


Regular Expression Tools and an Approach to Using Them
How It Works
The regular expression engine in Word attempts to find matches for the following pattern:
?ight
The ? metacharacter in Word matches any single alphanumeric character but doesn’t match other ASCII characters — for example, the newline character that is also contained in the file ight.txt. If a matching character is found for the ? metacharacter, an attempt is made to match the next character against the pattern i (lowercase i). If there is a match for that, an attempt is made to match the next character against the pattern g (lowercase g). Then an attempt is made to match the next character against the pattern h (lowercase h). If all four attempts at matching have been successful, an attempt is made to match against the pattern t (lowercase t). If all attempts at matching are successful, the match is highlighted in Word (as you saw in Figures 2-5 and 2-6). In this example, the first match is the word right, and that is highlighted after you click the Find Next button for the first time.
When you click the Find Next button a second time, Word attempts to find another match. The next match occurs when the attempt to match is made on the initial s of the word sight and the four characters that follow that s.
Many more wildcard options are available in Microsoft Word. For example, the pattern h?nd would match the sequences of characters hand and hind but would not match hound, because there are two characters between the h and the nd of hound. The ? metacharacter matches exactly one alphanumeric character in Word.
In most regular expression implementations the ? metacharacter is a quantifier, which specifies that the character or group that it qualifies occurs zero times or one time (meaning that it is optional).
However, another Word wildcard, the asterisk, matches zero or more alphanumeric characters, so the pattern h*nd would match hand, hind, and hound.
The use of regular expressions (wildcards) in Word is described in more detail in Chapter 11.
StarOffice Writer/OpenOffice.org Writer
Regular expressions are supported in OpenOffice.org Writer from version 1.1 and in Sun StarOffice Writer version 6 and above. OpenOffice.org is the official name of an open-source package consisting of word processor, spreadsheet, and presentation packages.
Many of the examples provided in the early parts of this book will show sample documents open in OpenOffice.org Writer, because the regular expressions implementation in OpenOffice.org Writer is standard in many respects, and it provides a convenient and useful way to demonstrate regular expression patterns without assuming that you have knowledge of particular programming languages. OpenOffice.org Writer is a particularly useful teaching tool because its regular expression implementation is mostly standard. It has a significant advantage in that it has an option to display all matches at once for a specified regular expression pattern.
The use of regular expressions in OpenOffice.org is described in more detail in Chapter 12.
27
Chapter 2
Komodo Rx Package
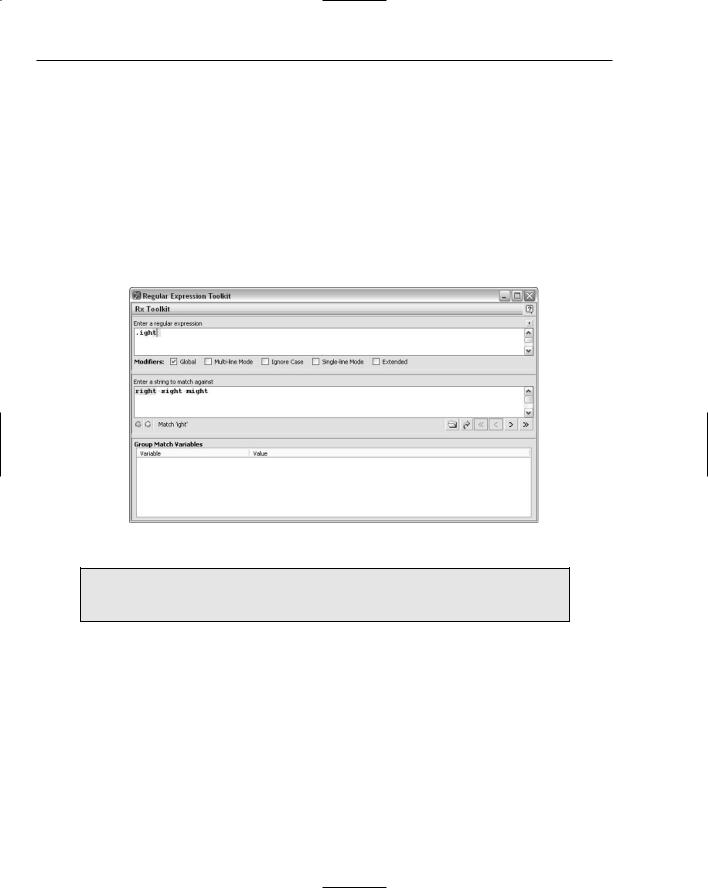
Active State, whose Web site is located at www.ActiveState.com, produces the Komodo developer’s editor. One tool in that editor is the Komodo Regular Expressions Toolkit, which allows regular expression patterns to be easily tested against sample sequences of characters.
The Komodo Regular Expressions Toolkit allows the developer to test regular expressions against a test string.
Figure 2-7 shows the Komodo Regular Expressions Toolkit being used to find matches for the pattern
.ight. In most regular expression implementations, the period character (also called the dot character) can match a single character (with the exception of newline and similar characters, but even that depends on specific settings in some situations).
Figure 2-7
Komodo Regular Expressions Toolkit version 2.5 is used in the examples in this chapter and following chapters. Version 3.0 of Komodo is used in Chapter 26.
PowerGrep
PowerGrep is a powerful, flexible, and educational tool because it implements many pieces of regular expression functionality. However, it also allows real-life search-and-replace use of regular expressions that can be targeted using the Folder and File mask, shown in Figure 2-8.
The use of regular expressions in PowerGrep is described in Chapter 14.
Microsoft Excel
Microsoft Excel supports limited use of wildcards. The use of wildcards in Excel is described in Chapter 15.
28

Regular Expression Tools and an Approach to Using Them
Figure 2-8
Languageand Platform-Specific Tools
The next few sections briefly describe the regular expression support at your disposal in several programming and scripting languages that are available on the Windows platform.
JavaScript and JScript
JavaScript was the original client-side scripting language from Netscape. Officially, we are now expected to refer to ECMAScript, because JavaScript was submitted to ECMA for recognition as an official standard. Support for regular expressions is significantly more complete in JavaScript 1.5 than in JavaScript 1.2.
Support for regular expression functionality is available in the RegExp and String objects.
The use of regular expressions in JavaScript is described in more detail in Chapter 19.
VBScript
Visual Basic Scripting Edition, often referred to simply as VBScript, has similarities to the regular expression support that exists in JScript. However, the object model underlying VBScript isn’t the same. Nonetheless, you can use techniques similar to those in JScript in many situations.
The use of regular expressions in VBScript is described in more detail in Chapter 20.
Visual Basic.NET
Regular expression support in Visual Basic .NET makes use of classes in the
System.Text.RegularExpressions namespace of the .NET Framework.
The use of regular expressions in Visual Basic .NET is described in more detail in Chapter 21.
29

Chapter 2
C#
C# is a new language, similar to Java, that Microsoft introduced as part of its .NET platform. C#, like VB.NET, makes heavy use of the classes in the System.Text.RegularExpressions namespace from the .NET Foundation Class Library for much of its functionality. There is extensive regular expression support in that class library.
The use of regular expressions in C# is described in more detail in Chapter 22.
PHP
PHP (PHP Hypertext Processor) is widely used on Web servers for the processing of data submitted from forms in Web pages. PHP has extensive regular expression support, which is largely standard.
The use of regular expressions in PHP is described in more detail in Chapter 23.
Java
Java is a full-featured, object-oriented programming language developed under the guidance of Sun Microsystems. Like Microsoft’s C# language, Java has ancestry in the C language.
Regular expression support in the Java language is focused in the java.util.regex pattern, which was introduced in Java version 1.4.
The use of regular expressions in Java is described in more detail in Chapter 25.
Perl
Regular expressions were first seriously applied in Perl in part because Perl was designed as a text manipulation language. Any programming language that is targeted at text processing will almost certainly have a significant need for regular expression functionality.
The range of regular expression support in Perl is enormous, often with several ways to achieve the same thing. Because both Perl code and regular expression syntax can be compact and cryptic, using regular expressions in Perl can be daunting at first for newcomers to the language. However, the power that is there makes the effort to master at least the basics well worthwhile.
The use of regular expressions in Perl is described in more detail in Chapter 26.
MySQL
MySQL is a relational database management system available on Windows and on Unix and Linux.
MySQL supports the SQL LIKE keyword. In addition, it supports a REGEXP keyword, which provides additional options for applying regular expressions.
The use of regular expressions in MySQL is described in more detail in Chapter 17.
30