

Понятие сложности алгоритма, оценки времени исполнения.
 Время
поиска оценивается как O(n) (читается
так: «О большое
от n»), имеют в виду не точное время
исполнения, а только его предел сверху,
причем с точностью до постоянного
множителя. Когда говорят, например, что
алгоритму требуется время порядка
O(n2),
имеют в виду, что время исполнения задачи
растет не быстрее, чем квадрат количества
элементов.
Время
поиска оценивается как O(n) (читается
так: «О большое
от n»), имеют в виду не точное время
исполнения, а только его предел сверху,
причем с точностью до постоянного
множителя. Когда говорят, например, что
алгоритму требуется время порядка
O(n2),
имеют в виду, что время исполнения задачи
растет не быстрее, чем квадрат количества
элементов.
Рассмотрим задачу сложения двух матриц. Например

Сколько операций сделано?
2+3 = 5 всего 2 операции и так делали 9 = 32 раз. В этом случае повторение отдельного шага α+β=γ выполняется 9 раз. Если обозначить длину строки через n, то получаем формулу для подсчета числа операций, выполняемых при сложении матриц в общем случае
<количество операций> = 2*n2
Здесь 2 – некоторый постоянный коэффициент и видим квадратичную зависимость от объема исходных данных О(n2).
Рассмотрим задачу умножения матриц. Сколько операций сделано?
2*3 + 2*2 + 3*1 = 13 и так делали 32 раз. Здесь уже «цена» отдельного шага зависит от размерности исходных данных: n операций умножения и n операций сложения и записи, т.е. 2*n операций.
Тогда общая сложность алгоритма есть 2*n3 и имеем алгоритм кубической сложности О(n3).
Если оба алгоритма, например, O ( n*log n ), то это отнюдь не значит, что они одинаково эффективны. Символ О не учитывает константу, то есть первый может быть, скажем в 1000 раз эффективнее.
За функцию берется количество операций, возрастающее быстрее всего.
То есть, если в программе одна функция выполняется O(n) раз - например, умножение, а сложение - O(n2) раз, то общая сложность программы - O(n2), так как в конце концов при увеличении n более быстрые ( в определенное, константное число раз ) сложения станут выполняться настолько часто, что будут влиять на быстродействие куда больше, нежели медленные, но редкие умножения. O() показывает исключительно асимптотику !
Основание логарифма не пишется.
Причина этого весьма проста. Пусть есть O( log2 n). Но log2 n=log3 n / log3 2, а log3 2, как и любую константу, асимптотика - символ О() не учитывает. Таким образом, O(log2 n) = O(log3 n).
Общая классификация вычислительных алгоритмов.
Общепринятой классификации множества вычислительных алгоритмов не существует. Будем понимать под «вычислительными» алгоритмы, используемые для вычисления математических объектов: констант, функций, нахождения корней различного типа уравнений и систем уравнений. Условно все вычислительные алгоритмы можно поделить на два класса: основанные на представлении данных целочисленными значениями либо использующими плавающую арифметику.
По области применения алгоритмов можно выделить такие области как
- теория чисел, быстрые алгоритмы вычисления различных констант и распространенных математических функций;
- решение алгебраических задач;
- нахождение корней различного рода уравнений;
- приближение функций;
- вычислительная геометрия;
Точность представления чисел
В в языке Си, для представления вещественных чисел используются типы данных float, double и long double, при этом оказывается задействованными 4, 8 и 10 байтов соответственно. Следует сразу заметить, что тип float может использоваться только в очень ограниченных ситуациях. Для того, чтобы в этом убедиться достаточно выполнить простую программу:
#include <stdio.h>
#include <conio.h>
void main()
{
float a, b,c,d,e,f;
a=95.0;
b=(float)0.2;
d = (a+b)*(a+b);
e = (float)-2.0*a*b -a*a;
f = b*b;
c = (d+e) / f;
printf ("\nc=%f\n",c);
getch();
}
(a+b)*(a+b)=a2+2ab+b2-2ab- a2b2
(a2+2ab+b2 – 2ab – a2) / b2
Результат: с=1.000976
Ясно, что это связано с возможностью дискретизации числового ряда. Значение 95.0 фактически представляется в памяти как 00 00 BE 42, а значение 0.2 последовательностью CD CC 4C 3E.
Фактически тип float может использоваться только для представления исходных данных или конечных результатов, но использовать его для промежуточных вычислений, особенно в итерационных алгоритмах (итерация — организация обработки данных, при которой действия повторяются многократно, не приводя при этом к вызовам самих себя (не путать с рекурсией).)– нельзя.
. Вычисление «машинного нуля».
При организации вычислений очень часто завершение работы алгоритма производится при достижении заданной точности, т.е. числового значения, меньше которого невозможно задавать точность данного алгоритма. Обычно, такое условие задается некоторой формулой типа |xi+1-xi|<ε. Указанное абсолютное значение зависит от разрядной сетки применяемого компьютера, от способа представления вещественных чисел в используемом компиляторе языка программирования и от самих значений, используемых для оценки точности.
#include <stdio.h>
#include <conio.h>
void main(){
int i=0;
float res=1.0, work;
do {
i++;
res = res/(float)2.0;
work = res+(float)1.0;
} while (work>1.0);
printf ("\nNumber of divisions =%6d\n",i);
printf ("\nprecision =%.10f\n",res);
getch();
}
Результат работы этой программы выглядит как

В заголовочном файле LIMITS.H приведены различные предельные значения для констант разных типов.
Понятие стека. Операции над стеком.
Стек - это последовательный список переменной длины, включение и исключение элементов из которого выполняются только с одной стороны списка, называемой вершиной стека. Функционирует по типу LIFO (Last - In - First- Out). Основные операции над стеком - включение нового элемента (английское название push (пуш)- заталкивать) и исключение элемента из стека (англ. pop - выскакивать). Полезными могут быть также вспомогательные операции:
определение текущего числа элементов в стеке;
очистка стека;
неразрушающее чтение элемента из вершины стека.
Реализация стека может быть выполнена на основе массива. Кроме собственно массива необходимо дополнительно иметь переменную, адресующую вершину стека. Под вершиной стека можно понимать либо первый свободный элемент стека, либо последний записанный в стек элемент
При занесении или удаления элемента в стек указатель модифицируется.
Программная реализация стека на основе статического массива.
struct node
{ int number; };
void add(node *, int*);
void prosm(node *,int);
int find(node *,int,int);
void main(){
int size,top=-1;
struct node *p=new node[size];
int i=find2(p,top,key);
if(i==-1) printf("Такого элемента не существует!\n");
else vivod(p,i);}
void add2(node *arr,int *top){
int i=*top+1;
vvod(arr,i);
*top=i;}
void prosm2(node *arr,int top){
int i;
for(i=0;i<=top;i++) vivod(arr,i);}
int find2(node *arr, int top, int key){
int i,c=0;
for(i=0;i<=top;i++)
if(arr[i].number==key){ c=1; break;}
if(c==1)return i;
else return -1}
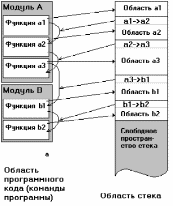
Использование стека при организации связи функций в языке Си и в операционной системе.
Структуры-стеки часто используются при разработке инструментального программного обеспечения – операционных систем, компиляторов, и т.п. Даже на уровне машинных команд процессора (практически всех типов процессоров) существуют команды push-pop. Стек является основной структурой, используемой при организации выполняющихся на компьютере процессов.
Понятие очереди. Операции над очередями.
Очередью FIFO (First - In - First- Out - "первым пришел - первым исключается") называется такой последовательный список переменной длины, в котором включение элементов выполняется только с одной стороны списка (эту сторону часто называют концом или хвостом очереди), а исключение - с другой стороны (называемой началом или головой очереди).
Основные операции над очередью - те же, что и над стеком - включение, исключение, определение размера, очистка, неразрушающее чтение.
При представлении очереди массивом в дополнение к нему необходимы параметры-указатели: на начало очереди (на первый элемент в очереди) и на ее конец (первый свободный элемент в очереди). При включении элемента в очередь элемент записывается по адресу, определяемому указателем на конец, после чего этот указатель увеличивается на единицу. При исключении элемента из очереди выбирается элемент, адресуемый указателем на начало, после чего этот указатель также увеличивается на единицу.