


Chapter 8
Figure 8-13
How It Works
When the regular expression engine matches the character sequence SQL Server, it checks whether the preceding characters correspond to the pattern specified in the lookbehind.
The first occurrence of SQL Server is not preceded by the character sequence like followed by a space character. The negative lookbehind is, therefore, satisfied. Because the character sequence SQL Server matches and the negative lookbehind constraint is satisfied, the whole regular expression matches.
The only occurrence of the character sequence SQL Server that fails to match is the occurrence preceded by the word like. The occurrence of the character sequence like followed by a space character does not satisfy the constraint imposed by the lookbehind. Therefore, although the character sequence SQL Server matches, the failure to satisfy the lookbehind constraint means that the whole regular expression fails to match.
How to Match Positions
By combining lookahead and lookbehind, it is possible to match positions between characters. For example, suppose that you wanted to match a position immediately before the Andrew of the following sample text:
This is Andrews book.
214

Lookahead and Lookbehind
You could state the problem definition as follows:
Match a position that is preceded by the character sequence is followed by a space character and is followed by the character sequence Andrew.
You could match that position using the following pattern:
(?<=is )(?=Andrew)
Try It Out |
Matching a Position |
1.Open RegexBuddy. On the Match tab, type the regular expression pattern (?<=is )(?=Andrew). If you used RegexBuddy for the replace example earlier in this chapter, delete the replacement text on the Replace tab.
2.On the Test tab, enter the sample text This is Andrews book.
3.Click the Find First icon, and inspect the information in the lower pane of the Test tab, as shown in Figure 8-14. On-screen, you can see the cursor blinking at the position immediately before the initial A of Andrews.
Figure 8-14
215

Chapter 8
How It Works
The regular expression engine starts at the beginning of the document and tests each position to see whether both the lookbehind and lookahead constraints are satisfied. In the test text, only the position immediately before the initial A of Andrews satisfies both constraints. It is, therefore, the only position that matches.
Adding Commas to Large Numbers
One of the useful ways to apply a combination of lookbehind and lookahead is adding commas to large numbers.
Assume that the sales for the fictional Star Training Company are $1,234,567. The data would likely be stored as an integer without any commas. However, for readability, commas are usual in many situations where financial or other numerical data is presented.
The process of adding commas to a large numeric value is essentially to match the position between the appropriate numeric digits and replace that position by a comma.
In some European languages, the thousands separator, which is a comma in English, is a period character. Such periods can be added to a numeric value by slightly modifying the technique presented below.
First, let’s look at a numeric value of 1234 and how you can add a comma in the appropriate place. You want to insert the comma at the position between the 1 and the 2. The reason to insert a comma in that position is that there are three numeric digits between the desired position and the end of the string.
Try It Out |
Adding a Comma Separator to a Four-Digit Number |
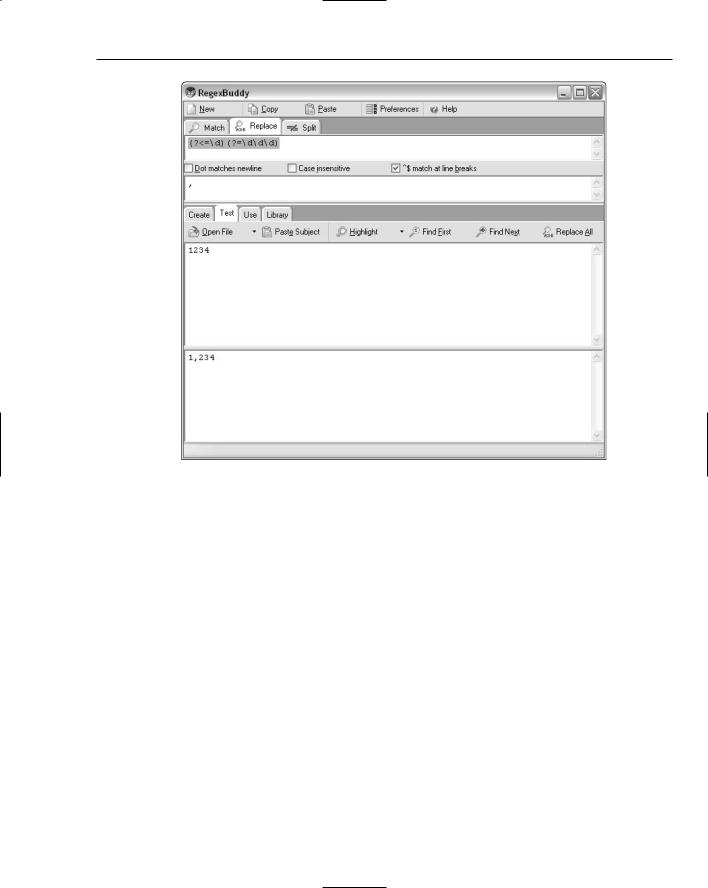
1.Open RegexBuddy. On the Replace tab, enter the pattern (?<=\d)(?=\d\d\d) in the upper pane and a single comma character in the lower pane.
2.On the Test pane, click the Find First icon. Confirm that there is a match, as described in the lower pane on the Test tab.
3.Click the Replace All icon, and check the replacement text shown in the lower pane on the Test tab (see Figure 8-15). The replacement text is 1,234, which is what you want. The regular expression pattern works for four-digit numbers.
216
Lookahead and Lookbehind
Figure 8-15
4.Edit the test text in the upper pane of the Test tab to read 1234567.
5.Click the Replace All icon, and inspect the replacement text in the lower pane of the Test tab. The replacement text is 1,2,3,4,567, which is not what you want. All the positions that have at least three numeric digits to the right have had a comma inserted, as shown in Figure 8-16.
6.Edit the pattern to (?<=\d)(?=(\d\d\d)+).
7.Click the Replace All icon, and inspect the replacement text in the lower pane of the Test tab. The undesired commas are still there.
217

Chapter 8
Figure 8-16
8.Edit the pattern to (?<=\d)(?=(\d\d\d)+$).
9.Click the Replace All icon, and inspect the replacement text in the lower pane of the Test tab (see Figure 8-17). This is 1,234,567, which is what you want.
10.Depending on your data source, the pattern (?<=\d)(?=(\d\d\d)+$) may not work. Imagine if a single character — for example, a period character — follows the last digit of the number to which you wish to add commas. Edit the test text to read Monthly sales figures are 1234567.
11.Edit the regular expression on the Replace tab to read (?<=\d)(?=(\d\d\d)+\W).
218

Lookahead and Lookbehind
Figure 8-17
How It Works
The pattern (?<=\d)(?=\d\d\d) looks for a position that follows a single numeric digit and precedes three numeric digits. In the sample text 1234, there is only one position that satisfies both the lookbehind and lookahead constraints: the position after the numeric digit 1.
When the test text is changed to 1234567, the pattern (?<=\d)(?=\d\d\d) matches several times. For example, the position following the numeric digit 2 is preceded by a numeric digit and is followed by three numeric digits. That position therefore satisfies both the lookbehind and lookahead constraints.
You need to group the numeric digits into groups of three to attempt to get rid of the undesired comma replacements. The pattern (?<=\d)(?=(\d\d\d)+) groups the numeric digits in the lookahead into threes but fails, as you saw in Figure 8-16, to prevent the unwanted commas. At the position following the numeric digit 2, there is still a sequence of three digits following that position, so the position matches. A comma is therefore inserted (although that is not appropriate to formatting norms for numbers).
219