

Chapter 5
Figure 5-5
Using Ranges in Character Classes
Using character class ranges is much more succinct and less error-prone than specifying a large number of individual characters. For example, if you want to select all alphabetic characters used in English (both lowercase and uppercase) you could write the following character class:
[abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ]
However, you could express the same character class by using the character class:
[a-zA-Z]
or:
[A-Za-z]
114

Character Classes
each of which uses two character class ranges: a-z for lowercase ASCII characters and A-Z for uppercase ASCII characters. Depending on the data set and the problem definition, it may not be appropriate simply to write [A-z] because that does not restrict characters in the character class to ASCII alphabetic characters. Due to the ASCII ordering of characters, several nonalphabetic characters, such as square brackets, come after uppercase Z and before lowercase a.
Ranges in character classes allow you to customize a character set to your own needs. For example, if you want to select surnames beginning with A, B, C, D, and E, the character set [A-E] can be used to match the first character of a surname.
Alphabetic Ranges
Look at a simple use of ranges in character classes using the example document Light.txt, which is shown here:
fight light sight right night delight plight tight fights height lightning might quite rights weight bite quite
If you want to select the sequences of characters right, sight, and tight, you can use the following regular expression:
[rst]ight
This simply enumerates three literal characters in a character class.
However, you can take advantage of the fact that the initial character of each of the three sequences of characters you are interested in follow each other in the alphabet. So you can use a range in a character class, like this:
[r-t]ight
The pattern [r-t] is a character class; the r is a literal character in the character class, the hyphen is a metacharacter indicating a range, and the t is a literal character. Figure 5-6 shows that the pattern selects the character sequences right, sight, and tight.
115

Chapter 5
Figure 5-6
Use [A-z] With Care
If you want to select all English-language alphabetic characters you might be tempted to use the regular expression pattern:
[A-z]
expecting it to be equivalent to the character class:
[A-Za-z]
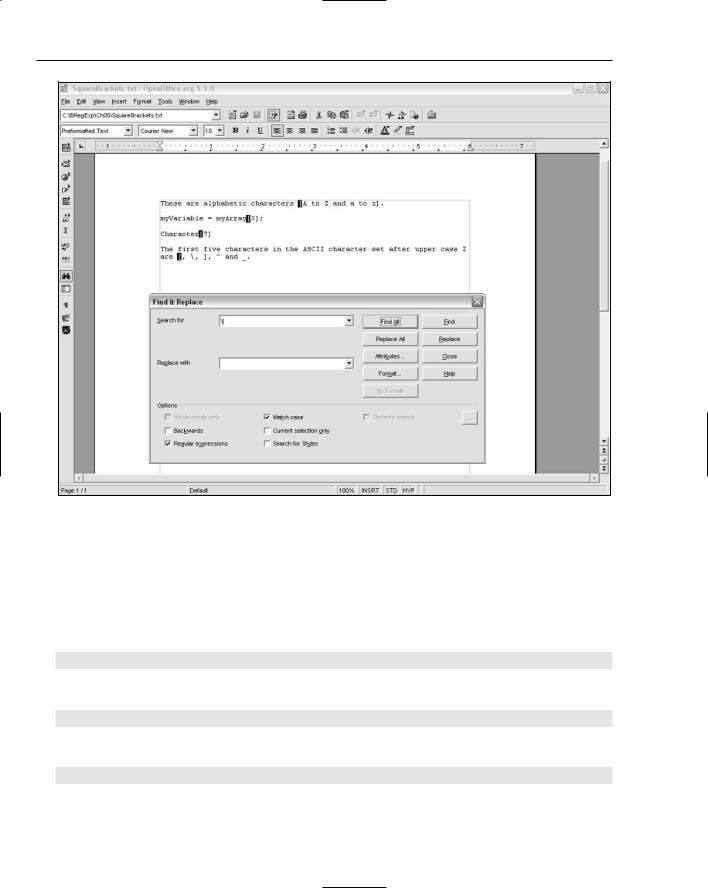
but that is not the case. The ASCII and Unicode characters sets don’t express the uppercase and lowercase alphabetic characters in one continuous sequence of characters, as you can see in Figure 5-7, which shows the Windows Character Map utility.
Six characters, each of which is not alphabetic, follow Z and precede lowercase a. They are [ (left square bracket), \ (backslash), ] (right square bracket), ^ (caret), _ (underscore), and the grave accent. In Figure 5-7 the cursor is on the ] character.
116

Character Classes
Figure 5-7
Digit Ranges in Character Classes
Numeric digits are widely used. One such use is in constructing part numbers. The file PartNums.txt shows some possible part numbers:
DB992
AX891
FG339
GE919
GE442
FG935
DB882
AX717
AX803
FG919
GE604
Notice that the part numbers consist of two alphabetic characters followed by three numeric digits. The alphabetic characters are of four sequences: AX, DB, FG, and GE. The data for the numeric digits suggests that all digits from 0 to 9 are used.
In implementations that support it, the \d metacharacter can be used to represent the class of numeric digits. An alternative is to use the character class [0-9] to represent a numeric digit.
Try It Out |
Matching Numeric Digits Using a Character Class |
If you assume that the first two characters are uppercase alphabetic characters, as described earlier, you can represent them using the first character using the character class [ADFG], and you can represent the
117

Chapter 5
second character using the character class [XBGE]. Similarly, each numeric digit can be matched using the character class [0-9].
The pattern, therefore, would be as follows:
[ADFG][XBGE][0-9]{3}
1.Open OpenOffice.org Writer, and open the test file, PartNums.txt.
2.Use Ctrl+F to open the Find & Replace dialog box.
3.Check the Regular Expressions and Match Case check boxes.
4.Type the pattern [ADFG][XBGE][0-9]{3} in the Search For text box, and click the Find All button.
5.Inspect the results, as shown in Figure 5-8 (all part numbers are highlighted).
Figure 5-8
118