объединения
одноточечных нечетких множеств
»
- обозначает операцию объединения
одноточечных нечетких множеств ;
«
;
« »
означает нечеткость соответствующих
параметров;
»
означает нечеткость соответствующих
параметров;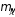 -
степень принадлежности
-
степень принадлежности нечеткому множеству
нечеткому множеству .
.
В
работе применена допусковая методика
контроля и диагностики технического
состояния энергоустановки, т.е.
 аппроксимируется
аппроксимируется -
мерным многогранником
-
мерным многогранником ,
грани которого соответствуют независимым
(или частично зависимым) допускам
,
грани которого соответствуют независимым
(или частично зависимым) допускам ,
рис. 3.6.
,
рис. 3.6.
Условная
плотность
 определяется аналогично(3.40),
где, вместо
определяется аналогично(3.40),
где, вместо
 ,
используется
,
используется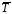 .
Размеры допусков
.
Размеры допусков получаются в результате решения задачи
минимизации ошибок первого и второго
рода (по критериям Неймана – Пирсона,
[67]) и т.д. Далее используются вероятности
ложного отказа
получаются в результате решения задачи
минимизации ошибок первого и второго
рода (по критериям Неймана – Пирсона,
[67]) и т.д. Далее используются вероятности
ложного отказа и
вероятности не обнаруженного отказа
и
вероятности не обнаруженного отказа .
.
3.5. Оценки погрешностей измерений и наблюдений за состоянием агрегатов
Точность
определения диагностических признаков
и последующего оценивания состояния
агрегатов зависит от точности измерения
исходной информации и особенностей
применяемых моделей диагностики (от
качества измеряемых параметров и
чувствительности к ним моделей).
Необходимо отметить также, что уменьшение
количества определяемых признаков и
оптимизация решения требуемой точности
их измерений могут в некоторой степени
сократить затраты на процесс измерения
как за счет перераспределения требуемой
погрешности, так и за счет уменьшения
количества измеряемых параметров.
Рассмотрим влияние погрешностей
измерения на результаты расчета и
основанного на них диагноза. Это так
называемые прямая и обратная задачи в
теории погрешностей [68, 69]. Основу решения
обратной задачи составляет нахождение
связей между абсолютными погрешностями
 выходной информации и
выходной информации и - входной информации, чтобы обеспечить
заданную (лежащую в заданном интервале
доверия) предельную погрешность функции
(энергетической характеристики, рис.
3.10) и установить предельные абсолютные
погрешности
- входной информации, чтобы обеспечить
заданную (лежащую в заданном интервале
доверия) предельную погрешность функции
(энергетической характеристики, рис.
3.10) и установить предельные абсолютные
погрешности ее аргументов. Это так называемый
«принцип равных влияний». Суть его
заключается в том, что вклад каждого
слагаемого в правой части формулы
(3.41):
ее аргументов. Это так называемый
«принцип равных влияний». Суть его
заключается в том, что вклад каждого
слагаемого в правой части формулы
(3.41):
 ,
(3.41)
,
(3.41)
в
общую сумму
 принят
равнозначным. Из этого условия следует
равенство
принят
равнозначным. Из этого условия следует
равенство
 ,
где
,
где
 .(3.42)
.(3.42)
Существенным
недостатком такого способа является
уравнивание различных (с точки зрения
физики протекающего в теплоэнергетической
установке процесса) параметров
погрешностей, формирующих в итоге
выходной параметр
 (мощность, расход и т.д.). В виду этого
искажается действительное, статистически
проявляющееся соотношение между
параметрами, включенными в
(мощность, расход и т.д.). В виду этого
искажается действительное, статистически
проявляющееся соотношение между
параметрами, включенными в (параметрический интервал
(параметрический интервал -
того функционала состояния энергоустановки).
Таким образом, появляется нечеткая
информация на интервалах нагрузки
энергетической характеристики (рис.3.10).
В [69] был получен вариант метода наименьших
квадратов (МНК), в котором учитываются
и погрешности функции и погрешности ее
аргументов в приложении к энергоустановке,
названный автором «методом согласования
балансов». Такой способ анализа данных
идентичен «способу согласования
балансов», применяемому в энергетике
и конфлюэнтному анализу в теории
статистики, [70].
-
того функционала состояния энергоустановки).
Таким образом, появляется нечеткая
информация на интервалах нагрузки
энергетической характеристики (рис.3.10).
В [69] был получен вариант метода наименьших
квадратов (МНК), в котором учитываются
и погрешности функции и погрешности ее
аргументов в приложении к энергоустановке,
названный автором «методом согласования
балансов». Такой способ анализа данных
идентичен «способу согласования
балансов», применяемому в энергетике
и конфлюэнтному анализу в теории
статистики, [70].
Указанный способ не приводит к появлению смещенных оценок идентифицируемых параметров и, в результате, сводится к минимизации суммы
 ,(3.43)
,(3.43)
при условии
 .(3.44)
.(3.44)
Обратная задача теории погрешностей отвечает условию получения погрешностей независимых аргументов и выполнению условия
 ,(3.45)
,(3.45)
при
выполнении условия (3.44)
и
обязательном
 .
.
Как показывает выполненный анализ измерений, при диагностических экспериментах на функционирующих энергоустановках, минимизация абсолютных погрешностей не может полностью учитывать имеющееся разнообразие физических и механических параметров (по их абсолютной величине) и, что особенно нежелательно, колебание погрешностей при изменении их аргументов (особенно ощутимое в нестационарных режимах работы энергоустановок и в динамике измерения параметров). В результате это приводит к неопределенности результата измерений – апостериорного состояния системы «объект – средство измерений, процессор».
В связи с изложенным и с учетом [71], в диагностические расчеты и выполняемый анализ результатов измерений признаков вводятся весовые согласующие коэффициенты вида
 .(3.46)
.(3.46)
Весовые коэффициенты выбираются диагностом, исходя из условия пропорциональности каждого слагаемого суммы (3.44) абсолютного значения аргумента и квадрата модуля частной производной функции по этой переменной.
Задача
минимизации суммы относительных
погрешностей
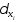 ,
в представленной автором постановке,
решается в виде
,
в представленной автором постановке,
решается в виде
 ,(3.47)
,(3.47)
при соблюдении условия (3.44). Для решения этой задачи используется метод множителей Лагранжа Ж.-Л. и программный модуль OPTIMIZATOR (рис. 3.9) диагностического комплекса SKAIS [9], позволяющие отыскивать максимум (минимум) функции при ограничениях в форме равенств. Основная идея применяемого метода заключается в переходе от задачи на условный экстремум к задаче отыскания безусловного экстремума некоторой специально построенной функции Лагранжа Ж.-Л..
Влияние погрешностей исходных данных на погрешности диагноза
Анализ влияния погрешностей измеряемых параметров на конечный диагноз выполняется с помощью следующей модели, использующей метод Лагранжа Ж.-Л. и (3.43), т.е.
 .
(3.48)
.
(3.48)
Для
устранения разнозначных погрешностей
и выполнения «согласования балансов»,
аналогично [72], вводим в (3.48) так называемые
«регуляризующие добавки»
 ,
которые позволят привести приведенную
погрешность конечной функции близко к
1%. Тогда (3.48) будет иметь вид:
,
которые позволят привести приведенную
погрешность конечной функции близко к
1%. Тогда (3.48) будет иметь вид:
 .(3.49)
.(3.49)
Подставляя (3.49) в выражение (3.47), получим, после преобразований, целевую функцию корректирования погрешностей и согласования балансов:
 .(3.50)
.(3.50)
Функция
(3.50) решается, при обязательном выполнении
условия (3.43)
с
помощью методов оптимизации из модуля
 программно-диагностического комплекса
SKAIS.
программно-диагностического комплекса
SKAIS.
Итак, решение задачи технической диагностики энергоустановки (или любого другого непрерывно действующего агрегата) выполняется на основе ее математического описания в виде граф – модели. В алгоритм решения задачи выбора диагностических параметров положены методы оценки параметров, по их информативности и доступности, определение веса дуг и вершин граф – модели механизма энергоустановки.
Контрольные вопросы и задания для самостоятельной работы по главе 3
3.1. Цель группирования данных?
3.2.Алгоритмы автоматического группирования данных?
3.3. Структурная декомпозиция данных, свойства?
3.4. Группирование данных?
3.5. Четкие декомпозиции?
3.6. Нечеткие декомпозиции?
3.7. Меры удаленности между объектами?
3.8. Критерии качества группирования?
Глава 4. Источники информации и причины возникновения ее неопределенности
Переработка и использование информации в реальных условиях функционирования агрегатов
В реальных условиях оценки эффективности энергоустановок ТЭС, выполняемой на основе диагностики их состояния с целью определения готовности к работе, анализа дефектов и распознавания неисправностей, необходимо использовать и перерабатывать самую разнообразную информацию. Значительная часть этой информации может быть очень низкого качества, т.е. неопределенной, заданной неоднозначно, нечетко, неполно (рис.4.1).
Неопределенность такой информации обусловлена существенными погрешностями измеренных значений параметров, неизбежными и значительными погрешностями оценок состояния, погрешностями принятых решений. При этом уровень получаемой неопределенности для разной информации будет различен, а также зависим от разных условий работы энергоустановки.
Количественная оценка неопределенности наступления множества событий, имеющих различную вероятность, которая обращается в нуль при действительном наступлении одного из событий, позволила, по мнению Шеннона К. рассматривать его энтропию как «разумную» количественную меру возможности выбора или меру количества информации, являющейся не противоречивой ранее предложенной мере Хартли Р. [73].


Рис. 4.1. Классификация исходной информации при диагностике функционирующих энергоустановок.
Однако с самим термином КОЛИЧЕСТВО ИНФОРМАЦИИ связана некоторая неясность, т.к. в неявном виде предполагается, что если известно, что такое количество информации, то должно быть известно и что такое ИНФОРМАЦИЯ.
 ,
(4.1)
,
(4.1)
Шеннон К., занимаясь непосредственно вопросами математической теории связи, абстрагировался от всех качественных и человеческих аспектов информации. В работах Эшби У.Р., Бриллюэна М.М., Харкевича А.А., Мазура М. и др. сделан вывод о существовании множества видов проявления информации и подмножествах логически выводимых форм ее представления. Среди этого множества существует лишь некоторое подмножество, занимаемое статистической информацией. А внутри уже этого множества существует свое подмножество, которое соответствует, по определению Шеннона К., количеству информации о рассматриваемом объекте. Второй важный вывод получен при анализе систем, для которых понятие информация является методологической основой для обобщения и упрощения [74, 75]. Это заключение особенно подчеркивается в работах Эшби У.Р., [76]. Возможность учета в информационных оценках неопределенности и размытости стала особенно важной в связи с тем, что сегодня учет качественной и размытой информации становится центральным в методах искусственного интеллекта, применяемых в отдеьных областях народного хозяйства со сложными технологиями и структурой управления, и в энергетике. Поэтому уточним понятия неопределенность, размытость, неразличимость и предпочтимость, которые будут использоваться далее в работе и в учебнике.
Неопределенность. Рассматривается как статистическое понятие и количественно находится из выражения Шеннона К.. В общем случае неопределенность следует делить на качественную и количественную, а также на полную и частичную. Качественная неопределенность (ее назовем «неопределенность границы») характеризует отсутствие различия в пределах рассматриваемых признаков между объективно различимыми множествами (образами). Количественная неопределенность характеризует отсутствие различия между элементами, находящимися внутри множества (образа). Понятия «множество» и «образ» в данном изложении равнозначны. В обоих случаях неопределенность может быть как статистической, так и детерминистской, а в общем случае комплексной, т.е. статистически – детерминированной. Зоны, в пределах которых будут использоваться выбранные признаки, различимые образы или их элементы, являются неразличимыми для данного случая. Такие зоны будем называть далее зонами полной неопределенности, а зоны с частичной разделимостью, соответственно, будем называть зонами частичной неопределенности.
На рис.4.2. представлены примеры полученных зон полной (ПН) и частичной (ЧН) неопределенности для вероятностной величины P(W) и одного из выбранных детерминированных показателей Э (W) или Р2 (W). На рисунке показано следующее: на основе прогноза на 2000г. установлено, что предельная мощность турбоустановки будет находиться в интервале (W1 W2), при этом P(W) – это вероятностная кривая прогноза предельной мощности турбоустановки на 2000г.;
Э(W) – эффективность работы электростанции в зависимости от мощности турбоустановки (турбина + генератор) по расчетным данным на 2000г., где приращение Э(W) находим в зонах частичной неопределенности в пределах точности расчета , т.е.:
Э(W)чн. (4.2)
При этом необходимо уточнить, что в случае статистической неопределенности и в предельном случае, когда для всей рассматриваемой области P(W)=const, неопределенность будет полной и равной
 .
(4.3)
.
(4.3)
При отсутствии в рассматриваемой области полностью неразличимых участков
 ,
(4.4)
,
(4.4)
где n – число различимых значений мощностей (Wi), находящихся в интервале точности их определения для фактических условий.

Рис. 4.2. Примеры областей неопределенностей:
а) зоны полной (жирная стрелка) и частичной (простая стрелка) неопределенностей (ПН и ЧН); б) вероятности – неопределенностей; в) неопределенности – вероятностей.
Неопределенность может быть собственной, т.е. обусловленной внутренними свойствами диагностируемого объекта и внешней (информационной), когда неопределенность вызывается объективными и субъективными причинами, действующими во всем канале получения (измерения, передачи, переработки и представления) информации. В случае, когда весовой показатель различия структуры конструкции или свойств отдельных элементов (w) диагностируемой энергоустановки обладает свойствами
 для wi,
(4.5)
для wi,
(4.5)
то нестатистическая неопределенность может находиться по аналогии с статистической неопределенностью, т.е.
 .
(4.6)
.
(4.6)
В общем случае мерой неопределенности является функция отношения различающихся и не различающихся образов или их элементов. Выражение, оценивающее величину аддитивной (суммарной) неопределенности, будет соответствовать
 ,
(4.7)
,
(4.7)
где f – функция, обеспечивающая заданную связь Н с Р и w при выполнении условий аддитивности.
В частном случае w может характеризовать предпочтимость того или иного элемента, например, предпочтимость того или иного алгоритма развития системы, предпочтимость режима работы энергоустановки и т.д.
Таким образом, в итоге будем считать под неопределенностью субъективную или объективную характеристику отсутствия статистического и (или) детерминированного различия между образами или их элементами.
Неразличимость. Под неразличимостью подразумевается «суммарная» неопределенность объекта, т.е. неопределенность состояния управляемого агрегата и неопределенность наблюдателя (человека – оператора или машины - автомата), выполняющего функции различения. Следует иметь в виду, что неопределенность при принятии решений в большой системе энергетики снижается по мере движения вниз по иерархическим рангам управления.
Действительно, если неопределенность оценивать статистической мерой, то неопределенность решения задачи в этом случае можно представить в виде
 ,
(4.8)
,
(4.8)
где k – число подзадач, из которых складывается решение - задачи;
m - число координат, в пространстве которых ищется ответ на каждую подзадачу;
n – число различимых отрезков, на которые разбивается каждая координата (n= N/, N –рассматриваемая длина координаты, - потребительский порог различимости);
P j, , i - априорная вероятность попадания решения в i-й различимый отрезок -й координаты в j-й подзадаче.
Практически, при анализе движения информации вниз по иерархическим рангам, было получено следующее соотношение по предпочтениям:
Н руководителя Н операции Н оператора . (4.9)
Предпочтимость. Предпочтимость образов или элементов в электроэнергетической системе (ЭЭС) меняется в зависимости от уровня иерархии и по задачам. Кроме того, предпочтимость на одном уровне иерархии может быть четкой, а на другом, из-за недостатка информации или субъективных причин, размытой или даже совсем неразличимой.
Размытость.
Это относительно новое понятие в
качественной теории информации. Оно
было предложено и разработано Заде Л.
[12-17] и уже сегодня широко используется
в теории систем, в методологии решения
задач искусственного интеллекта и во
многих технических областях, включая
и электроэнергетику [77]. Размытость
возникла как промежуточное качество
между четкостью с одной стороны и
неопределенностью – с другой, причем
в предельных случаях размытость переходит
в четкость или неопределенность. В
качестве меры размытости в работе
используется показатель принадлежности
 ,
характеризующий степень принадлежности
Х к i-му образу. В отдельных случаях,
помимо статистической принадлежности,
применяется также детерминированная
принадлежность
,
характеризующий степень принадлежности
Х к i-му образу. В отдельных случаях,
помимо статистической принадлежности,
применяется также детерминированная
принадлежность ,
которая представляет собойстепень
сходства Х
(в отношении свойств, структуры или
состава) с i-м образом.
,
которая представляет собойстепень
сходства Х
(в отношении свойств, структуры или
состава) с i-м образом.
Образ – это множество изображений (отображения объекта наблюдения на пространство признаков), характеризуемое близостью классифицируемых объектов по свойствам и выделяемым в качестве классификационных признаков. При этом отдельному образу будет соответствовать элемент фактор – множества W изображений Х, характеризующихся совокупностью признаков, или описанием подмножества {х1, х2, …, хn}.
В
задачах управления энергетическими
установками (и особенно их диагностике)
нас интересует, в первую очередь, не сам
факт степени принадлежности Х тому или
иному образу, а следствие от этого.
Однако знание степени принадлежности
также необходимо при установлении
диагноза. Так, к примеру, если известно,
какая реакция системы (в виде вибро–
смещения) соответствует i-тому образу,
то представляет значительный интерес
знание приведенной степени принадлежности
 ,
т.е. степень близости реакции системы,
вызываемой элементом Х к реакции (т.е.
появившимся дисбалансом), имеющей место
при i-м образе.
,
т.е. степень близости реакции системы,
вызываемой элементом Х к реакции (т.е.
появившимся дисбалансом), имеющей место
при i-м образе.
Размытость
может иметь место как в отношении границ
между образами – внешняя размытость,
так и внутри образов между их элементами
– внутренняя размытость. Размытость
между образами может проявляться в двух
видах: как наличие промежуточного
образа, элементы которого имеют
определенную степень принадлежности
к основным образам, например, А и В, так
и границы между множествами, переход
через которые не вызывает качественного
(как минимум на зону различимости)
изменения рассматриваемых признаков.
При этом показатель принадлежности
 -того
элемента к тому или иному Mi
-тому образу имеет упорядоченный
характер. Например, показатель
принадлежности элемента
-того
элемента к тому или иному Mi
-тому образу имеет упорядоченный
характер. Например, показатель
принадлежности элемента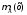 ,
для i-того элемента промежуточного
образа будет увеличиваться по мере
приближения этого элемента к границе
МА.
,
для i-того элемента промежуточного
образа будет увеличиваться по мере
приближения этого элемента к границе
МА.
Возможны следующие типы размытости:
а) размытые границы между четкими (не размытыми) образами;
б) промежуточные образы, имеющие с основными образами четкие и размытые границы.
Размытость элементов внутри образа означает, что хотя все эти элементы качественно однородны, но существуют какие-то, имеющие значения для решаемой задачи, количественные различия, которые имеют определенную упорядоченность от центра (фокуса) образа до его внешних границ.
Неопределенность и размытость имеют некоторую общность как показатели недостаточного знания, осведомленности, наблюдаемости об объектах и явлениях. Упрощенно можно представить, что неопределенность – это низшая ступень нашего знания, а размытость – это некоторые дополнительные знания внутри неопределенности, выраженные через показатели принадлежности (рис. 3.10).
Причем, в отличие от вероятностей, если говорить только о статистической принадлежности, она может отражать не только объективные закономерности, но и различные субъективные факторы (например, «человеческий фактор»).
Таким образом, исходя из изложенного, будем считать размытостью некоторую степень неопределенности при сравнении между образами или их элементами, представляемую функциями принадлежности и упорядоченными таким образом, что они меняются до полной определенности (четкости), при приближении к границам образа или его предельным элементам. Размытость также связана с понятиями различимость и предпочтимость. В результатебудем считать, что неопределенность и вероятность – это связанные понятия, сложность которых все же требует приложения еще и философского осмысления и объяснения [77, 78].
При диагностике состояния функционирующих энергоустановок исходную информацию будем классифицировать по способу ее получения и по характеру неопределенности (рис. 4.1). По способу получения диагностическую информацию разделим на оперативную и ретроспективную. Оперативная информация при диагностике необходима для управления энергоустановок в темпе реального технологического процесса. Она поступает периодически или по контрольному запросу и отражает функциональную работу энергоустановки за короткий промежуток времени (так называемый моментный диагноз) как внутри электростанции, так и в энергетической системе.
Ретроспективная информация есть результат статистической обработки данных о параметрах состояния энергоустановки, ее дефектах, происшедших отказах за «время жизни» механизма, модернизациях и реконструкциях, текущих и капитальных ремонтах, всех вынужденных остановках и post - дефектных состояний.
По характеру неопределенности выделим исходную диагностическую информацию и разделим ее на следующие группы: детерминированная, вероятностно – определенная и неопределенная (нечеткая и размытая). Основой такого разделения является анализ и результаты измерений и экспериментов, полученные автором в процессе продолжительных диагностических исследований на функционирующих энергоустановках [46], а также в ремонтных кампаниях, прогнозной и экспертной информации.
Следует отметить также, что с переходом на более низкие уровни управления и технического обслуживания энергоустановок (по иерархии) степень неопределенности возрастает до неразличимости состояния элемента механизма.
Детерминированная информация и ее получение основаны на закономерных причинно – следственных связях, протекающих в энергоустановке, физических процессах и производимых ею операций во время технологического процесса производства электрической и тепловой энергии. К детерминированной, т.е. однозначно заданной, можно отнести информацию о номинальных параметрах рабочего тела (пара, питательной воды, масла, частоты тока и напряжения в сети и т.д.), паспортные данные на оборудование, установленное в технологической схеме энергоустановки и т.п.
Вероятностно – определенная информация отражает причинно – следственные отношения, имеющие вероятностную (стохастическую) природу и может описываться известными законами распределения или его характеристиками. В работе принимается, что вероятностно – определенная информация обладает также и статистической устойчивостью, однако для нее закон распределения неизвестен, или же вид закона распределения всего лишь приближенный, т.к. известны не все его параметры.
Вероятностно – неопределенная информация обусловлена, с одной стороны, тем, что нельзя точно задать фактические энергетические характеристики энергоустановок. Необходимо выполнение специальных экспресс – испытаний или больших балансовых испытаний, по результатам которых уже можно приближенно установить для них вероятностные законы распределения, получить числовые характеристики, которые и будут характеризовать средние значения или вариации параметров и выборок из них. А с другой стороны, она характеризуется вероятностным характером выбираемого закона распределения, точнее, тем, кто принимает решение по установлению выбранного (наиболее близкого к действительным характеристикам) закона распределения, т.е. человека – исследователя состояния данной энергоустановки.
Нечеткая информация характеризуется отсутствием причинно – следственных связей. Поэтому при решении задач диагностики энергоустановок в условиях неопределенности исходной информации необходимо определять только диапазоны (интервалы) измерения неопределенных факторов (рис. 3.10, 4.1), [46]. Наиболее существенными из неопределенных параметров в задачах диагностики технического состояния энергоустановок являются:
полный ресурс энергоагрегата,
остаточный ресурс основных узлов агрегата,
максимальные годовые нагрузки,
длительность максимальных нагрузок,
число неплановых пусков/остановов агрегата,
работоспособность энергоустановки,
живучесть энергоагрегата в резкопеременных режимах,
живучесть энергоагрегата в предотказовых и аварийных состояниях,
потери экономичности энергоустановки в процессе эксплуатации,
потери надежности и эффективности энергоустановки в процессе ремонтов,
замыкающие затраты на восстановление работоспособности энергоустановки,
срок жизни энергоустановки до перехода в состояние деградации и выход в утилизацию,
и т.п.
Значения этих факторов представляются интервальными оценками типа «от … до… около».
4. 2. Управление и идентификация на объекте в условиях неопределенности информации на основе знаний, получаемых при функциональной диагностике
Рассмотрим метод контроля правильности функционирования турбоустановки при представлении ее в виде механизма с нечеткими состояниями.
В качестве диагностических признаков будем использовать управляющие правила функционирования механизма, а также эвристические знания и опыт экспертов.
Общую постановку задачи оценивания технического состояния турбоустановки и принятия решений будем представлять нечеткими уравнениями в отношениях. Для этого должны быть формализованы в терминах нечетких множеств также априорные и апостериорные данные.
Итак, будем считать заданными следующие исходные данные. Пусть в результате предварительного анализа известно множество классов технического состояния объекта контроля
 ,
, ,
(4.10)
,
(4.10)
представляемого в виде нечеткого множества с соответствующими функциями принадлежности
 .
(4.11)
.
(4.11)
Используя основные понятия теории систем [45], представим объект контроля в виде декартова произведения пространств входа и выхода

 ,
(4.12)
,
(4.12)
где U – множество входных значений в объект {u};
V – множество выходных значений из объекта {v};
u, v – параметры состояния объекта.
Ввиду неопределенности знаний об объекте используется нечеткая модель его описания с заданной структурой, вида (3.17).
Для доопределения структуры нечеткой модели задаем операторы формирования нечетких множеств
 (4.13)
(4.13)
где пространства
U,
V
рассматриваются как исходные данные
для формирования терм-множеств
лингвистических переменных ,
и процедуры вычисления соответствующих
функций принадлежности
 ,
, .
.
Тогда уравнение управляющего правила вида «А:ЕСЛИ…, ТО…,» на языке функций принадлежности будет иметь вид
 .
(4.14)
.
(4.14)
Информацию о состоянии объекта контроля будем получать с помощью информационно-измерительной системы в составе диагностического комплекса SKAIS, представленной в виде операторов измерений
 (4.15)
(4.15)
и операторов первичной
 (4.16)
(4.16)
и вторичной схемы
 (4.17)
(4.17)
обработки измерений
[29, 30]. Здесь u,
v–
параметры состояния;
 – оценки параметров состояния;
– оценки параметров состояния; – измеряемые параметры;t
– текущее время;
– измеряемые параметры;t
– текущее время;
 – оценки нечетких множеств;
– оценки нечетких множеств; – матрица нечетких отношений,
идентифицированная по результатам
измерений.
– матрица нечетких отношений,
идентифицированная по результатам
измерений.
Техническое
состояние объекта контроля оценивается
по реализациям определенных признаков
состояния – диагностических признаков
 .
.
При этом множество таких диагностических признаков должно обеспечивать наблюдаемость заданных технических состояний при представлении объекта контроля математической моделью выбранного вида.
Так
как вид диагностических признаков
определяется параметрами модели, то
при аппроксимации неопределенности
функционирования объекта контроля
нечетким уравнением в отношениях вида
 (3.17) в
качестве диагностических признаков
принимаем множество управляющих правил
(3.17) в
качестве диагностических признаков
принимаем множество управляющих правил
 ,
j=1, …,n,
(4.18)
,
j=1, …,n,
(4.18)
представленных в форме эталонных матриц нечетких отношений
 ,
i=1, …,m,
(4.19)
,
i=1, …,m,
(4.19)
и являющихся
собственно параметрами модели (в общем
случае, ввиду того, что отображение
 не является взаимно однозначным,
не является взаимно однозначным, ).
).
Множества классов технических состояний F и диагностических признаков G находятся между собой в определенном отношении
 (4.20)
(4.20)
т.е. каждое техническое состояние рассматриваемого объекта (турбоустановки) отображается в соответствующие реализации диагностических признаков. Такое отношение далее формализуется в виде соответствующей матрицы отношений.
Принимаем полученное отношение нечетким и представляем его матрицей нечетких отношений H с элементами, идентифицируемыми по знаниям экспертов.
Тогда множество диагностических признаков g также будет нечетким
 .
(4.21)
.
(4.21)
Здесь:
– операторы формирования нечеткого
множества
 определяются в виде процедуры вычисления
функций принадлежности
определяются в виде процедуры вычисления
функций принадлежности
 ;
(4.22)
;
(4.22)
–
 –расстояние
между априорно заданными значениями
диагностических признаков
–расстояние
между априорно заданными значениями
диагностических признаков
 и их оценками
и их оценками .
.
В качестве показателя эффективности решения задачи оценивания технического состояния выбираем
 ,
(4.23)
,
(4.23)
где
 – обобщенная функция принадлежностиI–го
технического состояния;
– обобщенная функция принадлежностиI–го
технического состояния;
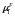 –априорная функция
принадлежности;
–априорная функция
принадлежности;
 –апостериорная
функция принадлежности I–го
технического состояния, полученная по
результатам измерений путем решения
уравнения, обратного (4.21).
–апостериорная
функция принадлежности I–го
технического состояния, полученная по
результатам измерений путем решения
уравнения, обратного (4.21).
В качестве критерия эффективности решения задачи оценивания примем следующее правило:
 .
(4.24)
.
(4.24)
В результате проведенной формализации были определены исходные данные для решения задачи оценивания технического состояния, что позволило сформулировать целевую установку рассматриваемой проблемы:
– на основе априорной информации о возможных технических состояниях объекта контроля и выбранной структуры его описания, по результатам проведенных измерений параметров входа и выхода объектов, требуется оценить, в соответствии с заданным критерием, действительное техническое состояние механизма.
Решение проблемы в данной постановке апробировано с помощью пакета прикладных программ комплекса SKAIS и его модуля OPTIMIZATOR (рис. 3.5, 3.9).
4.3.Представление и использование чётких и «размытых» знаний в математических моделях оценивания состояния агрегатов, на основе функциональной диагностики
В работе принято следующее утверждение:
– при существующем уровне знаний (четких и нечетких, в смысле Л.Заде [12-17]), о процессах изменения технического состояния агрегатов, задачи диагностики функционирующих энергоустановок более эффективно решаются в условиях неопределенности. Это подтверждается также и в работах других исследователей.Решение задачи диагностики агрегатов в условиях неопределенности исходной информации приводит к неопределенности самих решений.
Выбор наилучшего решения из равнозначных осуществляет человек (точнее ЛПР - лицо, принимающее решение) на основе предпочтений или функций принадлежности (ФП). Предпочтения и ФП далее анализируются и используются в картах состояния энергоустановки.
На выбор математических моделей диагностики состояния энергоустановок, методов расчета работоспособности и остаточного ресурса оказывают существенное влияние формы задания и описание исходной информации. Перед началом оценки работоспособности агрегата существует значительная неопределенность суждений о техническом состоянии энергоустановки. Осуществляемая проверка каждого показателя в измерительных процедурах, в соответствии с требованиями [68], уменьшает степень неопределенности и дает качественную информацию о состоянии механизма. Если оценить объем информации, которую несет каждый показатель, то можно определить при диагностике вероятность P(v) правильной оценки действительного состояния энергоустановки.
При решении задач диагностики, в условиях неопределенности исходной информации, следует направлять усилия оператора энергоблока или инженера-исследователя на поиск возможностей снятия или хотя бы частичного преодоления неопределенности, на основе «опыта и знаний» эксперта-диагноста.
В настоящее время выделяют два основных пути уменьшения неопределенности информации при исследовании состояния энергоустановок электростанций.
Первый путь состоит в совершенствовании систем сбора, обработки и оценивании информации; второй путь основан на создании моделей и методов, обеспечивающих использование всех форм информации (рис. 4.1), с целью максимального ее использования для выбора рациональных решений по определению диагноза состояния функционирующих энергоустановок.
Результатом работы, ее конечной целью, стал диагностический комплекс SKAIS - «система контроля, анализа и слежения за техническим состоянием и работоспособностью энергоустановок» (рис. 3.5).
Система диагностики энергоустановок ТЭС с программным комплексом SKAIS содержит модули информационного, технологического, термодинамического анализа, математического обеспечения, логического вывода, умозаключений и оптимизации, построенных на основе методов теории систем и системного анализа с применением математических методов кибернетики и методов искусственного интеллекта.
Назначением системы SKAIS является:
а) выполнение задачи правильного планирования и исполнения наблюдений и измерений на функционирующей энергоустановке в темпе реального времени;
б) отбор существенных для эксперта сведений, решения задач оценивания в условиях неопределенности и нечеткости исходных данных;
в) обработка в реальном, или близком к нему, масштабе времени;
г) использование большого количества данных из базы данных (фонды, каталоги, архивы, библиотеки, статистические и экспериментальные данные о работе диагностируемого оборудования), информация о работе оборудования за все время эксплуатации на данной ТЭС.
Для реализации системы SKAIS в работе решена задача получения качественной информации, последующего диагноза состояния энергоустановки, с применением расширения понятия «измерение информации».
4.3.1.Формализация решения задачи оценивания состояния
Решение задачи, в соответствии с изложенной в п. 3.1 постановкой, представим в виде:
 .
(4.25)
.
(4.25)
Процедура оценивания состояния представляется в виде следующих этапов:
А. Формализация априорной информации, включая: задание классов технических состояний; выбор и составление словаря диагностических признаков; описание классов технических состояний на языке словаря диагностических признаков; разработка правил принятия решения.
Б. Получение диагностической информации, включая: измерение параметров состояния; проведение первичной и вторичной обработки полученных данных; получение оценок диагностических признаков.
В. Применение алгоритма принятия решения о техническом состоянии объекта контроля.
4.3.2. Особенности решения задач контроля и функционирования агрегата
Задача контроля правильности функционирования технического объекта (агрегата, теплоэнергоустановки) решается как задача оценивания, применительно к нечеткой системе управления, следующим образом.
Шаг 1. Формализация априорной информации включает определение множества технических состояний объекта с использованием всех накопленных знаний об объекте.
При этом возможны различные варианты учета степени уверенности, а также здравый смысл лица, принимающего решение [33, 45, 46]: определение технического состояния объекта контроля, составление прогноза на его последующую эксплуатацию.
Для решения поставленной задачи предлагается использовать методы теории возможностей [22]. Согласно теории возможностей, вся накопленная априорная информация, а также интуиция и опыт экспертов (т.е. эвристика) формализуются в виде нечеткого множества с соответствующими функциями принадлежности.
Шаг
2. Выбирается математическая модель,
описываемая нечетким уравнением в
отношениях при ограничениях,
удовлетворяющих условию корректной
идентифицируемости. Для этого матрица
нечетких отношений R
должна быть неособенной (т.е., ее
 ).
).
Под корректностью понимается также условие единственности описания модели в рамках заданной структуры и его устойчивость по отношению к исходным данным.
Результаты расчетов и проведенные эксперименты [46] подтверждают проводимые рассуждения. В результате, этому требованию удовлетворяют управляющие правила, отражающие весь диапазон изменения параметров входа и выхода, и представляются в виде продукционных правил:
«ЕСЛИ u есть umin ТО v есть vmax ИЛИ ЕСЛИ u есть umax ТО v есть vmin». (4.26)
Данное условие налагает определенные требования на организацию процедуры измерения параметров системы и выполняемые эксперименты. Измерения следует проводить в области определения крайних термов лингвистических переменных, как можно ближе к краям диапазонов характеристики регулирования энергетического агрегата (рис.3.10). Проведенные эксперименты позволили выполнить анализ идентифицируемости отдельных структур турбоустановки ТЭС.
Контрольные вопросы и задания для самостоятельной работы по главе 4
4.1. Прямой логический вывод?
4.2. Алгоритм обратного логического вывода?
4.3. Логическое программирование?
4.4. Функции полезности?
4.5. Сети принятия решений?
4.6. Формирование деревьев решений на основе обучения?
4.7. Принципы функционирования алгоритмов обучения?
4.8. Применение знаний в обучении?
4.9. Нейронные сети.
Глава 5. Введение в генетическое программирование
5.1. Введение в генетические и эволюционные алгоритмы
Генетические алгоритмы
Особенности идей теории эволюции и самоорганизации заключаются в том, что они находят своё подтверждение не только для биологических систем.
Современная теория ЭА (Эволюционные алгоритмы) начинается с конца 50-х годов. Появились первые работы Бокса и Бремермана, Анохина П.К. [80-82] в области эволюционных методов оптимизации и функциональных систем. Менее заметным было появление работ Фридберга, посвящённых принципам видоизменения и селекции обучающихся автоматов. С середины 60-х годов начали формироваться основные работы по ЭА, в том числе Эволюционные стратегии, эволюционное программирование, генетические алгоритмы и генетическое программирование. Рехенберг и Швефель, работая над проблемой сопротивления линий электропередач, предложили использовать для обеспечения оптимизации непрерывных функций стратегии эволюции, получившей название ЭС (Эволюционная стратегия). Фогель, Оуэнс и Уолш, [82], изучая возможности проектирования интеллектуальных автоматов, пришли к выводу о том, что необходимо применять моделирование с использованием основных операторов поиска мутации и селекции. Холланд [83], проводивший исследования в области адаптивных систем предложил план моделирования эволюции, основу которого составили понятия эволюции, генетического кодирования и генетических операторов. Коzа [84, 85] провёл работы в области генетического программирования. С середины 80-х годов начали регулярно проводиться международные конференции по ЭА. Появилась электронная почта и спец журналы. С 1996 года, с появлением интернета образовалась сеть EvoNet, с помощью которой стали быстро достигаться результаты, работы по генетическим алгоритмам. Это всё способствовало развитию компьютеров и параллельных вычислителей. В настоящее время благодаря этой тематике ЭА мы можем проводить анализ сложных нелинейных систем, совместно с достижениями теории исследования операций ИИ, теории мягких вычислений и моделирования живой природы. На практике ЭА в основном используются для решения оптимизационных задач и дополняют арсенал методов исследования операций, главная цель которых разработка научных методов и средств принятия решений для решения сложных задач с ограничениями на ресурсы. В области ИИ активно начали разрабатываться и решаться задачи распознавания образов, диагностики, классификации и обучения, как проблема поиска в абстрактном пространстве решений,и если цель поиска – оптимизация, то решается вопрос о выборе оптимальных решений, поэтому, с точки зрения методологии ИИ, ЭА являются классом адаптивных стохастических методов поиска, дополняя традиционные стратегии самообучения, базируясь на механизме эволюции живой природы, который на практике доказал свою непримитивность. Фогель вообще видит теорию эволюции и самоорганизации как базовую концепцию всех интеллектуальных процессов и систем, значительно расширяющую сферу применения традиционной парадигмы ИИ. «Мягкие вычисления» прямо противоположны аналитическим методам поиска решений исследования операций и классической парадигме ИИ, в связи с чем возникла пограничная область проектирования систем, являющихся гибридом эволюционных алгоритмов и мягких вычислений [86, 87]. С другой стороны, ЭА могут рассматриваться как базовая технология для проектирования моделей ИИ, имитирующих фундаментальный принцип самоорганизации живых систем: целое больше, чем сумма его частей. Примерами сочетаний идей ЭА и ИИ являются модели системы «жертва-хищник», компьютерных игр, программы художественного дизайна и т.д.[88].
5.2. Сравнительный анализ эволюционных алгоритмов
Высокий потенциал, которым обладают различные формы ЭА для решения трудных оптимизационных задач, известен давно. Диверсификация ЭА привела к значительному разнообразию их форм. Актуальной становится проблема сравнительного анализа, систематизация их особенностей и выработка рекомендаций для решения оптимизационных задач (табл. 5.1), [89]. Джон Фон Нейман опубликовал теорию самовоспроизводящихся автоматов [90].
Критерий сравнения Таблица 5.1.
|
Вид ЭА |
Критерий сравнения | ||||||||
|
Представление решения |
целевая функция |
Селекция |
Мутация |
Рекомбинация |
Самоадаптивность | ||||
|
ГА |
Двоичное вещественное |
Скаляр
|
Стохастическая, недискриминационная |
Вспомогательный оператор |
Основной оператор поиска |
Малоисследована | |||
|
ГП |
Программное |
- |
То же |
Применяется неоднозначно |
То же |
- | |||
|
ЭС |
Вещественное |
вектор |
Детерминированная, дискриминационная |
Основной оператор поиска |
Важна для самоадаптивности |
Среднеквадратичное отклонение | |||
|
ЭП |
- |
- |
То же |
Единственный оператор поиска |
Не применяется |
- | |||
Различные формы ЭА имитируют эволюционный процесс на различном уровне
абстракции. ГА (генетический алгоритм) и ГП (генетическое программирование) делает акцент на генетический механизм наследственности на уровне хромосом. ЭС, напротив, рассматривают ход эволюции на уровне фенотипа. Алгоритмы ЭП анализируют эволюцию на уровне популяции в целом. Один стринг (хромосома) в ГА кодирует одно решение, т.е. пропорция между генотипом и фенотипом равна 1:1, что соответствует в биологическом смысле одному гаплоиду, т.е. особь с одинарным набором непарных хромосом.
Открытия в генетике (60-е годы), так называемые интроны (гены, не содержащие генетической информации) свидетельствуют о некоторой ограниченности подобного рода подхода к моделированию эволюции. В алгоритмах ЭС и ЭП оператор мутации применяется с частотой, соответствующей нормальному закону распределения, что оправдано для выбранного уровня моделирования в отличие от мутации на генном уровне, где она проявляется как редкое событие и практически не влияет на фенотип.
В ГА вероятность мутации отдельных генов и хромосом (называется инверсией) близка к природной. В алгоритмах ЭП мутация вообще является единственным оператором поиска, а оператор дискретной рекомбинации в ЭС соответствует природному механизму доминирования родительских хромосом в отличие от так называемой промежуточной рекомбинации, которая аналогична природной передаче некоторых признаков по наследству, что соответствует некоторому компромиссу между родительскими хромосомами. Наконец, оператор кроссинговера, который не применяется в алгоритмах ЭП, т.е. является основным алгоритмом для ГА и ГП. Эти и многие другие методологические различия между разными формами ЭА позволяют говорить о базовых постулатах, таких, как универсальность и фундаментальность, присущих эволюции независимо от формы и уровня абстракции модели. Указанная общность может быть выражена в следующей схеме абстрактного ЭА [89-92]:
установка параметров эволюции;
инициализация начальной популяции P(0);
 ;
;оценка решений, входящих в популяцию;
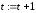 ;
;селекция (отбор);
репликация (повторение, копирование, аутосинтез)
вариация (видоизменение);
оценка решений – потомков;
образование новой популяции
 ;
;выполнение алгоритма до тех пор, пока параметр t не достигнет заданного значения
 ,
либо не будут выполняться другие условия
останова;
,
либо не будут выполняться другие условия
останова;вывод результатов и останов.
Контроверзу Ч. Дарвина (1859 г.) о том, что в ходе естественного отбора побеждает сильнейший, необходимо дополнить: материал для эволюции дают побеждённые.
Между тем в ЭА чаще всего применяются статические fitness – функции, что не позволяет учесть механизм коэволюции в живой природе. Популяция в природе, как объясняет правило, состоит из отдельных, более или менее изолированных локальных подпопуляций, допускающих миграцию отдельных индивидуумов. Большинством ЭА это обстоятельство игнорируется, алгоритмы работают с одной большой, неструктурированной популяцией. Тем не менее решающим обстоятельством для оценки практической пригодности ЭА является прежде всего то, насколько успешно с помощью ЭА может быть решена та или иная оптимизационная задача с точки зрения качества решения и вычислительной сложности. Результаты сравнительного анализа ГА, ГП, ЭС и ЭП представлены выше в таблице 5.1 [81].
В литературе была предпринята попытка сравнительного анализа конкурирующих алгоритмов оптимизации с точки зрения их результативности.
Пусть конкурирующие
алгоритмы, F
– целевая функция задачи оптимизации,
H–
гистограмма значений
конкурирующие
алгоритмы, F
– целевая функция задачи оптимизации,
H–
гистограмма значений
 количество полученных решений. Обозначим
через
количество полученных решений. Обозначим
через вероятность
получения с помощью А алгоритма поискаm
различных решений, имеющих вид гистограммы
H.
вероятность
получения с помощью А алгоритма поискаm
различных решений, имеющих вид гистограммы
H.
Английские учёные Вольперти Макрид сформулировали и доказали следующую теорему NFL (No-Free-Lunch).
Теорема
NFL:
для любой пары эвристических алгоритмов
поисковой оптимизации
 справедливо следующее соотношение:
справедливо следующее соотношение:
 =
= .
(5.1)
.
(5.1)
Иными
словами, все алгоритмы поиска оптимума
целевой функции имеют одинаковую
результативность, если сравнение
производится по всем возможными
представлениям F.
Таким образом, если алгоритм
 при оптимизации некоторой целевой
функции позволяет получить лучшие
результаты, нежели алгоритм
при оптимизации некоторой целевой
функции позволяет получить лучшие
результаты, нежели алгоритм ,
то существуют оптимизационные задачи
с другой целевой функцией, для которой
лучшие результаты дает алгоритм
,
то существуют оптимизационные задачи
с другой целевой функцией, для которой
лучшие результаты дает алгоритм .
.
Несмотря на очевидную ограниченность NFL- теоремы (не учитывается время решения оптимизационной задачи конкурирующими алгоритмами), она позволяет подходить к оценке алгоритмов оптимизации с единых методологических позиций и имеет практически важные следствия:
Поиск эвристического алгоритма оптимизации, который превосходит все конкурирующие с ним алгоритмы, не имеет смысла без точного описания конкретных задач и целевых функций, при оптимизации которых разрабатываемый алгоритм имеет преимущество перед другими алгоритмами. Нельзя рассчитывать найти один алгоритм, который будет результативнее других для любых целевых функций оптимизации.
Чтобы найти хорошее решение для заданного класса задач оптимизации, необходимо, в начале, идентифицировать характеристические особенности классов задач и затем на их основе искать подходящий алгоритм (самый простой алгоритм – задача линейного программирования и симплекс-метод).
В связи с появлением эвристических алгоритмов появилась возможность решения проблемы быстрого достижения цели и решения целевой функции оптимизации.
Достоинства ЭА:
а) широкая область применения [92];
б) возможность проблемно-ориентированного кодирования решений, подбора начальной популяции, комбинирования эволюционных алгоритмов с не эволюционными алгоритмами, продолжение процесса эволюции до тех пор, пока имеются необходимые ресурсы;
в) пригодность для поиска в сложном пространстве решений большой размерности;
г) отсутствие ограничений на вид целевой функции;
д) ясность схемы и базовых принципов ЭА;
е) интегрируемость ЭА с другими классическими парадигмами ИИ, такими как, искусственные нейросети и нечеткая логика.
Недостатки ЭА:
а) эвристический характер ЭА не гарантирует оптимальности полученного решения (на практике важно за заданное время получить одно или несколько субоптимальных альтернативных решений, тем более что исходные данные в задаче могут динамически меняться, быть неточными или неполными);
б) относительно высокая вычислительная трудоемкость, причинами которой является то обстоятельство, что в ходе моделирования эволюции многие решения отбрасываются как не перспективные (однако на практике считается, что временная сложность эвристических алгоритмов в среднем ниже чем у лучших конкурирующих алгоритмов, но не более чем на один порядок);
в) невысокая эффективность ЭА на исключительных фазах моделирования эволюции (в особенности для ГА), объясняется тем, что операторы поиска в ЭА не ориентированы на быстрое попадание в локальный оптимум;
г) нерешенными остаются вопросы самоадаптации ЭА.
Преодоление перечисленных выше трудностей тесно связано с понятием параллелизма ЭА, что позволяет реалистично моделировать эволюцию с помощью параллельных вычислительных систем и использовать для эволюции популяции большой размерности.
Параллелизм ЭА.
Различают следующие типы параллелизма ЭА [81, 89]:
1. глобальный;
2. миграционная модель;
3. диффузионная модель.
В первом случае выполняется параллельное вычисление целевой функции и параллельное выполнение операторов ЭА. Целевая функция отдельного индивидуума в популяции, как правило, не зависит от других индивидуумов, поэтому вычисление целевых функций допускает распараллеливание. При этом популяция хранится в общей памяти, а отдельный процессор считывает хромосому из памяти и возвращает результат после вычислений целевой функции в виде fitness-значения. Процедура синхронизации здесь проводится лишь при формировании новой популяции. В случае, если вычислительная система имеет распределенную память, то популяция и fitness-значения отдельных индивидуумов хранятся в «мастер-процессоре», а расчеты производятся на вспомогательных процессорах. Некоторую трудность для распараллеливания представляет процедура селекции. Здесь преимущество в смысле распараллеливания получают те форы селекции, которые не используют глобальную статистику о популяции, например, «соревновательные» способы селекции. Легко распараллеливаемыми являются операторы мутации и кроссинговера, так как они выполняются независимо друг от друга и в основном случайным образом.
Другой тип параллелизма – миграционная модель - наиболее эффективно реализуется в вычислительных системах с MIMD – архитектурой путем разделения общей популяции на отдельные подпопуляции, имитационное моделирование которых осуществляются на отдельных процессорах. Если между отдельными подпопуляциями установить правила миграции отдельных индивидуумов, то получится миграционная модель. Для этого требуется задать количество и размеры подпопуляций, топологию связей между ними, частоту и интервал миграции, а также стратегию эмиграции и иммиграции. Размеры и число подпопуляций определяются числом и быстродействием используемых процессов или транспьютеров, а так же сложностью решаемой оптимизационной проблемы. Что касается топологии связей в миграционной модели, то здесь различаются два варианта: «островная» модель, предусматривающая миграцию между любыми подпопуляциями, и миграционная модель, предусматривающая обмен между соседними подпопуляциями. Применение того или иного варианта миграционной модели зависит от архитектуры параллельного вычислителя (сетевая или кольцевая). Частота миграции определяется размерами подпопуляций. При высокой частоте подпопуляция может быстро потерять гетерогенность. Наоборот, при слабой интенсивности миграции и большом числе подпопуляций возрастает вероятность получения нескольких хороших решений, однако сходимость ЭА замедляется [92].
Третья разновидность параллелизм ЭА – диффузионная модель – наиболее эффективно реализуется в вычислительных системах с SIMD-архитектурой. В этом случает общая популяция разделяется на большое количество немногочисленных подпопуляций, а операторы кроссинговера и селекции применяются лишь в ограниченной области, определяемой отношением соседства. Это приводит к тому, что хорошие решения очень медленно распространяются в популяции (диффузия) и проблема попадания в «локальную яму» становится менее острой.
Выводы. Эволюционные алгоритмы наименее подходят для решения оптимизационных проблем, если:
требуется найти глобальный оптимум;
имеется эффективный не эволюционный алгоритм оптимизации;
переменные, от которых зависит решение, можно оптимизировать независимо;
для задачи характерна высокая степень эпистазии, т. е. взаимозависимость между переменными оптимизации такова, что одна переменная подавляет другую;
значения целевой функции во всех точках, за исключением оптимума, приблизительно одинаковы.
Принципиально подходящими для решения с помощью ЭА являются следующие оптимизационные проблемы:
задачи многомерной оптимизации с мультимодальными целевыми функциями, для которых, по существу, нет подходящих неэволюционных методов решения;
стохастические задачи;
динамические задачи с блуждающим оптимумом;
задачи комбинаторной оптимизации;
задачи прогнозирования и распознавания образов.
5.3. Генетическое программирование
Проблемы компьютерного синтеза программ [86] стали одним из направлений искусственного интеллекта примерно в конце 50-х годов. Попытки автоматической генерации программ, решающих представленную задачу, привели к достаточно скромным результатам, что вполне объяснимо тогдашним состоянием вычислительных систем Hardware и Software. Начиная с середины 80-х годов интерес исследователей к данной проблематике резко возрос, благодаря работам [84, 85] по генетическому программированию, представленных в рамках первой и последующих международных конференций по ГА. Наиболее значительными следует признать работы Дж. Коzа, опубликованных в виде 2-х томов под названием «Генетическое программирование» [84, 85].
Основы ГП.
ГП представляет собой одно из направлений ГА и ориентировано в основном на решение задач автоматического синтеза программ на основе обучающих данных путем индуктивного вывода.
Хромосомы или структуры, которые автоматически генерируются с помощью генетических операторов, являются компьютерными программами различной величины и сложности. Программы состоят из функций, переменных и констант.Исходная популяция P(0) хромосом в ГП образуется стохастически и состоит из программ, которые включают в себя элементы множества проблемно-ориентированных элементарных функций (functionset), а также проблемно-ориентированные переменные и константы (terminalset). Множества functionset и terminalset являются основой для эволюционного синтеза программы, способной наилучшим образом решать поставленную задачу. Одновременно устанавливаются правила выбора элементов из указанных множеств в пространстве всех потенциально синтезируемых программ, структура которых имеет древовидную форму.
Понятно, что множества terminalset и functionset, а также правила их обработки оказывают серьезное влияние на размерность пространства поиска наилучшего решения и на качество результатов, получаемых методами ГП. ГП-структуры как правило имеют древовидную форму.
Koza в своих исследованиях по ГП применяет язык LISP, обладающий всеми необходимыми для синтеза ГП-структур свойствами:
LISP (Маккартни Дж.) [93] является синтаксически простым функциональным языком, программа на котором, представляет собой рекурсивную функцию символьных выражений, состоящих из элементарных функций, условных операторов и операторов суперпозиции;
Обработка данных в LISP-программе сводится к объединению, делению и перегруппировке информации;
LISP-выражения представляются древовидной структурой (рис. 5.1), форма и величина которой может динамически изменяться.

Рис. 5.1. Дерево LISP-выражения (* 11(+314)).
Язык LISP имеет свои недостатки и применение ГП нельзя связывать лишь с LISP-программированием, что нашло свое подтверждение в работах, где для целей ГП применяются языки C, Smalltalk, C++.
Стартовыми, по Koza, условиями для ГП являются:
установка множества terminal set;
установкамножества function set;
определение подходящего вида функции соответствия (fitness-function);
установка параметров эволюции;
определение критерия остановки моделирования эволюции и правил декодирования результатов эволюции.
Поскольку основой моделирования эволюции в ГП являются элементы множеств terminalset и functionset, то в этом смысле выбор пользователем языка программирования будет в дальнейшем определять вид получаемых решений. Что касается установки fitness-function, параметров эволюции и критериев остановки процесса моделирования, то они совпадают с аналогичными этапами других типов ЭА.
В качестве элементов functionsets могут фигурировать следующие:
арифметические операции
 ;
;математические функции (
 );
);булевыоперации (например, if-then- else);
циклы (например, for, do-until);
некоторые специальные функции, для быстрого поиска хороших решений.
Элементами множества terminalset являются константы и переменные, среди которых особое значение имеют так называемое ephemeralrandom (случайные с коротким временем жизни) константы, в частности для задач связанных с оценкой параметров регрессивных функций.
Koza упоминает о шести различных константах указанного вида. Речь идет о булевых константах, принимающих значения из множества {T, Nil}, а также вещественных константах, принимающих значение на отрезке [-1,000;1,000] с шагом 0,001.
Множества terminalset и functionset должны быть достаточными для нахождения решения задачи, а любая функция быть корректно выполнимой при любых допустимых аргументах (символ операции деления в ГП обозначается через %). Форма fitness-functionимеет большое значение для эффективности ГП.
Общепризнанным способом оценки качества fitness-function является такой показатель, как среднеквадратичная ошибка С.К.О. (чем она меньше, тем лучше программа). Иногда используется критерий «выигрыша», согласно которому выигрыш определяется в зависимости от степени близости к корректному значению целевой функции. Fitness-functionв ГП называют rohfitness и обозначают через
 .
Однако на практике обычно используется
стандартное значение
.
Однако на практике обычно используется
стандартное значение
Обозначим
через
 некоторую
программу из популяции размером
некоторую
программу из популяции размером .
Тогда стандартное значениеfitness
определяется
как
.
Тогда стандартное значениеfitness
определяется
как
 (5.2)
(5.2)

Интервал
изменения
 равен
(0.1). Размер популяции
равен
(0.1). Размер популяции в ГП обычно составляет несколько тысяч
программ.
в ГП обычно составляет несколько тысяч
программ.
Для
максимального числа генераций
 рекомендации
отсутствуют.Koza
в своих экспериментах использует
значение
рекомендации
отсутствуют.Koza
в своих экспериментах использует
значение
 =51.
=51.
Рассмотрим подробнее процедуру ГП.
Инициализация. На этом этапе стохастически генерируется популяция P(0), состоящая из
 древовидных
программ, причем корневой вершиной
дерева всегда является функция, аргументы
которой выбираются случайно из множеств
function set или terminal set. Концевыми вершинами
дерева должны быть переменные или
константы, в противном случае процесс
генерации необходимо рекурсивно
продолжить. Если структура дерева
становится сложной, то заранее
устанавливается максимальная высота
дерева, равная числу ребер дерева,
которое содержит самый длинный путь
от корневой вершины до некоторой
концевой вершины. В экспериментахKoza
максимальная высота дерева колеблется
от шести, для популяции P(0), до 17 в более
поздних популяциях P(t).
древовидных
программ, причем корневой вершиной
дерева всегда является функция, аргументы
которой выбираются случайно из множеств
function set или terminal set. Концевыми вершинами
дерева должны быть переменные или
константы, в противном случае процесс
генерации необходимо рекурсивно
продолжить. Если структура дерева
становится сложной, то заранее
устанавливается максимальная высота
дерева, равная числу ребер дерева,
которое содержит самый длинный путь
от корневой вершины до некоторой
концевой вершины. В экспериментахKoza
максимальная высота дерева колеблется
от шести, для популяции P(0), до 17 в более
поздних популяциях P(t).
Для обеспечения многообразия популяции P(0) в ходе инициализации Koza предлагает применить так называемый half-ramping способ, согласно которому деревья разной высоты генерируются с одинаковой частотой. Правда этот способ не лишен недостатка, связанного с не совсем случайным характером генерируемых деревьев и в IbaH. предлагаются альтернативные методы «случайной» генерации деревьев начальной популяции P(0), причем дупликация идентичных хромосом в P(0) считается недопустимой.
Оценка решений. На 2-м этапе оценивается fitness– функциякаждой программы в P(0), указанным выше способом. Поскольку все программы выбраны случайно, то большинство из них будет иметь fitness– функцию, далекую от лучшего решения, поэтому в качестве оценки можно взять разницу между лучшим и худшим значением fitness– функции в популяции P(0).
Генерация новой популяции. Этот этап принято разделять на следующие подэтапы:
Выбор операторов эволюции. Основными операторами ГП являются репродукция и кроссинговер, применяемые с вероятностью
 и
и соответственно,
причем
соответственно,
причем (чаще
всего
(чаще
всего ).
).Селекция и репликация. Данный этап моделирования выполняется по схемам аналогичным ГА.
Образование новой популяции. Если к некоторой программе применяют оператор репродукции, то эта программа копируется в новую популяцию. Для проведения кроссинговера выбираются две родительские хромосомы (программы), случайным образом определяются точки кроссинговера и путем обмена образуются два потомка (рис. 5.2).



Рис. 5.2. Кроссинговер
При программной реализации на языке LISP кроссинговер сводится к обмену списками между двумя программами при сохранении синтаксической корректности вновь получаемых программ.
Проверка критерия остановки. Процедура ГП является итерационной, и критерии ее остановки аналогичны критериям для обычных генетических алгоритмов.
В качестве примера, иллюстрирующего рассмотренную процедуру, возьмем следующую проблему:
Проблема двух параллелепипедов


H1
H2
L1
B1 L2
B2
Рис. 5.3. Два параллелепипеда
Пусть два параллелепипеда задаются шестью независимыми переменными L1, B1, H1, L2, B2, H2 и одной зависимой переменной D (рис.5.3.). В таблице 5.2 представлены 10 различных вариантов исходных значений для шести независимых переменных, а также разность объемов D= L1*B1*H1 - L2*B2*H2.
Таблица 5.2
Исходные данные для вычисления разности объемов двух параллелепипедов
|
|
L1 |
B1 |
H1 |
L2 |
B2 |
H2 |
D |
|
1 |
3 |
4 |
7 |
2 |
5 |
3 |
54 |
|
2 |
7 |
10 |
9 |
10 |
3 |
1 |
600 |
|
3 |
10 |
9 |
4 |
8 |
1 |
6 |
312 |
|
4 |
3 |
9 |
5 |
1 |
6 |
4 |
111 |
|
5 |
4 |
3 |
2 |
7 |
6 |
1 |
-18 |
|
6 |
3 |
3 |
1 |
9 |
5 |
4 |
-171 |
|
7 |
5 |
9 |
9 |
1 |
7 |
6 |
363 |
|
8 |
1 |
2 |
9 |
3 |
9 |
2 |
-36 |
|
9 |
2 |
6 |
8 |
2 |
6 |
10 |
-24 |
|
10 |
1 |
10 |
7 |
5 |
1 |
45 |
-155 |
Пусть до получения корректных значений величины D установлены следующие стартовые условия:
terminal set T ={ L1, B1, H1, L2, B2, H2};
function set F ={+, -, *, %};
rohfitness-функция (функция соответствия) указывает абсолютную ошибку, определяемую разностью между действительным значением D и тем значением, которое получается программно
 ;
;выигрыш определяется числом случаев, когда сравниваемые величины D различаются менее, чем на 0.01:μ=4000;
программа останавливается, если число выигрышей равно 10, либо tmax=51.
В результате моделирования эволюции для популяции P(0) лучшая fitness-функция имела значение 783, что соответствовало следующейформе:
(*(―(―B1L2)(―B2H1))(+(―H1H1)(*H1L1))) или H1L1(B1+H1―B2―L2).
Видно, что в данном математическом выражении отсутствует переменная H2 и оно мало похоже на корректное решение. Далее, лучшие fitness-функции в популяциях P(1)-P(6) имели следующие значения: 778, 510, 138, 117, 53, 51. Лучшая программа на восьмом этапе эволюции дала значение fitness, равное 4.44, что соответствовало LISP-выражению следующего вида:
(―(―(*B1H1)L1)(*(*L2H2)B2))(%(+B1L1)×(―(―L1B2)(+(+B2L2)(*L2B2)))))
или B1H1L1―B2H2L2―(B1+L1)(L1―2B2―L2―L2B2).
Видно, что, за исключением последнего ошибочного терма, данное выражение соответствует корректному решению. Наконец, на 11-м шаге эволюции была получена правильная программа вида:
(―(*(*B1H1)(L1)(*(*L2H2)B2)) или L1B1H1―L2B2H2.
5.4. Перспективные направления развития гп
Рассмотрим наиболее перспективные направления исследований, проведенных Koza J.R. [84, 85]. Следует отметить следующее:
Автоматически определяемые функции (ADF), идея которых состоит в повышении эффективности ГП за счет модульного построения программ, состоящих из главной программы и ADF-модулей, генерируемых в ходе моделирования эволюции. При этом до начала эволюции определяется архитектура программы, число ADF-модулей и параметры каждой (аргументы) ADF.
Особый интерес представляют интеллектуальные гибридные системы, такие, как нейроэволюционные сети и нечеткие эволюционные системы, которые, по словам Л. Заде, являются «waveofthefuture». Другая область, где ЭА могли бы сыграть важную роль – компьютерное моделирование и робототехника на основе многоагентных систем.
Контрольные вопросы и задания для самостоятельной работы по главе 5
5.1.Задачи оптимизации и эволюционные алгоритмы?
5.2.Виды алгоритмов, относимых к эволюционным?
5.3. Классический генетический алгоритм?
5.4. Теоретические основы функционирования генетических алгоритмов?
5.5. Эволюционные стратегии?
5.6. Эволюционное программирование?
5.7. Генетическое программирование?
5.8. Особые технологии в эволюционных алгоритмах?
5.9. Применение эволюционных алгоритмов для проектирования нейронных
сетей?
5.10. Эволюционные алгоритмы и нечеткие системы для контроля эволюции?
Глава 6. Введение в нейронные сети
6.1. Алгоритмы их обучение и эластичные нейро-нечеткие системы
Проблема машинной имитации человеческих мыслей воодушевляет ученых уже несколько столетий. Более 50 лет назад были созданы первые электронные модели нервных клеток. В это же время появилось много работ по новым математическим моделям и обучающим алгоритмам. Сегодня так называемые нейронные сети представляют наибольший интерес в этой области [81, 91]. Они используют множество простых вычислительных элементов, называемых нейронами, каждый из которых имитирует поведение отдельной клетки человеческого мозга. Принято считать, что человеческий мозг- это естественная нейронная сеть, а модель мозга-это просто нейронная сеть. На рис. 6.1. показана базовая структура нейронной сети:
Входной сигнал Выходной сигнал

Входной слой -1.Внутренний слой; 2. Внутренний слой - Выходной слой
Рис. 6.1. Базовая структура нейронной сети (фрагмент).
Каждый нейрон в нейронной сети осуществляет преобразование входных сигналов в выходной сигнал и связан с другими нейронами. Входные нейроны имитируют так называемый интерфейс нейронной сети. Нейронная сеть, показанная на рис. 6.1., имеет слой, принимающий входные сигналы, и слой, генерирующий выходные сигналы. Информация вводится в нейронную сеть через входной слой. Все слои нейронной сети обрабатывают эти сигналы до тех пор, пока они не достигнут выходного слоя.
Задача нейронной сети - преобразование информации требуемым образом. Для этого сеть предварительно обучается. При обучении используются идеальные (эталонные) значения пар «входы-выходы» или «учитель», который оценивает поведение нейронной сети. Для обучения используется так называемый обучающий алгоритм [91]. Ненастроенная нейронная сеть не способна отображать желаемого поведения. Обучающий алгоритм модифицирует отдельные нейроны сети и веса ее связей таким образом, чтобы поведение сети соответствовало желаемому поведению.
6.2. Имитация нервных клеток
Исследователи
в области нейронных сетей проанализировали
множество моделей клеток человеческого
мозга.Человеческий мозг состоит из
более, чем
 нервных
клеток, имеющих более
нервных
клеток, имеющих более взаимосвязей.
На рис. 6.2. показана упрощенная схема
такого человеческого нейрона.
взаимосвязей.
На рис. 6.2. показана упрощенная схема
такого человеческого нейрона.

Рис. 6.2. Упрощенная схема человеческого нейрона.
Сама по себе клетка состоит из ядра и внешней электронной мембраны. Каждый нейрон имеет уровень активации, лежащий в диапазоне между максимумом и минимумом, следовательно, в отличие от булевой логики, существует более чем два уровня активации.
Для увеличения или уменьшения активности данного нейрона другими нейронами существуют так называемые синапсы. Они переносят величину активности от нейрона-отправителя к нейрону-получателю. Если синапс является возбуждающим, то величина активности нейрона-отправителя увеличивает активность нейрона-получателя. Если синапс является тормозящим, то величина активности нейрона-отправителя уменьшает активность нейрона-получателя. Синапсы различаются не толькопо признаку торможения или возбуждения нейрона-получателя, но также и по суммарному воздействию (синаптическая мощность). Выходной сигнал каждого нейрона передается по так называемому аксону, который заканчивается более чем 10000 синапсами, влияющими на другие нейроны.
Рассмотренная модель нейрона лежит в основе большинства сегодняшних применений нейронной сети. Отметим, что данная модель является лишь очень грубым приближением действительности. На самом деле мы не можем смоделировать даже один единственный человеческий нейрон; это выше человеческих возможностей в моделировании. Следовательно, любая работа, базирующаяся на этой простой модели нейрона, не способна точно имитировать человеческий мозг. Однако многие успешные применения, использующие этот метод, обеспечили успех нейронным сетям, базирующимся на простой модели нейрона.
6.3. Математическая модель нейрона
Множество
математических моделей нейрона может
быть построено на более простой концепции
строения нейрона. На рис.6.3. показана
наиболее общая схема. Так называемая
суммирующая функция объединяет все
входные сигналы
 ,
которые поступают от нейронов-отправителей.
Значением такого объединения является
взвешенная сумма, где веса
,
которые поступают от нейронов-отправителей.
Значением такого объединения является
взвешенная сумма, где веса представляют собой синаптические
мощности. Возбуждающие синапсы имеют
положительные веса, а тормозящие
синапсы-отрицательные веса. Для выражения
нижнего уровня активности нейронак
взвешенной сумме прибавляется компенсация
(смещение)
представляют собой синаптические
мощности. Возбуждающие синапсы имеют
положительные веса, а тормозящие
синапсы-отрицательные веса. Для выражения
нижнего уровня активности нейронак
взвешенной сумме прибавляется компенсация
(смещение) .
.

Рис.6.3. Простая математическая модель нейрона.
Так
называемая функция активации рассчитывает
выходной сигнал нейрона

по
уровню активности
 .
Функция активации обычно является
сигмоидальной, как показано в правой
нижней рамке на рис. 6.4. Другими возможными
видами функций активации являются
линейная и радиально-симметричная
функции, показанные на рис. 6.4.
.
Функция активации обычно является
сигмоидальной, как показано в правой
нижней рамке на рис. 6.4. Другими возможными
видами функций активации являются
линейная и радиально-симметричная
функции, показанные на рис. 6.4.

Рис. 6.4. Функции активации нейронов (возбуждение выходного слоя):
Здесь: а-область возбуждения букв; б-область возбуждения цифр; в- область
возбуждения специальных знаков.
6.4. Обучение нейронных сетей
Существует множество способов построения нейронных сетей. Они различаются своей архитектурой и методами обучения.
Первый шаг в проектированиинейронной сети состоит в ее обучении желаемому поведению. Это-фаза обучения. Для этого используется так называемая обучающая выборка или учитель. Учитель-это либо математическая функция, либо лицо, которое оценивает качество поведения нейронной сети. Поскольку нейронные сети в основном используются в сложных применениях, где нет хороших математических моделей, то обучение производится с помощью обучающей выборки, то есть эталонных пар «входы-выходы».
После завершения обучения нейронная сеть готова к использованию. Это-рабочая фаза. В результате обучения нейронная сеть будет вычислять выходные сигналы, близкие к эталонным данным при соответствующих входных сигналах. При промежуточных входных сигналах сеть аппроксимирует необходимые выходные величины. Поведение нейронной сети в рабочей фазе детерминировано, то есть каждой комбинации входных сигналов на выходе будут одни и те же сигналы. На протяжении рабочей фазы нейронная сеть не обучается. Это очень важно для большинства технических применений, поскольку система не будет стремиться к экстремальному поведению [91].
Собаки Павлова. Как же обучается нейронная сеть? Как правило,это демонстрируется на примере известных собак Павлова. Когда он показывал собакам еду, у них выделялась слюна. В собачьих клетках устанавливались звонки. Когда звонил звоночек, у собак не выделялась слюна, т.е. они не видели разницу между звонком и едой. Тогда Павлов стал обучать собак иначе, каждый раз используя звоночек при предъявлении пищи. После этого, даже при отсутствии еды, наличие звоночка вызывало у собак слюну.
На рис. 6.5. показано, как простая модель нейрона может быть представлена на примере «собаки Павлова». Имеется два входных нейрона: один из них соответствует тому, что собака видит пищу, другой-наличию звонка. Оба входных нейрона имеют связи с выходным нейроном. Эти связи соответствуют синапсам, а толщина линий-весам синапсов. Перед обучением собака реагирует лишь на еду, но не на звонок. Следовательно, линия между входным и выходным нейронами являетсяжирной, в то время как линия между правым входным и выходным нейронами является очень толстой.

Рис. 6.5. Принцип «эксперимента Павлова» над собаками: моделирование
реакции на изображение.
Правило обучения Хебба. Совершенно очевидно, что звонок при предъявлении пищи вырабатывает ассоциацию между ним и едой. Следовательно, выходная линия также становится толще, поскольку увеличивается вес синапса. На результатах этих наблюдений Хебб [81] в 1949 году предложил следующее обучающее правило: Увеличивать вес активного входа нейрона, если выход этого нейрона может быть активным. Уменьшить вес активного входа нейрона, если выход этого нейрона не может быть активным.
Это правило, названное правилом Хебба, предшествует всем обучающим правилам, включая наиболее используемый в настоящее время метод обратного распространения ошибки (errorbackpropagationalgorithm) [81].
6.5. Метод обратного распространения ошибки
Этот метод обучения многослойной нейронной сети называется обобщенным дельта-правилом или правилом errorbackpropagation (обратного распространения ошибки). Метод был предложен в 1986г. Руммельхартом, Маклеландом и Вильямсом [89]. Это ознаменовало возрождение интереса к нейронным сетям, который стал угасать в начале 70-х годов. Позже было обнаружено, что Паркер опубликовал подобные результаты в 1982г., а Вербос выполнил такую работу в 1984г. Однако такова природа науки, что ученые, работающие независимо друг от друга, не могут использовать все то прогрессивное, что есть в других областях, и поэтому часто случается повторение уже достигнутого. Однако статья Руммельхарта и др., опубликованная в журнале Nature (1986), является до сих пор наиболее цитируемой в этой области [81].
Обучение сети начинается с предъявления образа и вычисления соответствующей реакции (рис. 6.5.). Сравнение с желаемой реакцией дает возможность изменять веса связей таким образом, чтобы сеть на следующем шаге могла выдавать более точный результат. Обучающее правило обеспечивает настройку весов связей. Информация о выходах сети является исходной для нейронов предыдущих слоев. Эти нейроны могут настраивать веса своих связей для уменьшения погрешности на следующем шаге. Когда мы предъявляем ненастроенной сети входной образ, она будет давать некоторый случайный выход. Функция ошибки представляет собой разность между текущим выходом сети и идеальным выходом, который необходимо получить. Для
успешного обучения сети требуется приблизить выход сети к желаемому выходу, т.е. последовательно уменьшать величину функции ошибки. Это достигается настройкой межнейронных связей. Обобщенное дельта-правило обучает сеть путем вычисления функции ошибки для заданного входа с последующим ее обратным распространением (вот откуда название) от каждого слоя к предыдущему. Каждый нейрон в сети имеет свои веса, которые настраиваются, чтобы уменьшить величину функции ошибки. Для нейронов выходного слоя известны их фактические и желаемые значения выхода. Поэтому настройка весов связей для таких нейроновявляется относительно простой. Однако для нейронов предыдущих слоев настройка не столь очевидна. Интуитивно ясно, что нейроны внутренних слоев, которые связаны с выходами, имеющими большую погрешность, должны изменять свои веса значительно сильнее, чем нейроны, соединенные с почти корректными выходами. Другими словами, веса данного нейрона должны изменяться прямо пропорционально ошибке тех нейронов, с которыми данный нейрон связан. Вот почему обратное распространение этих ошибок через сеть позволяет корректно настраивать веса связей между всеми слоями. В этом случае величина функции ошибки уменьшается и сеть обучается.
Основные соотношения метода обратного распространения ошибки получены в [81] при следующих обозначениях:
 величина
функции ошибки для образа
величина
функции ошибки для образа
 ;
;
 желаемый
выход нейрона
желаемый
выход нейрона для
образа
для
образа ;
;
 действительный
выход нейрона
действительный
выход нейрона
 для
образа
для
образа ;
;
 вес
связи между
вес
связи между
 м
и
м
и м
нейронами.
м
нейронами.
Пусть функция ошибки прямо пропорциональна квадрату разности между действительным и желательным выходами для всей обучающей выборки:
 (6.1)
(6.1)
Множитель
 вводится здесь для упрощения операции
дифференцирования.
вводится здесь для упрощения операции
дифференцирования.
Активация
каждого нейрона
 для
образа
для
образа записывается
в виде взвешенной суммы:
записывается
в виде взвешенной суммы:
 .
(6.2)
.
(6.2)
Выход
каждого нейрона
 является
значением пороговой функции
является
значением пороговой функции ,
которая активизируется взвешенной
суммой. В многослойной сети это обычно
переходная функция, хотя может
использоваться любая непрерывно
дифференцируемая монотонная функция:
,
которая активизируется взвешенной
суммой. В многослойной сети это обычно
переходная функция, хотя может
использоваться любая непрерывно
дифференцируемая монотонная функция:
 (6.3)
(6.3)
Тогда можно будет записать по правилу цепочки:
 (6.4)
(6.4)
Для второго сомножителя в (6.4), используя (6.2), получаем:
 (6.5)
(6.5)
поскольку
 за исключением случая
за исключением случая ,
когда эта производная равна единице.
,
когда эта производная равна единице.
Изменение ошибки как функция изменения входов нейрона определяется так:
 (6.6)
(6.6)
Поэтому (6.4) преобразуется к виду:
 (6.7)
(6.7)
Следовательно,
уменьшение величины означает
изменение веса пропорционально
означает
изменение веса пропорционально
 (6.8)
(6.8)
где
 коэффициент
пропорциональности, влияющий на скорость
обучения.
коэффициент
пропорциональности, влияющий на скорость
обучения.
Теперь
нам необходимо знать значение
 для
каждого нейрона. Используя (6.6) и правило
цепочки, можно записать:
для
каждого нейрона. Используя (6.6) и правило
цепочки, можно записать:
 (6.9)
(6.9)
Исходя из (6.3), записываем второй сомножитель в (6.8):
 .
(6.10)
.
(6.10)
Теперь рассмотрим первый сомножитель в (6.9). Согласно (6.1), нетрудно получить:
 (6.11)
(6.11)
Поэтому
 (6.12)
(6.12)
Последнее соотношение является полезным для выходных нейронов, поскольку для них известны целевые и действительные значения выходов. Однако для нейронов внутренних слоев целевые значения выходов не известны.
Таким
образом, если нейрон
 не
выходной нейрон, то снова, используя
правило цепочки, а также соотношения
(6.2) и (6.6), можно записать:
не
выходной нейрон, то снова, используя
правило цепочки, а также соотношения
(6.2) и (6.6), можно записать:
 (6.13)
(6.13)
 (6.14)
(6.14)
Здесь
сумма по исчезает, поскольку частная производная
не равна нулю только лишь в одном случае,
также как и в (6.4). Подставив (6.11) в (6.8),
получим окончательное выражение:
исчезает, поскольку частная производная
не равна нулю только лишь в одном случае,
также как и в (6.4). Подставив (6.11) в (6.8),
получим окончательное выражение:
 (6.15)
(6.15)
Уравнения (6.12) и (6.15) составляют основу метода обучения многослойной сети.
Преимущество использования сигмоидной функции в качестве нелинейного элемента состоит в том, что очень напоминает шаговую функцию и, таким образом, может демонстрировать поведение, подобное, естественному нейрону [81]. Сигмоидная функция определяется как
 ,
(6.16)
,
(6.16)
и
имеет диапазон

Здесь
 положительная
константа, влияющая на растяжение
функции: увеличение
положительная
константа, влияющая на растяжение
функции: увеличение сжимает
функцию, а при
сжимает
функцию, а при функция
функция приближается
к функции Хевисайда [94]. Этот коэффициент
может использоваться в качестве параметра
усиления, поскольку для слабых входных
сигналов угол наклона будет довольно
крутым и функция будет изменяться
быстро, производя значительное усиление
сигнала. Для больших входных сигналов
угол наклона и, соответственно, усиление
будут намного меньшими. Это означает,
что сеть может принимать большие сигналы
и при этом оставаться чувствительной
к слабым изменениям сигнала.
приближается
к функции Хевисайда [94]. Этот коэффициент
может использоваться в качестве параметра
усиления, поскольку для слабых входных
сигналов угол наклона будет довольно
крутым и функция будет изменяться
быстро, производя значительное усиление
сигнала. Для больших входных сигналов
угол наклона и, соответственно, усиление
будут намного меньшими. Это означает,
что сеть может принимать большие сигналы
и при этом оставаться чувствительной
к слабым изменениям сигнала.
Однако
главный смысл в использовании данной
функции состоит в том, что она имеет
простую производную, и это значительно
облегчает применение backpropagation-метода.
Если выход нейрона
 задается
как
задается
как
 (6.17)
(6.17)
то
производная по отношению к данному
нейрону
 вычисляется
так:
вычисляется
так:
 (6.18)
(6.18)
т.е., является простой функцией от выходов нейронов.
6.6. Алгоритм настройки нейронной сети
Приведен
алгоритм настройки многослойной
нейронной сети с использованием
backpropagation-правила
обучения (рис. 6.1. - 6.8.). Для его применения
необходимо, чтобы нейроны имели непрерывно
дифференцируемую нелинейную пороговую
функцию активации. Пусть это будет
сигмоидная функция
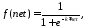 поскольку
она имеет простую производную.
поскольку
она имеет простую производную.
Алгоритм обучения, в общем виде, состоит в следующем:
Задать начальные значения весов и порогов каждого нейрона.
Всем весам и порогам присваиваются малые случайные значения.
Представить входной и выходной образы из обучающей выборки.
Пусть
 текущий входной образ,
текущий входной образ, -
текущий выходной образ из обучающей
выборки, где
-
текущий выходной образ из обучающей
выборки, где число
нейронов входного слоя,
число
нейронов входного слоя,
 число
нейронов выходного слоя. При этом
число
нейронов выходного слоя. При этом
 (смещение)
и
(смещение)
и .
.
При
решении задач классификации образ
 может
состоять из нулей, кроме одного элемента,
равного 1, который и будет определять
класс текущего выходного образа.
может
состоять из нулей, кроме одного элемента,
равного 1, который и будет определять
класс текущего выходного образа.
Рассчитать действительные значения выходов.
Значения выходов нейронов каждого слоя рассчитываются как
 (6.19)
(6.19)
и
передаются на входы нейронов следующего
слоя. Выходные значения нейронов
выходного слоя равны
 .
.
Провести модификацию весов связей.
Начиная от выходного слоя и, двигаясь в обратном направлении, необходимо изменять веса связей следующим образом:
 (6.20)
(6.20)
где
 вес
связи между
вес
связи между м
и
м
и м
нейронами на
м
нейронами на м
шаге;
м
шаге;
 скорость
обучения;
скорость
обучения;
 скорость
изменения ошибки для нейрона
скорость
изменения ошибки для нейрона при
предъявлении образа
при
предъявлении образа .
.
Для нейронов выходного слоя
 (6.21)
(6.21)
для нейронов внутренних слоев
 (6.22)
(6.22)
где под знаком суммы стоят величины, относящиеся к нейронам последующего слоя.

Рис. 6.6. Локализация возбуждения нейронов выходного слоя.


![]()
в г
Рис. 6.7. Матрица следования при обучении первому эталону:
а – общий вид; б – первый шаг преобразования матрицы следования;
в –вид после исключения нейронов В1, А1 и 6; г – после исключения
«невозбужденных» входов.

Рис. 6.8. Нейросеть, обученная первому эталону.
В результате имеем сеть (ее трассировку), обученную реакции на эталон одной комбинации событий, где единичные веса соответствуют жирным стрелкам.
Контрольные вопросы и задания для самостоятельной работы по главе 6
6.1. Понятие нейронных сетей. Однослойные искусственные нейронные сети?
6.2. Многослойные искусственные нейронные сети?
6.3. Архитектура сетей?
6.4. Обучение искусственных нейронных сетей?
6.5. Персептроны?
6.6. Нейронные сети Хопфилда и Хэмминга?
6.7. Нейронные сети и алгоритмы их обучения?
6.8. Гибридные нейронные сети, введение?
Глава 7. Другие методы нечетких технологий для построения
интеллектуальных технологий информатики
7.1. Введение в теорию возможностей и смысла
7.1.1. Неопределенность и неточность
Неопределенность и неточность можно рассматривать как две противоположные точки зрения на одну и ту же реальность - неполноту информации [95]. Будем предполагать, что информация выразима в форме логического высказывания, содержащего предикаты и в случае необходимости – квантификаторы. Под базой знаний будем понимать множество сведений, имеющихся у субъекта или группы субъектов или содержащихся в информационной системе и относящихся к одной и той же проблемной области. Тогда предикаты, появляющиеся при выражении информации, могут интерпретироваться как подмножества одного и того же универсального множества. Любое высказывание может также рассматриваться как утверждение, относящееся к появлению некоторого события. В свою очередь, события представимы в виде подмножеств этого универсального множества, называемого «достоверным событием».
Таким образом, имеютсятри эквивалентных способа анализа множества данных в зависимости от того, делается ли акцент на структуре (логическая точка зрения), содержании (теоретико-множественнаяточка зрения) этой информации или на ее отношении к действительным фактам (событийная точка зрения).
Определим информационную единицу четверкой (объект, признак, значение, уверенность). Признаку соответствует функция, задающая значение (множество значений) объекта или предмета, название которого фигурирует в информационной единице. Это значение соответствует некоторому предикату, т.е. подмножеству универсального множества, связанного с данным признаком.
Уверенность есть показатель надежности информационной единицы.
Очевидно, что четыре компонента, образующие информационную единицу, могут быть составными (множество объектов, множество признаков, n-местный предикат, разные степени уверенности). Кроме того, могут вводиться переменные, особенно на уровне объектов, если информация содержит квантификаторы.
В данном контексте можно четко различать понятия неточности и неопределенности: неточность относится к содержанию информации (составляющая «значение» в четверке), а неопределенность – к ее истинности, понимаемой в смысле соответствия действительности (составляющая «уверенность»).
Степень неопределенности информации отражают с помощью квалификаторов (модальностей) типа «вероятно», «возможно», «необходимо», «правдоподобно» и др., которым мы попытаемся придать точный смысл.
Модальность «вероятно» исследовалась на протяжении уже двух веков. Вероятностьимеет две различные интерпретации. Одна из них – физическая (статистическая), связанная с проведением статистических испытаний и определением частоты появления события. Другая - эпистомологическая, относящаяся к субъективному суждению. Модальности «возможно» и «необходимо» изучались еще Аристотелем, который подчеркнул факт их двойственности (если некоторое событие является необходимым, то противоположное ему событие невозможно). В противоположность понятию «вероятно» понятия «возможно» и «необходимо» часто рассматривались в рамках двузначной логики, как категории «все» или «ничего». Но понятие «возможно», как и понятие «вероятно», допускает две интерпретации: физическую (мера трудоемкости выполнения некоторого действия) и эпистомологическую (суждение, которое мало связывает его автора). Наоборот, «необходимо» - гораздо более утвердительное понятие в физическом или эпистомологическом смысле (субъективная необходимость есть определенность, уверенность). Естественно допустить наличие степеней возможности и необходимости, как степеней вероятности (оттенки возможности находятся уже в естественном языке, поскольку можно сказать, например, «очень возможно»). Правдоподобность и доверие имеют чисто эпистемологическую интерпретацию и связаны с возможностью и необходимостью соответственно. Каждое из этих понятий соответствует некоторому способу вывода из заданной базы знаний: заслуживает доверия все то, что непосредственно дедуктивно выводится из базы знаний, а правдоподобно все то, что не противоречит ей (индуктивная точка зрения).
Модальность – одно из важнейших свойств суждений, так как в нем выражается степень существенности того или иного признака для данного предмета, отображенного в суждении. Утверждение о вероятности наступления того или иного события, высказанной в проблематическом суждении, основывается на исследовании фактов, на изучении объективной действительности [96, 97].
Примерами неопределенных высказываний являются высказывания:
«Вероятно,
что рост Жана не мене 1,70м»
 (рост,
Жан,
(рост,
Жан, 1,70м,
вероятно).
1,70м,
вероятно).
«Вероятность того, что завтра выпадет 10мм осадков, равна 0,5»
 (количество,
осадки завтра, 10мм, вероятность = 0,5).
(количество,
осадки завтра, 10мм, вероятность = 0,5).
Будем называть информационную единицу точной, если подмножество, соответствующее «значение» в наборе, является одноточечным, т.е. его нельзя разбить на части. В зависимости от способа анализа множества данных будем говорить об элементарном высказывании (т.е. не имплицированном никаким другим высказыванием, за исключением всегда ложного высказывания), синглетоне (теоретико-множественная точка зрения) или элементарном событии. Точность, конечно, зависит от способа определения базового множества (от его «зернистости», например от выбора единицы измерения). В других случаях будем говорить о неточной (impreise) информации.
Нечеткий, размытый, расплывчатый характер информации заключается в отсутствии четких границ у множества значений соответствующих объектов. Многие квалификаторы естественного языка расплывчаты, и для них характерна обобщенность.
В
качестве примера можно привести неточное
четкое высказывание:
 с точностью
с точностью (равенство,
(
(равенство,
( ),
с точностью
),
с точностью ,
1); неточное нечеткое высказывание: «
,
1); неточное нечеткое высказывание: « приблизительно равен
приблизительно равен »=(равенство,
(
»=(равенство,
( ,
, ),
приблизительно, 1).
),
приблизительно, 1).
Расплывчатый
термин «приблизительно» характеризует
совокупность значений, более или менее
адекватных
 .
.
Отсюда следует, что информация может быть одновременно нечеткой и неопределенной, о чем свидетельствует предложение: “Вероятно, что завтра выпадет много осадков”= (количество, осадки завтра, много, вероятно).
Для заданного множества сведений противоречиемежду неточностью и неопределенностью выражается в том, что с повышением точности содержания высказывания возрастает его неопределенность. И наоборот, неопределенный характер очной информации приводит в общем случае к некоторой неточности окончательных заключений, выводимых из этой информации.
7.1.2. Традиционные модели неточности и неопределенности
Традиционно используются два средства представления неполноты данных: теория вероятностей и теория ошибок [98-100].
Сегодня теория вероятностей – вполне разработанная математическая теория с ясными и общепринятыми аксиомами. Основная из них – аксиома аддитивности вероятностей совместных событий. Споры вокруг теории вероятностей касаются ее интерпретации: какого рода действительность хотят выразить с помощью этой математической модели? Исторически ею пользовались в основном для «подсчета шансов» в азартных играх, причем вероятность события определялась отношением числа благоприятных исходов к числу возможныхисходов. Недостаточная строгость этого определения породила школу частотной интерпретации вероятности, в которой вероятность рассматривается как предел частот наблюдаемых событий. Третья, так называемая субъективистская школа, попыталась избежать трудностей приложений теории, с которыми сталкиваются «частотники» (требований достаточного числа наблюдений, повторяемости экспериментов и т.д.), предложив интерпретацию вероятности как меры неуверенности. Значение вероятности при этом понимается как число, пропорциональное сумме, которую субъект согласится заплатить в том случае, если высказывание, являющееся по его утверждению истинным, в действительности окажется ложным. Было показано, что подобным образом определенная мера неуверенности подчиняется аксиомам теории вероятностей, если только поведение субъекта удовлетворяет условиям «рациональности» (Сэвидж) [98]. Исходя из этого «субъективисты» стали утверждать, что аксиомы Колмогорова – единственные рациональные условия для оценки чувства неуверенности. Субъективные вероятности не позволяют проводить различия между этими двумя уровнями информированности и представляются малопригодными в ситуациях, когда информации мало. В вероятностной модели особенно плохо учитывается предельный случай полного незнания, поскольку в ней всегда предполагается заданным множество взаимно независимых событий, которым в силу принципа максимума энтропии приписываются равные вероятности (в конечном случае). Тогда идентификация всех этих событий исключена и кажется спорным, что значения неопределенности, связанные с этими событиями, зависят от числа рассматриваемых альтернатив, как в случае вероятностей.
С практической точки зрения очевидно, что числа, назначаемые субъектами для вероятностного описания уровня их информированности, должны рассматриваться как приближенные оценки. Теория субъективных вероятностей не затрагивает этот тип неточности и полагает, что «рациональный индивидуум» должен в результате процедур оценивания задавать точные числа.
Отметим
также, что теория вероятностей
представляется слишком нормативной
для выражения всех аспектов субъективного
суждения. Теория же ошибок [99, 101], часто
используемая в физике, отражает лишь
неточность средств измерения, выраженную
в интервальной форме, в величинах,
оцениваемых с помощью этих средств. То
есть, в математическом плане определяется
образ отображения, аргументы которого
суть подмножества. Теория ошибок не
признает вариантов: если неизвестно
точное значение параметра, то точно
известны пределы его изменения. Заметим,
что когда задана мера неточности
 величины
величины ,
то предложения типа: «
,
то предложения типа: « принадлежит
интервалу-
принадлежит
интервалу- будут
естественным образом характеризоваться
с помощью модальностей «возможно» и
«необходимо», так как:
будут
естественным образом характеризоваться
с помощью модальностей «возможно» и
«необходимо», так как:
если пересечение
 непусто,
то «
непусто,
то « »,
возможно, истинно;
»,
возможно, истинно;если
 ,
то «
,
то « »
с необходимостью истинно.
»
с необходимостью истинно.
Здесь
выявляются связи между этими модальностями
и теорией множеств: возможность
оценивается с помощью
теоретико-множественногопересечения
содержаний
 и
и двух
высказываний: «
двух
высказываний: « »
и «
»
и « »,
а необходимость вычисляется, исходя из
отношений вложенности.
»,
а необходимость вычисляется, исходя из
отношений вложенности.
Принцип «все или ничего» - характерная черта теории ошибок[98], тогда как в теории вероятностей учитываются оттенки, градации неопределенности. Это вводит определенные различия между ними. Теория вероятностей не обобщает теорию ошибок, поскольку распределение вероятностей для функции равномерно распределенных случайных переменных (вероятностный аналог интервала ошибки) в общем случае не является равномерным, поэтому здесь предлагается вариант канонического обобщения теории ошибок, позволяющий учитывать оттенки неопределенности.
Часто оказывается, что неточность типа ошибки измерения присутствует в самой серии испытаний, проводимых для определенияслучайного явления. В этом случае без введения дополнительных гипотез не удается представить полученную информацию в чисто вероятностнойформе, так как основная гипотеза, обеспечивающая применимость теории вероятностей в математической статистике, состоит в том, что пространство испытаний необходимо поставить во взаимно однозначное соответствие с пространством событий [46]. С каждым событием связывается множество его реализаций (непустое, если только данное событие не является невозможным), и для любой пары различных событий существует, по крайней мере, одно испытание, в котором одно событие исключает другое. Эта гипотеза позволяет разбить достоверное событие на элементарные события, каждое из которых соответствует какой-то реализации. При обработке статистических данных это приводит к предположению о существовании такого разбиения множества реализаций, что результат всякого эксперимента можно будет сопоставить с одним, и только одним элементом этого разбиения, т.е., результат- есть элементарное событие.
Можно отыскать такие ситуации, в которых гипотеза о разбиении испытаний не справедлива. Например, если измерения дают интервалы ошибок, то вообще мало шансов сопоставить их с непересекающимися классами реализаций. Физик часто оказывается в противоположной ситуации: ему требуется получить пересекающиеся интервалы, порожденныенезависимыми измерениями, чтобы иметь возможность с помощью проверки уменьшить ошибку измерения. Отсюда видно, что даже в случае «объективных» повторяющихся явлений не всегда можно напрямую применять теорию вероятностей. Вероятностная модель приспособлена к обработке точной, но распределенной по реализациям информации. Как только возникает неточность в отдельной реализации, модель становится неприменимой.
В то время как вероятности были приспособлены к обработке точных, но противоречивых результатов испытаний, меры возможности станут естественным средством для построения баз знаний, хотя и неточных, но согласованных.
7.1.3. Меры неопределенности
Рассмотрим
множество событий, связанных с базой
неточных и неопределенных знаний,
понимаемых как подмножества универсального
множества
 ,
называемого достоверным событием.
Предполагается, что каждому событию
,
называемого достоверным событием.
Предполагается, что каждому событию можно поставить в соответствие
действительное число
можно поставить в соответствие
действительное число ,
задаваемое субъектом – «хранителем»
базы знаний (или получаемое с помощью
процедуры переработки информации,
хранящейся в памяти информационной
системы). Значение
,
задаваемое субъектом – «хранителем»
базы знаний (или получаемое с помощью
процедуры переработки информации,
хранящейся в памяти информационной
системы). Значение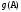 оценивает
степень уверенности, имеющейся у субъекта
по отношению к событию
оценивает
степень уверенности, имеющейся у субъекта
по отношению к событию с
учетом текущего уровня информированности.
По определению величина
с
учетом текущего уровня информированности.
По определению величина растет
с увеличением уверенности. Более того,
если
растет
с увеличением уверенности. Более того,
если -
достоверное событие, то полагают
-
достоверное событие, то полагают ,
а если
,
а если -невозможное
событие, то полагают
-невозможное
событие, то полагают .
.
Имеем
 и
и .
(7.1)
.
(7.1)
Однако
 (соответственно
(соответственно )
вообще говоря, не означает, что
)
вообще говоря, не означает, что непременно является достоверным
(соответственно, невозможным) событием.
непременно является достоверным
(соответственно, невозможным) событием.
Наиболее
слабая аксиома для обеспечениянекоторого
минимума согласованности при определении
функции множества
 ,
которую можно себе представить - это
монотонность по включению
,
которую можно себе представить - это
монотонность по включению
 (7.2)
(7.2)
Эта
аксиома выражает следующее: если событие
 влечет за собой другое событие
влечет за собой другое событие ,
то всегда имеется, по меньшей мере,
столько же уверенности появления
,
то всегда имеется, по меньшей мере,
столько же уверенности появления ,
сколько в появлении
,
сколько в появлении .
.
Такие функции множества были предложены Сугэно [21] для оценки неопределенности под названием нечеткие меры. Кофман А. [102] предложил термин «оценка». Мы принимаем здесь название мера неопределенности.
Следует напомнить, что эти функции множества не являются обычными мерами, поскольку они могут не быть аддитивными, за исключением специально оговоренных случаев.
Если
 -
бесконечное множество, то можно ввести
условие непрерывности в виде
-
бесконечное множество, то можно ввести
условие непрерывности в виде
 (7.3)
(7.3)
для
любой последовательности
 вложенных
множеств вида
вложенных
множеств вида
 или
или

Будем предполагать, что мера неопределенности удовлетворяет условию (7.3)
по крайней мере для одной из двух указанных последовательностей вложенных множеств.
7.1.4. Меры возможности и необходимости
Следующие
неравенства непосредственно вытекают
из аксиомы монотонности (7.2) и характеризуют
объединение
 или
пересечение
или
пересечение событий:
событий:
 (7.4)
(7.4)
 (7.5)
(7.5)
Предельным
случаем мер неопределенности оказываются
функции множества

такие,
 (7.6)
(7.6)
Они
называются мерами возможности по Заде
[12-17]. Если условие справедливо для любой
пары непересекающихся множеств
 ,
то оно справедливо и для любой пары
множеств (событий).
,
то оно справедливо и для любой пары
множеств (событий).
Пусть
 достоверное
событие. Легко определить функцию
достоверное
событие. Легко определить функцию со
значениями из
со
значениями из ,
удовлетворяющую условию (7.6):
,
удовлетворяющую условию (7.6):
 (7.7)
(7.7)
Ясно,
что в данном контексте
 означает,
что событие
означает,
что событие возможно.
возможно.
Это
наводит на мысль о связи мер возможности
с теорией ошибок. В частности, если
 два
противоположных события (
два
противоположных события ( есть дополнение
есть дополнение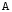 в
в ),
то имеем
),
то имеем
 (7.8)
(7.8)
Утверждение,
что события
 и
и одинаково возможны, соответствует
случаю полного незнания, когда событие
одинаково возможны, соответствует
случаю полного незнания, когда событие столь
же ожидаемо, что и противоположное
событие.
столь
же ожидаемо, что и противоположное
событие.
Наконец,
условие (7.6) согласуется с представлением
о возможности на уровне здравого смысла:
для того чтобы реализовать
 ,
достаточно реализовать самый
,
достаточно реализовать самый
«легкий» вариант из этих двух (наименее дорогостоящий), [103].
Когда
множество
 конечно, то всякую меру возможности
конечно, то всякую меру возможности можно
определить по ее значениям на одноточечных
подмножествах
можно
определить по ее значениям на одноточечных
подмножествах :
:
 (7.9)
(7.9)
где

 есть отображение из
есть отображение из в
в ,
называемоефункцией
распределения возможностей. Оно
является нормальным
в смысле
,
называемоефункцией
распределения возможностей. Оно
является нормальным
в смысле
 (7.10)
(7.10)
поскольку

Когда
множество
 бесконечно, то не гарантировано
существование функции распределения
возможностей. Соответствующее
распределение становится распределением
возможности лишь тогда, когда аксиома
(7.6) расширяется на случай бесконечных
объединений событий [97]. В прикладных
задачах можно всегда исходить из функции
распределения возможностей и строить
меру возможности
бесконечно, то не гарантировано
существование функции распределения
возможностей. Соответствующее
распределение становится распределением
возможности лишь тогда, когда аксиома
(7.6) расширяется на случай бесконечных
объединений событий [97]. В прикладных
задачах можно всегда исходить из функции
распределения возможностей и строить
меру возможности с
помощью формулы (7.9). В наиболее общем
случае меры возможности не удовлетворяют
аксиоме непрерывности (7.3) для убывающих
последовательностейвложенных множеств.
Другой граничный случай мер неопределенности
получается при достижении равенства в
формуле (7.5). При этом определяется класс
функций множества, называемыхмерами
необходимости
и обозначаемых
с
помощью формулы (7.9). В наиболее общем
случае меры возможности не удовлетворяют
аксиоме непрерывности (7.3) для убывающих
последовательностейвложенных множеств.
Другой граничный случай мер неопределенности
получается при достижении равенства в
формуле (7.5). При этом определяется класс
функций множества, называемыхмерами
необходимости
и обозначаемых
 ,
которые удовлетворяют аксиоме,
двойственной аксиоме (7.6):
,
которые удовлетворяют аксиоме,
двойственной аксиоме (7.6):
 (7.11)
(7.11)
Легко
построить функцию
 со
значениями в {0,1}, исходя из информации
о достоверном событии и полагая
со
значениями в {0,1}, исходя из информации
о достоверном событии и полагая
 (7.12)
(7.12)
Здесь
 означает,
что
означает,
что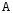 -
достоверное событие (с необходимостью
истинное).
-
достоверное событие (с необходимостью
истинное).
Более
того, легко видеть, что функция множества
 удовлетворяет аксиоме (7.11) тогда, и
только тогда, когда функция
удовлетворяет аксиоме (7.11) тогда, и
только тогда, когда функция ,
определяемая в виде
,
определяемая в виде
 (7.13)
(7.13)
является
мерой возможности. Формулы (7.12) и (7.13)
поясняют название «меры необходимости»
для функции
 [97].
Формула (7.13) есть численное выражение
отношения двойственности между
модальностями «возможно» и «необходимо»
(в модальной логике), постулирующее, что
некоторое событие необходимо, когда
противоположное событие невозможно.
Это отношение двойственности означает,
что всегда можно построить функцию
распределения необходимости исходя из
функции распределения возможностис
помощью формулы
[97].
Формула (7.13) есть численное выражение
отношения двойственности между
модальностями «возможно» и «необходимо»
(в модальной логике), постулирующее, что
некоторое событие необходимо, когда
противоположное событие невозможно.
Это отношение двойственности означает,
что всегда можно построить функцию
распределения необходимости исходя из
функции распределения возможностис
помощью формулы
 (7.14)
(7.14)
Меры необходимости удовлетворяют соотношению
 (7.15)
(7.15)
которое исключает одновременную необходимость двух противоположных событий. С помощью (7.13) и (7.15) (или (7.8)) нетрудно проверить, что
 (7.16)
(7.16)
Данное условие отвечает интуитивно представлению о том, что, прежде чем быть необходимым, событие должно быть возможным. К тому же имеются более сильные утверждения, чем аксиома (7.16):
 (7.17)
(7.17)
 (7.18)
(7.18)
7.1.5. Возможность и вероятность
Когда имеется информация о появлении событий в форме измеренных частот элементарных событий, полученная мера неопределенности естественным образом удовлетворяет аксиоме аддитивности
 (7.19)
(7.19)
т.е. становится вероятностной мерой, [97] которая, конечно, является монотонной в смысле условия (7.2). Формула (7.19) – вероятностный эквивалент аксиом (7.6) и (7.11).
Условие, эквивалентное условиям (7.9) и (7.14), для конечного случая записывается в виде
 (7.20)
(7.20)
где

Условие
нормировки
 является аналогом условия (7.10). Общая
черта вероятностных мер, мер возможности
и необходимости заключается в том, что
все они могут характеризоваться
некоторыми распределениями на элементах
универсального множества.
является аналогом условия (7.10). Общая
черта вероятностных мер, мер возможности
и необходимости заключается в том, что
все они могут характеризоваться
некоторыми распределениями на элементах
универсального множества.
Здесь аналогом соотношений (7.8) и (7.15) является хорошо известное соотношение
 (7.21)
(7.21)
в то время, как из (7.8) и (7.15), следуют лишь неравенства
 (7.22)
(7.22)
 (7.23)
(7.23)
Из
этих соотношений видно одно из главных
различий между возможностью и вероятностью.
Вероятность некоторого события полностью
определяет вероятность противоположного
события. Возможность (или необходимость)
некоторого события и возможность
(необходимость) противоположного ему
события связаны слабее; в частности,
для того, чтобы охарактеризовать
неопределенность по отношению к событию
 ,
требуется два числа
,
требуется два числа и
и ,
удовлетворяющие условию (7.17) или (7.18).
,
удовлетворяющие условию (7.17) или (7.18).
Когда моделируется субъективное суждение, кажется естественным стремление не устанавливатьжесткой связи между показателями, свидетельствующими в пользу некоторого события (степень необходимости), и показателями, свидетельствующими против него (степень возможности). В этой ситуации понятие вероятности оказывается менее гибким, чем понятие меры возможности.
Даже
когда сохраняется требование аддитивности,
можно построить меры возможности и
необходимости, если не требовать
дополнительно, чтобы значения вероятностей
(распределение p)
относились к элементарным событиям.
Точнее, пусть
 непустые,
попарно различные подмножества
непустые,
попарно различные подмножества (предполагаемого
конечным), с соответствующими значениями
вероятности
(предполагаемого
конечным), с соответствующими значениями
вероятности такими,
что
такими,
что
 (7.24)
(7.24)
и
 (7.25)
(7.25)
Величина
 понимается
как значение вероятности совокупности
элементарных событий, составляющих
понимается
как значение вероятности совокупности
элементарных событий, составляющих ,
причем здесь не оговаривается распределение
величины
,
причем здесь не оговаривается распределение
величины
 по
элементарным событиям. Подмножества
по
элементарным событиям. Подмножества
 называются
«фокальными элементами» и могут отражать
неточность наблюдений. В этой ситуации
вероятность события
называются
«фокальными элементами» и могут отражать
неточность наблюдений. В этой ситуации
вероятность события
 можно
охарактеризовать лишь неточно как
величину, содержащуюся в интервале
можно
охарактеризовать лишь неточно как
величину, содержащуюся в интервале
 с
границами
с
границами
 (7.26)
(7.26)
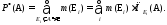 (7.27)
(7.27)
Значение
 вычисляется
по всем фокальным элементам, которые
делают необходимым появление события
вычисляется
по всем фокальным элементам, которые
делают необходимым появление события (или
влекут за собой событие
(или
влекут за собой событие ).
Значение
).
Значение получается
при рассмотрении всех фокальных
элементов, которые делают возможным
появление события
получается
при рассмотрении всех фокальных
элементов, которые делают возможным
появление события .
Отметим, что имеется отношение
двойственности между
.
Отметим, что имеется отношение
двойственности между и
и :
:
 (7.28)
(7.28)
Доказано
(Шейфер [24]), что функция
 (соответственно
(соответственно )
удовлетворяют аксиоме (7.6) (соответственно
(7.11)), т.е. является мерой возможности
(соответственно необходимости) тогда
и только тогда, когда фокальные элементы
образуют последовательность вложенных
множеств. А именно если
)
удовлетворяют аксиоме (7.6) (соответственно
(7.11)), т.е. является мерой возможности
(соответственно необходимости) тогда
и только тогда, когда фокальные элементы
образуют последовательность вложенных
множеств. А именно если то
функция распределения возможностей
то
функция распределения возможностей ,
связанная с
,
связанная с и
и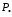 ,
определяется в виде
,
определяется в виде
 (7.29)
(7.29)
Ясно,
что если, наоборот, фокальные элементы
являются элементарными (а значит,
несовместными) событиями, то т.е.
снова возвращаемся к вероятностной
мере.
т.е.
снова возвращаемся к вероятностной
мере.
Если схематично представить базу знаний с помощью множества фокальных элементов, которые являются составляющими «значение» в наборе, описывающем информационную единицу, то легко понять, что вероятностные меры [17], естественным образом синтезируют базу точных и дифференцированных знаний, тогда как меры возможности [97], суть отражение неточных, но связных (т.е. подтверждающих друг друга) знаний. Отметим, что функции возможности в этом смысле более естественны для представления чувства неуверенности: от субъекта не ждут слишком точной информации, но желают услышать по возможности наиболее связную речь. Зато точные, но флуктуирующие, данные чаще всего получают из наблюдений физического явления.
Несомненно, в базе знаний будет содержаться информация, которая в общем случае не сведется ни к точной, ни к полностью согласованной информации. Вероятность, с одной стороны, и пара «возможность-необходимость» - с другой соответствуют двум крайним, а значит, идеальным ситуациям.
Формулы (7.26) и (7.27) позволяют считать, что функция распределения возможностей определяет класс вероятностных мер Р, такой, что
 (7.30)
(7.30)
Это
позволяет строго определить понятие
математического ожидания в рамках мер
возможности. Если f-
функция, определенная на
 и принимающая значения из множества
действительных чисел
и принимающая значения из множества
действительных чисел ,
то верхние и нижние математические
ожиданияf,
обозначаемые
,
то верхние и нижние математические
ожиданияf,
обозначаемые
 соответственно,
определяются с помощью интегралов
Лебега-Стилтьеса (Демпстер [23]):
соответственно,
определяются с помощью интегралов
Лебега-Стилтьеса (Демпстер [23]):
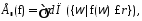 (7.31)
(7.31)
 (7.32)
(7.32)
Названия верхних и нижних математических ожиданий оправдываются тождествами

 (7.33)
(7.33)
Эти
соотношения были получены Демпстером
для случая, когда множество

конечно; более общий случай описан в данной работе.
7.2. Языки и технологии логического программирования prolog, lisp
7.2.1. Prolog — один из старейших и все еще один из наиболее популярных языков логического программирования, хотя он значительно менее популярен, чем основные императивные языки. Он используется в системах обработки естественных языков, исследованиях искусственного интеллекта, экспертных системах, онтологиях и других предметных областях, для которых естественно использование логической парадигмы [104].
Главной парадигмой, реализованной в языке Prolog, является логическое программирование. Как и для большинства старых языков, более поздние реализации, например, Visual Prolog, добавляют в язык более поздние парадигмы, например, объектно-ориентированное или управляемое событиями программирование, иногда даже с элементами императивного стиля.
Prolog использует один тип данных, терм, который бывает нескольких типов [104]:
атом— имя, без особого смысла, используемое для построения составных термов;
числа и строки такие же, как и в других языках;
переменная обозначается именем, начинающимся с прописной буквы, и используется как символ-заполнитель для любого другого терма;
составной терм состоит из атома-функтора, за которым следует несколько аргументов, каждый из которых в свою очередь является атомом.
Целью выполнения программы на Prolog является оценивание одного целевого предиката. Имея этот предикат и набор правил и фактов, заданные в программе, Prolog пытается найти привязки (значения) переменных, при которых целевой предикат принимает значение истинности [104].
Prolog-программа является собранием правил и фактов. Решение задачи достигается интерпретацией этих правил и фактов. При этом пользователю не требуется обеспечивать детальную последовательность инструкций, чтобы указать, каким образом осуществляется управление ходом вычислений на пути к результату. Вместо этого он только определяет возможные решения задачи и обеспечивает программу фактами и правилами, которые позволяют ей отыскать требуемое решение [105].
Prolog относится к так называемым декларативным языкам, требующим от автора умения составить формальное описание ситуации. Поэтому программа на Prolog не содержит управляющих конструкций типа if … then, while … do; нет также оператора присваивания [105].
В Prolog задействованы другие механизмы. Задача описывается в терминах фактов и правил, а поиск решения Prolog берет на себя посредством встроенного механизма логического вывода.
Перечень возможных синтаксических конструкций Prolog невелик и в этом смысле язык прост для изучения.
Prolog реализован, практически, для всех известных операционных систем и платформ. В число операционных систем входят OS для мэйнфреймов, всё семейство Unix, Windows, OS для мобильных платформ [106].
7.2.2. Lisp -[93]
Контрольные вопросы и задания для самостоятельной работы по главе 7
7.1.Эффективность информированных стратегий поиска?
7.2. Жадный поиск по первому наилучшему совпадению?
7.3.
Поиск
 :
минимизация суммарной оценки стоимости
решения
:
минимизация суммарной оценки стоимости
решения ,
где
,
где -
стоимость достижения данного узла, и
-
стоимость достижения данного узла, и -
стоимость прохождения от данного узла
до цели?
-
стоимость прохождения от данного узла
до цели?
7.4.
Поиск
 с использованием алгоритма жадного
поиска является оптимальным, если
функция
с использованием алгоритма жадного
поиска является оптимальным, если
функция преемственна?
преемственна?
7.5.
Эвристический поиск с ограничением
объема памяти (для поиска применяется
идея итеративного углубления эвристического
поиска, за счет условия останова
развертывания
применяется
идея итеративного углубления эвристического
поиска, за счет условия останова
развертывания
 стоимости
стоимости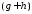 ,
а не глубины)?
,
а не глубины)?
7.6. Зависимость производительности поиска от точности эвристической функции?
7.7. Составление допустимых эвристических функций?
7.8. Нечеткие события?
7.9. Мера необходимости?
7.10. Нечеткие элементы, нечеткие множества?
7.11. Принцип относительности возможности?
7.12. Оптимальное оценивание и принятие решений?
7.13. Оценивание параметра нечеткого множества?
7.14. Решения в известной и неизвестной ситуациях?
7.15. Байесовская стратегия решения?
7.16. Логические аспекты здравого смысла?
7.17. Использование обычных средств программирования?
7.18. Использование дополнительных пакетов?
7.19. Языки искусственного интеллекта: Lisp?
7.20. Языки искусственного интеллекта: Prolog?
Глава 8. Послесловие
8.1. Эволюция искусственного интеллекта для развития интеллектуальных
технологий информатики
На протяжении десятилетий ученые дискутируют о перспективах развитияискусственного интеллекта. Наибольшее внимание сегодня уделено мнению Роджера Пенроуза: «Мыслительные процессы человека» фундаментальным образом отличаются от функционирования компьютера. Никакая машина, работающая по принципу вычислений, не сможет мыслить и понимать так, как человек. Процессы в нашем мозгу являются не вычислительными». Пенроуз считает, что мышление человека полностью объясняется в категориях материального мира [107].
Доктор Рей Курцвайль, исследуя проблематикуискусственного интеллекта, утверждает, что исчезновение различий между машиной и человеком – только вопрос времени, поскольку человеческий мозг не совершенствовался, а его электронный аналог, только за последние 20 лет, развивался невероятными темпами и такая тенденция сохранится и в дальнейшем.
Директор лаборатории мобильных роботов Мелан Ганс Морайен отмечает, что человека можно заменить более сложным искусственным аналогом. Он утверждает, что рано или поздно земной шар будет заселен детищами техники.
Профессор кибернетики Кевин Уорвик пишет: «после включения первой серьезной машины, интеллект которой будет сопоставим с интеллектом человека, мы не сможем её отключить. Мы как бы запустим бомбу с часовым механизмом, которая будет отсчитывать время, отпущенное человечеству и не сможем ее разрядить».
Ни одна из созданных машин не будет существовать за пределами комплекса.
Системы искусственного интеллекта (ИИ)не будут точно имитировать функции человеческого мозга, что обусловлено аппаратными ограничениями.
Машины могут пройти тест Тьюринга[108] в узкой области.
В будущем нам может показаться, что машины проявляют признаки разума, однако машины никогда не будут способны к философским обобщениям.
В перспективе ИМ будут нашими партнерами на работе и дома
Компьютеры будут проектировать следующие поколения компьютеров и роботов.
Компьютеры будут играть существенную роль в развитии жизни на земле.
Интеллект – умение приспособиться к новым задачам и условиям жизни, либо способ обработки информации и решения задач. Интеллект это также умение сопоставлять и понимать. Важнейшими процессами и функциями, составляющими человеческий интеллект, считаются самообучение и использование знаний, способность к обобщению, возможность восприятия и познавательные способности, способность распознавать некоторый объект, в произвольном контексте.
На интеллект влияют как наследственные факторы, так и воспитание. Важнейшими процессами и функциями, составляющими человеческий интеллект, считаются: самообучение, накопление и использование знаний. Способность к обобщению, возможность восприятия и познавательные способности, например: способность распознавать некоторый объект в произвольном контексте. На виду с этим можно отметить такие элементы как: запоминание, целеполагание и реализация целей, умение сотрудничать, формулировать выводы, обладать аналитическими способностями, иметь концептуальное и абстрактное мышление. С интеллектом связаны такие факторы как: самосознание, эмоциональное и иррациональное состояние человека.
В настоящее время созданные человеком интеллектуальные машины можно запрограммировать так, что они будут только очень приблизительно имитировать лишь некоторые из упомянутых элементов человеческого интеллекта. Перед нами лежит долгая дорога изучения функционирования мозга и создание его искусственного аналога. В принципе искусственным интеллектом, в современном его понимании, занимались уже давно. Но всё это можно считать только лишь попытками заглянуть в разум человека, его осмысление и использование в разных целях.
Понятие искусственный интеллект предложил в 1956 году Джон Маккарти на организованной им конференции в Дартмутском колледже, посвящённой интеллектуальным машинам. Уже тогда к проблематике искусственного интеллекта был отнесён поиск методов решения задач, в том числе решение задач в шахматы.
Логические рассуждения– вторая из множества задач ИИ. Она сводится к построению алгоритма, воспроизводящего реализуемый мозгом способ вывода.
Следующим объектом исследования в области ИИ стала обработка естественного языка и автоматический перевод фраз с одного языка на другой, формулирование словесных команд машинам, а также выделение информации из речевых выражений и построение на его основе базы знаний.
Перед исследователями в области искусственного интеллекта сегодня встаёт необходимость создания программ, которые обучаются на основе аналогии и обретают возможность самосовершенствоваться (см. Виноград Т. [109]).
Предсказания, прогнозирование результатов, событий и явлений, а также клонирование, тоже относятся к предметам ИИ. Но, при этом, можно отметить следующее глубокое размышление - возможности самосознания интеллектуального компьютера. Учёные пытаются познать процессы восприятия: зрение, осязание, слух, для того, чтобы на этой основе сконструировать электронные аналоги и применить их в робототехнике.
В научной литературе представлены различные варианты определения искусственного интеллекта:
ИИ – наука о машинах для решения задач, которые требуют применения человеческого интеллекта (МарвинМинский).
ИИ – область информатики, охватывающая компьютерные методы и технологии символьного вывода, а также символьного представления знаний, при осуществлении такого вывода (Е. Фейгенбаум) [110].
ИИ охватывает решения задач способами, основанными на естественных человеческих действиях и процессах познания, при помощи имитационных компьютерных программ (Р. Дж. Шалькофф).
Несмотря на то, что ИИ считается областью информатики, он привлекает внимание многих учёных из других областей, в том числе философов, психологов, медиков и математиков.
ИИ – интердисциплинарная наука, которая стремиться исследовать человеческий интеллект и использовать его в машинах.
Наряду с созданием и изучением ИИ, всегда стоял вопрос, как сделать программу интеллектуальной. Первым этот вопрос поставил Алан Тьюринг в 1950 году. Тьюринг создал тесты, для выявления интеллектуальности ПО. Идея заключалась в том, что человек при помощи монитора и клавиатуры, задавая один и тот же вопрос компьютеру, как бы передаёт информацию другому человеку, если спрашивающий не может отличить ответы компьютера от ответов человека, то можно утверждать, что программа является интеллектуальной. Идею Тьюринга раскритиковал американский философ Джон Сирл, который утверждал, что компьютеры не могут обладать интеллектом, потому что они хотя и используют символы, в соответствии с определёнными правилами, но при этом не понимают их значения. Джон Сирл таким образом парировал задачу Тьюринга, которая осталась в истории под названием «Китайская комната».
Предположим, что существует закрытая комната, в которой находится европеец, не знающий китайского языка. Ему передаются одиночные карточки, на которых иероглифами записана некоторая история. Наш герой не знает китайского языка. Однако он находит на книжной полке книгу на известном ему языке под названием: «Что делать, если кто-то подсунет под дверь карточку с китайскими иероглифами». В этой книге изложены инструкции по составлению последовательности китайских иероглифов. На каждый вопрос европеец даёт ответ, в соответствии с инструкцией в книге. Джон Сирл утверждает, что в замкнутой комнате человек ничего не понимает, также, как и компьютер, выполняющий программу. По этой причине существует очевидное различие между мышлением и имитацией мыслительных процессов. Согласно Джону, даже если мы не отличаем ответы машины от ответов человека, то это не означает интеллектуальность машины. Однако предположим, что существует машина, которая сдала тест Тьюринга. В этой ситуации автор книги «Новое мышление цезаря» Р. Пенроуз размышляет - можно ли считать приемлемым использование такой машины для удовлетворения своих потребностей, без учёта её пожеланий. Роджер Пенроуз, в своей книге, описывает одно из устройств оснащённое ИИ - электронную черепаху. Эта черепаха перемещалась по помещению, благодаря энергии от аккумулятора. Когда напряжение падало ниже определённого уровня, черепаха начинала искать ближайший источник энергии и сама заряжала себя. Такое поведение аналогично поглощению людьми пищи.
Роджер Пенроуз считает, что такое устройство в принципе реально, но для этого он предлагает ввести некоторую меру, которой он присвоил название интеллектуальность.
8.2.Экспертные системы нового уровня
Общая идея функционирования экспертных систем заключается в переносе опыта эксперта в базу знаний, в проектировании машины для вывода решений по имеющейся информации и в создании соответствующего GUI [111-113]. Первая ЭС считается программа DENDRAL, которая была написана в первой половине 60 годов в Стэнфордском университете. Задача этой программы заключалась в подсчёте всех возможных конфигураций заданного множества атомов. Интегральной частью этой программы была база знаний, содержащая химические законы и правила, которые в течение многих десятилетий вырабатывались в химических лабораториях.
Программа DENDRAL оказалась чрезвычайно полезной при решении задач, до которых не существовало аналитических методов. Также в Стэнфорде были созданы ещё две ЭС для помощи геологам, при определении типа пробы грунта, в зависимости от содержания в нём различных минералов. Она была названа PROSPECTOR. Эта система была диалоговой системой и работала на основе правил, полученных от специалистов, которые составляли базу знаний, отделённую от механизма вывода решения. Применение такой системы дало очевидный эффект в виде открытия залежей молибдена. Следующая система получила название MYCIN, созданная для диагностирования инфекционных болезней. В этой системе вводились данные пациента и данные лабораторных анализов. Результат функционирования представлял собой диагноз и рекомендацию по лечению. В случае некоторых заболеваний крови, система помогала принимать решения, при неполной информации, при наличии сомнений, система определяла уровень уверенности в поставленном диагнозе и предлагала альтернативное решение (диагноз). На базе этой системы была создана система NEOMYCIN, которая применялась для обучения врачей. Одним из крупнейших проектов в истории ИИ, известное под название CYC, это была мощная система, которая содержала миллионы правил. Разработчики предполагали ввести в её базу знаний порядка 100000000 правил, что позволило бы обеспечить чрезвычайно большие возможности компьютеру. Таким образом, основными элементами ЭС считаются БЗ, механизм вывода решения и интерфейс пользователя. Правила - это логические высказывания, которые определяют некоторые импликации и обеспечение получения новых фактов, что и позволяет решить исходную задачу.
Логические правила могут быть разного типа. Очень хорошо работает такая система при диагностике каких-то объектов. Механизм вывода решения это также программный модуль, использующий БЗ.
Большой популярностью пользуются скелетные ЭС, то есть компьютерные программы с реализованным механизмом вывода и пустой базой знаний. Но составной частью таких программ являются специальные редакторы, позволяющие заносить в базу правила решения задач, стоящие перед пользователями. Проблематика построения ЭС относится к инженерии знаний.
8.3. Роботика
Карел Чапек, 1920г.
Два подхода в развитии искусственного интеллекта: слабая и сильная гипотеза ИИ, 50-е годы ХХ в.
Слабая гипотеза – предполагает, что интеллектуальная машина должна имитировать процесс человеческого сознания, однако не может распознавать психическое состояние.
Сильная гипотеза- ИИ ведёт к конструированию машин, способных распознавать когнитивные психические состояния. Такой подход позволяет создать машину, способную осознать собственное существование, обладающую эмоциями и самоощущениями.
8.4. Преобразование речи искусственного языка
Существенным средством межчеловеческой коммуникации является речь. Джон Сирл ответил на вопрос о достижениях в области ИИ следующим образом: «Мне не настолько хорошо известны технологические достижения в этой области, чтобы дать ответ, однако меня всегда восхищали успехи в сфере понимания естественного языка».
Синтез речи, понимание устной речи, понимание естественного языка, автоматический перевод.
Синтез речи можно отождествить с попыткой чтения книги компьютером. Исследование речи непростая задача, поскольку при произнесении фраз человек соответствующим образом интонирует их. Т.е., для того, чтобы хорошо выразить некоторые суждения, необходимо понимать их смысл, а компьютер в этих вопросах не слишком компетентен.
8.5. Интеллект муравьёв и его использование
Учёных заинтересовал способ, которым муравьи выбирают путь к корму, оказалось, что они выбирают наикратчайший путь.
Алгоритмы: муравьиный алгоритм, метод роя частиц, пчелиный алгоритм и т.д.
8.6. Искусственная жизнь, мозг, познание, разум, память и мышление
Искусственная жизнь (ИЖ) – это научная отрасль, посвященная пониманию жизни через попытки прояснения жизни в динамике, оказывающей влияние на биологические явления. Эти явления отображаются посредством ИТ, например, с применением компьютеров, для того чтобы в полной мере использовать современные экспериментальные условия. ИЖ представляет собой область знаний, которая использует достижения химии, физики, робототехники и других наук. Основу дисциплины составляет понятие жизни. Она занимается имитационным моделированием такой жизни, которую мы знаем, то есть работа посвящается изучению поведения организмов, построенных на иных принципах, нежели земные существа [114, 115]. Исходные комбинации клеток могут трансформироваться в очень разнородные сложные структуры.
Другой пример ИЖ – биоморфы. Ричард Гоугенс, для изучения эволюции видов, применял теорию графов, что позволило ему представить генетические операции для получения новых структур в последующих поколениях, т.е. если эволюция начинается с простых структур, напоминающих деревья, то можно получить структуры в форме различных насекомых. При этом рост организмов имитировался, при помощи формального описания развития. В последующем эти системы были применены для описания и моделирования развития растений, а эффект от этого перешел в область описания при создании фракталов.
Система Тьера представляет собой виртуальный мир, созданный биологом Томом Рейем. За жизненное пространство он взял виртуальный компьютер, в котором живут программы и индивиды. Программы он описал на простом языке, близком к ассемблеру. Для эволюции индивидов он использовал принцип мутации, т.е. случайной замены одной из команд программы, либо рекомбинации, состоящей в подмене фрагментов кода. При этом индивиды начинают соперничать между собой за ресурсы, т.е. за память виртуального компьютера и за время использования процессора, в результате, они пытаются занять больше памяти и выполнить больше команд.
Система Фремштик, которую считают наиболее развитой, была создана в 1997 году. Поляки реализовали этот проект. Они представили жизнь в виртуальном трехмерном мире, имеющим земную и водную среду, а организмы называли фремштиками, они состоят из палочек, которые дополнительно могут играть роль рецепторов, обладающих разными чувствами. Органы перемещения управляются при помощи нервной системы, моделируемой с помощью нейронной сети. Они конкурируют между собой за жизненное пространство и поиск пищи, путём борьбы. Каждая особь описывается генотипом – код с описанием строения фремштика. Доступны 3 способа описания хромосом:
Самый простой способ, описывающий структуру фремштика;
Рекуррентное описание;
Описание, основанное на записи информации о конкретной клетке.
Степень приспособленности оценивается в самом жизненном пространстве. Этот процесс может принимать различные формы в зависимости от подвижности особи, её устойчивости, размеров. Модель может принимать различные формы, например, поиск самой высокой особи. Следующие поколения особей будут возникать в результате эволюции, которая вызывается селекцией, мутацией и скрещиванием генов. Эволюция затрагивает как внешнюю форму организма, так и структуру их нервной системы.
8.7. Боты
Это автоматический софтверный инструментарий, т.е. программа, предназначенная для поиска и выявления данных.
Интеллектуальные боты могут принимать решения на основе полученных ранее знаний. В настоящее время можно выделить несколько типов ботов, которые по своим функциям подразделяются на:
чаттербот – автомат для беседы (имитирует разговор на естественном языке, получая информацию от собеседника);
серчбот – занимается автоматическим обслуживанием БД, предназначен для поиска, индексирования и накопления данных;
шоппингбот – помогает совершать покупки через Интернет, просматривает витрины в поисках продуктов, формирует отчет об уровне цен продуктов;
датабот – автомат для поиска данных и решения задач, структура основана на нейронных сетях;
апдейтбот – обновление данных пользователя, информирует об изменении сетевых ресурсов;
инфобот – программа, автоматически отвечающая по электронной почте
Нечеткая оптимизация в задачах теплоэнергетики и промышленности
Optimizator подсистемы диагностики состояния энергоустановок, skais, для решения задач технического обслуживания
Диагностический контроль энергоустановок тепловой электростанции (ТЭС) осуществляется с помощью экспертной диагностической системы функционально-гибридного типа с именем SKAIS. SKAIS - «Система контроля, анализа и слежения за изменением состояния энергоустановки» - управляемый в диалоговом режиме программный комплекс, ориентированный на диагностирование и экспертизу энергоустановок любых типов. SKAIS позволяет на ранней стадии (с использованием экспресс - испытаний) диагностировать снижение экономичности, определять величину, причины и опасность происходящих изменений, прогнозировать состояние, оценивать надежность, остаточный ресурс, долговечность, степень риска и ущерб от продолжения дальнейшей эксплуатации энергоустановки. Система SKAIS осуществляет принятие решений на выход из создавшейся конфликтной ситуации (вывод в ремонт или введение ограничения) с представлением подготовленных в базе знаний рекомендаций (в виде готовых продукций - решающих правил) оперативному и ремонтному персоналу тепловой электростанции. Для этого создается база данных и знаний (БД и З) обо всех вынужденных остановах и дефектах оборудования, отклонениях от правил его нормальной эксплуатации.
Ключевые слова: Комбинационная оптимизация, четкая и нечеткая постановки решения, глобальный минимум функции цели, диагностика и экспертиза.
Введение
В
интеллектуальном центре подсистемы
контроля и диагностики энергоустановок
ТЭС –
 ,
(рис.1, 2) работает программный модуль
,
(рис.1, 2) работает программный модуль по схеме
по схеме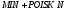 ,
(рис.3- 6, см. Приложение). Основное
назначение модуля – программное решение
задач минимизации функций цели, имеющих
несколько минимумов, но достаточно
гладких в окрестностях каждого из них.
Вдали от минимумов допускаются
неустранимые разрывы первого рода. Для
нахождения окрестности глобального
минимума используется из
,
(рис.3- 6, см. Приложение). Основное
назначение модуля – программное решение
задач минимизации функций цели, имеющих
несколько минимумов, но достаточно
гладких в окрестностях каждого из них.
Вдали от минимумов допускаются
неустранимые разрывы первого рода. Для
нахождения окрестности глобального
минимума используется из метод случайного поиска (его комбинация).
Методом сопряженных градиентов минимум
уточняется. При появлении «оврагов»
градиентные методы отказываются
работать. В этом случае подключается к
метод случайного поиска (его комбинация).
Методом сопряженных градиентов минимум
уточняется. При появлении «оврагов»
градиентные методы отказываются
работать. В этом случае подключается к овражный
метод Гельфанда И.М., который позволяет
осуществить многомерный поиск минимума,
[7, 8]. Из точки
овражный
метод Гельфанда И.М., который позволяет
осуществить многомерный поиск минимума,
[7, 8]. Из точки по двум направлениям выполняется
наискорейший спуск на дно оврага,
(рис.5-6, см. Приложение). Но срабатывает
помеха! Для этого, при вычислении
градиента, вначале берем шаг
по двум направлениям выполняется
наискорейший спуск на дно оврага,
(рис.5-6, см. Приложение). Но срабатывает
помеха! Для этого, при вычислении
градиента, вначале берем шаг ,
а потом шаг
,
а потом шаг ,
получаем точки
,
получаем точки ,
определяющие прямую линию – «дно
оврага». По «дну оврага» выполняем еще
один многомерный поиск минимума. Получим
точку
,
определяющие прямую линию – «дно
оврага». По «дну оврага» выполняем еще
один многомерный поиск минимума. Получим
точку .
При необходимости этот элемент поиска
можно повторить. Последовательность
.
При необходимости этот элемент поиска
можно повторить. Последовательность задает
убывающую последовательность целевой
функции
задает
убывающую последовательность целевой
функции .
После срабатывания правила остановки,
когда реализуется заданный порог
похожести
.
После срабатывания правила остановки,
когда реализуется заданный порог
похожести ,
(рис. 5. и ПП с именемSIM),
последняя полученная точка
,
(рис. 5. и ПП с именемSIM),
последняя полученная точка
 и значение функции в этой точке будут
точкой глобального минимума
и значение функции в этой точке будут
точкой глобального минимума .
.
Результаты
анализа сравниваемых состояний
представляются визуально, в виде их
Порог похожести задается разработчиком
 -а.
Точки
-а.
Точки и
и считаются лежащими на дне оврага (рис.6).
Эти две точки определяют прямую линию,
по которой осуществляется одномерный
поиск минимума. Одно из направлений в
точке
считаются лежащими на дне оврага (рис.6).
Эти две точки определяют прямую линию,
по которой осуществляется одномерный
поиск минимума. Одно из направлений в
точке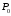 является градиентным. Второе направление
будет случайным. Эта комбинация,
детерминированного и случайного поиска,
приводит к желаемому результату.
Регулирующими параметрами элемента
поиска является пара (
является градиентным. Второе направление
будет случайным. Эта комбинация,
детерминированного и случайного поиска,
приводит к желаемому результату.
Регулирующими параметрами элемента
поиска является пара ( ),
где
),
где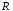 -
первоначальный шаг. В качестве правила
остановки, при наискорейшем спуске на
дно оврага и принятом механизме случайного
выбора решения из полученного набора
эвристик, используется принцип «похожести»
точек [4,9]. Одной из эвристик алгоритма
является предварительное знание об
области
-
первоначальный шаг. В качестве правила
остановки, при наискорейшем спуске на
дно оврага и принятом механизме случайного
выбора решения из полученного набора
эвристик, используется принцип «похожести»
точек [4,9]. Одной из эвристик алгоритма
является предварительное знание об
области и примерной зоне поиска
и примерной зоне поиска ,
в которой находится минимум функции
,
в которой находится минимум функции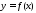 ,
а также знание об изменении параметров
технологического процесса по их
«похожести» (значения
,
а также знание об изменении параметров
технологического процесса по их
«похожести» (значения должны
быть одинаковыми, или близкими). Эта
информация позволит оценить первоначальный
шаг
должны
быть одинаковыми, или близкими). Эта
информация позволит оценить первоначальный
шаг и значения функции
и значения функции в выбранных точках. функциональных
значений
в выбранных точках. функциональных
значений на экране монитора (рис.5, табл. П.1).
на экране монитора (рис.5, табл. П.1).
Похожесть
диагностируемых состояний определяется
с помощью программы РОХ из.
 .
В геометрической интерпретации значения
.
В геометрической интерпретации значения отображают (представляют) собой
колебательную линию, построенную по
параметрам оцениваемого состояния
относительно его эталонного значения
отображают (представляют) собой
колебательную линию, построенную по
параметрам оцениваемого состояния
относительно его эталонного значения ,
(рис.5).
,
(рис.5).
Регулирование
этими параметрами с использованием
«меры похожести»
 позволяет эффективно (и визуально на
экране монитора) применять диалоговый
подход при оптимизации задач тепловой
электростанции (ТЭС). В этом случае лицу
принимающему решение (ЛПР) желательно
иметь не одно, а группу хороших решений
и возможности принятия решения по
времени
позволяет эффективно (и визуально на
экране монитора) применять диалоговый
подход при оптимизации задач тепловой
электростанции (ТЭС). В этом случае лицу
принимающему решение (ЛПР) желательно
иметь не одно, а группу хороших решений
и возможности принятия решения по
времени для последующего выбора окончательного
оптимального решения (например, при
базовом и переходном режимах работы
энергоустановки). Для реализации этого
в используемые эвристические правила
вводится неопределенность исходной
информации, благодаря чему и будет
порождаться класс субоптимальных
решений. Эвристические правила, обладающие
ограниченной неопределенностью, назовем
«размытыми» эвристиками [4,5]. Результатом
поиска будет единственное решение,
близость которого к оптимальному решению
определяется величиной максимальной
похожести
для последующего выбора окончательного
оптимального решения (например, при
базовом и переходном режимах работы
энергоустановки). Для реализации этого
в используемые эвристические правила
вводится неопределенность исходной
информации, благодаря чему и будет
порождаться класс субоптимальных
решений. Эвристические правила, обладающие
ограниченной неопределенностью, назовем
«размытыми» эвристиками [4,5]. Результатом
поиска будет единственное решение,
близость которого к оптимальному решению
определяется величиной максимальной
похожести ,
если мы имеем дело с тестовой задачей.
,
если мы имеем дело с тестовой задачей.
Тестовые
задачи сконструированы авторами работы
так, чтобы выделить особенности
теплоэнергетического процесса, [4,5,9].
При опробовании
 а
по схеме
а
по схеме на тестовых примерах (использованы
функции Розенброка Х.Х. -
на тестовых примерах (использованы
функции Розенброка Х.Х. - и
РастригинаЛ.А.-
и
РастригинаЛ.А.- )
алгоритм сходится, т.е. минимум
осуществляется из любой начальной
точки. Использование механизма случайного
выбора решений позволяет расширять
область возможных реализаций или сужать
ее, в зависимости от ситуации и готовности
энергоустановки по состоянию к выполнению
режима.
)
алгоритм сходится, т.е. минимум
осуществляется из любой начальной
точки. Использование механизма случайного
выбора решений позволяет расширять
область возможных реализаций или сужать
ее, в зависимости от ситуации и готовности
энергоустановки по состоянию к выполнению
режима.
Задачи математического программирования при четкой постановке, в приложении к задачам технической диагностики энергоустановок ТЭС, решаем следующим образом.
Пусть
в области
 ,
определяемой ограничениями
,
определяемой ограничениями
 ,
,
 (1)
(1)
задана
целевая, в общем случае, нелинейная
функция
 .
Требуется найти такой
.
Требуется найти такой ,
для которого справедливо
,
для которого справедливо
 .
(2)
.
(2)
Здесь
условие (1) означает, что каждая компонента
 вектора (матрицы)
вектора (матрицы) изменяется в пределах от соответствующего
наименьшего допустимого значения
изменяется в пределах от соответствующего
наименьшего допустимого значения до наибольшего допустимого значения
до наибольшего допустимого значения .
Количество компонент -
.
Количество компонент - .
Любой вектор
.
Любой вектор называется допустимым. Вектор
называется допустимым. Вектор назовем оптимальным, если для любого
другого вектора
назовем оптимальным, если для любого
другого вектора выполняется условие:
выполняется условие:
 .
(3)
.
(3)
Как
известно из теории исследования операций,
[2, 3], использование градиентных методов
для решения многоэкстремальных задач
затруднительно и малоэффективно, так
как необходимы полные исследования
целевой функции (определение, можно
приближенное, вида поверхности, начальные
приближения). Поэтому, как это подтверждает
практика, наиболее результативными
методами поиска минимума могут быть
различные модификации случайного
поиска. С этой целью в модуль
 включена модификация метода случайного
поиска – метод “Монте-Карло”, [3, 9].
включена модификация метода случайного
поиска – метод “Монте-Карло”, [3, 9].
Формула
изменения координат вектора
 имеет
следующий вид:
имеет
следующий вид:
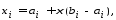 (4)
(4)
где
 - случайное число,
- случайное число, ;
;
 –нижние
и верхние ограничения на переменные.
–нижние
и верхние ограничения на переменные.
Из
(4) следует, что точка
 при любом
при любом всегда находится в области
всегда находится в области (в ограничителях). Для определения
случайного числа
(в ограничителях). Для определения
случайного числа используется процедура RAND, вырабатывающая
случайные числа, необходимые при поиске
окрестности глобального минимума
функции цели. Попадание в окрестность
глобального минимума происходит с
некоторой вероятностью:
используется процедура RAND, вырабатывающая
случайные числа, необходимые при поиске
окрестности глобального минимума
функции цели. Попадание в окрестность
глобального минимума происходит с
некоторой вероятностью:
 (5)
(5)
где
 - объем зоны критерия глобального
минимума;
- объем зоны критерия глобального
минимума;
 -
объем зоны поиска;
-
объем зоны поиска;
 –количество
случайных бросков.
–количество
случайных бросков.
Работа
метода прекращается, если количество
случайных бросков превышает заданное
целое число
 .
Из совокупности точек, полученных в
результате случайных бросков, выбирается
точка
.
Из совокупности точек, полученных в
результате случайных бросков, выбирается
точка ,
которая соответствует наименьшему
значению функции цели
,
которая соответствует наименьшему
значению функции цели .
Однако метод Монте-Карло нецелесообразно
использовать для нахождения
.
Однако метод Монте-Карло нецелесообразно
использовать для нахождения ,
так как вероятность случайного попадания
в
,
так как вероятность случайного попадания
в - окрестность на одном шаге поиска,
определяемая отношением объемов
- окрестность на одном шаге поиска,
определяемая отношением объемов – мерных гиперсфер с радиусами
– мерных гиперсфер с радиусами и
и (начальным расстоянием до цели), равна:
(начальным расстоянием до цели), равна:
 (6)
(6)
Среднее
число шагов, необходимое для случайного
попадания в
 - окрестность цели
- окрестность цели
 (7)
(7)
имеет
экспоненциальный характер и, следовательно,
с ростом
 быстро растет и
быстро растет и .
В схеме
.
В схеме этот метод используется для двух целей:
этот метод используется для двух целей:
1) проведение статистических испытаний и расчетных экспериментов на ЭВМ;
2) оценки окрестности глобального экстремума функции цели.
В
последнем случае точка
 ,
найденная методом “Монте–Карло”,
улучшается постепенным приближением
к цели путем ограничения поиска зоной,
стягивающейся к наилучшей случайной
пробе. Это значит, что случайные пробы
производятся в объеме, центром которого
является точка с наименьшим значением
функции цели. По мере производства
случайных испытаний этот объем стягивается
к своему центру.
,
найденная методом “Монте–Карло”,
улучшается постепенным приближением
к цели путем ограничения поиска зоной,
стягивающейся к наилучшей случайной
пробе. Это значит, что случайные пробы
производятся в объеме, центром которого
является точка с наименьшим значением
функции цели. По мере производства
случайных испытаний этот объем стягивается
к своему центру.
Если
в процессе испытаний была найдена точка
с меньшим значением функции цели, то
объем испытаний устанавливается вокруг
этой новой точки. Таким образом, зона
испытаний перемещается в район цели,
причем на каждом шаге вероятность
случайного нахождения наилучшей точки
становится все большей. Этот принцип
лежит в основе второй модификации
случайного поиска – методе случайного
направленного поиска, [3, 9, 10]. Из точки
 делается
случайный шаг
делается
случайный шаг
 ,
(8)
,
(8)
где
 .
(9)
.
(9)
Величина
 на
начальном шаге принимается равной
на
начальном шаге принимается равной .
Затем определяется координата новой
точки
.
Затем определяется координата новой
точки
 ,
(10)
,
(10)
и сравниваются значения
 .
. (11)
(11)
При
этом
 считается неудачной ситуацией,
а при
считается неудачной ситуацией,
а при проверяется условие
проверяется условие
 ,
(12)
,
(12)
при
выполнении которого ситуацию также
считают неудачной и удачной – в противном
случае. При неудаче предусмотрен возврат
в точку
 ,
из которой делается шаг в диаметрально
противоположном направлении с последующей
проверкой условия (12). В случае неудачи
вновь происходит возвращение в точку
,
из которой делается шаг в диаметрально
противоположном направлении с последующей
проверкой условия (12). В случае неудачи
вновь происходит возвращение в точку ,
из которой делается столько случайных
шагов, сколько потребуется для нахождения
удачной ситуации. Если такая точка
найдена, то через нее и
,
из которой делается столько случайных
шагов, сколько потребуется для нахождения
удачной ситуации. Если такая точка
найдена, то через нее и проводится вектор, в направлении которого
начинается движение с постоянным шагом.
проводится вектор, в направлении которого
начинается движение с постоянным шагом.
При движении по выбранному направлению проверяется относительное изменение функции цели
 .
(13)
.
(13)
В
случае
 предусмотрено возвращение в точку
предусмотрено возвращение в точку с последующим выбором (с помощью случайных
испытаний) нового направления.
с последующим выбором (с помощью случайных
испытаний) нового направления.
Значение
 меняется,
в процессе минимизации, следующим
образом.
меняется,
в процессе минимизации, следующим
образом.
Как
только число неудачных шагов фиксированной
точки окажется равным заданному целому
числу
 ,
то
,
то увеличивается на единицу.
увеличивается на единицу.
Эта операция позволяет осуществлять поиск и движение в выбранном направлении с все более и более уменьшающимися шагами.
Метод
случайного направленного поиска
прекращает свою работу, если выполняется
условие
 (заданное
целое число >>1). Если координаты точки
вдруг оказываются вне ограничений, то
функции присваивается число 1010
(или любое другое, определяемое на основе
расчетных экспериментов).
(заданное
целое число >>1). Если координаты точки
вдруг оказываются вне ограничений, то
функции присваивается число 1010
(или любое другое, определяемое на основе
расчетных экспериментов).
Предполагая,
что окрестность глобального минимума
найдена, продолжается дальнейшее
улучшение точки минимума. Для этого в
схеме
 используется метод сопряженных градиентов
с преобразованием координат, [4, 9, 10],
(рис.3).
используется метод сопряженных градиентов
с преобразованием координат, [4, 9, 10],
(рис.3).
Задачи математического программирования в нечетких условиях, в приложении к задачам технической диагностики энергоустановок, решаются следующим образом, [3, 4, 9].
Под ситуацией принятия решений, при выборе диагноза состояния энергоустановки, условимся понимать:
- множество альтернатив, из которых лицо, принимающее решение (ЛПР), производит выбор;
- множество ограничений, накладываемых на этот выбор;
- целевую функцию, которая позволяет ЛПР ранжировать имеющиеся у него альтернативы.
В результате, каждое ЛПР, имея множество сформулированных целей, способно определить свои предпочтения.
Но
на практике, особенно при диагностике
в реальном масштабе времени, картина
принятия решений резко меняется, так
как ЛПР вынуждено применять следующее
утверждение: '' должно
быть в окрестности
должно
быть в окрестности ''!
А это уже подчеркивает появление
нечеткости в формулировании цели,
согласно [4, 6, 8, 11].
''!
А это уже подчеркивает появление
нечеткости в формулировании цели,
согласно [4, 6, 8, 11].
Выражение
«
в
окрестности…», представим
нечетким подмножеством
 ,
определяемым функцией (точнее, ее
отображением
,
определяемым функцией (точнее, ее
отображением ):
):
 ,
(14)
,
(14)
где
 - полная дистрибутивная решетка;
- полная дистрибутивная решетка; – множество альтернатив.
– множество альтернатив.
В
результате принятия решения по одному
из предлагаемых диагнозов, представим
возникшую нечеткую обстановку как
множество
 – альтернатив вместе с его нечеткими
подмножествами. Эти подмножества
представляют собой также нечетко
сформулированные критерии (цели и
ограничения), т.е. систему:
– альтернатив вместе с его нечеткими
подмножествами. Эти подмножества
представляют собой также нечетко
сформулированные критерии (цели и
ограничения), т.е. систему:
 .
(15)
.
(15)
Здесь
 – целевые функции.
– целевые функции.
Перебирая, по возможности, все критерии при выборе наиболее предположительного диагноза, можно построить функцию
 .
(16)
.
(16)
Оптимум,
в этом случае, будет соответствовать
той области
 ,
элементы которой максимизируют диагноз
,
элементы которой максимизируют диагноз .
В результате проведенных рассуждений
можно определить нечеткую обстановку
такой задачи тройкой
.
В результате проведенных рассуждений
можно определить нечеткую обстановку
такой задачи тройкой .
Предположим при этом, что решение задачи
диагноза в нечеткой постановке будет
определяться в виде нечеткого подмножества
универсального множества альтернатив.
Под оптимальным решением при этом будем
понимать элемент
.
Предположим при этом, что решение задачи
диагноза в нечеткой постановке будет
определяться в виде нечеткого подмножества
универсального множества альтернатив.
Под оптимальным решением при этом будем
понимать элемент (если такой существует), для которого,
согласно [7, 8]:
(если такой существует), для которого,
согласно [7, 8]:
 ,
(17)
,
(17)
где
 - нечеткое решение;
- нечеткое решение; означает
означает ,
, означает
означает .
Таким образом, задача минимизации
решений при выборе предположительного
диагноза сведена к задаче нечеткого
математического программирования
(НМП), т.е. к задаче многокритериальной
оптимизации.
.
Таким образом, задача минимизации
решений при выборе предположительного
диагноза сведена к задаче нечеткого
математического программирования
(НМП), т.е. к задаче многокритериальной
оптимизации.
Итак,
под задачей НМП будем понимать задачу
нахождения
 ,
или
,
или .
(18)
.
(18)
Результат решения задачи минимизации функции цели
В данной работе было уделено внимание на реализацию комплексного решения оптимального нахождения минимума различных функций цели с помощью среды MathCAD 14. Рассмотрены , при участии магистранта института прикладной информатики НГУЭУ А.Е. Некипелова, в комплексе метод «Монте-Карло» и градиентный метод наискорейшего спуска, позволяющие уточнить минимум функции, начальное приближение которого получается из случайного поиска методом Монте-Карло.
Метод «Монте-Карло»
Для минимизации функции многих переменных разработано множество численных методов, но большинство из них связано с подсчётом градиента функции, что со своей стороны может дать эффективные алгоритмы вычисления лишь, если удаётся аналитически подсчитать частные производные. Между тем, более универсальным методом минимизации функции многих переменных является метод перебора, при котором произвольным образом разбивается область определения функций на симплексы и в каждом узле симплекса вычисляется значение функции цели, причём происходит сравнение – перебор значений и на печать выводится точка минимума и значение функции в этой точке.
В
методе «Монте-Карло» зададим функцию
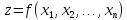 .
Выбираем область поиска решения задачи:
.
Выбираем область поиска решения задачи:
 ;
;
а)
Производим случайные броски, т.е. выбираем
значения
 для каждой переменной
для каждой переменной по формуле:
по формуле:
 ;
;
б) Сравниваем значения функции:
 ,
,
если это неравенство выполняется, то
 ,
,
если не выполняется, то
 ;
;
в) Количество случайных бросков либо фиксировано, либо уточняется при достижении необходимой определенной погрешности.
Метод градиентного спуска
Строгий
аналитический метод не всегда приводит
к цели (случай, когда
 в критической точке). В подобных, и в
более сложных случаях применяют различные
приближённые аналитические методы,
которые в математическом смысле иногда
менее строго обоснованы, но, тем не
менее, порой приводят к желаемому
результату. К таким методам относятся
и градиентные методы наискорейшего
спуска.
в критической точке). В подобных, и в
более сложных случаях применяют различные
приближённые аналитические методы,
которые в математическом смысле иногда
менее строго обоснованы, но, тем не
менее, порой приводят к желаемому
результату. К таким методам относятся
и градиентные методы наискорейшего
спуска.
Пусть,
нам нужно найти
 .
Рассмотрим некоторую точку
.
Рассмотрим некоторую точку

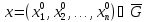 и вычислим в этой
точке градиент функции
и вычислим в этой
точке градиент функции
 :
:
 ,
,
где
 - ортонормированный базис в пространстве
- ортонормированный базис в пространстве .
.
Если
 ,
то полагаем:
,
то полагаем:
 ,
,
где
 ,
а
,
а выбирается из условия сходимости
итерационного процесса:
выбирается из условия сходимости
итерационного процесса:
 ,
,
где
 ,
а
,
а выбирается из условия сходимости.
выбирается из условия сходимости.
Формулу можно расписать в виде:
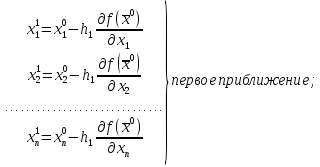

…………………………………………………………………

Здесь m – число итераций. Процесс итерации останавливается, когда достигается требуемая предельная погрешность, т.е. когда выполнены условия остановки итерации:
 .
.
Данный метод хорош лишь в том случае, когда имеется некое первое оптимальное приближение, в противном случае результат может быть совсем иной, не удовлетворяющий критериям. Поэтому в данной работе мы используем его в комплексе с методом «Монте-Карло», в дальнейшем, получив начальное приближение, уточним его до некоторой погрешности градиентным методом наискорейшего спуска.
ПРИМЕРЫ РЕАЛИЗАЦИИ И РЕШЕНИЯ ЗАДАЧИ определЕНИЯ МИНИМУМА ФУНКЦИИ ЦЕЛИ В СРЕДЕ MATHCAD
Пусть задана многоэкстремальная функция:
 .
.
Рассмотрим
ее графики при различных изменениях
 .
Из первого графика видим, что глобальный
экстремум находится в районах
.
Из первого графика видим, что глобальный
экстремум находится в районах и равен примерно 75.
и равен примерно 75.

Если
смотреть другую область изменения, то
глобальный экстремум находится в районе
 .
Рассмотрим область изменения
.
Рассмотрим область изменения .
.

Используем
метод «Монте-Карло» для нахождения
глобального минимума функции. Сформируем
два вектора
 и
и ,
присвоив их нулевым элементам значение
нуль:
,
присвоив их нулевым элементам значение
нуль:

Зададим
количеством случайных чисел
 ,
которое мы будем использовать для
вычисления минимума. Чем больше это
количество, тем точнее будет результат
вычисления:
,
которое мы будем использовать для
вычисления минимума. Чем больше это
количество, тем точнее будет результат
вычисления:
 .
.
С
помощью функции
 создадим вектор случайных значений
элементов
создадим вектор случайных значений
элементов .
Функция
.
Функция генерирует равномерно распределенные
случайные числа в интервале 0…
генерирует равномерно распределенные
случайные числа в интервале 0… .
.
Из
графика видно, что нам достаточен
интервал
 .
.
 .
.
Теперь
в векторе
 помещено 100000 случайных чисел. Вычислим
значения функции от них и поместим их
в вектор
помещено 100000 случайных чисел. Вычислим
значения функции от них и поместим их
в вектор .
.
 .
.
Величину
минимального элемента этого вектора
найдем, используя функцию .
.

Величину
минимального элемента вектора
 найдем, используя небольшую программу
и вычислим по ней ответ:
найдем, используя небольшую программу
и вычислим по ней ответ:
 ,
,
 ,
,
 .
.
Получили первое приближенное значение минимума функции цели. Для уточнения значения используем градиентный метод. Поиск минимума ведется по следующим формулам:
 ,
,
 выбирается
из условия
выбирается
из условия
 .
.
 –параметр,
определяющий погрешность поиска
минимума.
–параметр,
определяющий погрешность поиска
минимума.
 -
отношение золотого сечения.
-
отношение золотого сечения.
 -
формула Бине
-
формула Бине
для
вычисления чисел Фибоначчи, где
 –
номер числа.
–
номер числа.
Сделаем
подпрограмму для вычисления частной
производной функции
 в точке заданной вектором
в точке заданной вектором по переменной
по переменной .
.
Подпрограмма выглядит следующим образом:

Сделаем подпрограмму для вычисления значений проекций градиента на оси координат. Подпрограмма возвращает вектор значений проекций и использует подпрограмму вычисления частной производной:
 .
.
Функция
 ,
используемая для выбора
,
используемая для выбора :
:
 .
.
Далее сделаем подпрограмму поиска минимума функции одной переменной по методу Фибоначчи (одномерной оптимизации функции цели).
Подпрограмма поиска минимума с помощью метода градиентного спуска:


Сформулируем
еще раз нашу многоэкстремальную
функцию:
 ,
,
 .
.
Находим,
в какой точке
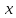 достигается минимум функции цели по
нашей программе:
достигается минимум функции цели по
нашей программе:
 .
.
Находим значение минимума функции цели:
 .
.
Отсюда можно сказать, что метод градиентного спуска подтвердил сходимость решения методом «Монте-Карло», [9, 10] .
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()


![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()


![]()
![]()
![]()
![]()
![]()
![]()



![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
Заключение
Целью
нашего рассуждения и последующего
исследования в работе является сведение
полученной задачи НМП (18) к классической
задаче математического программирования
(2), для той же целевой функции
 ,
[3, 5, 8-11].
,
[3, 5, 8-11].
Приложение: рисунки и таблица
 Рис.
1. Принципиальная модульно-структурная
схема ВК для SKAIS
ТЭС
Рис.
1. Принципиальная модульно-структурная
схема ВК для SKAIS
ТЭС
с теплофикационными установками.

Рис. 2. SKAIS - подсистема диагностики состояния энергоустановки
в контуре управления электростанции.
Рис.
3. Принципиальная блок – схема
 модуля
модуля .
.

Рис. 4. Диагностический комплекс SKAIS (реализованный вариант).

Рис.
5. «Похожесть» диагностируемого состояния
(при сравнении с нормативным значением
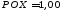 )
и определение фактического значения
)
и определение фактического значения (общее состояние энергоустановки) как
расстояния между ними, определяемое по
формуле [9]:
(общее состояние энергоустановки) как
расстояния между ними, определяемое по
формуле [9]:
 ,[9].
,[9].
Здесь
 -
вектор измеренных параметров;
-
вектор измеренных параметров; -
вектор эталонных значений параметров;
-
вектор эталонных значений параметров; -
количество анализируемых параметров;
-
количество анализируемых параметров; - наборы значений признаков (параметров
состояния) для диагностируемого (
- наборы значений признаков (параметров
состояния) для диагностируемого ( )
и эталонного (
)
и эталонного ( )
объектов (агрегатов),
)
объектов (агрегатов), коэффициент Фехнера (см. закон
Вебера-Фехнера,
коэффициент Фехнера (см. закон
Вебера-Фехнера, ,
где
,
где -
оценка некоторой величины
-
оценка некоторой величины при «ощущении»
при «ощущении» ).
).
При
этом,
 .
Если известно
.
Если известно элементов – эталонов
элементов – эталонов ,
где
,
где ,
то, используя понятие «похожесть», можно
найти ближайший к данному объекту
,
то, используя понятие «похожесть», можно
найти ближайший к данному объекту (его
состоянию) эталон
(его
состоянию) эталон по максимуму значения коэффициента
по максимуму значения коэффициента ,
где
,
где .
.
Таблица П.1
Массив
«весов» параметров-признаков (отклонение
мощности турбины ΔNЭ
и ее экономичности
Δ от
гарантийного значения,DELTA
= ΔNЭ/Δ
от
гарантийного значения,DELTA
= ΔNЭ/Δ )
турбоустановки
)
турбоустановки
Т – 100 – 130 ТМЗ ст. №7 Н ТЭЦ – 4 (в отдельных опытах до и после ремонта) и сравнение параметров состояний по мере «похожесть» (РОХ). Режим работы – конденсационный.
|
Номинальные (гарантийные) параметры |
|
|
|
|
|
|
|
|
РОХ
|
DELTA | |||||||||||
|
МВт |
МПа |
0С |
МПа |
т/ч |
0С |
м3/ч |
кДж/ кВтч |
-
|
МВт/кДж/кВтч | ||||||||||||
|
110,0 |
12,8 |
555,0 |
0,0049 |
480,0 |
5,8 |
16000 |
8918 |
1,00 |
- | ||||||||||||
|
Фактические параметры |
Перед ремонтом |
79,73 |
12,29 |
552,4 |
0,0218 |
392,6 |
22,5 |
13430 |
9245 |
0,52 |
| ||||||||||
|
75,09 |
12,29 |
549,8 |
0,0216 |
366,6 |
14,2 |
11762 |
9312 |
0,65 |
| ||||||||||||
|
64,5 |
12,87 |
546,0 |
0,019 |
326,6 |
12,6 |
10151 |
9513 |
0,61 |
| ||||||||||||
|
55,84 |
12,94 |
547,7 |
0,0156 |
302,2 |
13,4 |
9608 |
9689 |
0,57 |
| ||||||||||||
|
После ремонта |
83,1 |
12,8 |
550 |
0,0121 |
330,8 |
24,7 |
15300 |
8818 |
0,66 |
0,52/10,05 | |||||||||||
|
85,7 |
12,9 |
543 |
0,0059 |
339,7 |
22,2 |
15900 |
8843 |
0,64 |
0,61/15,9 | ||||||||||||
|
78,0 |
12,8 |
556 |
0,0052 |
323,6 |
22,2 |
14420 |
8819 |
0,67 |
0,39/14,2 | ||||||||||||
|
71,1 |
13,04 |
551 |
0,0056 |
289,0 |
24,3 |
15608 |
8887 |
0,61 |
0,92/10,9 | ||||||||||||
|
82,3 |
12,92 |
543 |
0,0061 |
332.7 |
17,1 |
15700 |
8829 |
0,66 |
0,63/15,9 | ||||||||||||








Здесь под РОХ («похожесть», Рис.5) понимается расстояние между признаками
(точнее их совокупностью образов) состояний энергоустановки близких номинальному (нормативному) состоянию. Похожесть фактического состояния энергоустановки номинальному состоянию определяется по формуле, [9]:
 .
.

Рис.6.
Элемент многомерного поиска оптимума
(по схеме
 )
) :
:
 -
где взять ближайшую точку – Эвристика!
– ближайшая точка совпадает с
-
где взять ближайшую точку – Эвристика!
– ближайшая точка совпадает с
 .
.
Роль искусственного интеллекта в архитектонике урбанизированного пространства
На современном этапе развития человечества разработаны и созданы технические и философские концепции в архитектуре и урбанистике, базирующиеся на системности и комплексности, т. е. системном подходе и системном анализе. Цифровые интеллектуальные технологии и компьютерное моделирование, представили сегодня проектировщикам сложных архитектурных объектов новые пути созидания в формообразовании и новые формы интеллектуального выражения архитектурных образов в градостроительстве. Действие системного фактора, при котором система, как целое, устанавливает заданные требования своим компонентам, а сами требования предъявляются с позиции достижения целевой функции – оптимизация эргономичности, экологичности, гармонии, композиции и надежности во времени существования «архитектурного произведения» – составляют основу проблемы исследуемой в данной работе.
Для решения задачи представляем математическую модель объектного образа «архитектурное произведение» в виде множества элементов динамической системы закрытого или открытого типов, используя при этом представляемую выше методологию «нечетких технологий». Динамическая система здесь составляется из основных определений (компонент «архитектурного произведения», выбранных в качестве основных характеристик), [9,112-114,117-119].
Алгоритм решения модели представим в виде И/ИЛИ-графа с выделением решающих подграфов. Такой алгоритм является одним из «механизмов» планирования решения особо сложных и плохо формализуемых задач, к которым относится проектирование и создание архитектурных произведений (ансамблей или объектов), [87, 117-119].
Исходную задачу (1) задаем начальным описанием в виде
 ,
(8.1)
,
(8.1)
где
 - образ «архитектурное произведение»;
- образ «архитектурное произведение»;
 -
множество начальных состояний образа;
-
множество начальных состояний образа;
 -
множество
«операторов», переводящих предметную
область (проектирование, создание) из
одного состояния в другое, согласно
знаниям проектировщика системы;
-
множество
«операторов», переводящих предметную
область (проектирование, создание) из
одного состояния в другое, согласно
знаниям проектировщика системы;
 -
множество целевых состояний.
-
множество целевых состояний.
Здесь
«оператором» является отображение,
преобразование, переводящее элемент
функционального пространства ( )
в
другой элемент того же самого пространства,
или какая-либо функция. Промежуточные
состояния обозначим через
)
в
другой элемент того же самого пространства,
или какая-либо функция. Промежуточные
состояния обозначим через
 .
.
Конечной целью сведения основной задачи оптимального проектирования «архитектурного произведения» к подзадачам, является получение элементарных задач, решения которых очевидны.
Элементарными
считаем задачи, которые могут быть
решены за один шаг, т.е. за одно применение
какого – либо оператора из множества
 (например,
использование уже готового проекта,
отдельного фрагмента, ордера).
(например,
использование уже готового проекта,
отдельного фрагмента, ордера).
Таким
образом, необходимо привести начальное
описание исходной задачи (1) к совокупности
более простых задач в пространстве
состояний, если удастся выделить основные
и оптимальные промежуточные состояния
 создаваемого «архитектурного
произведения».
создаваемого «архитектурного
произведения».
Каждому из этих состояний в соответствие можно поставить свое описание в виде троек:
 (8.2)
(8.2)
Решение
этих подзадач эквивалентно решению
исходной задачи
 .
.
На этой идее построен в теории систем искусственного интеллекта основной «механизм» сведения сложной многоэкстремальной задачи к подзадачам, использующий эвристические методы поиска в пространстве состояний, [117].
Представим структуру «архитектурное произведение» в виде динамической системы вида:
 ,
(8.3)
,
(8.3)
где
 -
архитектурное
произведение
-
архитектурное
произведение комплексный
эстетический механизм (семантика
ансамбля, стиль),
комплексный
эстетический механизм (семантика
ансамбля, стиль),
 -
знания
-
знания
 интеллект
(творчество, эвристика),
интеллект
(творчество, эвристика),
 -
восприятие
-
восприятие
 искусство
(целостность),
искусство
(целостность),
 -
образ
-
образ
 интуиция,
интуиция,
 -
отображение
-
отображение
 эстетика (выразительность),
эстетика (выразительность),
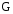 -
композиция
-
композиция
 гармония,
гармония,
 -
пропорции
-
пропорции
 симметрия (соразмерность),
симметрия (соразмерность),
 -
трансформация
-
трансформация изоморфизм,
изоморфизм,
 -
устойчивость
-
устойчивость
 катастрофа
(разрушение),
катастрофа
(разрушение),
 -
конструктивность
-
конструктивность
 пластичность,
пластичность,
 -
экологичность
-
экологичность
 надежность
(живучесть),
надежность
(живучесть),
 -
внешняя
среда
-
внешняя
среда
 неопределенность
(хаос),
неопределенность
(хаос),
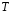 -
топология
-
топология
 время.
время.
Здесь
символ « »
обозначает
взаимно-однозначное соответствие,
»
обозначает
взаимно-однозначное соответствие,
« »
- внешний фактор.
»
- внешний фактор.
Таким
образом, динамическая система (8.3), в
первом приближении, будет состоять из
двенадцати определений (компонент)
«архитектурного произведения», согласно
его структуре
 ,
[117].
,
[117].
Построение основного механизма сведения задачи (1) к подзадаче (2) выполняем по шагам:
Шаг
1. Выделяем
один оператор
 ,
который
обязательно будет участвовать в решающей
цепочке операторов. Все операторы такого
типа называются ключевыми, т.е. участвующими
в решающей цепочке.
,
который
обязательно будет участвовать в решающей
цепочке операторов. Все операторы такого
типа называются ключевыми, т.е. участвующими
в решающей цепочке.
Шаг 2. Для каждого из ключевых операторов определяем промежуточные состояния, к которым они могут быть применены в условиях задачи (1).
Для
оператора
![]() это
будет состояние
это
будет состояние![]() .
Таких
состояний может быть несколько, и тогда
они образуют подмножество целевых
состояний
.
Таких
состояний может быть несколько, и тогда
они образуют подмножество целевых
состояний
![]() .
.
В
результате выделим подзадачу поиска
пути от начала до состояния
![]() (или
до
(или
до
![]() ,точнее
от
,точнее
от
![]() ,
т.е.
приблизимся к возможному решению).
,
т.е.
приблизимся к возможному решению).
В
результате применение оператора
![]() привело к подзадаче - 1 с описанием
привело к подзадаче - 1 с описанием
в
виде кортежа![]() ,
или
,
или
![]() .
Здесь
.
Здесь![]() -
начальные
состояния образа
-
начальные
состояния образа
![]() и состояние в области цели
и состояние в области цели![]() .
.
Шаг
3. Еслитакое
описание найдено, то формулируем
2-юподзадачу, соответствующую 1-й
(элементарной). При этом если состояние
![]() соответствует
оператору
соответствует
оператору![]() ,
то
можно применить его к
,
то
можно применить его к
![]() и
получить, в результате, новое состояние
и
получить, в результате, новое состояние![]() ,
приближающее решение к конечной цели,
но только на один шаг.
,
приближающее решение к конечной цели,
но только на один шаг.
Шаг
4. От
вновь полученного состояния
![]() до
конечной цели
до
конечной цели![]() может быть еще несколько шагов, что
представляет 3-ю подзадачу.
может быть еще несколько шагов, что
представляет 3-ю подзадачу.
Таким
образом, применение выбранного оператора
![]() к
задаче с описанием
к
задаче с описанием![]() позволяет
выделить сразу 3 подзадачи:
позволяет
выделить сразу 3 подзадачи:
![]() ,
(8.4)
,
(8.4)
одна из которых элементарная.
Представим изложенное на линейном графике, (рис. 8.1).
Здесь
все решение изображено отрезком, который
разбивается точкой
![]() ,
соответствующей
оператору
,
соответствующей
оператору
![]() ,
на
подзадачи (п/з):
,
на
подзадачи (п/з):
![]()
![]()
![]()
![]()
![]()
![]()
![]()
1-я п/з 2-я п/з 3-п/з
Рис. 8.1. Разбиение задачи на подзадачи.
Такому разбиению будет соответствовать следующий И/ИЛИ – граф, (рис. 8.2):
![]()
![]()
![]()
1-я п/з 2-я п/з 3-п/з
Рис.
8.2. И/ИЛИ – граф разбиения на подзадачи
для состояния
![]() .
.
Элементарная
подзадача типа 2 решается для любой
выбранной точки
![]() пространства
состояния, поэтому ее можно не указывать.
пространства
состояния, поэтому ее можно не указывать.
Точка
![]() -
одна из возможных промежуточных целей:
-
одна из возможных промежуточных целей:
![]() .
(8.5)
.
(8.5)
Выбрав
ее, мы применяем к ней оператор
![]() .
.
Обобщая сказанное, приходим к окончательному виду И/ИЛИ – графа разбиения на подзадачи для одной точки (рис. 8.3):
![]()
![]()
![]()
Рис.
8.3. Обобщенный И/ИЛИ – граф для одной
точки
![]() .
.
Вывод. Для разбиения задачи на подзадачи и построения соответствующего И/ИЛИ – графа нужны ключевые операторы (обычно более одного). Один из способов нахождения операторов, могущих быть ключевыми, состоит в вычислении различий между состояниями по пути от
![]() (состояние
на пути от начальной точки до целевой).
(состояние
на пути от начальной точки до целевой).
Каждому
возможному различию ставится в
соответствие оператор (или их множество),
который это различие может устранить.
Цепочка операторов, последовательно
устраняющих различия между
![]() и будет решением задачи, [119].
и будет решением задачи, [119].
Представим
на рис. 8.4 интерпретацию структуры
модели «архитектурное произведение»![]() , (8.3):
, (8.3):

Рис. 8.4. Интерпретация структуры модели
«архитектурное
произведение»
![]() .
.
Выход
системыможет быть описан вектором
![]() .
Здесь:
.
Здесь:![]() -
вход,
-
вход,![]() -
выход,
-
выход,![]() -
внешняя среда,
-
внешняя среда,![]() -
внешний фактор (эстетика). Изменение
состояния такой системы происходит во
времени
-
внешний фактор (эстетика). Изменение
состояния такой системы происходит во
времени![]() .
.
Далее
изобразим вход
системы в виде
вектора
![]() ,
компонентыкоторого характеризуют
внешние факторы, действующие на систему,
включая и параметры внешней среды.Эти факторы могут
быть не взаимосвязанными и представляются
параметрами условий эксплуатации
объекта или параметрами смежных систем.
Внутренняя структура «архитектурного
произведения» может быть описана
вектором
,
компонентыкоторого характеризуют
внешние факторы, действующие на систему,
включая и параметры внешней среды.Эти факторы могут
быть не взаимосвязанными и представляются
параметрами условий эксплуатации
объекта или параметрами смежных систем.
Внутренняя структура «архитектурного
произведения» может быть описана
вектором
![]() ,
компоненты которого характеризуют
собственно параметры «архитектурного
произведения» (конструкция, гармония,
симметрия, стиль, целостность, надежность
и т.д.), причем между некоторыми из этих
параметров может и не существовать
функциональная взаимосвязь. Эти параметры
«архитектурного произведения», как
системы, могут быть выходными параметрами
её компонентов и параметрами процессов
взаимодействия структуры модели,
компоненты которой характеризуют
параметры процесса воздействия системы
на внешнюю среду (урбанистику),
(рис.8.5).параметры внешней среды.
,
компоненты которого характеризуют
собственно параметры «архитектурного
произведения» (конструкция, гармония,
симметрия, стиль, целостность, надежность
и т.д.), причем между некоторыми из этих
параметров может и не существовать
функциональная взаимосвязь. Эти параметры
«архитектурного произведения», как
системы, могут быть выходными параметрами
её компонентов и параметрами процессов
взаимодействия структуры модели,
компоненты которой характеризуют
параметры процесса воздействия системы
на внешнюю среду (урбанистику),
(рис.8.5).параметры внешней среды.

Рис.8.5.
Система – «машина – человек — объект»,
![]() .
.
Здесь:
![]() - параметры объекта;
- параметры объекта;![]() - параметры человека-оператора;
- параметры человека-оператора;
![]() -
параметры архитектурного произведения;
-
параметры архитектурного произведения;
![]() - критерий оптимальности подсистемы
«объект-человек»;
- критерий оптимальности подсистемы
«объект-человек»;![]() - критерий оптимальности подсистемы
«человек-объект»;
- критерий оптимальности подсистемы
«человек-объект»;![]() - выходные параметры системы
- выходные параметры системы![]() ,
(при
втором приближении).
,
(при
втором приближении).
Именно эти параметры интересуют в первую очередь население (урбанистику) проектируемого ОБЪЕКТА. Выходные параметры архитектурного произведения образуются в результате взаимодействия внутренней и внешней среды и реакции экологической системы.
Поэтому при втором
приближении, для полного описания
состояния архитектурного произведения
(как системы
![]() ),
необходимо знать уравнения связей и
отношений между параметрами внутри
такой системы, так и между параметрами
системы и параметрами внешней среды
(выхода от входа). Уравнение связей
системы будет иметь вид:
),
необходимо знать уравнения связей и
отношений между параметрами внутри
такой системы, так и между параметрами
системы и параметрами внешней среды
(выхода от входа). Уравнение связей
системы будет иметь вид: (8.6)
(8.6)
Но
таким путем описывается поведение
объекта как статической системы, у
которой векторы параметров
![]() описывают её состояние в фиксированный
момент времени. Для случая представления
«архитектурного произведения», как
динамической системы, необходимо вход
системы описать вектором параметров
описывают её состояние в фиксированный
момент времени. Для случая представления
«архитектурного произведения», как
динамической системы, необходимо вход
системы описать вектором параметров![]() ,
саму систему – вектором параметров
,
саму систему – вектором параметров![]() ,
а выход – вектором параметров
,
а выход – вектором параметров![]() ,
компоненты которых зависят от моментов
времени
,
компоненты которых зависят от моментов
времени![]() ,
где
,
где![]() -
множество моментов времени.
-
множество моментов времени.
Следовательно,
в общее понятие урбанизации объекта
«архитектурное произведение» мы
включаем вспомогательное множество
моментов времени
![]() .
В каждый рассматриваемый момент времени
.
В каждый рассматриваемый момент времени![]() система
система![]() получает некоторое входное воздействие
получает некоторое входное воздействие![]() и, в ответ, порождает некоторую выходную
величину
и, в ответ, порождает некоторую выходную
величину![]() .
.
Тогда уравнение связей такой динамической системы, будет иметь вид:
![]() .
(8.7)
.
(8.7)
Полученное
уравнение связей выражает зависимость
потенциального технико-экономического
и экологического уровня архитектурного
произведения от различных параметров,
характеризующих как сам объект, так и
внешнюю среду, включая и урбанистику
объекта, (рис. 8.6), которые находятся
между собой в некотором отношении связи
![]() .
.

Рис. 8.6. Человек и «архитектурное произведение» в системе
«машина-человек-объект» в среде проектирования.
Здесь:
![]() -
параметры процесса проектирования;
-
параметры процесса проектирования;![]() -
параметры урбанистики;
-
параметры урбанистики;![]() -
параметры объекта;
-
параметры объекта;![]() -
параметры человека-оператора;
-
параметры человека-оператора;![]() -
параметры архитектурного произведения;
-
параметры архитектурного произведения;![]() -
параметры
-
параметры![]() «агрегатов» (элементов) технологического
комплекса (ансамбля);
«агрегатов» (элементов) технологического
комплекса (ансамбля);![]() - критерий оптимальности технологического
процесса создания архитектурного
произведения, его оптимизации,
математической модели, в соответствии
с изменением эксплуатационного фона -
урбанистики.
- критерий оптимальности технологического
процесса создания архитектурного
произведения, его оптимизации,
математической модели, в соответствии
с изменением эксплуатационного фона -
урбанистики.
Решение уравнения связей архитектурного произведения как системы, т.е., конкретизация, моделирование зависимости технико-экономического уровня архитектурного произведения от различных параметров - конечная цель разработки прогноза проектирования и построения архитектурного произведения в эксплуатации и отработке до деградации (и разрушения), (рис.8.7).

Рис. 8.7. Концепция «интеллектуального моделирования» архитектурного произведения, с учетом его «времени жизни» в эксплуатации (в урбанистике).
Здесь под реновацией подразумевается обновление (реконструкция), SKAIS – «система контроля, анализа и слежения за изменением состояния объекта», представляющая программную интегрированную систему, с помощью которой можно решать рассматриваемую задачу, [9].
В этом и заключена идея концепции «интеллектуального моделирования» архитектурного произведения в его «времени жизни», [87, 120].
Основной смысл «интеллектуального моделирования» – ускоренные приближенные (мягкие) расчеты, ориентированные на синтезе законов теории систем и искусственного интеллекта при моделировании объектов, для которых показатели качества и точности управления (здесь это проектирование и строительство архитектурных объектов) поддерживаются в заданном интервале времени, (см. также [87, 121]).
Для решения этой задачи представим на рис. 8.8 расширенное системное уравнение математической модели состояния архитектурного произведения, в виде множества элементов динамической системы, составленное из пятнадцати определений архитектурного произведения, как сложной системы (согласно его структуре, (8.3), [9, 120- 126]:
![]() .
(8.8)
.
(8.8)

Рис.
8.8. Интерпретация структуры интеллектуальной
модели – «архитектурное произведение»
-![]() ,
при
втором приближении.
,
при
втором приближении.
Здесь:
![]() -
время,
-
время,![]() -
архитектурное произведение,
-
архитектурное произведение,![]() -
конструктивность,
-
конструктивность,![]() -
внешняя среда (урбанистика, природная
среда),
-
внешняя среда (урбанистика, природная
среда),![]() -
эвристическое состояние (знания человека)
объекта,
-
эвристическое состояние (знания человека)
объекта,![]() -
информация (композиция) об объекте,
-
информация (композиция) об объекте,![]() -
признаки состояния объекта,
-
признаки состояния объекта,![]() -
симметрия (пропорции) объекта,
-
симметрия (пропорции) объекта,![]() - множество решений о состоянии
архитектурного произведения,
- множество решений о состоянии
архитектурного произведения,![]() -
трансформация объекта,
-
трансформация объекта,![]() -
значения операторов формирования
состояния,
-
значения операторов формирования
состояния,![]() -
оператор обработки исходных данных (
-
оператор обработки исходных данных (![]() )
- наблюдений и обработки данных,
)
- наблюдений и обработки данных,![]() -
оператор преобразования данных (
-
оператор преобразования данных (![]() )
- первичного и вторичного преобразований,
)
- первичного и вторичного преобразований,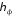 -
функциональная связь в уравнении
-
функциональная связь в уравнении ,
, -
функциональная связь в уравнении
-
функциональная связь в уравнении ,
, -
моменты времени на входе и выходе из
объекта.
-
моменты времени на входе и выходе из
объекта.
В этой связи следует проанализировать два основных состояния архитектурного произведения - как объекта эксплуатации (применения) и как объекта оптимального проектирования, для урбанистики. Архитектурное произведение, в этих состояниях, должно рассматриваться в интерактивном режиме как часть системы более высокого порядка. Для достоверности и результативности такого анализа в диалоге человек-машина (интерактивный режим) необходимо поэтапно обособлять компоненты системы, все более сужая границу, выделяющую анализируемую часть системы.
Основной задачей анализа архитектурной системы является её нелинейная оптимизация, т.е. создание наилучшего (оптимального) состояния, в соответствии с целевой функцией и критерием оптимальности (и с учетом определенных ограничений): оптимизация эргономичности, экологичности, гармонии, композиции и надежности во времени «архитектурного произведения».
При этом можно выделить как минимум три задачи оптимизации архитектурной системы:
1) выбор оптимального варианта из возможных состояний системы при заданных ограничениях и цели;
2) выбор экономически наивыгоднейшего направления изменения (совершенствования) системы;
3) интеллектуальное (мягкое) проектирование с помощью программного комплекса SKAIS + REVIT ARCHITECTURE.
Первая
задача решается для проектируемой
системы, вторая – для реализуемой,
третья — для урбанистики. При этом
обязательно выполнение сравнения и
анализа достигаемого состояния системы
с критерием (или критериями) оптимальности
её состояния, с учетом заданных
ограничений. Этой цели служит установление
обратной связи между выходными параметрами
системы
 и критерием её оптимальности
и критерием её оптимальности .
.
Для такого сложного и многофункционального объекта, как архитектурное произведение, может быть применено несколько критериев оптимальности и поэтому возможно образование не одного, а нескольких контуров обратной связи, так как оптимизация будет выполняться по векторному принципу и в условиях неопределенности, [122-126].
Принцип «интеллектуального (мягкого) моделирования процесса проектирования», внедряемый автором в технологические процессы и применяемые здесь методы теории искусственного интеллекта [116-119, 87, 120, 121, 123], позволяют проектировать объекты архитектуры системно, с учетом влияния «времени жизни» на изменение состояния. Таким образом, можно получить желаемые - «архитектурное произведение» и урбанистику.
На основе получаемых знаний истинного состояния критических элементов объекта, возможно, идентифицировать его и представить в темпе on-line как непрерывный процесс, протекающий параллельно проектированию и, следовательно, урбанистике. В результате, применяемая здесь параметрическая идентификация архитектурного объекта (или отдельных его элементов), позволит обеспечить максимальную адаптацию математической модели (объекта), ее адекватность объекту и урбанистике.
В дальнейшем совокупность получаемых математических моделей архитектурных произведений объектов позволит создать базу знаний (банк данных). Анализ данных может быть использован как в процессе проектирования различных архитектурных объектов, так и в процессе урбанизации [126, 128].
Контрольные вопросы и задания по самостоятельной работе к главе 8 и 9
8.1. Концепция эволюционных вычислений?
8.2. Основы теории генетических алгоритмов?
8.3. Самоорганизующиеся карты?
8.4. Вероятностные нейронные сети?
8.5. Программное обеспечение: Evolver?
8.6. Программное обеспечение: GTO (Genetik Training Option-Режим Генетического
обучения)?
Заключение
Рассмотренные в учебном пособии нечеткие технологии могут с успехом использоваться как прикладные технологии «вычислительного интеллекта». Примером тому могут служить запуск в 1987 г. системы управления новым метро в г. Сендай около Токио и увеличение экспорта японских изделий с встроенными в них «fuzzy logic» к 1991г. до 25 млрд долл. США. Американской фирмой AAC (Accurate Automation Corp.) был разработан нейрокомпьютерный чип на базе MIMD-архитектуры, который содержит 16-разрядный специализированный процессор, эмулирующий 8192 нейрона и память для хранения 32768 16-разрядных синаптических весов. Производительность нейрокомпьютера – 140 переключений млн в секунду; он был установлен на борту экспериментального гиперзвукового самолета, скорость полета которого в 5 раз превышала скорость звука LoFLYTE (Low-Observable Flight Test Experiment). На бортовой нейрокомпьютер были возложены функции управления полетом, поскольку летчик на таких скоростях не в состоянии управлять самолетом.
Таким образом, совершенно ясно, что «вычислительный интеллект» это современная, успешная электронная и программная индустрия. Дж. Клир излагает в [127]: «Одним из способов работы с очень сложными системами, возможно, самым важным, является допущение неточности при описании данных … Математический аппарат для этого подхода, разрабатываемый с середины 1960-х годов, известен как ”теория нечетких множеств”». Вероятно, самым существенным достижением «вычислительного интеллекта» является создание способа описания систем, сочетающего число и слово, сигнал и понятие, восприятие и абстракцию, непрерывное и дискретное. Именно такой способ описания необходим для техногенных, гуманистических систем.
Автор: Крохин Геннадий Дмитриевич, доктор технических наук,
профессор Новосибирского государственного университета экономики и
управления - «НИНХ» г. Новосибирска (НГУЭиУ),
раб.тел. +7(383)243-95-19, моб.т. 8-983-309-05-03.
E-mail: gdkrokhin@mail.ru
СПИСОК ЛИТЕРАТУРЫ
Кантор Г.Труды по теории множеств. Ч.1: Работы по теории множеств. М.: Наука, 1985. – с.9-245.
Киселев А.П.Алгебра. М.: Наука, 1965.
Блехман И.И., Мышкис А.Д., Гановко Я.Г. Механика и прикладная математика: Логика и особенности приложений математики. М.: Наука. Гл. ред. физ.-мат. лит., 1990.-360с.
Александров П.С. Введение в теорию множеств и общую топологию. М.: Наука. Гл. ред. физ.-мат. лит., 1977.-368с.
Лузин Н.Н. Лекции об аналитических множествах и их приложениях. М.: ГИ Техн.-теоретич. Лит., 1953.-360с.
Бурбаки Н.Теория множеств. 1-я Ч., Кн. 1-я. М.: Мир, 1965. -456с.
Кондаков Н.И. Логический словарь-справочник. М.: Наука, 1975. -720с.
Беллман Р., Дрейфус С. Прикладные задачи динамического программирования. М.:Наука, 1965. - 459с.
Крохин Г.Д. Математические модели идентификации технического состояния турбоустановок на основе нечеткой информации. Автореферат дисс. на соиск. учен. ст. д.т.н. Иркутск, 2008. -48с.
Рутковский Л. Методы и технологии искусственного интеллекта. М.: Горячая линия-Телеком, 2010. -520с.
Нечеткие множества в моделях управления и искусственного интеллекта. //А. Н. Аверкин, И. З. Батыршин, А.Ф. Блишун, В. Б. Силов, В. Б. Тарасов. - М.: Наука, ФМЛ, 1986. – 312с.
12. Zadeh L. A. Fuzzy sets. // Information and control. - 1965.V.8, No.3.-P.338-353.
13. Заде Л. Понятие состояния в теории систем.//Сб. Общая теория систем. Под
ред. М. Месаровича.- М.: Мир, 1966. – с.49 – 65.
14. Заде Л. А. Тени нечетких множеств. //Проблемы передачи информации. –
1966, №1. - с. 37-44.
15.Заде Л.А. Понятие лингвистической переменной и его применение к
принятию приближенного решения. М.: Мир, 1976. -165с.
16. Заде Л. А. Основы нового подхода к анализу сложных систем принятия
решений. //Математика сегодня: Сб. - М.: Знание, 1974. - с.5-49.
17. Беллман Р., Заде Л. Принятие решений в расплывчатых условиях. // Вопросы
анализа и процедуры принятия решений. М.: Мир, 1976.- с. 172-215.
18. Борель Э. Вероятность и достоверность. М.: Наука, 1964.
19. Жордан К.Математический анализ. М.: Наука, 1887.
20. Лебег А.Об измерении величин. М.: Наука, 1960.
21. Сугэно М. Нечеткие множества и их применение в логическом управлении.
//Кэйсрку то сэйге.- 1979.-Т.18, N2. – с. 150-160.
22. Дюбуа Д., Прад А. Теория возможностей. Приложения к представлению
знаний в информатике. М.: Радио и связь, 1990. – 287с.
23. Dempster A.P. Upper and lower probabilities induced by a multivalued mapping.
Ann. Math. Statist, (1967). 38, 325-339.
24. Shafer G. Non-additive probabilities in the works of Bernoulli and
Lambert. Archives for the History, 1978. 309-370.
25. Маслов С.Ю.Теория дедуктивных систем и ее применения. М.; Радио и
связь, 1986.-136с.
26. Физический энциклопедический словарь, М.: СЭ, 1983. -928с.
27. Аткинсон Р., Бауэр Г., Кротерс Э. Введение в математическую теорию
обучения. М.: Мир, 1969. – 486с.
28. Энциклопедия кибернетики (в 2-х.Т.), т.1. Киев: Гл.ред, УСЭ, 1974. -608с.
29. Элементы теории испытаний и контроля технических систем. //Городецкий
В.И., Дмитриев А.К., Марков В.М., Петухов Г.Б., Юсупов Р.М.- Л.:
Энергия,1978. – 192с.
30. Крохин Г.Д. Программа решения проблемы диагностики энергетического
оборудования. // «Материалы межвузовского научного семинара по
проблемам теплоэнергетики». - Саратов, СГТУ, 1996. - с.21-25.
31. Аракелян Э.К. Особенности выбора структуры общестанционной
автоматизированной системы комплексной диагностики.
// Теплоэнергетика. - 1994, №10. – с. 19-22.
32. Крохин Г.Д., Манусов В.З. Диагностика состояния турбинных установок
тепловых электростанций с использованием теории нечетких множеств.
//Труды IV международной конференции «Актуальные проблемы
электронного приборостроения» АПЭП –98, в 16-ти т.- Новосибирск,
НГТУ, 1998. Т.11. - с.48-49.
33. Денисов В.И., Полетаева И.А., Хабаров В.И. Экспертная система для
анализа многофакторных объектов. Дисперсионный анализ. Прецедентный
подход. Новосибирск, НЭТИ, 1992. – 128с.
34. Goguen J.A. On Fuzzy Robot Planning. // Fuzzy Sets and their Applications to
Cognitive and Decision Processes. Academic Press, 1975.
35. Букур И., Деляну А. Введение в теорию категорий и функторов. М.: Мир,
1972. -260с.
36. Блаck M. Vagueness: on exercise in logical analusis.Philos. Sci. 4, p. 427-455,
1951.
37. Суппес П., Зинес Дж. Психологические измерения. М.: Мир, 1967. (Основы
теории измерений. - с.9-110).
38. Математическая энциклопедия. М.: Изд-во СЭ, (в 5-ти Т.), 1985. Т. 3 –с.1183.
39. Новиков Ф.А. Дискретная математика для программистов. СПб.:
Питер, 2001. -304с.
40. Сикорский Р. Булева алгебра. М.: Мир, 1969. -376с.
41. Bellman R. and Giertz M. (1973). Onthe Analitic
Formalism of the Theory of Fuzzy Sets. Inf. Sci., 5, 149-156.
42. Бернулли Я.О законе больших чисел. М., 1986.
43. Бехтерева Н. П. Нейрофизиологические аспекты психической деятельности
человека. Л., «Медицина», 1974.
44. Терано Т. Введение в системотехнику. Токио: Керицу сюппан, 1985.
45. Перегудов Ф.И., Тарасенко Ф.П. Основы системного анализа. Томск, НТЛ,
1997. – 389с.
46. Крохин Г.Д., Мухин В.С., Судник Ю.А. Интеллектуальные технологии в
теплоэнергетике: Монография (ч. 1). М.: ООО «УМЦ «Триада», 2010. -170с.
47. Загоруйко Н.Г. Прикладные методы анализа данных и знаний. Новосибирск:
ИМ, 1999. – 270с.
48. Ту Дж., Гонсалес Р. Принципы распознавания образов. М.: Мир, 1978. –
413с.
49. Прикладная статистика: Классификация и снижение размерности.
Справочное издание. //С.А. Айвазян, В.М. Бухштабер, И.С. Енюков, Л.Д.
Мешалкин. – М.: Финансы и статистика, 1989. – 607с.
50. Соловьев И.А., Зуев А.В., Кириллов В.А. и др. Обработка данных
теплофизических экспериментов с учетом погрешностей всех измеряемых
величин. //Инж. -физ. журн.. -1992. Т.62, № 2. – с. 294-300.
51. Айвазян С.А., Бежаева З.И., Староверов О.В. Классификация многомерных
наблюдений. М.: Статистика, 1974. – 240с.
52. Ицкович Э.Л. Контроль производства с помощью вычислительных машин. М.:
Энергия, 1975. – 415с.
53. Айзерман М.А. Нечеткие множества, нечеткие доказательства и некоторые
нерешенные задачи теории автоматического регулирования.//Автоматика и
телемеханика.- 1976, № 7. - с. 171 - 177.
54. Поляк Б.Т. Методы минимизации функций многих переменных. // Экономика и
мат. методы.- 1967, Т.3, вып.6. – с. 881-902.
55. Супруненко М.Я. Эвристический подход при разработке алгоритмов
распознавания и оптимизации. Новосибирский гуманитарный университет,
г. Новосибирск, 2004. -69с.
56. Цыпкин Я.З. Управление динамическими объектами в условиях ограниченной
неопределенности. Современное состояние и перспективы развития.
//Измерение, контроль, автоматизация. - 1991, № 3-4. – с. 3-21.
57. Красовский А.А. Проблемы физической теории управления. //Автоматика и
телемеханика. - 1990, № 11. – с. 3-27.
58. Моисеев Н.Н., Иванилов Ю.П., Столяров Е.М. Методы оптимизации. М:
Наука, 1978. – 352с.
59. Язенин А.В. Методы оптимизации и принятия решений при нечетких данных.
Автореферат дисс. доктора физ.-мат. наук. Тверь: ТГУ, 1995. – 49с.
60. Борисов А.Н., Алексеев А.В., Меркурьева Г.В. и др. Обработка нечеткой
информации в системах принятия решений. М.: Радио и связь, 1989. – 304с.
61. Борисов А.Н., Алексеев А.В., Крумберг О.А. и др. Модели принятия решений
на основе лингвистической переменной. Рига: Зинатне, 1982. – 256с.
62. Борисов А.Н., Вилюмс Э.Р., Сукур Л.Я. Диалоговые системы принятия
решений на базе ЭВМ. Рига: Зинатне, 1986. – 195с.
63. Борисов А.Н., Крумберг О.А., Федоров И.П. Принятие решений на основе
нечетких моделей. Рига: Зинатне, 1990. – 184с.
64. Батыршин И.З. Методы представления и обработки нечеткой информации в
интеллектуальных системах. /Новости искусственного интеллекта.1996, №2.
–с. 9 - 65.
65. Алиев Р. А., Церковный А. Э., Mамедова Г. А. Управление производством при
нечеткой исходной информации. М.: Энергоатомиздат, 1991. - 240 с.
66. GoguenJ.A. L-fuzzysets. //J. Math. Anal. Appl., 1967, V.18. – pp.145-174.
67. Ломакина Л.С., Сагунов В.И. Оптимизация глубины диагностирования
непрерывных объектов. //Автоматика и телемеханика. - 1986, №3. – с. 146-152.
68. Назаров В.И. Коррекция коэффициентов математической модели
энергоблока для задачи контроля достоверности информации в АСУ ТП
ТЭС и АЭС. // Известия ВУЗов. Энергетика. -1994, №3-4. – с.97-100.
69. Демидович Б.П., Марон И.А. Основы вычислительной математики. М.:
Наука, 1970. – 664с.
70. Бенедикт Р. Инженерный анализ экспериментальных данных. // Труды
американского общества инж.-мех. Серия А. Энергетические машины и
установки. - 1969, Т. 91, №1. - с.32-47.
71. Иган Дж. Теория обнаружения сигналов и анализ рабочих характеристик.
М.: Наука ФМЛ, 1983. – 213с.
72. Крохин Г.Д. Проблемы получения достоверной информации при
диагностике функционального состояния энергоустановок. //Труды второй
международной науч. - техн. конф. «Актуальные проблемы электронного
приборостроения» АПЭП – 94, в 7-ми т.- Новосибирск, НГТУ, 1994.
Т.1.- с.207-213.
73. Хартли Р. Передача информации. // Теория информации и ее приложения. -
М.: Физматиздат, 1959. – с.5 – 35.
74. Методы решения задач реального времени в электроэнергетике. //
Гамм А. З., Кучеров Ю. Н., Паламарчук С. И. и др. - Новосибирск: Наука
СО,1991. – 264с.
75. Бриллюэн Л. Наука и теория информации. М.: ГИ ФМЛ, 1960. – 392с.
76. Эшби У. Росс. Введение в кибернетику. М.: ИЛ, 1959. – 432с.
77. Гамм А. З., Герасимов Л. Н., Голуб И. И. и др. Оценивание состояния в
электроэнергетике. М.: Наука, 1983. – 302с.
78. Гамм А. З., Голуб И. И. Наблюдаемость электроэнергетических систем. М.:
Наука, 1990. -200с.
79. Рутковский Д., Пилинский М., Рутковский Л.
Нейронные сети, генетические алгоритмы и нечёткие системы.
М.: Горячая линия-Телеком, 2004. - 452с.
80. Анохин П.К. Очерки по физиологии функциональных систем. М.:
Медицина, 1975. -448с.
81. Редько В.Г. Эволюция. Нейронные сети. Интеллект. Модели и концепции
эволюционной кибернетики. М.: Книжный дом «ЛИБРОКОМ», 2013. -224с.
82. Фогель Л., Оуэнс А., Уолш М. Искусственный интеллект и эволюционное
моделирование. М.: Мир, 1969. -232с.
83. Holland J.H., Holyoak K.J., Nisbett R.E., Thagard P. Induction: Processes of
Inference, Learning, and Discovery. Cambridge, MA: MIT Press, 1986.
84. Koza J. GeneticProgramming: On the Programming of Computers by Means of
Natural Selection. The MIT Press, 1992.
85. Koza J. GeneticProgramming 11: Automatic Discovery of Reusable
Subprograms. TheMITPress, 1994.
86. Курейчик В.М. Генетические алгоритмы и их применение. Таганрог:
ТРТУ, 2002.
87. Арнольд В.И. «Жесткие» и «мягкие» математические модели. М.:
Изд-во МЦНМО, 2004. -32с.
88. Цетлин М.Л. Исследования по теории автоматов и моделирование
биологических систем. М.: Наука, 1969. – 316с.
89. Rumelhart D.E., Hinton G.E., WilliamsR.G. Learningrepresentationbyback-
propagatingerror//Nature. 1986. Vol. 323. № 6088. Pp. 533-536.
90. Фон Нейман Дж. Теория самовоспроизводящихся автоматов. М.: Мир, 1971.
-382с.
91. Хайкин С. Нейронные сети. М.: Издательский дом «Вильямс», 2006. -1104с.
92. Емельянов В.В., Курейчик В.М., Курейчик В.В. Теория и практика
эволюционного моделирования. М.: Физматлит, 2003.
93. Маурер У. Введение в программирование на языке ЛИСП. М.: Мир, 1976.
–104с.
94. Сигорский В.П. Математический аппарат инженера. Киев: «Технiка», 1975.
- 768с.(330с.)
95. Трауб Дж., Васильковский Г., Вожьняковский Х. Информация,
неопределенность, сложность. М.: Мир, 1988. – 184с.
96. Кондаков Н.И. Логический словарь-справочник. М.: Изд-во «Наука»,1975.
-720с. (с.359-363)
97. Нечеткие множества и теория возможностей./Под ред. Р.Р. Ягера.М.: Радио и
связь, 1986. -408с. (Прад А. Модальная семантика и теория нечетких
множеств). с.161-177
98. Кендалл М. Дж., Стьюарт А. Статистические выводы и связи. М.: Наука,
1973. -900с. (с.40-45)
99. Румшинский Л.З. Математическая обработка результатов эксперимента.
Справочное руководство. М.: Наука, 1971. -192с.
100. Налимов В.В. Теория эксперимента. М.: Наука, 1971. -208с.
101. Агекян Т.А. Основы теории ошибок для астрономов и физиков. М.: Наука,
1972. -172с.
102. Кофман А. Введение в теорию нечетких множеств. М.: Радио и связь, 1982. –
432с.
103. Кулик Б.А. Логические основы здравого смысла. СПб: Политехника, 1997.
– 132с.
104. Доорс Дж., Рейблейн А.Р., Вадера С. ПРОЛОГ – язык программирования
будущего. М.: Финансы и статистика, 1990. – 144с.
105. Клоксин У., Меллиш К. Программирование на языке ПРОЛОГ. М.: Мир,
1987.
106. Братко И. Алгоритмы искусственного интеллекта на языке PROLOG.
М.: ВИЛЬЯМС, 2004. – 640с.
107. Пенроуз Р. Тени разума. В поисках науки о сознании. -
Ижевск: Институт компьютерных исследований, 2005. -688с.
108. Тьюринг А. Может ли машина мыслить. М.: ГИФМЛ, 1960.-112с.
109. Виноград Т. Программа, понимающая естественный язык. М.: Мир, 1976.
– 294с.
110. Фейгенбаум Э., Фельдман Дж. Вычислительные машины и мышление.
М.: Мир, 1967. -552с.
111. Джексон П. Введение в экспертные системы. М., СПб., Киев: Изд. дом
«Вильямс», 2001.-624с.
112. Частиков А.П., Гаврилова Т.А., Белов Д.Л. Разработка экспертных
систем. Среда CLIPS. СПб.: БХВ-Петербург, 2003.-608с.
113. Джарратано Дж., Райли Г. Экспертные системы. Принципы разработки и
программирование. М.: ООО «И.Д. Вильямс», 2007. -1152с.
114. Баарс Б., Гейдж Н. Мозг, познание, разум: введение в когнитивные
нейронауки: (в 2-х т.). М.: БИНОМ. Лаборатория знаний, 2014. т.1-544с.,
т.2-464с.
115. Сегаран Т. Программируем коллективный разум. СПб: Символ-Плюс,
2008. -368с.
116. Люгер Дж. Искусственный интеллект. Стратегии и методы решения сложных
проблем. М.: Изд. дом «Вильямс», 2003. -864с.
117. Острейковский В.А.. Теория систем. М.: Высш. школа, 1997. – 240с.
118. Ван Гиг Дж. Прикладная общая теория систем (в 2-х кн.). М.: Мир, 1981. –
- Кн. 1-336с; Кн. 2-733с.
119. Аракелян Э.К., Крохин Г.Д., Mухин В.С.. Концепция мягкого регулирования
технического обслуживания энергоустановок ТЭС на основе интеллектуальной
диагностики. // Вестник МЭИ, № 1. – М.:
Изд-во МЭИ, 2008. - с.14-20.
120. Крохин Г.Д., СупруненкоМ.Я.. Диагностика состояния энергоустановок ТЭС
(постановка экспериментов). // Труды третьей международной научно-технической конференции «Актуальные проблемы электронного приборостроения» АПЭП –96, в 11-ти томах. - Новосибирск, НГТУ, 1996. Т.5. - с.105-111.
121. Волегова А.А., БарабановА.А.. Феномен архитектуры нового тысячелетия. //Вестник ТГАСУ. Томск: Изд-во ТГАСУ, №3, 2008.
– с. 34-46.
122.Krokhin G., Manusov V., Glaser M. Fuzzy Models for Intellectual Industrial Regulatorin Control Systems of Thermal Power Station. // 7th European Congress on Intelligent Techniques and Soft Computing, EUFIT’99. - Aachen, Germany, 1999. Final Program. Abstracts of the Papers and Proceedings on CD-ROM. - P.204, of 6 p.
123. Зайченко Ю.П. Исследование операций. Нечеткая оптимизация.
Киев: Выща школа, 1991. -191с.
124. Горнева О.С., Титов С.С. Математические аналогии в учебном
архитектурном проектировании. //Вестник ТГАСУ. Томск: Изд-во
ТГАСУ, №1, 2009. – с. 17-23.
125. Сазонов В.И. Становление графоаналитической теории архитектурной
гармонии. Новосибирск, НГАХА, 2002. – 216с.
126. АРХИТЕКТУРА. Краткий справочник /Гл. ред. М.В.Адамчик. – М.: АСТ: Мн.:
Харвест, 2007. -624с.
127. Клир Дж. Системология. Автоматизация решения системных задач. М.: Радио
и связь, 1990. -544с.
128. Материалы сайта: www.intuit.ru
Литература
1.Беллман Р., Заде Л. Принятие решений в расплывчатых условиях. // Вопросы анализа и процедуры принятия решений. М.: Мир, 1976. - с. 172-215.
2. Гилл Ф., Мюррей У., Райт М.. Практическая оптимизация. М.: Мир, 1985. – 509с.
3.Зайченко Ю.П. Исследование операций: нечеткая оптимизация. К.: Выща шк., 1991. -191с.
4.Крохин Г.Д., Супруненко М.Я., Манусов В.З. Распознавание образов при диагнозе состояния энергоустановок электростанций. / Труды 3-й Международной научно-технической конференции “АПЭП - 96”, Новосибирск, НГТУ, 1996.
5.Крохин Г.Д., Мухин В.С., Судник Ю.А. Интеллектуальные технологии в теплоэнергетике. Ч. 1. М.: ООО «УМЦ «Триада»,2010.-170с.
6.Максимей И.В. Имитационное моделирование на ЭВМ. М.: Радио и связь, 1988. – 232с.
7.Растригин Л.А.. Статистические методы поиска. М.: Наука ФМЛ, 1968. – 376с.
8.Растригин Л.А. Системы экстремального управления. М.: Наука ФМЛ, 1974. – 632с.
9.Супруненко М.Я. Эвристический подход при разработке алгоритмов распознавания образов и оптимизации. Новосибирск: Сова, 2004. -72с.
10.Таха Х. Введение в исследование операций (в 2-х кн.). М. : Мир, 1985. Кн. 1- 479с., Кн. 2 - 496с.
11.Штойер Р. Многокритериальная оптимизация. Теория, вычисления и приложения. М.: Радио и связь, 1992. – 504с.