

Множественный коэффициент корреляции
Множественный коэффициент показывает тесноту связи между результирующей переменной и многомерным массивом из остальных переменных.
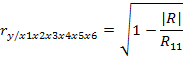
Где |R| - определитель матрицы частных коэффициентов корреляции, R11 – алгебраическое дополнение элемента r11 корреляционной матрицы.
![]()
Проверим ![]()

![]()
Множественный коэффициент корреляции значим и равен 0,428. Это означает, что расходы на алкоголь сильно зависят от всех выбранных для этого анализа шести переменных, которые с разных сторон характеризуют уровень жизни населения в регионе.
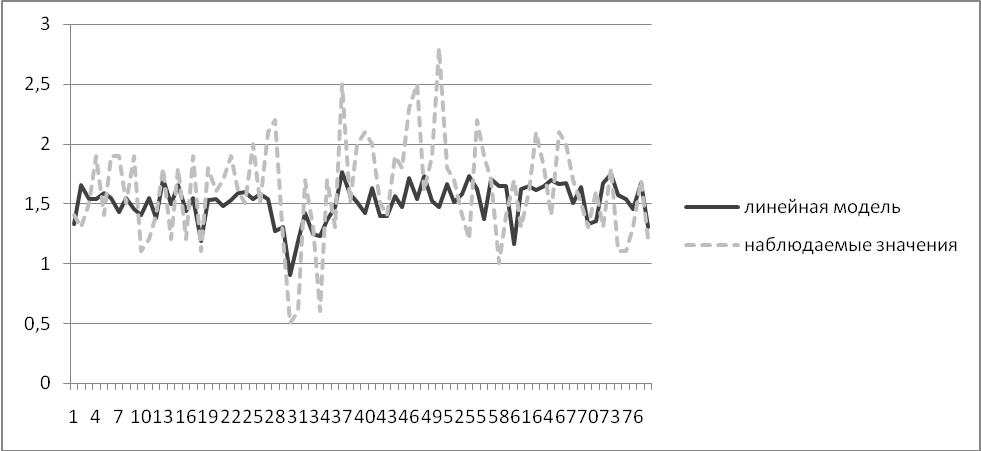
Регрессионный анализ Линейная модель
Метод пошагового исключения переменных заключается в том, что сначала мы рассчитываем уравнение регрессии, используя все переменные, затем исключаем одну самую незначимую, пересчитываем уравнение заново, и опять исключаем самую незначимую переменную. Так происходит до тех пор, пока все переменные оказываются значимыми с определенной вероятностью ошибки. В регрессионном анализе было принято решение взять уровень значимости α=0,1.
Сначала было получено первое уравнение регрессии:
![]()
Из этого уравнения нужно исключить переменную X1, так как у неё самый низкий по модулю уровень t-статистики.
В ходе дальнейшего пошагового исключения переменных было получено уравнение регрессии, в котором при уровне значимости 10% осталось три переменных: X2, X4, X5.
![]()
![]()
Модель:
![]()
Коэффициент детерминации R2= 0,164 < 0,5, значит, доля дисперсии результирующей переменной, которую можно объяснить вариацией факторных признаков меньше, чем доля остальных, не учтённых в модели факторов. Следовательно, эта регрессионная модель имеет невысокое практическое значение.
Среднеквадратическая ошибка S=0,3917
Коэффициенты эластичности:
![]()
При увеличении реальной заработной платы на 1%, доля расходов на алкоголь в среднем уменьшится на 0,15%.
![]()
При увеличении соотношения разводов и браков на 1%, доля расходов на алкоголь в среднем увеличится на 0,37%.
![]()
При повышении уровня преступности на 1%, люди в среднем будут тратить на алкоголь на 0,25% больше.
Верификация модели:
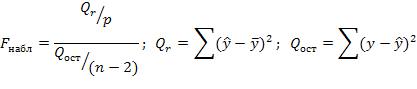
![]()
Fнабл >Fкр, следовательно, гипотеза о незначимости отвергается и уравнение регрессии считаем значимым, модель верифицирована.
Относительная ошибка прогноза:
![]()
Вывод:
Данная модель показывает зависимость средней по России доли расходов на алкоголь среди расходов на конечное потребление от реальной зарплаты, соотношения браков и разводов и уровня преступности в регионе. Но, поскольку коэффициент детерминации меньше 0,5, то можно сказать, что на потребление алкоголя влияют признаки, не учтённые в этой модели.
Нелинейная (степенная) модель
Методом пошагового исключения переменных было получено уравнение регрессии
![]() ,
где
,
где ![]()
![]()
![]()
![]()
![]()
![]()
Проэкспонируем обе части этого уравнения, чтобы получить нелинейную (степенную) модель.
![]()
Коэффициент детерминации R2= 0,267< 0,5, значит, на вариацию результирующего признака дисперсия неучтённых в модели факторов влияет сильнее.
Среднеквадратическая ошибка S=0,25921
Коэффициенты эластичности:
![]()
![]()
При увеличении отношения разводов к бракам на 1%, люди в среднем будут тратить на алкоголь на 0,401% больше, а при повышении уровня преступности на 1%, люди в среднем будут тратить на алкоголь на 0,286% больше.
Верификация модели:
![]()
Fнабл >Fкр, следовательно, гипотеза о незначимости отвергается и уравнение регрессии считаем значимым, модель верифицирована.
Относительная ошибка прогноза:
![]()
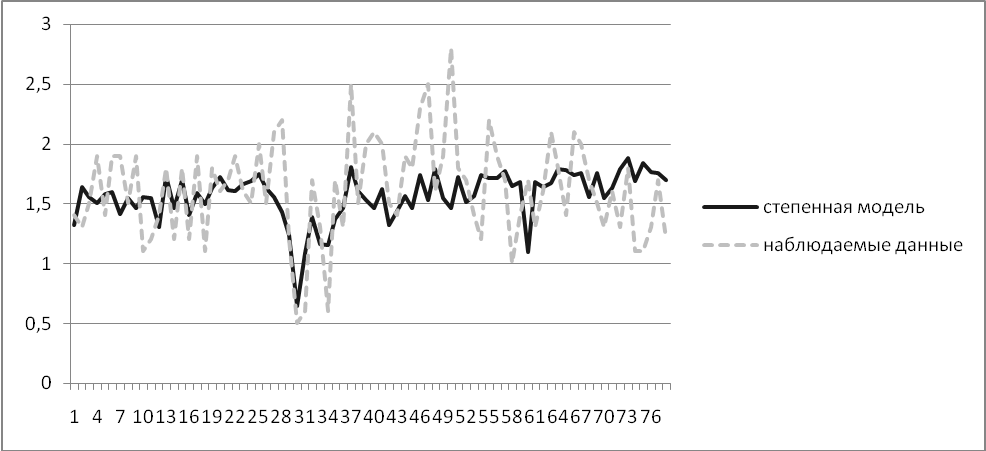
Сравним линейную и степенную модель:
Модель |
Линейная |
Степенная |
Число переменных |
3 |
2 |
Коэффициент детерминации |
0,164 |
0,267 |
Скорректированный коэффициент детерминации (для сравнения моделей с разным количеством переменных) |
0,130 |
0,247 |
Среднеквадратическая ошибка |
0,3917 |
0,25921 |
Относительная ошибка прогноза |
9,5% |
4,2% |
Степенная модель проще (в ней меньше переменных), у неё больше коэффициент детерминации и меньше среднеквадратическая ошибка, а это значит, что она сильнее соответствует реальным данным. Также у неё выше прогнозные качества, так как ошибка прогноза более чем в два раза меньше, чем в линейной модели.
Следовательно, можно сделать вывод, что степенная модель является оптимальной.