

4. Ускорение вычислений.
Ускорение достигается за счёт одновременного вычисления правых частей, за счёт одновременного вычисления прогнозируемых значений параметров, за счёт одновременного вычисления прогнозируемых правых частей и одновременного вычисления новых параметров. Потери времени происходят на 3 и 4 этапах за счёт пересылок. Потери точности при таком алгоритме и правильном выборе шага не происходит.
Size = n+1
Действие Rank |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
0 |
|
R1 □□□□ |
|
R2 □□□□ |
|
R3 □□□□ |
|
|
Xk+1 □□□□ |
tk+1=tk+t |
tk+1≤tmax |
Печать Xk+1
|
1 |
|
|
|
|
|
|
|
|
|
tk+1=tk+t |
tk+1≤tmax |
|
2 |
|
|
|
|
|
|
|
|
|
tk+1=tk+t |
tk+1≤tmax |
|
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
Size -1 |
|
|
|
|
|
|
|
|
|
tk+1=tk+t |
tk+1≤tmax |
|
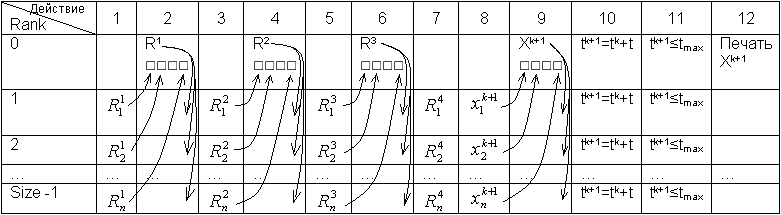
4. Ускорение и точность вычислений.
Ускорение достигается за счёт одновременного вычисления коэффициентов R1 R2 R3 R4 и Xk+1 . Потери времени за счёт пересылок. Потери точности при правильном выборе шага τ не происходит.
Пример: решить задачу Коши методом Рунге-Кутта2.
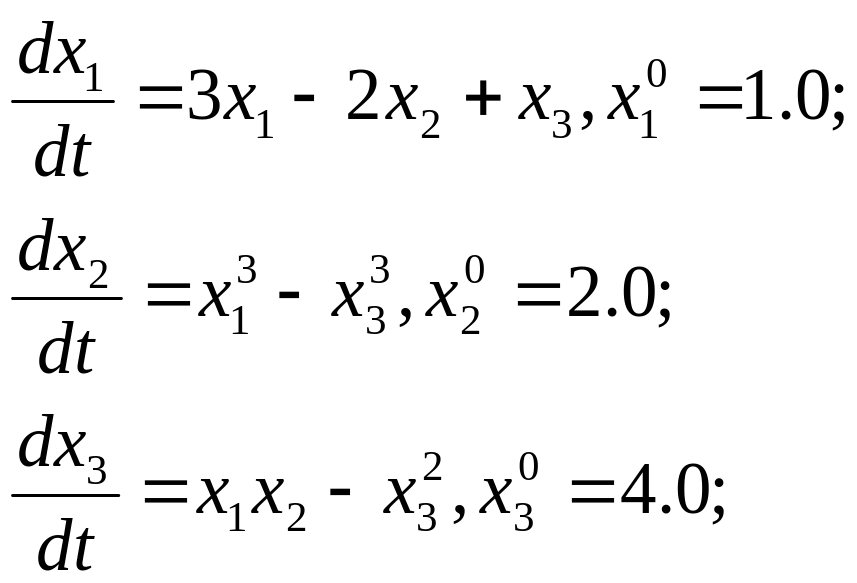
τ =0.01; t0=0.0; tmax=1.0
Size = 4
#include<stdio.h>
# include<math.h>
# include<mpi.h>
void main (inf argc, char **argv) {
MPI_Init (&argc,&argv);
int size, rank;
MPI_Comm_size (MPI_COMM_WORLD,& size);
MPI_Comm_rank (MPI_COMM_WORLD,& rank);
const int n=3;
double x[n]={1.0, 2.0, 4.0}
xx[n], f, time=0.0, tau=0.01;
tmax = 1.0;
MPI_Status status;
const int msgtag = 7;
int j = rank-1;
do {
if (!rank) {
for (int i=0; i<n; i++)
MPI_Recv (&xx[i],1, MPI_DOUBLE,i+1,msgtag, MPI_COMM_WORLD,& Status);
for (i=0; i<n; i++)
MPI_Ssend (xx, n, MPI_DOUBLE, i+1, msgtag, MPI_COMM_WORLD);
for (i=0; i<n; i++)
MPI_Recv (& x[i],1, MPI_DOUBLE,i+1,msgtag, MPI_COMM_WORLD,& Status);
for (i=0; i<n; i++)
MPI_Ssend (x, n, MPI_DOUBLE, i+1, msgtag, MPI_COMM_WORLD);
}
……….
else {
switch (rank) {
case 1: xx[j]=x[0]+tau*(3.0*x[0]-2.0*x[1]+x[2])/2.0;
break;
case 2: xx[j]=x[1]+tau*(pow(x[0],3.0)-pow (x[2],3.0))/2.0;
break;
case 3: xx[j]=x[2]+tau*(x[0]+x[1]-pow(x[2],2.0))/2.0;
break;
}
MPI_Ssend (& xx[j], 1, MPI_DOUBLE, 0, msgtag, MPI_COMM_WORLD);
MPI_Recv (xx, n, MPI_DOUBLE,0,msgtag, MPI_COMM_WORLD,& Status);
Switch (rank) {
case 1: f=3.0*xx[0] – 2.0*xx[1]+xx[2];
break;
case 2: f=pow (xx[0],3.0)-pow(x[2],3.0);
break;
case 3: f=xx[0]*xx[1]-pow()xx[2],2.0);
break;
}
x[j]+=tau*f;
MPI_Ssend (& x[j],1, MPI_DOUBLE, 0, msgtag, MPI_COMM_WORLD);
MPI_Recv (x, n, MPI_DOUBLE,0,msgtag, MPI_COMM_WORLD,& Status);
} //else
time + = tau;
} while (time <=tmax);
if (! rank) {
for (int i=0; i<n; i++)
print (“x[%d] = %7.2f’’,i,x[i]);
print (“\n”);
}
MPI_Finalize();
}