

1.4.2. Методы кодирования и декодирования линейных кодов
Правила кодирования линейного кода задает проверочная матрица.
Пусть матрица H определена следующим образом:
 , (1.33)
, (1.33)
Матрица
![]() состоит из двух частей: информационной
состоит из двух частей: информационной![]() и проверочной
и проверочной![]() .
Каждая из
.
Каждая из![]() строк матрицы определяет правило
формирования соответствующего
проверочного элемента. Так, единицы,
расположенные на местах, соответствующих
информационным элементам в первой
строке, указывают на то, какие информационные
элементы должны участвовать в получении
первого проверочного элемента. Например,
из первой строки следует
строк матрицы определяет правило
формирования соответствующего
проверочного элемента. Так, единицы,
расположенные на местах, соответствующих
информационным элементам в первой
строке, указывают на то, какие информационные
элементы должны участвовать в получении
первого проверочного элемента. Например,
из первой строки следует![]() .
.
Структурная
схема кодирующего устройства, задаваемого
проверочной матрицей
![]() ,
приведена на рис.1.9.
,
приведена на рис.1.9.
|
|
|
|
Рис.1.9 |
Рис.1.10 |


Алгоритм
декодирования включает в себя вычисление
и анализ синдрома
![]() .
Если R(x)=0,
то принятое кодовое слово считается
неискаженным. Если R(x)
.
Если R(x)=0,
то принятое кодовое слово считается
неискаженным. Если R(x)![]() ,
то приемник отвергает принятое кодовое
слово.
,
то приемник отвергает принятое кодовое
слово.
Структурная схема декодера, определенного проверочной матрицей (1.33), представлена на рис.1.10.
1.4.3. Методы кодирования и декодирования свёрточных кодов
При сверточном кодировании поток данных разбивается на блоки длины k0, которые называют кадрами информационных символов. Кадры информационных символов кодируются кадрами кодового слова длины n0 каждый. Причем кодирование каждого кадра информационных символов в отдельный кадр кодового слова производится с учетом предыдущих т кадров информационных символов.
Структура кодера определяется длиной регистра, числом сумматоров и связями каждого сумматора с регистром. Связи выражают двоичным числом (или порождающим полиномом). Единицы в разрядах числа указывают на наличие связей соответствующих отводов регистра с сумматором.
Например,
приведенная на рис.1.11 схема кодера
соответствует сверточному коду,
определенному порождающими полиномами
![]() =
=![]() (111),
(111),
![]() =
=![]() (101).
(101).

Рис.1.11
Способ представления связи между входными и выходными последовательностями называется решетчатой диаграммой (рис.1.12). Для решетчатой диаграммы характерны следующие утверждения:
состоит из узлов и ребер (ветвей);
число ребер, исходящих из узла, равно основанию кода;
число узлов -
 ;
;выходные символы записываются над ветвями;
надписи около узлов характеризуют логическое состояние кодирующего устройства;
каждой информационной последовательности символов соответствует определенный путь на диаграмме;
процесс кодирования заключается в выборе одного из путей диаграммы.

Рис.1.12
Декодирование сверточных кодов осуществляется одним из трех методов: c вычислением проверочной последовательности, по принципу максимума правдоподобия или методом Витерби.
С вычислением проверочной последовательности. На приемной стороне из принятых информационных символов формируют проверочные по тому же закону, что и на передающей стороне, которые затем сравнивают с принимаемыми проверочными символами. Закон формирования проверочных символов выбирается таким образом, чтобы по структуре проверочной последовательности можно было определить искаженные символы. Метод применим только для систематических сверточных кодов.
Декодирование
по принципу максимума правдоподобия
сводится к
задаче отождествления принятой
последовательности с одной из
![]() возможных. Решение принимается в пользу
той последовательности, которая в
меньшем числе позиций отличается от
принятой. Метод применим для любого
сверточного кода, но не реализуем при
больших значенияхk
из-за необходимости перебора
возможных. Решение принимается в пользу
той последовательности, которая в
меньшем числе позиций отличается от
принятой. Метод применим для любого
сверточного кода, но не реализуем при
больших значенияхk
из-за необходимости перебора
![]() возможных кодовых последовательностей.
возможных кодовых последовательностей.
При
декодировании методом Витерби
из всех путей
на решетчатой диаграмме выбирается
путь, которому соответствует кодовая
последовательность, отличающаяся от
принятой в меньшем числе символов (весе
-
![]() ).
).
Пример. Пусть
последовательность на выходе кодера
(рис.1.11) имеет вид 00 00 00 00 00 … , а принятая
последовательность - 10 00 10 00 00… . Работу
декодера иллюстрируют диаграммы
(рис.1.13,а-в), где числа в узлах характеризуют
минимальный вес пути на
![]() -м
такте.
-м
такте.
|
|
|
|
| |
|
Рис.1.13 | |
 а)
а)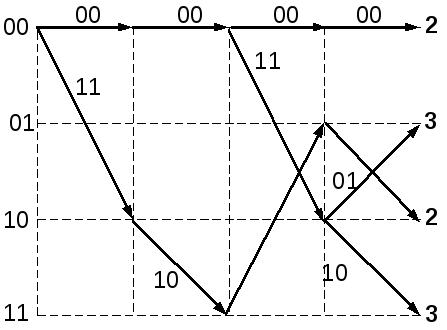 б)
б) в)
в)
На третьем такте работы декодера (рис.1.13а) общее число путей равно 8. Декодер сравнивает метрики для пар путей, ведущих в каждый узел, и из каждой пары оставляет путь с меньшим весом:
|
Расчет веса пути для первого узла |
|
|
|
Расчет веса пути для второго узла |
|
|
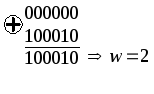



Таким
образом, для первого узла на диаграмме
выбирается путь с весом
![]() (рис.1.13а), для второго узла – путь с весом
(рис.1.13а), для второго узла – путь с весом![]() и т.д. На четвертом такте работы (рис.1.13б)
для первого узла на диаграмме выбирается
путь с весом
и т.д. На четвертом такте работы (рис.1.13б)
для первого узла на диаграмме выбирается
путь с весом![]() ,
для второго узла – путь с весом
,
для второго узла – путь с весом![]() и т.д. Процесс сравнения веса пар путей,
ведущих в каждый узел, повторяется на
каждом такте.
и т.д. Процесс сравнения веса пар путей,
ведущих в каждый узел, повторяется на
каждом такте.
Глубина (число тактов), на которой происходит слияние путей, является случайной величиной, зависящей от ошибок в принятой последовательности, и заранее не может быть вычислена. Поэтому при практической реализации декодера устанавливают некоторую фиксированную глубину декодирования. В примере на 10-м такте первые восемь ветвей всех «выживших» путей совпадают (рис.1.13в). В этот момент согласно алгоритму Витерби, принимается решение о принятых символах.