

Компонентный анализ
Далее проведем компонентный анализ, целью которого является выявление скрытых закономерностей и снижение признакового пространства. Проанализировав матрицу частных и парных коэффициентов корреляции, можно предположить, что будет выделено 2 главные компоненты, одна из которых характеризует уровень жизни, а другая – уровень преступности и соотношение браков и разводов.
Проверим гипотезу критерием Кайзера.
Компонента |
Начальные собственные значения |
||
Итого |
% Дисперсии |
Кумулятивный % |
|
1 |
2,582 |
43,029 |
43,029 |
2 |
1,455 |
24,246 |
67,275 |
3 |
,891 |
14,854 |
82,129 |
4 |
,560 |
9,334 |
91,463 |
5 |
,276 |
4,608 |
96,071 |
6 |
,236 |
3,929 |
100,000 |
Как видно из таблицы, только у двух компонент собственные значения превышают 1, то есть только две компоненты объясняют дисперсию более, чем одной переменной. Кумулятивный процент объясненной дисперсии равен 67,275%, что является достаточным уровнем.
Применим критерий «каменистой осыпи». Для этого рассмотрим график нормализованного простого стресса. Нужно найти такое место на графике, где убывание собственных значений слева направо максимально замедляется. Справа от этой точки находится «факториальная осыпь».
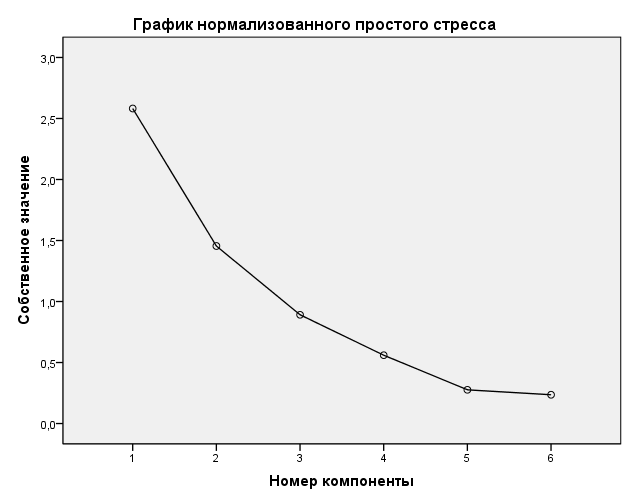
Итак, следуя двум критериям, были выделены две главные компоненты.
Рассмотрим матрицу компонент, которая поможет определить, из каких изначальные переменных состоят компоненты.
Матрица компонент |
||
|
Компонента |
|
1 |
2 |
|
x1 |
-,615 |
,355 |
x2 |
,531 |
,517 |
x3 |
-,890 |
,156 |
x4 |
,716 |
,418 |
x5 |
-,010 |
,891 |
x6 |
,786 |
-,263 |
Переменные распределились следующим образом: во вторую компоненту вошла только одна переменная – число зарегистрированных преступлений на 100 человек населения, а в первую – все остальные переменные, которые характеризуют социально-экономическое положение населения в регионе (численность населения с доходами ниже прожиточного минимума, реальная начисленная заработная плата, уровень безработицы, соотношение браков и разводов и общая площадь жилых помещений, приходящаяся в среднем на одного человека).
В результате факторного анализа признаковое пространство было сокращено с 6 до 2 признаков: уровня преступности и социально-экономического положения населения.
Далее построим диаграмму рассеивания.
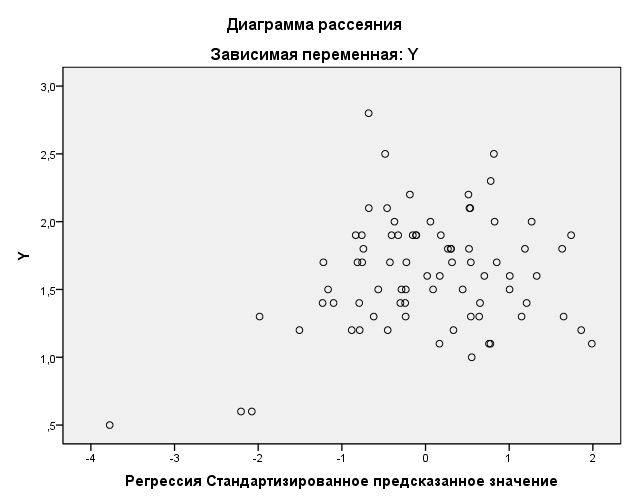
Форма облака не очень напоминает эллипс, скорее это круг, имеются несколько элементов, похожих на аномальные. Это означает, что этим способом предположение о нормальности распределения исходных данных подтвердить нельзя (рекомендуется проверять гипотезы статистическим аппаратом, а не просто визуально).
Построим уравнение регрессии на главных компонентах:
![]()
Как видно, у первой главной компоненты Z1 очень маленькая значимость, следовательно, её необходимо исключить из уравнения.
![]()
Итоговое уравнение показывает, что доля расходов на потребление алкоголя положительно зависит от уровня преступности в регионе. Сравним это уравнение с уравнениями регрессии, полученными пошаговым способом в линейной и нелинейной моделях. Во всех уравнениях переменная «уровень преступности» присутствует, что в очередной раз свидетельствует о её значимости. Но в первых двух моделях кроме этой переменной есть ещё и другие: соотношение браков и разводов и реальная начисленная заработная плата. Регрессия на главных компонентах показала, что эти переменные, взятые вместе со всеми остальными характеристиками социально-экономического положения, не влияют на потребление алкоголя в России.