

Решение уравнений в частных производных
Решение уравнения теплопроводности в одномерном случае.
Постановка
задачи:
пусть дан тонкий однородный стержень
длины L,
уравнение распространения тепла в
стержне описывается так:
![]()

где u (x, t) – температура;
x – Координата;
t – Время;
a2>0 – коэффициент температуропроводности;
u (x, 0) = u (x, t0) = φ(x), где φ(x) – известная функция;
u
|Г1
= u
(0,t)
= ψ1(t)
=
![]()
u
|Г2
=
u
(L,t)
= ψ2(t)
=
![]()
и - известные значения.
Найти значение температуры для любого момента времени t>t0 u(x,t) для любых t>t0
Расчётные формулы:
Метод расчётных сеток
xi±1xi±h;
tk+1τ=tk+ τ;
u(x,t)~![]()
= u (xi,tk);
по оси x n-точек
неустойчивая
схема
Условие
устойчивости:
![]()
Алгоритм распараллеливания. Воспользуемся геометрическим видом параллелизма. Весь стержень разобьём на примерно равные части, число которых равно числу используемых процессов. Пусть L – длина стержня, size – число процессов.
int N = (int) (L/h)+ 1;
int l1 = (int) (N/size);
int l2 = N%size; // остаток от деления
size = 3; N=14;

rank |
l1 |
l2 |
0 |
4 |
2 |
1 |
4 |
2 |
2 |
4 |
2 |
if (l2) {
if (rank == size -1) l1 ++;
l2 --;
}
if (l2) if (rank <l2) l1 ++;
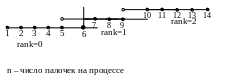
n = l1
0 1 2 3 4 5
if ((rank ==0)//(rank ==size-1))
n++;else n+=2;
В начальный момент времени начальное значение температур известны на всех процессах, причём учитываются дополнительные точки.
Определим значения в граничных точках. Организуем цикл по времени от t0 до tmax с шагом τ. На каждой итерации будет выполняться:
все процессы одновременно вычисляют значения температур в своих внутренних точках. Значения записываются в некоторый вспомогательный массив;
все процессы одновременно переписывают значения из вспомогательного массива в основной массив для внутренних точек.
Все процессы получают значение в своих граничных точках от соседних процессов, для которых эти точки являются внутренними.
if (rank % 2) { // нечётные процессы
MPI_Send (& u[1],1, MPI_DOUBLE, rank-1, msgtag, MPI_COMM_WORLD);
MPI_Recv (& u[0], 1, MPI_DOUBLE,rank-1,msgtag, MPI_COMM_WORLD,& Status);
if (rank ! = size -1) {
MPI_Send (& u[n-2],1, MPI_DOUBLE, rank+1, msgtag, MPI_COMM_WORLD);
MPI_Recv (& u[n-1], 1, MPI_DOUBLE,rank+1,msgtag, MPI_COMM_WORLD,& Status);
}
}
else { // чётные процессы
if (rank ! = size -1) {
MPI_Recv (& u[n-1], 1, MPI_DOUBLE,rank+1,msgtag, MPI_COMM_WORLD,& Status);
MPI_Send (& u[n-2],1, MPI_DOUBLE, rank+1, msgtag, MPI_COMM_WORLD);
if (rank) {
MPI_Recv (& u[0], 1, MPI_DOUBLE,rank-1,msgtag, MPI_COMM_WORLD,& Status);
MPI_Send (& u[1],1, MPI_DOUBLE, rank-1, msgtag, MPI_COMM_WORLD);
}
}
Нулевой процесс и последний процесс определяют значение на левой и правой границе соответственно.
все процессы делают шаг по времени;
все процессы проверят условия окончания итерационного процесса. Если процесс не закончен то пункт 1, иначе пункт – 6;
все процессы последовательно печатают вычисленные значения. Нумерация элементов массива сквозная и дополнительные точки не учитываются.
Пример последовательной распечатки:
if (! rank) {
for (i=0; i<n-1; i++)
print f (“u[%d] = %2.8f\n”,i,u[i]);
l=n-1;
MPI_Ssend (& l,1, MPI_Int,1, msgtag, MPI_COMM_WORLD);
}
else {
MPI_Recv (&l, 1, MPI_Int,rank-1,msgtag, MPI_COMM_WORLD,& Status);
for (i=1; i<n-1;i++, l++)
printf (“u[%d] = %2.8f\n”,l,u[i]);
if (rank ! = size -1)
MPI_Ssend (& l,1, MPI_Int,rank+1, msgtag, MPI_COMM_WORLD);
else
printf (“u[%d] = %2.8f\n”,l,u[n-1]);
}
Ускорение вычислений достигается за счёт одновременного вычисления всеми процессами новых температур во внутренних точках, но потеря времени при передаче. Передача осуществляется за 4 такта.
При данном алгоритме распараллеливания потери точности не происходит.