

Кольцевая очередь. Деки.
Для того, чтобы места, занимаемые исключенными элементами, могли быть повторно использованы, очередь замыкается в кольцо: указатели (на начало и на конец), достигнув конца выделенной области памяти, переключаются на ее начало. Такая организация очереди в памяти называется кольцевой очередью. В исходном состоянии указатели на начало и на конец указывают на начало области памяти. Равенство этих двух указателей (при любом их значении) является признаком пустой очереди.
Дек - особый вид очереди. Дек (от англ. deq - double ended queue, т.е. очередь с двумя концами) - это такой последовательный список, в котором как включение, так и исключение элементов может осуществляться с любого из двух концов списка. Частный случай дека - дек с ограниченным входом и дек с ограниченным выходом. Логическая и физическая структуры дека аналогичны логической и физической структуре кольцевой FIFO-очереди. Однако, применительно к деку целесообразно говорить не о начале и конце, а о левом и правом конце.
Физическая структура дека в статической памяти идентична структуре кольцевой очереди. Динамическая реализация является очевидным объединением стека и очереди.
Примером дека может быть, например, некий терминал, в который вводятся команды, каждая из которых выполняется какое-то время. Если ввести следующую команду, не дождавшись, пока закончится выполнение предыдущей, то она встанет в очередь и начнет выполняться, как только освободится терминал. Это FIFO очередь. Если же ввести дополнительно операцию отмены последней введенной команды, то получается дек.
Программная реализация очереди на основе статического массива.
struct nodе { int number;};
void add1(node *, int, int *, int *);
void print1(node *, int, int, int);
int find1(node *, int,int,int,int);
void main()
{
int exit=1,size,ex=1,begin=-1,end=-1;
scanf("%d",&size);
struct node *p=new node[size];
while(1)
{
if(end+1==begin || (end+1==size && begin==0)){
printf("Ошибка! Очередь заполнена!\n"); break;}
add1(p,size,&begin,&end);
scanf("%d",&ex);
if(ex==0) break;
}
print1(p,begin,end,size);
int i,key;
scanf("%d",&key);
i=find1(p,begin,end,key,size);
if(i==-1) printf("Такого элемента не существует!\n");
else vivod(p,i);
}
void add1(node *arr, int size, int *head, int *tail)
{
int i;
if(*tail==-1){ i=0; *head=0;}
else{
if(*tail+1==size)i=0;
else i=*tail+1; }
vvod(arr,i);
*tail=i;
}
void print1(node *arr,int head,int tail,int size)
{
int i;
for(i=head;;i++)
{
vivod(arr,i);
if(i+1==size && head>tail)i=-1;
if(i==tail)break;
}
}
int find1(node *arr, int head, int tail,int key,int size
{
int i,x=0;
for(i=head;;i++)
{
if(arr[i].number==key)
{ x=1;break;}
if(i+1==size && head>tail)i=-1;
if(i==tail)break;
}
if(x==0)
return -1;
else
return i;
}
Структура данных «список».
Список – это упорядоченное множество, состоящее из переменного числа элементов, к которым применимы операции включения и исключения.
Ссылки.
Ссылка – это информация о связи данного компонента структуры с другими (удобно реализовать ссылки на основе использования указателей). Компонент списка всегда состоит из ссылки и содержания. В качестве содержания может выступать любой тип данных, в том числе и агрегированный (т.е. массив или структура). В качестве ссылки – один или множество указателей, ссылающихся на элементы рассматриваемого списка.
Линейные списки – основные операции.
Список, отражающий отношение соседства между элементами, называется линейным. Линейные списки являются простейшими динамическими структурами данных. Каждый список должен иметь особый элемент, называемый указателем начала списка или головой списка, который по формату обычно отличен от остальных элементов. Список называется односвязным, если в каждом его элементе используется только одна ссылка, связывающая текущий элемент со следующим.
1. Создание списка. Эта операция предполагает определение указателя начала списка и присвоение ему NULL-значения (т.е. никакого).
2. Перебор элементов списка. Эта операция состоит в последовательном доступе к элементам списка – ко всем до конца списка либо до нахождения искомого элемента. Для каждого из перебираемых элементов осуществляется некоторая обработка его информационной части: сравнение с образцом, печать, модификация и прочее.
3. Вставка элемента в список.
4. Удаление элемента из списка.
5. Перестановка элементов списка. Изменчивость динамических структур данных предполагает не только изменения размера структуры, но и изменения связей между элементами. Для связных структур изменение связей не требует пересылки данных в памяти, а только изменения указателей в элементах связной структуры. В качестве примера на рис.7 приведена перестановка двух соседних элементов списка.

Реализация списков на основе динамических структур.
struct node{
int nomer;
node *next;};
typedef node *nodePtr;
void add(nodePtr *start){
nodePtr p=new node;
scanf("%d",&p->nomer);
if(*start==NULL)
{
p->next=NULL;
*start=p;
}
else
{
nodePtr pred=*start,sled=*start;
while(sled)
{
if(sled->nomer > p->nomer)
{
p->next=sled;
if(sled==*start)
*start=p;
else
pred->next=p;
return;
}
pred=sled;
sled=sled->next;
}
p->next=NULL;
pred->next=p;
}}
nodePtr find(nodePtr start,int key){
nodePtr p=start;
while(p){
if(p->nomer==key)
return p;
p=p->next;}
return NULL;
}
nodePtr del(nodePtr *start,int key){
nodePtr p=find(*start,key);
if(p==NULL) return NULL;
else{
nodePtr tmp=new node;
tmp->nomer=p->nomer;
if(p==*start)
*start=p->next;
else
{
nodePtr pred=*start;
while(pred)
{
if(pred->next==p) break;
pred=pred->next;
}
if(p->next==NULL)pred->next=NULL;
else pred->next=p->next;
}
delete p;
return tmp;
}}
Двусвязный список и его программная реализация.
Для такого списка в качестве ссылки используется два указателя – один на следующий элемент списка, другой – на предыдущий. Операции идентичны операциям над линейным списком, но изменяются 2 указателя.
Кольцевые списки
Если замкнуть связь «вперед» последнего блока на первый блок списка, а связь «назад» первого блока на последний, то получим кольцевой список.
Многосвязные (слоеные) списки
В
одном элементе списка можно указать
сколько угодно связей и в этом случае
нам придется иметь дело с многосвязными
списками, или как их еще называют –
«слоеными списками 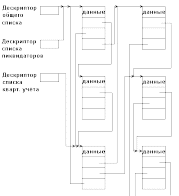
Для того, чтобы при выборке каждого подмножества не выполнять полный просмотр с отсеиванием записей, к требуемому подмножеству не относящихся, в каждую запись включаются дополнительные поля ссылок, каждое из которых связывает в линейный список элементы соответствующего подмножества. В результате получается многосвязный список или мультисписок, каждый элемент которого может входить одновременно в несколько односвязных списков.
Каждая подзадача работает со своим подмножеством как с линейным списком, используя для этого определенное поле связок. Специфика мультисписка проявляется только в операции исключения элемента из списка. Исключение элемента из какого-либо одного списка еще не означает необходимости удаления элемента из памяти, так как элемент может оставаться в составе других списков. Память должна освобождаться только в том случае, когда элемент уже не входит ни в один из частных списков мультисписка. Обычно задача удаления упрощается тем, что один из частных списков является главным - в него обязательно входят все имеющиеся элементы.
Поиск
Поиск – это одно из наиболее часто встречающихся в программировании действий. Если нет никакой дополнительной информации о разыскиваемых данных, то очевидный подход – простой последовательный просмотр элементов массива. Такой подход называется линейным поиском. Условия окончания поиска таковы: элемент найден или совпадения не обнаружено.
Бинарный поиск
Поиск можно сделать гораздо более эффективным, если данные в массиве будут упорядочены. Это значит, что выполняется условие
A[k-1] <= A[k] для k=1,2,…,N
Основная идея алгоритма – выбрать случайно некоторый элемент, предположим am, и сравнить его с искомым х. Если он равен х, то поиск заканчивается; если он меньше х, то можно сказать, что все элементы с индексами не большими m из дальнейшего поиска можно исключить. В итоге имеем алгоритм, называемый «поиском деления пополам». Здесь две индексные переменные L и R отмечают соответственно левый и правый конец секции массива a, где еще может быть обнаружен требуемый элемент.
int FindD2 (int* A, int N, int X ){
int m, L=0, R=N-1, flag=0;
while (L<=R && !flag){
m=(L+R)/2;
if (A[m]==X) flag = 1;
else
if (A[m]<X) L=m+1;
else R=m-1; }
return flag;}
В результате максимальное число сравнений равно log N. Приведенный алгоритм существенно выигрывает по сравнению с алгоритмом линейного поиска, для которого число сравнений равно N/2.
Алгоритм прямого поиска строки
Пусть задан массив s из N элементов и массив p из M элементов, причем 0<M<=N. Поиск строки обнаруживает первое вхождение p в s. Сначала разберем простейший алгоритм, называемый прямым поиском строки.
Результатом поиска будем считать индекс i, указывающий на первое от начала строки совпадение с образцом. Условно алгоритм можно описать следующим образом
for(i=0,j=0;j<M && i<N-M;i++){
j=0;
while ((j<M) && (s[i+j] == p[j]) ) j++; }
Этот алгоритм работает достаточно эффективно, если допустить, что несовпадение пары символов происходит после всего нескольких операций сравнений во внутреннем цикле. Если же взять в качестве текста АААААААВ и искать в нем AAВ – то в общем случае может понадобиться N*M операций.