

1.3.2. Проверка остатков регрессии на автокорреляцию (статистика Дарбина – Уотсона)
При анализе остатков на автокорреляцию в случае пространственной выборки надо меть в виду, что последовательную зависимость остатков друг от друга необходимо рассматривать не для случайного набора пар наблюдений, а для пар наблюдений, упорядоченных по величине значений независимой переменной. И только в этом случае поведение остатков будет соответствовать ситуации, проверяемой по описываемому ниже критерию.
Проверку остатков регрессии на автокорреляцию можно осуществить на основе статистики Дарбина-Уотсона. Этот критерий основан на гипотезе о существовании автокорреляции между соседними членами ряда остатков и использует статистику

Здесь
ei
=
yi
–
 .
Можно показать, что
.
Можно показать, что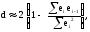 где
вычитаемая в скобках из единицы дробь
равна коэффициенту автокорреляции
первого порядка
где
вычитаемая в скобках из единицы дробь
равна коэффициенту автокорреляции
первого порядка (т.
е. это коэффициент корреляции междуei
и ei-1).
Ясно, что d-статистика
равна двум, если автокорреляция
отсутствует (тогда
(т.
е. это коэффициент корреляции междуei
и ei-1).
Ясно, что d-статистика
равна двум, если автокорреляция
отсутствует (тогда ),
и равна 0 или 4 при полной автокорреляции
(
),
и равна 0 или 4 при полной автокорреляции
( ).
).
Для
d-статистики найдены критические
границы (du
– верхняя и dl
– нижняя), на основе которых можно
определить области, позволяющие принять
или отклонить нулевую гипотезу об
отсутствии автокорреляции при
фиксированном уровне значимости
 ,
известном числе независимых переменных
m и объёме выборки n.
,
известном числе независимых переменных
m и объёме выборки n.
Таблица 1.3 – Механизм проверки гипотезы об автокорреляции в остатках по критерию Дарбина – Уотсона
|
Автокорреляция есть |
Область неопределённости |
Автокорреляция отсутствует |
Область неопределённости |
Автокорреляция есть |
0 dl du 4–du 4–dl 4
Если вычисленное значение d-статистики попало в область неопределенности критерия, то это означает, что нет статистических оснований ни принять, ни отклонить нулевую гипотезу об отсутствии автокорреляции в остатках. В этом случае нужно использовать какой-либо иной критерий или для большей точности увеличить объём выборки. Учитывая наличие области неопределённости, в литературе по эконометрике можно встретить такую рекомендацию: считать приближённо, что автокорреляции в остатках нет, если значение критерия находится в интервале (1,5 – 2,5), в противном случае признаётся наличие автокорреляции.
В
некоторых статистических пакетах
программ при проверке гипотезы об
отсутствии автокорреляции в остатках
совместно со статистикой Дарбина –
Уотсона рассчитывается р-value,
например в Statgraphics.
В этом случае проверяется гипотеза H0:
 = 0, т. е. что автокорреляция первого
порядка отсутствует, так что если
р-величина больше принятого уровня
значимости, то гипотеза об отсутствии
автокорреляции не отклоняется.
= 0, т. е. что автокорреляция первого
порядка отсутствует, так что если
р-величина больше принятого уровня
значимости, то гипотеза об отсутствии
автокорреляции не отклоняется.
Как уже отмечалось, статистика Дарбина-Уотсона в большей мере используется при анализе временных рядов, поскольку именно для них актуально понятие автокорреляции. Однако она может быть использована для проверки правильной спецификации уравнения парной (простой) регрессии, но при этом необходимо случайную выборку упорядочить по степени возрастания независимой переменной. Тогда появится смысл в понятии «последовательные остатки». Если при этом с помощью критерия Дарбина-Уотсона обнаружена существенная автокорреляция остатков, то необходимо признать наличие проблемы в спецификации уравнения регрессии и либо вернуться к выбору объясняющей переменной, либо к форме регрессионной зависимости, либо попытаться избавиться от автокорреляции другими методами.
Следует иметь в виду, что статистика Дарбина-Уотсона обладает рядом недостатков: проверяет автокорреляцию только первого порядка, имеет области неопределённости и не может использоваться, если в качестве независимой переменной выступает лаговое значение зависимой переменной и если в уравнении регрессии отсутствует константа.
Несмотря на указанные недостатки, данная статистика используется наиболее часто и работает с выборочными наблюдениями, не требуя жёстких требований к выборке в отличие от асимптотических критериев.
Пример 1. Анализ функции потребления.
Приведём пример использования рассмотренных положений теории по простой регрессии, анализируя зависимость расхода 60 семей от их доходов. Эта информация представлена на графике (рисунок 1.1).

Рисунок 1.1 – График исходных данных
Уравнение регрессии зависимости расходов (y) от доходов (х) раcсчитано в EViews и отчёт о регрессии приведён ниже (рисунок 1.2).
Проанализируем
его. В отчёте указан метод оценивания
параметров уравнения регрессии (Least
Squares
– наименьшие квадраты), число наблюдений
– 60. В столбце «коэффициенты» указаны
оценки параметров уравнения регрессии
(коэффициент при х равен 0,6 и свободный
член (с) равен 17). Следовательно, можно
выписать уравнение регрессии:
 = 17 + 0,6х. За столбцом «коэффициенты»
следуют столбцы стандартных ошибок иt-статистик.
Последний столбец (Prob.)
– это расчётный уровень значимости,
т.е. вероятность того, что |t
|≤
= 17 + 0,6х. За столбцом «коэффициенты»
следуют столбцы стандартных ошибок иt-статистик.
Последний столбец (Prob.)
– это расчётный уровень значимости,
т.е. вероятность того, что |t
|≤
 .
Если эта вероятность меньше
.
Если эта вероятность меньше (по умолчанию будем в дальнейшем принимать
(по умолчанию будем в дальнейшем принимать = 0,05), то соответствующая оценка значимо
отлична от нуля. У нас обе вероятности
меньше 0,05, следовательно, обе оценки
значимо отличны от нуля.
= 0,05), то соответствующая оценка значимо
отлична от нуля. У нас обе вероятности
меньше 0,05, следовательно, обе оценки
значимо отличны от нуля.

Рисунок 1.2 – Отчёт о регрессии
Проанализируем показатели точности уравнения регрессии. Начнём с анализа значимости уравнения регрессии. F-satstistic = 544, а вероятность для неё (Prob(F-statistic)) равна нулю. Это – результат дисперсионного анализа уравнения регрессии. Здесь проверяется гипотеза о значимости уравнения регрессии, т. е., что коэффициент уравнения регрессии равен нулю. Поскольку расчётный уровень значимости здесь меньше принятого (0,05), то гипотеза о равенстве коэффициента регрессии отклоняется и считается, что уравнение регрессии значимо.
Коэффициент
детерминации (R-squared)
равен 0,9. Следовательно, изменение
расходов в нашем примере на 90% зависит
от изменения доходов. Показатель Adjusted
R-squared
(исправленный коэффициент детерминации)
в простой регрессии не анализируется.
Затем указана стандартная ошибка
регрессии (S.E.
of
regression).
Она равна 11.32. Затем показана сумма
квадратов остатков регрессии (Sum
squared
resid
–
 )2
= 7432), которая используется в более
подробном анализе (см. далее в примере).
)2
= 7432), которая используется в более
подробном анализе (см. далее в примере).
Далее (в правом столбце нижней части отчёта) указано среднее значение зависимой переменной (Mean dependent var) – средний уровень доходов этих 60 семей (он равен 121,2). Стандартную ошибку регрессии (11,32) можно сравнить с этим средним доходом и определить, насколько точно в среднем прогнозируются расходы семьи по этому уравнению регрессии.
Далее указаны три информационных критерия (Akaike, Schwarz, Hannan), которые в парной регрессии не анализируются.
Статистика Дарбина – Уотсона (d) рассчитана для проверки гипотезы о наличии в остатках регрессии автокорреляции первого порядка. Как отмечалось, эта информация более полезна при анализе временных рядов. Для пространственной информации надо данные упорядочить, чтобы понятие «соседние» остатки приняло какой-то смысл. В случае случайной выборки это понятие теряет смысл. В нашем случае данные упорядочены по росту доходов (см. рисунок1.1), следовательно, можно анализировать эту статистику без предварительного упорядочения. Как видно из отчёта, d = 1,51. Табличные значения нижней (dl) и верхней (du) границ соответственно равны 1,55 и 1,62. Построим области принятия решения о наличия или отсутствия автокорреляции в остатках в соответствии с приведённой схемой в таблице 1.3.
|
Автокорреляция есть |
Область неопределённости |
Автокорреляция отсутствует |
Область неопределённости |
Автокорреляция есть |
0 1,55 1,62 2,38 3,45 4
Как видим, расчётное значение попало в область, где автокорреляция есть. Да и по графику (рисунок 1.3) видно, что остатки не являются случайным процессом. Видна закономерность их изменения – регулярная смена отрицательных остатков на положительные. На этом рисунке изображены реальные (Actual) и расчётные (Fitted – подобранные) значения моделируемой переменной (расходов) и остатки (Residual). Причём, правая вертикальная ось – для моделируемого показателя, левая – для остатков.

Рисунок 1.3 – Графики остатков, выборочных и расчётных значений
для расходов
Гомоскедастичность остатков проверим тестом Голдфелда – Квандта. Для этого всю выборку разобьём на три части по 20 наблюдений, рассчитаем уравнения регрессии поотдельности для первых 20 наблюдений и для последних 20 наблюдений и выпишем остаточные суммы квадратов этих уравнений (Sum squared resid). Получим для первой части выборки 1 246,276, а для третьей – 4 164,0 (рисунок 1.4 и рисунок 1.5). Обратите внимание на позицию Sample – выборка. В первом случае в окне спецификации было установлено «1 20» (т. е. первых 20 наблюдений), а во втором – «41 60» (последних 20 наблюдений).

Рисунок 1.4 – Регрессия для первых 20 наблюдений

Рисунок 1.5 – Регрессия для последних 20 наблюдений
Вычислим F-статистику как отношение этих двух дисперсий и сравним с критическим значением. Получим F = 3,34, а табличное значение F(20;20;0,05) = 2,1. Поскольку выборочное значение F-статистики оказалось больше табличного, то гипотеза о равенстве дисперсий отклоняется, и делаем вывод, что дисперсии различаются значимо, а значит, остатки анализируемого уравнения гетероскедастичны (растут с ростом доходов).
Тестирование предпосылки о нормальном законе распределения остатков проведём тестом Jarque – Bera, который сравнивает асимметрию и эксцесс остатков с асимметрией и эксцессом нормального закона распределения.
Чтобы провести это тестирование, необходимо после оценки уравнения регрессии сначала создать остатки, выбрав Proc/Make Residual Series…/OK. Затем выбрать View/Descriptive Statistics&Tests/Histogram and Stats. Получим рисунок 1.6. Здесь кроме гистограммы остатков приведены описательные статистики остатков, а также асимметрия (Skewness) и эксцесс (Kurtosis). Известно, что для нормального закона распределения эти характеристики равны соответственно 0 и 3. Статистика Jarque – Bera рассчитывается из соотношения
JB
= (n–k) ,
,
где n – объём выборки, k – число оцениваемых параметров, S – асимметрия, K – эксцесс. Поскольку в нашем случае вероятность больше 0,05, то гипотезе о нормальном законе распределения остатков не отклоняется.

Рисунок 1.6 – Гистограмма остатков и тест Jarque – Bera
Как поступить, если установлены наличие автокорреляции и гетероскедастичность остатков, а также тестирование второй предпосылки МНК – рассмотрим далее, при анализе уравнения множественной регрессии.