

1.1. Виявлення сумнівного результату
![]() Часто,
аналізуючи зразки, проводять лише три
паралельні досліди. Щоб одержати
оптимальний результат аналізу,
використовують середнє арифме-тичне
значення з трьох результатів. Однак
трапляється, що два результати добре
узгоджуються між собою, а третій
відрізняється від двох попередніх. У
таких випадках виникає бажання відкинути
сумнівний результат і середнє значення
обчислити за двома. Проте сумнівний
результат для 3
n
10 не треба відкидати, поки
не буде обчислений Q-тест.
Цей тест найчастіше обчислюють при 90%
імовірності, а коефіцієнт відбракування
позначають Q0,90.
Якщо досто-вірна імовірність
дорівнює 95%, то коефіцієнт відбракування
буде Q0,95.
У табл. 1.1. наведені
значення коефіцієнтів відбракування
для n
результатів, розташованих у порядку
зростання.
Часто,
аналізуючи зразки, проводять лише три
паралельні досліди. Щоб одержати
оптимальний результат аналізу,
використовують середнє арифме-тичне
значення з трьох результатів. Однак
трапляється, що два результати добре
узгоджуються між собою, а третій
відрізняється від двох попередніх. У
таких випадках виникає бажання відкинути
сумнівний результат і середнє значення
обчислити за двома. Проте сумнівний
результат для 3
n
10 не треба відкидати, поки
не буде обчислений Q-тест.
Цей тест найчастіше обчислюють при 90%
імовірності, а коефіцієнт відбракування
позначають Q0,90.
Якщо досто-вірна імовірність
дорівнює 95%, то коефіцієнт відбракування
буде Q0,95.
У табл. 1.1. наведені
значення коефіцієнтів відбракування
для n
результатів, розташованих у порядку
зростання.
Таблиця 1.1. Значення коефіцієнтів відбракування для n результатів та формули для обчислення сумнівних результатів за Q-тестом
-
Сумнівний результат
Формула
n
Q0,95
Найменше значення Xi
Найбільше значення Xi
Qексп =

Qексп =
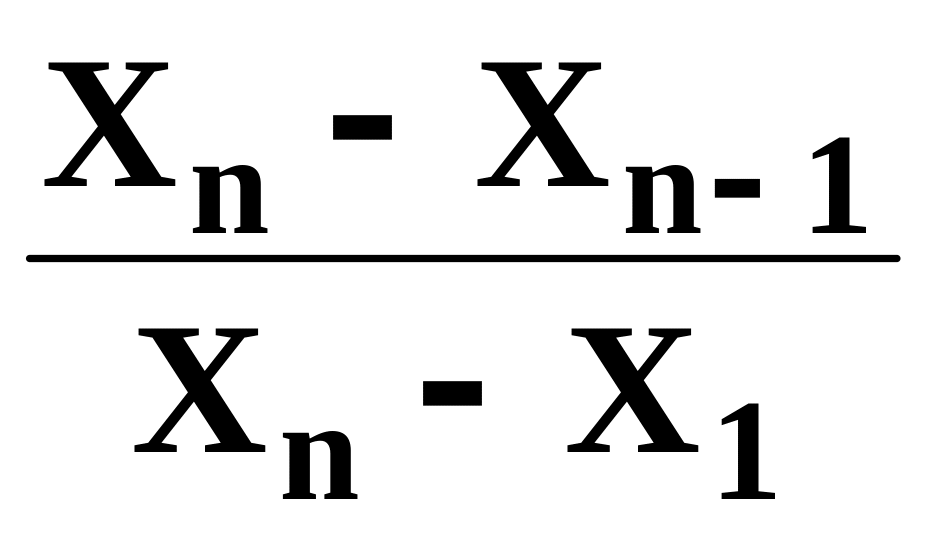
3
4
5
6
7
8
9
10
0,94
0,77
0,64
0,56
0,51
0,48
0,44
0,42
Для виявлення сумнівного результату (промаху) обчислюють значення Q як частку від ділення різниці сумнівного результату і сусіднього з ним на різницю найбільшого та найменшого результатів (діапазон значень). Відповідні формули наведено в табл. 1.1. Якщо одержане число більше або дорівнює зна-ченню, наведеному у табл. 1.1, тобто Qексп Q0,95, то цей результат відкидають. У випадку, коли одержали лише три результати, а один із них відкинули, треба виконати додаткове визначення, оскільки обчислювати середнє арифметичне за двома значеннями некоректно.
Q-тест використовують, коли n 3. Спочатку перевіряють найменше значення, а потім найбільше.
Приклад. Виконали три паралельні визначення і з’ясували, що вміст ком-понента у зразку становить 30,13; 30,20; 31,23%. Необхідно визначити, який із результатів можна відкинути. Використовуючи Q-тест, найменший результат зберігають. Для найбільшого значення (31,23%) обчислюють частку Q:
Qексп
=
![]()
![]() =0,94.
=0,94.
Отримане значення Q дорівнює табличному Q0,95 (табл. 1.1), отже, сум-нівний результат треба відкинути та провести додатковий аналіз.
1.2. Обробка результатів аналізу методами математичної статистики
Статистично можна обробити як вимірювані значення, так і результати. Числові значення, які використовують у статистичній обробці, називають варіантами і позначають символом X. Якщо обробляти n варіант, то можна обчислити середнє значення
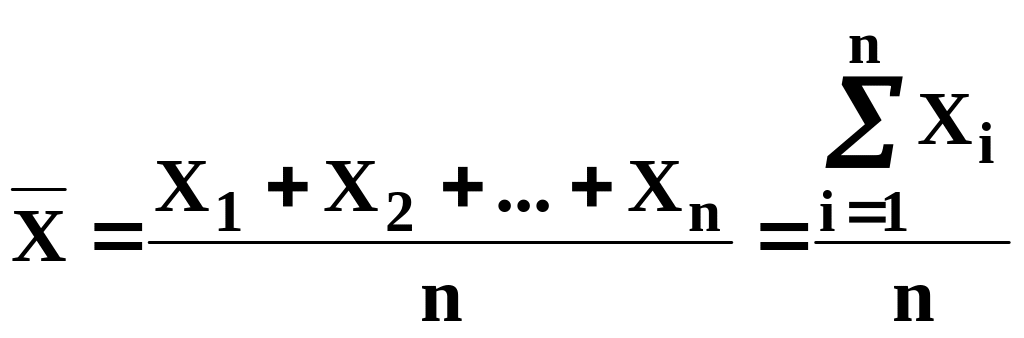 , (1.2)
, (1.2)
дисперсія
для n
варіант
S2
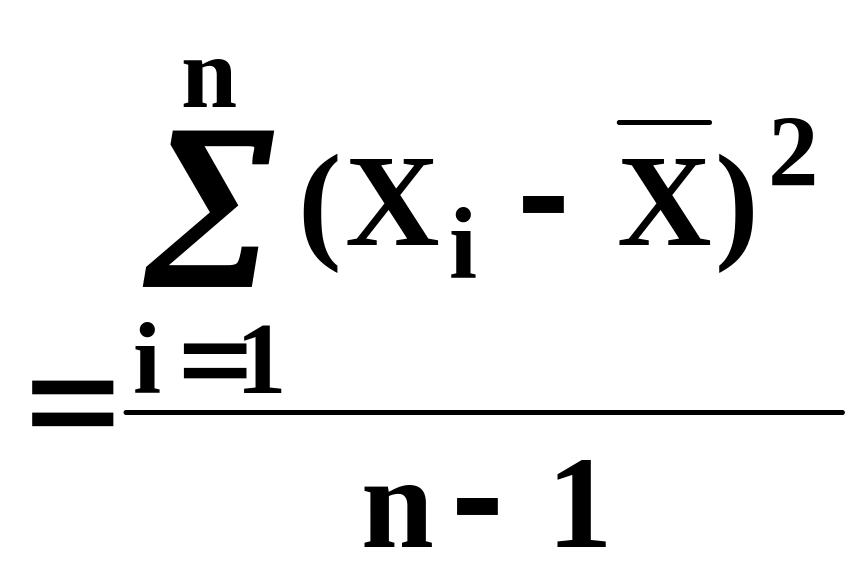 , (1.3)
, (1.3)
cтандартне
відхилення
S
=
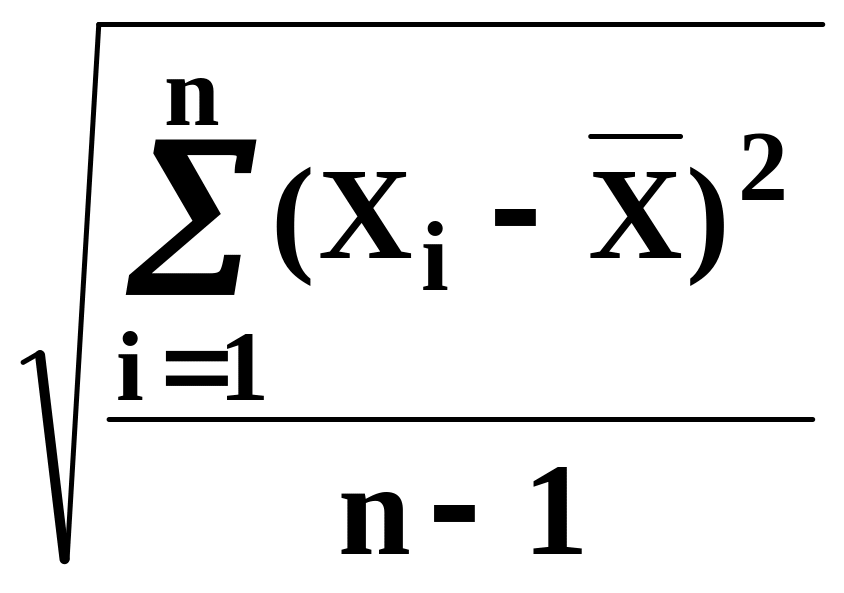 . (1.4)
. (1.4)
Дисперсія і стандартне відхилення характеризують точність методу, тобто розсіювання окремих варіант (виміряних значень чи результатів) відносно середнього арифметичного.
Якщо систематичної похибки нема, то дуже важко передбачити, в яких межах найбільш імовірна відповідність середнього значення істинному . Імовірність такого допущення не може становити 100%, а повинна мати якусь частку ризику () або достовірну імовірність (100100). Межі, передбачені для визначення імовірності, називаються достовірними. Найчастіше приймають, що дорівнює 0,90, 0,95 або 0,99. Наприклад, якщо = 0,95, то це означає, що із 100 результатів лише п’ять не укладаються в достовірні межі.
Достовірні межі визначають за розподілом Стьюдента t. Константа t залежить від частки ризику і числа ступенів свободи f, f = n 1. Значення t знаходять у табл. 1.2.
Істинне значення для цих достовірних меж обчислюють за формулою
![]() .
(1.5)
.
(1.5)
Таблиця 1.2. Значення коефіцієнтів Стьюдента t при різних значеннях імовір-ності та різних ступенях свободи f
-
f = n 1
0,90
0,95
0,99
1
6,31
12,71
63,66
2
2,92
4,30
9,92
3
2,35
3,18
5,84
4
2,13
2,78
4,60
5
2,01
2,56
4,03
6
1,94
2,45
3,71
7
1,89
2,36
3,50
Часто
доводиться порівнювати дані, одержані
декількома методами, які характеризуються
різною дисперсією. Потрібно з’ясувати,
чи можна їх об’єд-нати
між собою. Для цього використовують
F-критерій
(коефіцієнт Фішера), який
обчислюють за формулою (де
![]()
![]() )
)
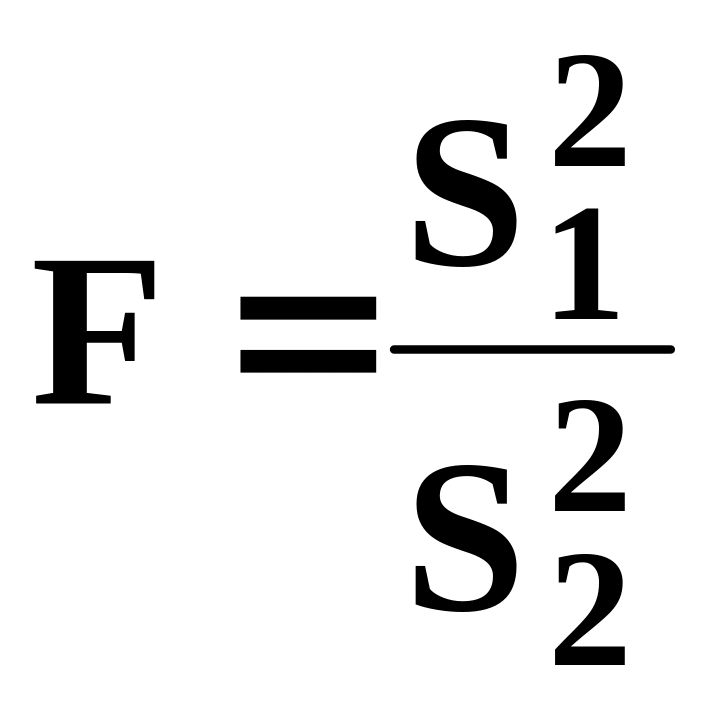 . (1.6)
. (1.6)
Значення F (табл. 1.3) залежить від числа ступенів свободи f1 і f2 для двох дисперсій відповідно.
Таблиця 1.3. Значення коефіцієнта Фішера F при 95% імовірності
-
f2
f1
2
3
4
5
6
2
19,00
19,16
19,25
19,30
19,33
3
9,55
9,28
9,12
9,01
8,94
4
6,94
6,59
6,39
6,26
6,16
5
5,79
5,41
5,19
5,05
4,95
6
5,14
4,76
4,53
4,39
4,28
Обчислюють
Fексп
за формулою (1.6) і зіставляють його з
Fтабл
для певного значення .
Якщо Fексп
Fтабл,
то розбіжність між дисперсіями
![]() і
незнач-на. На підставі цих даних можна
оцінити розбіжність між середніми
і
незнач-на. На підставі цих даних можна
оцінити розбіжність між середніми
![]() і
і
![]() .
Для цього обчислюють середнє значення
двох дисперсій і tексп:
.
Для цього обчислюють середнє значення
двох дисперсій і tексп:
![]() , (1.7)
, (1.7)
tексп= . (1.8)
. (1.8)
Одержані значення tексп зіставляють з tтабл при 99% імовірності і f =n1 + n2 2. Якщо tтабл tексп, то вважають, що X1-X2 = 0. Отже, отримані результати (n1+n2) відображають істинне значення і всі результати розглядають як ряд з n1+n2 варіант.