

Assembly Language Step by Step 1992
.pdfaccess memory banks.
A disk (floppy or hard) is a circular platform coated with magnetic plastic of some sort. In a floppy disk drive, the platform is a flexible disk of tough plastic; in a hard disk the platform is a rigid platter of aluminum metal. Data is stored as little magnetic disturbances on the plastic coating in a fashion similar to that used in audio cassettes and VCRs. A sensor called a read/write head sits very close beside the rotating platform, and waits for the data to pass by.
A simplified illustration of a rotating disk device is shown in Figure 3.1. The area of the disk is divided into concentric circles called tracks. The tracks are further divided radially into sectors. A sector (typically containing 512 bytes) is the smallest unit of storage that can be read from or written to at one time. A DOS disk file consists of one or more sectors containing the file's data.
The read/write head is mounted on a sliding shaft that is controlled by a solenoid mechanism. The solenoid can move the head horizontally to position the head over a specific track. (In Figure 3.1, the head is positioned over track 2—counting from 0, remember!) However, once the head is over a particular track, it has to count sectors until the sector it needs passes beneath it. The tracks can be accessed at random, just like bytes in the computer's memory banks, but the sectors within a track must be accessed sequentially.
Perhaps the single most valuable service DOS provides is handling the headaches of distributing data onto empty sectors on a disk. Programs can hand sectors of data to DOS,

one at a time, and let DOS worry about where on the disk they can be placed. Each sector has a number, and DOS keeps track of what sectors belong together as a file. The first sector in a file might be stored on track 3, sector 9; the second sector might be stored on track 0, sector 4, and so on. You don't have to worry about that. When you ask for sector 0 of your file, DOS looks up its location in its private tables, goes directly to track 3, sector 9 and brings the sector's data back to you.
Binary Files
The data that is stored in a file is just binary bytes and can be anything at all. Files like this, where there are no restrictions on the contents of a file, are called binary files, because they can legally contain any binary code. Like all files, a binary file consists of some whole number of sectors, with each sector (typically) containing 512 bytes. The least space any file can occupy on your disk is 512 bytes; when you see the DOS DIR command tell you that a file has 17 bytes it in, that's the count of how many bytes are stored in that file. But like a walk-in closet with only one pair of shoes in it, the rest of the sector is still there, empty but occupying space on the disk.
A binary file has no structure, but is simply a long series of binary codes divided into numbered groups of 512 and stored out on disk in a scheme that is best left to DOS to understand.
Text Files
If you've ever tried to use the TYPE command to display a binary file (like an .EXE or
.COM file) to the screen, you've seen some odd things indeed. There's no reason for such files to be intelligible on the screen; they're intended for other "eyes," typically the CPU's.
There is a separate class of files that is specifically restricted to containing humanreadable information. These files are called text files because they con-tain the letters, digits, and symbols of which printed human information (text) is composed.
Unlike binary files, text files have a certain structure to them. The characters in text files are divided into lines. A line in a text file is defined not so much by what it contains as by how it ends. Two invisible characters called an end-of-line (or EOL) marker (or EOL) tag the end of a line. The EOL marker is not one character but two: the carriage return character (called CR by those who know and love it) followed by the linefeed character (similarly called LF). You don't see these characters on the screen as separate symbols, but you see what they do: they end the line. Anywhere a line ends in an ordinary DOS text file, you'll find a mostly invisible partnership of one CR character and one LF character hanging out. The first line in a text file runs from the first byte in the file to the first EOL marker; the second line starts immediately after the first EOL marker and runs to the second EOL marker, and so on. The text characters falling between two sequential EOL markers is considered a single line.
Why two characters to end a line? Long ago, there was (and still is at hamfests, lordy) an incredible mechanical nightmare called a teletype machine. These were invented during World War II as robot typewriters that could send written messages over long distances through electrical signals that could pass over wires. Returning the typing carriage to the left margin of the paper (carriage return) and feeding the paper up one line to expose the next clean line of paper to the typing carriage (line feed) are separate mechanical opera-tions. A separate electrical signal was required to do each of these operations. Although I don't know why separate signals were necessary, it has carried over into the solid-state autumn of the 20th century in the form of those two characters, CR and LF. Not only is this a case of the tail wagging the dog; it is a case of the tail walking around twenty years after the poor dog rolled over and died.
Figure 3.2 shows how CR and LF divide what might otherwise be a single meaningless string of characters into a structured sequence of lines. It's important to understand the structure of a text file because that structure dictates how some important software tools operate, as I'll explain a little later.
The CR character is actually character 13 in the ASCII character set summa-rized in Appendix A. The LF character is character 10. They are two of a set of several invisible characters called whitespace, indicating their role in positioning text characters within the white space of a text page. The other whitespace characters include the space character (character 32) the tab character (character 9) and the form feed character (character 12), which can further divide a text file into pages.
Another character, the bell character (BEL) falls in between binary and text characters. When either displayed or printed, it signals that a tone should be sounded. Back in the old teletype days, the BEL character caused the teletype machine to ring its bell. BEL characters are allowed in text files, but are generally considered sloppy practice.
One more invisible character plays an important role in the structure of a text file: The end-of-file (EOF) marker character. Unlike EOL, EOF is a single character, ASCII character 26, sometimes written as Ctrl+Z because you generate the EOF character by holding down the Ctrl key then pressing the Z key.
By convention, the EOF marker is considered the last significant character in a text file, and DOS will ignore any characters following it, even if the file goes on for thousands of additional bytes. Those additional bytes will be ignored by the assembler and by most text editors.
An EOF marker can be mistakenly placed in the middle of a text file by some utilities. The most frequent source of false EOF markers comes from saving a text file to disk in a word processor program's "native" mode, which may write EOF characters and many other unprintable characters into a text file. Such native mode document files are not actually text files, but are binary files intended to be read only by that particular word processor.

.
Text Editors
Manipulating a text file is done with a program called a text editor. A text editor is a word processor for program source code files. In its simplest form, a text editor works like this: you type characters at the keyboard and they appear on the screen. When you press the Enter key, an EOL marker is placed at the end of a line, and the cursor moves down to the next line.
A text editor also allows you to move the cursor into existing text to change, or edit, it. You can delete words and whole lines and, if necessary, replace them with new text. Ultimately, when you are finished, you press a key like F2 or a key combination like Ctrl+KD, and the text editor saves the text you entered from the keyboard as a text file. This text file is the source code file you'll later present to the assembler for processing. Later on, you can load that same text file back into the editor to make repairs on faulty
lines that cause errors during assembly or bugs during execution.
A great many people still use their word processors as program text editors. WordStar, WordPerfect, and most of the others make acceptable text editors, as long as you remember to write your text file to disk in "non-document mode" or "ASCII text mode". Most true word processors embed countless strange little codes in their text files, to control things like margin settings, font selections, headers and footers, and soft page and line breaks. These codes are not recognized ASCII characters but binary values, and actually change the document file from a text file to a binary file. The codes will give the assembler fits. If you write a program source code file to disk as a document file, it will not assemble. See the word processor documentation for details on how to export a document file as a pure ASCII text file.
There are numerous text editor products on the market specifically for use by assemblylanguage programmers. Two of the best are called Brief and Epsilon. A very good editor, Point, is often sold as an accessory with the Logitech Mouse. The Sidekick notepad editor makes a perfectly reasonable text editor for assembly-language work, as do the editors built into Microsoft's Quick language compilers and Borland's Turbo language compilers.
If you have no other editor, I have put one together and given it to various user groups around the country. If you can't find my JED editor anywhere, you can order it directly from me through the address on the flyleaf. JED works very much like the editor in the Turbo language products, because I produced it with the Turbo Pascal Editor Toolbox and Turbo Pascal 5.0.
Because there are so many different text editors in use among program-mers, I'll be using JED as the example editor in this book. When you see a command line incorporating the name JED, keep in mind that you will have to substitute the name and command suite for whatever editor you may be using if you're not using JED.
Chapter 4 describes JED in detail. JED has the advantage (over editors like Brief and Epsilon) of being simple. I designed it for beginning assembly-language programmers, and if you've ever used any of the Turbo language products, JED will feel just like home.
3.3 Compilers and Assemblers
With that understanding of DOS files under your belt, you can come to under-stand the nature of two important kinds of programs: compilers and assemblers. Both fall into a category of programs we call translators.
A translator is a program that accepts human-readable source code files and generates
some kind of binary file. The binary file could be an executable program file that the CPU can understand, or it could be a font file, or a Compressed binary data file, or any of a hundred other types of binary file.
Program translators are translators that generate machine instructions that the CPU can understand. A program translator reads a source code file line by line, and writes a binary file of machine instructions to accomplish the actions that the source code file describes. This binary file is called an object code file.
A compiler is a program translator that reads in source code files written in higher-level languages like C and Pascal and outputs object code files.
An assembler is a special type of compiler. It, too, is a program translator that reads source code files and outputs object code files for the CPU. However, an assembler is a translator designed specifically to translate what we call assembly language into object code. In the same sense that a language compiler for Pascal or C compiles a source code file to an object code file, we say that an assembler assembles an assembly language source code file to an object code file. The process, one of translation, is similar in both cases. An assembler, however, has an overwhelmingly important characteristic that sets it apart from other compilers: total control over the object code.
Assembly Language
Some people define assembly language as a language in which one line of source code generates one machine instruction. This has never been literally true, since some lines in an assembly-language source code file are instructions to the translator program and do not generate machine instructions. My own definition follows:
Assembly language is a language that allows total control over every individual machine instruction generated by the translator program.
Pascal or C compilers, on the other hand, make a multitude of invisible and inalterable decisions about how a given language statement will be translated into machine instructions. For example, the following single Pascal instruction assigns a value of 42 to a numeric variable called I:
I : = 42:
When a Pascal compiler reads this line, it outputs a series of four or five machine instructions that take the value 42 and store it in memory at a location encoded by the name I. Normally, you the programmer have no idea what these four or five instructions actually are, and you have utterly no way of changing them, even if you know a sequence of machine instructions that is faster and more efficient than the sequence the compiler
uses. The Pascal compiler has its own way of generating machine instructions, and you have no choice but to accept what it writes to disk to accomplish the Pascal statements in the source code file.
An assembler, however, has at least one line in the source code file for every machine instruction it generates. It has more lines than that to handle numerous other things, but every machine instruction in the final object code file is controlled by a corresponding line in the source code file.
Each of the CPU's many machine instructions has a corresponding mnemonic in assembly language. As the word suggests, these mnemonics began as devices to help programmers remember a particular machine instruction. For example, the mnemonic for machine instruction 9CH, which pushes the flags register onto the stack, is PUSHF—which is a country mile easier to remember than 9CH.
When you write your source code file in assembly language, you will arrange series of mnemonics, typically one mnemonic to a source code file text line. A portion of a source code file might look like this:
MOV |
AH.12H |
: |
12H is Motor Information Service |
|
MOV |
AL.03H |
: |
03H is Return Current Speed function |
|
XOR |
BH.BH |
; |
Zero BH for |
safety's sake |
INT |
71H |
; |
Call Motor |
Services Interrupt |
Here, the words MOV, XOR, and INT are the mnemonics. The numbers and other items to the immediate right of each mnemonic are that mnemonics's operands. There are various kinds of operands for various machine instructions, and some instructions (like PUSHF mentioned above) have no operands at all. We'll thoroughly describe each instruction's operands when we cover that specific instruction.
Taken together, a mnemonic and its operands are called an instruction. This is the word we'll be using most of the time in this book to indicate the human-readable proxy of one of the CPU's pure binary machine code instruc-tions. To talk about the binary code specifically, we'll always refer to a machine instruction.
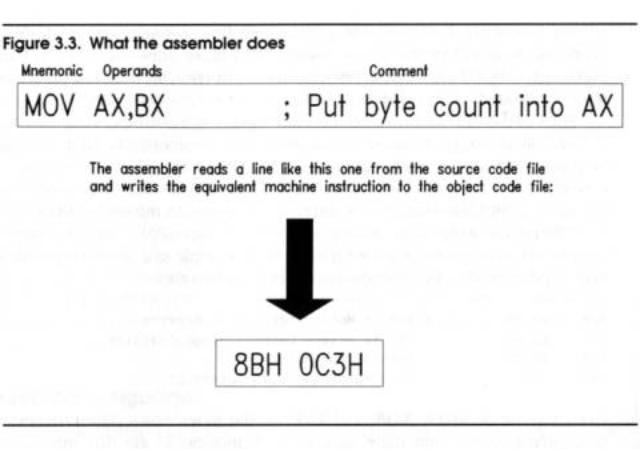
The assembler's most important job is to read lines from the source code file and write machine instructions to an object code file. See Figure 3.3.
Comments
To the right of each instruction is some information starting with a semicolon. This information is called a comment, and its purpose should be plain: to cast
some light on what the associated assembly language instruction is for. The instruction
MOV AH,12H places the value 12H in register AH—but why? The comment provides the why.
Far more than in any other programming language, comments are critical to success of your assembly language programs. My own recommendation is every instruction in your source code files have a comment to its right.
Structurally, a comment starts with the first semicolon on a line, and continues to the EOL marker at the end of that line. This is one instance where understanding how a text file
is structured is very important—because in assembly language, comments end at the ends of lines. In most other lan-guages, comments are placed between pairs of comment delimeters like (* and *), and EOL markers at line ends are ignored.
.
Comments begin at semicolons, and end at an EOL marker
Beware "Write-Only" Source Code!
This is as good a time as any to point out a serious problem with assembly language. The instructions themselves are almost vanishingly brief, and while each instructions states what it does, there is nothing to indicate the context in which that instruction operates.
With some skill and discipline, you can build that context into your Pascal or BASIC code but in assembly language you can add context only through comments.
Without context, assembly language starts to turn into what we call "write-only" code. It can happen like this: on November 1, in the heat of creation, you crank out about 300 instructions in a short utility program that does something important. You go back on January 1 to add a feature to the program and discover that you no longer remember how it works. The individual instructions are all correct, but knowledge of how it all came together and how it works from a height have vanished under Christmas memories and eight weeks of doing other things. In other words, you wrote it, but you can no longer read it, or change it. Voila! Write-only code.
Comment like crazy. Each individual line should have a comment, and every so often in a sizable source code file, take a few lines out and make entire lines into comments, explaining what the code is up to at this point in its execution.
While comments do take room in your source code disk files, they are not copied into your object code files, and a program with loads of comments runs exactly as fast as the same program with no comments at all.
You will be investing a considerable amount of time and energy into writing your assembly-language programs. It's more difficult than just about any other way of writing programs, and if you don't comment you may end up having to simply toss out hundreds of lines of inexplicable code and write it again, from scratch.
Work smart. Comment till you drop.
Object Code and Linkers
There's no reason at all why an assembler could not read a source-code file and write out a finished, executable program file as its object-code file. Most assemblers don't work this way, however. Object-code files produced by the major assemblers are a sort of intermediate step between source code and executable program. This intermediate step is a type of binary file called a relocatable object module, or (more simply) an .OBJ file, which is the file extension used by the assembler when it creates the file. For example, a source-code file called FOO.ASM would be assembled into an object file called FOO.OBJ. (The "relocatable" portion of the concept is crucial, but a little advanced for this chapter. More on it later.)
Because .OBJ files cannot be run as programs, an additional step, called linking, is necessary to turn these files into executable program files.
The reason for using .OBJ files as intermediate steps is that a single, large source-code