

Фаза 1 сортировки: построение пирамиды
H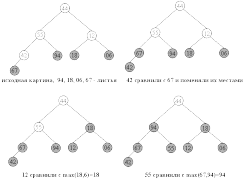 ачать
построение пирамиды можно с a[k]...a[n],
k = [(n+1)/2].
Эта часть массива удовлетворяет свойству
пирамиды, так как не существует индексов
i,j:
i = 2i+1
(или j
= 2i+2)...
Просто потому, что такие i,j
находятся за границей массива (на
графическом языке – эта часть элементов
не имеет потомков).
ачать
построение пирамиды можно с a[k]...a[n],
k = [(n+1)/2].
Эта часть массива удовлетворяет свойству
пирамиды, так как не существует индексов
i,j:
i = 2i+1
(или j
= 2i+2)...
Просто потому, что такие i,j
находятся за границей массива (на
графическом языке – эта часть элементов
не имеет потомков).
Далее будем расширять часть массива, добавляя по одному элементу за шаг. Следующий элемент на каждом шаге добавления - тот, который стоит перед уже готовой частью. Чтобы при добавлении элемента сохранялась пирамидальность, будем использовать следующую процедуру расширения пирамиды a[i+1]..a[n] на элемент a[i] влево:
Смотрим на сыновей слева и справа - в массиве это a[2i+1] и a[2i+2] и выбираем наибольшего из них.
Если этот элемент больше a[i] - меняем его с a[i] местами и идем к шагу 2, имея в виду новое положение a[i] в массиве. Иначе конец процедуры.
Новый элемент "просеивается" сквозь пирамиду.
Фаза 2: собственно сортировка
Итак, задача построения пирамиды из массива решена. Как видно из свойств пирамиды, в корне всегда находится максимальный элемент. Отсюда вытекает алгоритм фазы 2:
1. Берем верхний элемент пирамиды a[0]...a[n] (первый в массиве) и меняем с последним местами. Теперь "забываем" об этом элементе и далее рассматриваем массив a[0]...a[n-1]. Для превращения его в пирамиду достаточно просеять лишь новый первый элемент.
2. Повторяем шаг 1, пока обрабатываемая часть массива не уменьшится до одного элемента.
Очевидно, в конец массива каждый раз попадает максимальный элемент из текущей пирамиды, поэтому в правой части постепенно возникает упорядоченная последовательность.
Построение пирамиды занимает O(n log n) операций, причем более точная оценка дает даже O(n) за счет того, что реальное время выполнения downheap зависит от высоты уже созданной части пирамиды. Вторая фаза занимает O(n log n) времени: O(n) раз берется максимум и происходит «просеивание» бывшего последнего элемента. Плюсом является стабильность метода: среднее число пересылок (n log n)/2, и отклонения от этого значения сравнительно малы.
Пирамидальная сортировка не использует дополнительной памяти. Метод не является устойчивым: по ходу работы массив так «перетряхивается», что исходный порядок элементов может измениться случайным образом. Поведение неестественно: частичная упорядоченность массива никак не учитывается.
Быстрая сортировка
Выбираем средний элемент массива, т.е. mas[N/2]. Потом используем переменные i=0, j=N-1 в качестве индексов и пройдемся по массиву, наращивая i и уменьшая j, и отыскивая в левой части элемент, больше среднего, а в правой части – меньше среднего. Найденные элементы переставим местами. Будем повторять эти действия до тех пор, пока i не станет больше j. После этого рассмотрим два подмножества, ограниченные с краев индексами left=0 и right=N-1, а в середине – j и i. Если эти подмножества существуют, (т.е. i < right и j > left), то к ним применим уже описанный здесь метод сортировки.
/*Сортировка всех тех элементов массива mas, индексы которых лежат в интервале от left до right*/
void QuickSort(int *mas, int left, int right) {
int i=left, j=right; /*Инициализируем переменные границами подмассива*/
int central = mas[(left+right)/2];
do {
while (mas[i] < central) i++;/*находим элемент,> элемента разбиения*/
while (mas[j] > central) j--;/* меньший элемента разбиения*/
if (i<=j) {
Swap(&mas[i], &mas[j]);/*меняем местами элементы */
i++; j--;}
}while(i <= j);
/*рекурсивно вызываем алгоритм для правого и левого подмассива*/
if (i<right) QuickSort(mas, i, right);
if (j>left) QuickSort(mas, left, j); }
Общее быстродействие: O(n log n). Но возможен случай таких входных данных, на которых алгоритм будет работать за O(n2) операций (каждый раз в качестве центрального элемента выбирается максимум или минимум входной последовательности). Метод неустойчив. Поведение довольно естественно, если учесть, что при частичной упорядоченности повышаются шансы разделения массива на более равные части.
Замечания:
1. Из-за рекурсии и других "накладных расходов" Quicksort может оказаться не столь уж быстрой для коротких массивов
2. В случае явной рекурсии в стеке сохраняются не только границы подмассивов, но и ряд совершенно ненужных параметров, таких как локальные переменные.
3. Чем на более равные части будет делиться массив – тем лучше
4. Пусть входные последовательности очень плохи для алгоритма. Можно просто выбирать в качестве опорного случайный элемент входного массива. Другой вариант - переставить перед сортировкой элементы массива случайным образом.
5. Быструю сортировку можно использовать и для двусвязных списков. Единственная проблема - отсутствие непосредственного доступа к случайному элементу..
6. Можно заменить рекурсию на итерации, реализовав стек на основе массива. Процедура разделения будет выполняться в виде цикла.
Сортировка слиянием
Сортировка слиянием построена на принципе "разделяй-и-властвуй", однако реализует его по-другому, нежели quickSort. А именно, вместо разделения по опорному элементу массив просто делится пополам.
//a - сортируемый массив, его левая граница lb,правая граница ub
void mergeSort(int a[], long lb, long ub) {
long split; // индекс, по которому делим массив
if (lb < ub) { // если есть более 1 элемента
split = (lb + ub)/2;
mergeSort(a, lb, ub); // сортировать левую половину
mergeSort(a, split+1, last);// сортировать правую половину
merge(a, lb, split, ub);
}}
Функция merge на месте двух упорядоченных массивов a[lb]...a[split] и a[split+1]...a[ub] создает единый упорядоченный массив a[lb]...a[ub].
Пример работы алгоритма на массиве 3 7 8 2 4 6 1 5.. (split – трещина, раскол)

Рекурсивный алгоритм обходит получившееся дерево слияния в прямом порядке. Каждый уровень представляет собой проход сортировки слияния - операцию, полностью переписывающую массив. Обратим внимание, что деление происходит до массива из единственного элемента. Такой массив можно считать упорядоченным, а значит, задача сводится к написанию функции слияния merge (мэдж).
Один из способов состоит в слиянии двух упорядоченных последовательностей при помощи вспомогательного буфера, равного по размеру общему количеству имеющихся в них элементов. Элементы последовательностей будут перемещаться в этот буфер по одному за шаг.
merge ( упорядоченные последовательности A, B , буфер C ) {
пока A и B непусты { cравнить первые элементы A и B и переместить наименьший в буфер}если в одной из последовательностей еще есть элементы дописать их в конец буфера, сохраняя имеющийся порядок}
Хорошо запрограммированная внутренняя сортировка слиянием работает немного быстрее пирамидальной, но медленнее быстрой, при этом требуя много памяти под буфер. Поэтому mergeSort используют для упорядочения массивов, лишь если требуется устойчивость метода (которой нет ни у быстрой, ни у пирамидальной сортировок). Сортировка слиянием является одним из наиболее эффективных методов для односвязных списков и файлов, когда есть лишь последовательный доступ к элементам