

Дискриминантный анализ
На основе кластеров, выделенных по переменным
Целью дискриминантного анализа является описание различий между кластерами и проверка качества кластерного анализа.
Собственные значения |
||||
Функция |
Собственное значение |
% объясненной дисперсии |
Кумулятивный % |
Каноническая корреляция |
1 |
2,248a |
73,0 |
73,0 |
,832 |
2 |
,832a |
27,0 |
100,0 |
,674 |
Лямбда Уилкса |
||||
Проверка функции(й) |
Лямбда Уилкса |
Хи-квадрат |
ст.св. |
Знч. |
от 1 до 2 |
,168 |
129,289 |
12 |
,000 |
2 |
,546 |
43,878 |
5 |
,000 |
Собственное значение у первой функции велико, лямбда Уилкса – мала, что означает сильные различия между первым и вторым кластером. А собственное значение второй дискриминантной функции довольно мало, при соответственно большой лямбде Уилкса, т.е. эта функция хуже, чем первая, проводит различия между кластерами.
Такой вывод подтверждает рисунок распределения объектов на кластеры.
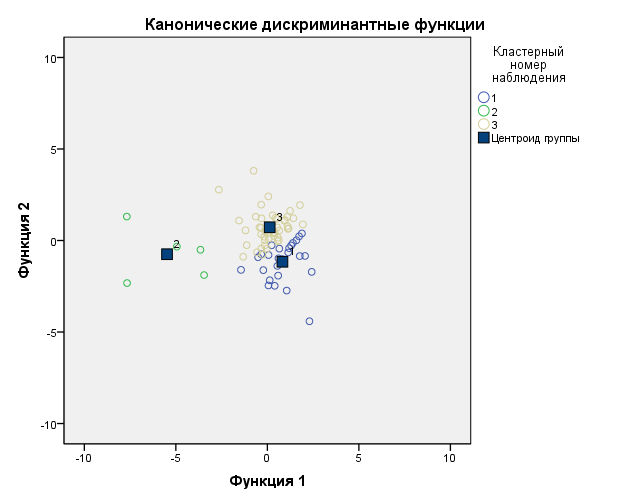
Видно, что второй кластер сильно отличается от первого и третьего, а первый и третий между собой похожи, их центроиды находятся очень близко, и между ними сложно провести очевидную грань.
Результаты классификацииa |
||||||
|
|
Кластерный номер наблюдения |
Предсказанная принадлежность к группе |
Итого |
||
|
|
1 |
2 |
3 |
||
Исходные |
Частота |
1 |
24 |
0 |
2 |
26 |
2 |
0 |
5 |
0 |
5 |
||
3 |
4 |
0 |
43 |
47 |
||
% |
1 |
92,3 |
,0 |
7,7 |
100,0 |
|
2 |
,0 |
100,0 |
,0 |
100,0 |
||
3 |
8,5 |
,0 |
91,5 |
100,0 |
||
a. 92,3% исходных сгруппированных наблюдений классифицировано правильно.
|
||||||
Результаты классификации показали, что объекты второго кластера определялись безошибочно, а первого и третьего – нет: 2 объекта первого кластера были приписаны к третьему и 4 объекта третьего – к первому.
Теперь проведем дискриминантный анализ пошаговым алгоритмом.
Собственные значения |
|
||||||||
Функция |
Собственное значение |
% объясненной дисперсии |
Кумулятивный % |
Каноническая корреляция |
|||||
1 |
2,248a |
75,2 |
75,2 |
,832 |
|||||
2 |
,739a |
24,8 |
100,0 |
,652 |
|||||
a. В анализе использовались первые 2 канонические дискриминантные функции. |
|
||||||||
Лямбда Уилкса |
|||||||||
Проверка функции(й) |
Лямбда Уилкса |
Хи-квадрат |
ст.св. |
Знч. |
|||||
от 1 до 2 |
,177 |
126,398 |
10 |
,000 |
|||||
2 |
,575 |
40,409 |
4 |
,000 |
|||||
Канонические дискриминантные функции получились примерно такими же, как и в методе включения всех переменных, но в данном случае при построении дискриминантной функции были использованы не все переменные, а только 5 из 6.
Введенные/исключенные переменныеa,b,c,d |
||||||||
Шаг |
Введенные |
Исключенные |
Мин. D квадрат |
|||||
Статистика |
Между группами |
Точное значение F |
||||||
Статистика |
ст.св1 |
ст.св2 |
Знч. |
|||||
1 |
x3_st |
|
1,879 |
1 и 3 |
31,448 |
1 |
75,000 |
3,253E-7 |
2 |
x1_st |
|
2,545 |
1 и 3 |
21,019 |
2 |
74,000 |
5,907E-8 |
3 |
x2_st |
|
3,276 |
1 и 3 |
17,792 |
3 |
73,000 |
9,103E-9 |
4 |
x5_st |
|
3,507 |
1 и 3 |
14,088 |
4 |
72,000 |
1,539E-8 |
5 |
x6_st |
|
4,031 |
1 и 3 |
12,775 |
5 |
71,000 |
7,316E-9 |
6 |
x4_st |
|
4,031 |
1 и 3 |
10,497 |
6 |
70,000 |
2,796E-8 |
7 |
|
x6_st |
3,624 |
1 и 3 |
11,487 |
5 |
71,000 |
3,831E-8 |
Из анализа была исключена переменная x6 - Общая площадь жилых помещений, приходящаяся в среднем на одного жителя. Закономерность такого исключения подтверждается тем, что эта же переменная при регрессионном пошаговом анализе была исключена первой. Получается, что общая площадь жилых помещений не влияет на классификацию.
Результаты классификацииa |
||||||
|
|
Кластерный номер наблюдения |
Предсказанная принадлежность к группе |
Итого |
||
|
|
1 |
2 |
3 |
||
Исходные |
Частота |
1 |
22 |
0 |
4 |
26 |
2 |
0 |
5 |
0 |
5 |
||
3 |
4 |
0 |
43 |
47 |
||
% |
1 |
84,6 |
,0 |
15,4 |
100,0 |
|
2 |
,0 |
100,0 |
,0 |
100,0 |
||
3 |
8,5 |
,0 |
91,5 |
100,0 |
||
a. 89,7% исходных сгруппированных наблюдений классифицировано правильно.
|
||||||
Неправильно классифицированные объекты опять были только между 1 и 3 кластером, но их больше, чем в принудительном включении.
Значит, метод принудительного включения показал более качественную классификацию – 92,3% против 89,7%.
Проведем дискриминантный анализ на основе кластеров, выделенных по главным компонентам.
Собственные значения |
|
||||||||
Функция |
Собственное значение |
% объясненной дисперсии |
Кумулятивный % |
Каноническая корреляция |
|||||
1 |
2,018a |
77,2 |
77,2 |
,818 |
|||||
2 |
,595a |
22,8 |
100,0 |
,611 |
|||||
a. В анализе использовались первые 2 канонические дискриминантные функции. |
|
||||||||
Лямбда Уилкса |
|||||||||
Проверка функции(й) |
Лямбда Уилкса |
Хи-квадрат |
ст.св. |
Знч. |
|||||
от 1 до 2 |
,208 |
117,095 |
4 |
,000 |
|||||
2 |
,627 |
34,796 |
1 |
,000 |
|||||
Собственные значения и лямбды Уилкса первой и второй дискриминантных функций отличаются ещё сильнее, чем в предыдущем дискриминантном анализе.
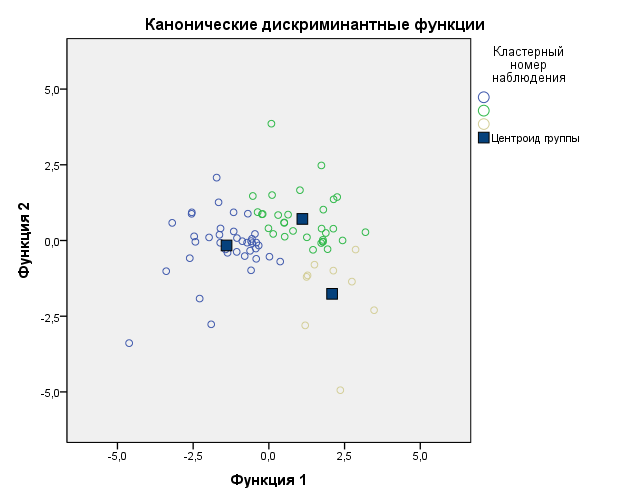
Но, если судить визуально по рисунку распределения объектов на кластеры, то видно, что центроиды находятся довольно далеко друг от друга и сами кластеры не так близко.
Результаты классификацииa |
||||||
|
|
Кластерный номер наблюдения |
Предсказанная принадлежность к группе |
Итого |
||
|
|
1 |
2 |
3 |
||
Исходные |
Частота |
1 |
37 |
1 |
0 |
38 |
2 |
0 |
31 |
0 |
31 |
||
3 |
0 |
0 |
9 |
9 |
||
% |
1 |
97,4 |
2,6 |
,0 |
100,0 |
|
2 |
,0 |
100,0 |
,0 |
100,0 |
||
3 |
,0 |
,0 |
100,0 |
100,0 |
||
a. 98,7% исходных сгруппированных наблюдений классифицировано правильно. |
||||||
Результаты классификации показали, что только один объект был классифицирован неправильно, в итоге 98,7% исходных сгруппированных наблюдений классифицированы правильно.
Дискриминация методом пошагового отбора не отличается ничем, т.к. пакет не исключил ни одной переменной.
Выводы
Доля расходов на алкогольные напитки среди населения сильно и положительно связана с уровнем преступности в регионе. Можно предположить, что это в том числе из-за того, что многие преступления совершаются в состоянии алкогольного опьянения.
Также доля расходов на алкогольные напитки положительно связана с соотношением разводов и браков. Это может быть связано с тем, что алкоголизм одного из супругов является как возможной причиной большой доли разводов, так и последствием.
Остальные факторы, характеризующие уровень жизни населения (в том числе реальная заработная плата, доля людей в регионе с доходами ниже прожиточного минимума, уровень безработицы и общая площадь жилых помещений, приходящаяся на одного человека), значимой связи с долей расходов на алкоголь не показали.
Факторный анализ показал, что все переменные можно разделить на две компоненты, одна из которых характеризует социально-экономическое положение населения, вторая – уровень преступности.
Кластерный и дискриминантный анализ показали, что субъекты России можно разбить двумя способами на три группы: «благополучные, неблагополучные и бедственные» и «спокойные, развитые и неблагополучные». В первом варианте разбиения благополучные и неблагополучные регионы потребляют примерно одинаковое количество алкоголя, а бедственные – почти в 2 раза меньше. Во втором варианте все три группы характеризуются почти одинаковым уровнем потребления алкоголя, но развитые регионы потребляют его почти на 5% больше.