

4.2 Статистические методы анализа информации.
Статистические ме́тоды — методы анализа статистических данных. Выделяют методы прикладной статистики, которые могут применяться во всех областях научных исследований и любых отраслях народного хозяйства, и другие статистические методы, применимость которых ограничена той или иной сферой. Имеются в виду такие методы, как статистический приемочный контроль, статистическое регулирование технологических процессов, надежность и испытания, планирование экспериментов.
Статистические методы анализа данных применяются практически во всех областях деятельности человека. Их используют всегда, когда необходимо получить и обосновать какие-либо суждения о группе (объектов или субъектов) с некоторой внутренней неоднородностью. Целесообразно выделить три вида научной и прикладной деятельности в области статистических методов анализа данных (по степени специфичности методов, сопряженной с погруженностью в конкретные проблемы):
а) разработка и исследование методов общего назначения, без учета специфики области применения;
б) разработка и исследование статистических моделей реальных явлений и процессов в соответствии с потребностями той или иной области деятельности;
в) применение статистических методов и моделей для статистического анализа конкретных данных.
Дисперсионный анализ. Дисперсионный анализ (от латинского Dispersio – рассеивание / на английском Analysis Of Variance - ANOVA) применяется для исследования влияния одной или нескольких качественных переменных (факторов) на одну зависимую количественную переменную (отклик).В основе дисперсионного анализа лежитпредположение о том, что одни переменные могут рассматриваться как причины (факторы, независимые переменные), а другие как следствия (зависимые переменные). Независимые переменные называют иногдарегулируемыми факторамиименно потому, что в эксперименте исследователь имеет возможность варьировать ими и анализировать получающийся результат.
Основной цельюдисперсионного анализа (ANOVA) является исследование значимости различия между средними с помощью сравнения (анализа) дисперсий. Разделение общей дисперсии на несколько источников, позволяет сравнить дисперсию, вызванную различием между группами, с дисперсией, вызванной внутригрупповой изменчивостью. При истинности нулевой гипотезы (о равенстве средних в нескольких группах наблюдений, выбранных из генеральной совокупности), оценка дисперсии, связанной с внутригрупповой изменчивостью, должна быть близкой к оценке межгрупповой дисперсии. Если вы просто сравниваете средние в двух выборках, дисперсионный анализ даст тот же результат, что и обычный t-критерий для независимых выборок (если сравниваются две независимые группы объектов или наблюдений) или t-критерий для зависимых выборок (если сравниваются две переменные на одном и том же множестве объектов или наблюдений).
Сущность дисперсионного анализазаключается в расчленении общей дисперсии изучаемого признака на отдельные компоненты, обусловленные влиянием конкретных факторов, и проверке гипотез о значимости влияния этих факторов на исследуемый признак. Сравнивая компоненты дисперсии, друг с другом посредством F—критерия Фишера, можно определить, какая доля общей вариативности результативного признака обусловлена действием регулируемых факторов.
Исходным материаломдля дисперсионного анализа служат данные исследования трех и более выборок, которые могут быть как равными, так и неравными по численности, как связными, так и несвязными. По количеству выявляемых регулируемых факторов дисперсионный анализ может быть однофакторным (при этом изучается влияние одного фактора на результаты эксперимента), двухфакторным (при изучении влияния двух факторов) и многофакторным (позволяет оценить не только влияние каждого из факторов в отдельности, но и их взаимодействие).
Дисперсионный анализ относитсяк группе параметрических методов и поэтому его следует применять только тогда, когда доказано, что распределение является нормальным.
Дисперсионный анализ используют, если зависимая переменная измеряется в шкале отношений, интервалов или порядка, а влияющие переменные имеют нечисловую природу (шкала наименований).
Примеры задач. В задачах, которые решаются дисперсионным анализом, присутствует отклик числовой природы, на который воздействует несколько переменных, имеющих номинальную природу. Например, несколько видов рационов откорма скота или два способа их содержания и т.п.
Пример 1: В течение недели в трех разных местах работало несколько аптечных киосков. В дальнейшем мы можем оставить только один. Необходимо определить, существует ли статистически значимое отличие между объемами реализации препаратов в киосках. Если да, мы выберем киоск с наибольшим среднесуточным объемом реализации. Если же разница объема реализации окажется статистически незначимой, то основанием для выбора киоска должны быть другие показатели.
Пример 2: Cравнение контрастов групповых средних. Семь политических пристрастий упорядочены от крайне либеральные до крайне консервативные, и линейный контраст используется для проверки того, есть ли отличная от нуля тенденция к возрастанию средних значений по группам - т. е. есть ли значимое линейное увеличение среднего возраста при рассмотрении групп, упорядоченных в направлении от либеральных до консервативных.
Пример 3: Двухфакторный дисперсионный анализ. На количество продаж товара, помимо размеров магазина, часто влияет расположение полок с товаром. Данный пример содержит показатели недельных продаж, характеризуемые четырьмя типами расположения полок и тремя размерами магазинов. Результаты анализа показывают, что оба фактора - расположение полок с товаром и размер магазина - влияют на количество продаж, однако их взаимодействие значимым не является.
Пример 4:Одномерный ANOVA: Рандомизированный полноблочный план с двумя обработками. Исследуется влияние на припек хлеба всех возможных комбинаций трех жиров и трех рыхлителей теста. Четыре образца муки, взятые из четырех разных источников, служили в качестве блоковых факторов. Необходимо выявить значимость взаимодействия жир-рыхлитель. После этого определить различные возможности выбора контрастов, позволяющих выяснить, какие именно комбинации уровней факторов различаются.
Пример 5: Модель иерархического (гнездового) плана со смешанными эффектами. Изучается влияние четырех случайно выбранных головок, вмонтированных в станок, на деформацию производимых стеклянных держателей катодов. (Головки вмонтированы в станок, так что одна и та же головка не может использоваться на разных станках). Эффект головки обрабатывается как случайный фактор. Статистики ANOVA показывают, что между станками нет значимых различий, но есть признаки того, что головки могут различаться. Различие между всеми станками не значимо, но для двух из них различие между типами головок значимо.
Пример 6: Одномерный анализ повторных измерений с использованием плана расщепленных делянок. Этот эксперимент проводился для определения влияния индивидуального рейтинга тревожности на сдачу экзамена в четырех последовательных попытках. Данные организованы так, чтобы их можно было рассматривать как группы подмножеств всего множества данных ("всей делянки"). Эффект тревожности оказался незначимым, а эффект попытки - значим.
Ковариационный анализ.Ковариационный анализ — совокупность
методов математической статистики,
относящихся к анализу моделей зависимости
среднего значения некоторой случайной
величины![]() одновременно от набора (основных)
качественных факторов
одновременно от набора (основных)
качественных факторов![]() и (сопутствующих) количественных факторов
и (сопутствующих) количественных факторов![]() .
ФакторыFзадают сочетания
условий, при которых были получены
наблюденияX,Y,
и описываются с помощью ндикаторных
переменных, причем среди сопутствующих
и индикаторных переменных могут быть
как случайные, так и неслучайные
(контролируемые в эксперименте).
.
ФакторыFзадают сочетания
условий, при которых были получены
наблюденияX,Y,
и описываются с помощью ндикаторных
переменных, причем среди сопутствующих
и индикаторных переменных могут быть
как случайные, так и неслучайные
(контролируемые в эксперименте).
Если случайная величина Yявляется вектором, то говорят о многомерном ковариационном анализе.
Ковариационный анализ часто применяютперед дисперсионным анализом, чтобы проверить гомогенность (однородность, представительность) выборки наблюденийX,Yпо всем сопутствующим факторам.
Примеры задач
Пример 1: Пусть у нас имеется 3 метода обучения арифметики и группа студентов. Группа разбивается случайным образом на 3 подгруппы для обучения одним из методов. В конце курса обучения студенты проходят общий тест, по результатам которого выставляются оценки. Также для каждого студента имеется одна или несколько характеристик (количественных) их общей образованности.
Требуется проверить гипотезу об одинаковой эффективности методик обучения.
Пример 2: Для сравнения качества нескольких видов крахмала (пшеничного, картофельного …) был проведён эксперимент, в котором измерялась прочность крахмальных плёнок. Также для каждого испытания измерена толщина использовавшейся крахмальной плёнки.
Требуется проверить гипотезу об одинаковом качестве различного крахмала.
Пример 3: Пусть для нескольких различных школ были собраны отметки их учеников, полученные на общем для всех экзамене. Также для каждого из учеников известны отметки, полученные ими по другим экзаменам (например, вступительным в школу).
Требуется проверить гипотезу об одинаковом качестве образования в школах.
Постановка задачи
Основные теоретические и прикладные
проблемы ковариационного анализа
относятся к линейным моделям. В частности,
если анализируются nнаблюдений![]() сpсопутствующими
переменными
сpсопутствующими
переменными![]() ,kвозможными типами условий
эксперимента
,kвозможными типами условий
эксперимента![]() ,
то линейная модель соответствующего
ковариационного анализа задается
уравнением:
,
то линейная модель соответствующего
ковариационного анализа задается
уравнением:
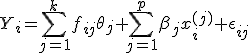
где
![]() ,
индикаторные переменные
,
индикаторные переменные![]() равны 1, если
равны 1, если![]() -е
условие эксперимента имело место при
наблюдении
-е
условие эксперимента имело место при
наблюдении![]() ,
и равны 0 в противном случае. Коэффициенты
,
и равны 0 в противном случае. Коэффициенты![]() определяют эффект влияния
определяют эффект влияния![]() -го
условия,
-го
условия,![]() — значение сопутствующей переменной
— значение сопутствующей переменной![]() ,
при котором получено наблюдение
,
при котором получено наблюдение![]() ,
,![]() — значения соответствующих коэффициентов
регрессии
— значения соответствующих коэффициентов
регрессии![]() по
по![]() ,
,![]() — независимые случайные ошибки с нулевым
математическим ожиданием.
— независимые случайные ошибки с нулевым
математическим ожиданием.
Приведённая формула задаёт линейную
модель однофакторного ковариационного
анализа с
![]() независимыми переменными и
независимыми переменными и![]() уровнями фактора. При включении в модель
дополнительных факторов в правой части
уравнения появятся слагаемые, отвечающие
за эффекты уровней вновь введённых в
модель факторов.
уровнями фактора. При включении в модель
дополнительных факторов в правой части
уравнения появятся слагаемые, отвечающие
за эффекты уровней вновь введённых в
модель факторов.
Замечание: коэффициенты регрессии в приведённой формуле не зависят от качественных факторов. Это включает предположение, что линейная зависимость имеет одинаковые коэффициенты для каждого значения качественного фактора.
Основное назначение ковариационного
анализа — использование в построении
статистических оценок
![]() ;
;![]() и статистических критериев для проверки
различных гипотез относительно значений
этих параметров. Если в модели постулировать
априори
и статистических критериев для проверки
различных гипотез относительно значений
этих параметров. Если в модели постулировать
априори![]() ,
то получится модель дисперсионного
анализа, если же исключить влияние
неколичественных факторов (положить
,
то получится модель дисперсионного
анализа, если же исключить влияние
неколичественных факторов (положить![]() ),
то получится модель регрессионного
анализа.
),
то получится модель регрессионного
анализа.
Корреляционный и регрессивный анализ.Матрица данных. Многие объекты исследования характеризуются множеством параметров, и по результатам наблюдения за их функционированием формируются многомерные совокупности (матрицы) ЭД.

(4.1)
Строки такой матрицы соответствуют результатам регистрации всех наблюдаемых параметров объекта в одном эксперименте, а столбцы содержат результаты наблюдений за одним параметром (фактором, вариантой) во всех экспериментах. Обозначим количество параметров через m(m>1), а количество наблюдений – черезn.
В матрице элемент хij соответствует значению j-й варианты в i-м наблюдении. Матрица, вообще говоря, может содержать пустые значения некоторых элементов, например, из-за пропусков в регистрации значений параметров. В многомерном анализе желательно устранить пропущенные значения. Для этого существуют специальные приемы, в частности, вычеркивание соответствующих строк матрицы или занесение средних значений вместо отсутствующих. В дальнейшем будем считать, что матрица не содержит пустых элементов, а параметры объекта характеризуются непрерывными случайными величинами.
Методы обработки матрицы ЭД основаны на следующем предположении: если объект подвергнуть новому обследованию и получить, вообще говоря, другую матрицу данных, то после ее обработки с помощью тех же методов будут получены результаты, близкие к результатам обработки первой матрицы. Данное предположение основано на статистической гипотезе формирования матрицы ЭД. Матрица порождается случайным образом в соответствии с определенной вероятностной закономерностью, а именно: в m-мерном пространстве параметров существует некоторое (пусть и неизвестное) распределение вероятностей, и каждая строка матрицы появляется в соответствии с этим распределением независимо от появления других строк.
Каждый столбец матрицы представляет собой случайную выборку значений одного параметра объекта. Указанное предположение означает, во-первых, что оценки моментов и параметров распределения, вычисленные по выборке, будут близки к истинным значениям, во-вторых, значения непрерывных функций, построенных по этим оценкам, будут близки к значениям функций, построенным по истинным значениям параметров.
Таким образом, объектом исследования в многомерном анализе является многомерная случайная величина, представленная выборкой конечного объема. К такой выборке применимы все методы и оценки, рассмотренные при обработке одномерных ЭД. Конечно, приведенные суждения не являются доказательством допустимости применения рассматриваемых методов, но вполне подтверждаются практикой.
Параметры, характеризующие объект исследования, имеют разный физический смысл, и матрица данных существенно изменяется, если изменяются шкалы, в которых измеряются те или иные параметры. Матрицу данных еще до проведения анализа целесообразно привести к стандартному виду, т.е. стандартизовать значения вариант (напомним, что среднее значение стандартизованной варианты равно нулю, дисперсия – единице). В тех случаях, когда все варианты измеряются в одной шкале, это преобразование все-таки желательно, ибо оно упрощает последующие преобразования. Стандартизованную матрицу будем обозначать через U. Переход от исходной к стандартизованной матрице осуществляется следующим образом:
вычисляются оценки математического
ожидания
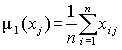 и дисперсии
и дисперсии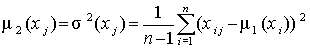 каждой варианты
каждой варианты![]() ;
;
вычисляются элементы стандартизованной матрицы
![]()
![]() ,
,![]() .
.
Элементы матрицы U являются безразмерными величинами. Именно матрица U будет являться объектом последующей обработки.
Корреляционный анализ.Величины, характеризующие различные свойства объектов, могут быть независимыми или взаимосвязанными. Различают два вида зависимостей между величинами (факторами): функциональную и статистическую.
При функциональной зависимостидвух величин значению одной из них обязательно соответствует одно или несколько точно определенных значений другой величины. Функциональная связь двух факторов возможна лишь при условии, что вторая величина зависит только от первой и не зависит ни от каких других величин. Функциональная связь одной величины с множеством других возможна, если эта величина зависит только от этого множества факторов. В реальных ситуациях существует бесконечно большое количество свойств самого объекта и внешней среды, влияющих друг на друга, поэтому такого рода связи не существуют, иначе говоря, функциональные связи являются математическими абстракциями. Их применение допустимо тогда, когда соответствующая величина в основном зависит от соответствующих факторов.
При исследовании АСОИУ многие параметры следует считать случайными, что исключает проявление однозначного соответствия значений. Воздействие общих факторов, наличие объективных закономерностей в поведении объектов приводят лишь к проявлению статистической зависимости. Статистической называют зависимость, при которой изменение одной из величин влечет изменение распределения других (другой), и эти другие величины принимают некоторые значения с определенными вероятностями. Функциональную зависимость в таком случае следует считать частным случаем статистической: значению одного фактора соответствуют значения других факторов с вероятностью, равной единице. Однако на практике такое рассмотрение функциональной связи применения не нашло.
Более важным частным случаем статистической зависимости является корреляционная зависимость, характеризующая взаимосвязь значений одних случайных величин со средним значением других, хотя в каждом отдельном случае любая взаимосвязанная величина может принимать различные значения.
Если же у взаимосвязанных величин вариацию имеет только одна переменная, а другая является детерминированной, то такую связь называют не корреляционной, а регрессионной. Например, при анализе скорости обмена с жесткими дисками можно оценивать регрессию этой характеристики на определенные модели, но не следует говорить о корреляции между моделью и скоростью.
При исследовании зависимости между одной величиной и такими характеристиками другой, как, например, моменты старших порядков (а не среднее значение), то эта связь будет называться статистической, а не корреляционной.
Корреляционная связь описывает следующие виды зависимостей:
- причинную зависимостьмежду значениями параметров. Примером такой зависимости является взаимосвязь пропускной способности канала передачи данных и соотношения сигнал/шум (на пропускную способность влияют и другие факторы – характер помех, амплитудно-частотные характеристики канала, способ кодирования сообщений и др.). Установить однозначную связь между конкретными значениями указанных параметров не удается. Но очевидно, что пропускная способность зависит от соотношения уровней сигнала и помех в канале. Иногда при этом причину и следствие особо не выделяют. В некоторых случаях такая корреляция является бессмысленной, например: если в качестве исходного фактора взять доходы разработчиков антивирусных программ, а за результат – количество вновь появляющихся вирусов, то можно сделать вывод, что разработчики антивирусов "стимулируют" создание вирусов;
- "зависимость" между следствиями общей причины. Подобная зависимость характерна, в частности, для скорости и безошибочности набора текста оператором (указанные факторы зависят от квалификации оператора).
Корреляционная зависимость определяется различными параметрами, среди которых наибольшее распространение получили показатели, характеризующие взаимосвязь двух случайных величин (парные показатели): корреляционный момент, коэффициент корреляции.
Оценка корреляционного момента(коэффициента ковариации) двух вариант xj и xk вычисляется по исходной матрице Х
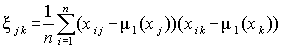
(4.2)
Этот показатель неудобен для практического применения, так как имеет размерность, равную произведению размерностей вариант, и по его величине трудно судить о зависимости параметров.
Коэффициент ковариации rjk нормированных случайных величин называют коэффициентом корреляции, его оценка
 .
.
(4.3)
Значение коэффициента корреляции лежит в пределах от –1 до +1. Если случайные величины Uj и Uk независимы, то коэффициент rjk обязательно равен нулю, обратное утверждение неверно. Коэффициент rjk характеризует значимость линейной связи между параметрами:
- при r jk =1 значения uij и uik полностью совпадают, т.е. значения параметров принимают одинаковые значения. Иначе говоря, имеет место функциональная зависимость: зная значение одного параметра, можно однозначно указать значение другого параметра;
- при r jk = – 1 величины uij и uik принимают противоположные значения. И в этом случае имеет место функциональная зависимость;
- при r jk = 0 величины uij и uik практически не связаны друг с другом линейным соотношением. Это не означает отсутствия каких-то других (например, нелинейных) связей между параметрами;
- при | r jk | > 0 и | r jk | < 1 однозначной линейной связи величин uij и uik нет. И чем меньше абсолютная величина коэффициента корреляции, тем в меньшей степени по значениям одного параметра можно предсказать значение другого.
Используя понятие коэффициента корреляции, матрице ЭД можно поставить в соответствие квадратную матрицу оценок коэффициентов корреляции (корреляционную матрицу)

(4.4)
К числу характерных свойств корреляционной
матрицы относят: симметричность
относительно главной диагонали, r jk=r
kj,
![]() ;
единичные значения элементов главной
диагонали, r kk=1 (r kk соответствует дисперсии
стандартизованного параметра uk),
;
единичные значения элементов главной
диагонали, r kk=1 (r kk соответствует дисперсии
стандартизованного параметра uk),![]() .
.
Оценка коэффициента корреляции, вычисленная по ограниченной выборке, практически всегда отличается от нуля. Но из этого еще не следует, что коэффициент корреляции генеральной совокупности также отличен от нуля. Требуется оценить значимость выборочной величины коэффициента или, в соответствии с постановкой задач проверки статистических гипотез, проверить гипотезу о равенстве нулю коэффициента корреляции. Если гипотеза Н0 о равенстве нулю коэффициента корреляции будет отвергнута, то выборочный коэффициент значим, а соответствующие величины связаны линейным соотношением. Если гипотеза Н0 будет принята, то оценка коэффициента не значима, и величины линейно не связаны друг с другом (если по физическим соображениям факторы могут быть связаны, то лучше говорить о том, что по имеющимся ЭД эта взаимосвязь не установлена). Проверка гипотезы о значимости оценки коэффициента корреляции требует знания распределения этой случайной величины. Распределение величины r ik изучено только для частного случая, когда случайные величины Uj и Uk распределены по нормальному закону.
В качестве критерия проверки нулевой
гипотезы Н0 применяют случайную величину
![]() .
Если модуль коэффициента корреляции
относительно далек от единицы, то
величина t при справедливости нулевой
гипотезы распределена по закону Стьюдента
с n – 2 степенями свободы. Конкурирующая
гипотеза Н1 соответствует утверждению,
что значение r ik не равно нулю (больше
или меньше нуля). Поэтому критическая
область двусторонняя.
.
Если модуль коэффициента корреляции
относительно далек от единицы, то
величина t при справедливости нулевой
гипотезы распределена по закону Стьюдента
с n – 2 степенями свободы. Конкурирующая
гипотеза Н1 соответствует утверждению,
что значение r ik не равно нулю (больше
или меньше нуля). Поэтому критическая
область двусторонняя.
Проверка гипотезы Н0 о равенстве нулю генерального коэффициента парной корреляции двумерной нормально распределенной случайной величины осуществляется в следующей последовательности:
- вычисляется значение статистики t;
- при уровне значимости a для двусторонней области определяется критическая точка распределения Стьюдента tкр(n–2; a ), табл. П.4;
- сравнивается значение статистики t с критическим значением tкр(n–2; a ). Если t < tкр (п–2; a ), то нет оснований отвергнуть нулевую гипотезу, иначе гипотеза Н0 отвергается (коэффициент корреляции значим).
Когда модуль величины r ik близок к единице, распределение r ik отличается от распределения Стьюдента, так как значение |r ik | ограничено справа единицей. В этом случае применяют преобразование yik=0,5ln[(1+|r ik |)/(1–|r ik |)]. Величина yik не имеет указанного ограничения, она при п > 10 распределена приблизительно нормально с центром m 1(r ik)=0,5ln[(1+|r ik|)/(1–|r ik|)]+0,5|r ik|/(n–1) и дисперсией m 2(r ik)=s 2(r ik)=1/(п–3). Если значение центрированной и нормированной величины (yik –m 1(r ik))/s (r ik) превышает значение квантили уровня 1–a /2 нормального распределения стандартизованной величины, то нулевая гипотеза отвергается.
Таким образом, постановка задачи линейного корреляционного анализаформулируется в следующем виде.
Имеется матрица наблюдений вида (4.1). Необходимо определить оценки коэффициентов корреляции для всех или только для заданных пар параметров и оценить их значимость. Незначимые оценки приравниваются к нулю. Допущения:
- выборка имеет достаточный объем. Понятие достаточного объема зависит от целей анализа, требуемой точности и надежности оценки коэффициентов корреляции, от количества факторов. Минимально допустимым считается объем, когда количество наблюдений не менее чем в 5–6 раз превосходит количество факторов;
- выборки по каждому фактору являются однородными. Это допущение обеспечивает несмещенную оценку средних величин;
- матрица наблюдений не содержит пропусков.
Если необходима проверка значимости оценки коэффициента корреляции, то требуется соблюдение дополнительного условия – распределение вариант должно подчиняться нормальному закону.
Задача анализа решается в несколько этапов:
- проводится стандартизация исходной матрицы;
- вычисляются парные оценки коэффициентов корреляции;
- проверяется значимость оценок коэффициентов корреляции, незначимые оценки приравниваются к нулю. По результатам проверки делается вывод о наличии связей между вариантами (факторами).
Пример 4.1. Результаты наблюдений за характеристиками канала представлены в табл. 4.1.
Таблица 4.1
|
№ пп |
Пропускная способность канала, кбит/с |
Соотношение сигнал/шум, |
Остаточное затухание, на частоте, Гц дБ, | ||
|
дБ |
1020 |
1800 |
2400 | ||
|
Х1 |
X2 |
X3 |
X4 |
X5 | |
|
1 |
26,37 |
41,98 |
17,66 |
16,05 |
22,85 |
|
2 |
28,00 |
43,83 |
17,15 |
15,47 |
23,25 |
|
3 |
27,83 |
42,83 |
15,38 |
17,59 |
24,55 |
|
4 |
31,67 |
47,28 |
18,39 |
16,92 |
26,59 |
|
5 |
23,50 |
38,75 |
18,32 |
15,66 |
26,22 |
|
6 |
21,04 |
35,12 |
17,81 |
17,00 |
27,52 |
|
7 |
16,94 |
32,07 |
21,42 |
16,77 |
25,76 |
|
8 |
37,56 |
54,25 |
26,42 |
15,68 |
23,10 |
|
9 |
18,84 |
32,70 |
17,23 |
15,92 |
23,41 |
|
10 |
25,77 |
40,51 |
30,43 |
15,29 |
25,17 |
|
11 |
33,52 |
49,78 |
21,71 |
15,61 |
25,39 |
|
12 |
28,21 |
43,84 |
28,33 |
15,70 |
24,56 |
|
13 |
28,76 |
44,03 |
30,42 |
16,87 |
24,45 |
|
14 |
24,60 |
39,46 |
21,66 |
15,25 |
23,81 |
|
15 |
24,51 |
38,78 |
25,77 |
16,05 |
24,48 |
Необходимо определить наличие линейных корреляционных связей между пропускной способностью и остальными факторами. Предполагается, что выборки по всем вариантам подчиняются нормальному закону. Проверку гипотезы о значимости оценок коэффициентов корреляции произвести с уровнем значимости a, равным 0,1.
Решение. Стандартизация исходной матрицы начинается с вычисления выборочной средней m1, несмещенной оценки дисперсии m2 и среднеквадратического отклонения s по каждой варианте, табл.4.2.
Таблица 4.2
|
Оценка параметра распределения |
Варианта
| ||||
|
Х1
|
X2
|
X3 |
X4
|
X5
| |
|
m 1 |
26,47 |
41,68 |
21,87 |
16,12 |
24,74 |
|
m 2 |
29,10 |
36,47 |
26,37 |
0,52 |
1,88 |
|
s |
5,39 |
6.04 |
5,13 |
0,72 |
1,37 |
В результате перехода к величинам
![]() формируется стандартизованная матрица
исходных данных, табл. 4.3.
формируется стандартизованная матрица
исходных данных, табл. 4.3.
Таблица 4.3
|
№ пп |
Пропускная способность |
Соотношение сигнал/шум, |
Остаточное затухание, на частоте, Гц | ||
|
канала, кбит/с |
дБ |
1020 |
1800 |
2400 | |
|
|
U1 |
U2 |
U3 |
U4 |
U5 |
|
1 |
–0,02 |
0,05 |
–0,82 |
–0,10 |
–1,38 |
|
2 |
0,28 |
0,36 |
–0,92 |
–0,90 |
–1,09 |
|
3 |
0,25 |
0,19 |
–1,26 |
2,03 |
–0,14 |
|
4 |
0,96 |
0,93 |
–0,68 |
1,10 |
1,35 |
|
5 |
–0,55 |
–0,49 |
–0,69 |
–0,64 |
1,08 |
|
6 |
–1,01 |
–1,09 |
–0,79 |
1,21 |
2,03 |
|
7 |
–1,77 |
–1,59 |
–0,09 |
0,90 |
0,74 |
|
8 |
2,06 |
2,08 |
0,89 |
–0,61 |
–1,20 |
|
9 |
–1,42 |
–1,49 |
–0,90 |
–0,28 |
–0,97 |
|
10 |
–0,13 |
–0,19 |
1,67 |
–1,15 |
0,31 |
|
11 |
1,31 |
1,34 |
–0,03 |
–0,71 |
0,47 |
|
12 |
0,32 |
0,36 |
1,26 |
–0,58 |
–0,13 |
|
13 |
0,42 |
0,39 |
1,66 |
1,03 |
–0,21 |
|
14 |
–0,35 |
–0,37 |
–0,04 |
–1,21 |
–0,68 |
|
15 |
–0,36 |
–0,48 |
0,76 |
–0,10 |
–0,19 |
Оценки коэффициентов корреляции
 (k = 2, 3, 4) представлены в табл. 4.4. В этой
же таблице приведены значения статистик
критерия Стьюдента
(k = 2, 3, 4) представлены в табл. 4.4. В этой
же таблице приведены значения статистик
критерия Стьюдента![]() для вычисленных оценок коэффициентов
корреляции приn= 15.
для вычисленных оценок коэффициентов
корреляции приn= 15.
Таблица 4.4
|
|
X2 |
X3 |
X4 |
X5 |
|
r 1 j |
0,93 |
0,25 |
– 0,13 |
– 0,22 |
|
t |
9,12 |
0,93 |
0,47 |
0,81 |
Критическое значение tкр (n–2; a ) = tкр (13; 0,1) = 1,77. Статистика критерия больше критического значения только для r 12. Это означает, что только для указанного коэффициента оценка значима (коэффициент корреляции генеральной совокупности не равен нулю), а остальные коэффициенты следует признать равными нулю.
Корреляционная зависимость не обязательно устанавливается только для двух величин, с ее помощью можно анализировать связи между несколькими вариантами (множественная корреляция). А кроме линейной существуют и другие виды корреляции.
Регрессионный анализ. Постановка задачи. Одной из типовых задач обработки многомерных ЭД является определение количественной зависимости показателей качества объекта от значений его параметров и характеристик внешней среды. Примером такой постановки задачи является установление зависимости между временем обработки запросов к базе данных и интенсивностью входного потока. Время обработки зависит от многих факторов, в том числе от размещения искомой информации на внешних носителях, сложности запроса. Следовательно, время обработки конкретного запроса можно считать случайной величиной. Но вместе с тем, при увеличении интенсивности потока запросов следует ожидать возрастания его среднего значения, т.е. считать, что время обработки и интенсивность потока запросов связаны корреляционной зависимостью.
Постановка задачи регрессионного анализаформулируется следующим образом. Имеется совокупность результатов наблюдений вида (4.1). В этой совокупности один столбец соответствует показателю, для которого необходимо установить функциональную зависимость с параметрами объекта и среды, представленными остальными столбцами. Будем обозначать показатель через y* и считать, что ему соответствует первый столбец матрицы наблюдений. Остальные т–1 (m > 1) столбцов соответствуют параметрам (факторам) х2, х3, …, хт .
Требуется: установить количественную взаимосвязь между показателем и факторами. В таком случае задача регрессионного анализа понимается как задача выявления такой функциональной зависимости y* = f(x2 , x3 , …, xт), которая наилучшим образом описывает имеющиеся экспериментальные данные. Допущения:
- количество наблюдений достаточно для проявления статистических закономерностей относительно факторов и их взаимосвязей;
- обрабатываемые ЭД содержат некоторые ошибки (помехи), обусловленные погрешностями измерений, воздействием неучтенных случайных факторов;
- матрица результатов наблюдений является единственной информацией об изучаемом объекте, имеющейся в распоряжении перед началом исследования.
Функция f(x2 , x3 , …, xт), описывающая зависимость показателя от параметров, называется уравнением (функцией) регрессии. Термин "регрессия" (regression (лат.) – отступление, возврат к чему-либо) связан со спецификой одной из конкретных задач, решенных на стадии становления метода, и в настоящее время не отражает всей сущности метода, но продолжает применяться.
Решение задачи регрессионного анализа целесообразно разбить на несколько этапов:
- предварительная обработка ЭД;
- выбор вида уравнений регрессии;
- вычисление коэффициентов уравнения регрессии;
- проверка адекватности построенной функции результатам наблюдений.
Предварительная обработка включает стандартизацию матрицы ЭД, расчет коэффициентов корреляции, проверку их значимости и исключение из рассмотрения незначимых параметров (эти преобразования были рассмотрены в рамках корреляционного анализа). В результате преобразований будут получены стандартизованная матрица наблюдений U (через y будем обозначать стандартизованную величину y*) и корреляционная матрица r .
Стандартизованной матрице U можно сопоставить одну из следующих геометрических интерпретаций:
в m-мерном пространстве оси соответствуют отдельным параметрам и показателю. Каждая строка матрицы представляет вектор в этом пространстве, а вся матрица – совокупностьnвекторов в пространстве параметров;
в n-мерном пространстве
оси соответствуют результатам отдельных
наблюдений. Каждый столбец матрицы –
вектор в пространстве наблюдений. Все
вектора в этом пространстве имеют
одинаковую длину, равную![]() .
Тогда угол между двумя векторами
характеризует взаимосвязь соответствующих
величин. И чем меньше угол, тем теснее
связь (тем больше коэффициент корреляции).
.
Тогда угол между двумя векторами
характеризует взаимосвязь соответствующих
величин. И чем меньше угол, тем теснее
связь (тем больше коэффициент корреляции).
В корреляционной матрице особую роль играют элементы левого столбца – они характеризуют наличие или отсутствие линейной зависимости между соответствующим параметром ui (i =2, 3, …, т) и показателем объекта y. Проверка значимости позволяет выявить такие параметры, которые следует исключить из рассмотрения при формировании линейной функциональной зависимости, и тем самым упростить последующую обработку.
Выбор вида уравнения регрессии. Задача определения функциональной зависимости, наилучшим образом описывающей ЭД, связана с преодолением ряда принципиальных трудностей. В общем случае для стандартизованных данных функциональную зависимость показателя от параметров можно представить в виде
y = f(u1, u2, ...up) + e
(4.5)
где f – заранее не известная функция, подлежащая определению;
e - ошибка аппроксимации ЭД.
Указанное уравнение принято называть выборочным уравнением регрессии y на u. Это уравнение характеризует зависимость между вариацией показателя и вариациями факторов. А мера корреляции измеряет долю вариации показателя, которая связана с вариацией факторов. Иначе говоря, корреляцию показателя и факторов нельзя трактовать как связь их уровней, а регрессионный анализ не объясняет роли факторов в создании показателя.
Еще одна особенность касается оценки степени влияния каждого фактора на показатель. Регрессионное уравнение не обеспечивает оценку раздельного влияния каждого фактора на показатель, такая оценка возможна лишь в случае, когда все другие факторы не связаны с изучаемым. Если изучаемый фактор связан с другими, влияющими на показатель, то будет получена смешанная характеристика влияния фактора. Эта характеристика содержит как непосредственное влияние фактора, так и опосредованное влияние, оказанное через связь с другими факторами и их влиянием на показатель.
В регрессионное уравнение не рекомендуется включать факторы, слабо связанные с показателем, но тесно связанные с другими факторами. Не включают в уравнение и факторы, функционально связанные друг с другом (для них коэффициент корреляции равен 1). Включение таких факторов приводит к вырождению системы уравнений для оценок коэффициентов регрессии и к неопределенности решения.
Функция f должна подбираться так, чтобы ошибка e в некотором смысле была минимальна. Существует бесконечное множество функций, описывающих ЭД абсолютно точно (e = 0), т.е. таких функций, которые для всех значений параметров uj,2 , uj,3 , …, uj,т принимают в точности соответствующие значения показателя yi , i =1, 2, …, п. Вместе с тем, для всех других значений параметров, отсутствующих в результатах наблюдений, значения показателя могут принимать любые значения. Понятно, что такие функции не соответствуют действительной связи между параметрами и показателем.
В целях выбора функциональной связи заранее выдвигают гипотезу о том, к какому классу может принадлежать функция f, а затем подбирают "лучшую" функцию в этом классе. Выбранный класс функций должен обладать некоторой "гладкостью", т.е. "небольшие" изменения значений аргументов должны вызывать "небольшие" изменения значений функции (ЭД содержат некоторые ошибки измерений, а само поведение объекта подвержено влиянию помех, маскирующих истинную связь между параметрами и показателем).
Простым, удобным для практического применения и отвечающим указанному условию является класс полиномиальных функций
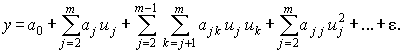
(4.6)
Для такого класса задача выбора функции сводится к задаче выбора значений коэффициентов a0 , aj , ajk , …, ajj , … . Однако универсальность полиномиального представления обеспечивается только при возможности неограниченного увеличения степени полинома, что не всегда допустимо на практике, поэтому приходится применять и другие виды функций.
Частным случаем, широко применяемым на практике, является полином первой степени или уравнение линейной регрессии
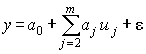
(4.7)
Это уравнение в регрессионном анализе следует трактовать как векторное, ибо речь идет о матрице данных,
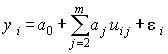 ,i =1, 2, … , n.
,i =1, 2, … , n.
(4.8)
Обычно стремятся обеспечить такое количество наблюдений, которое превышало бы количество оцениваемых коэффициентов модели. Для линейной регрессии при п > т количество уравнений превышает количество подлежащих определению коэффициентов полинома. Но и в этом случае нельзя подобрать коэффициенты таким образом, чтобы ошибка в каждом скалярном уравнении обращалась в ноль, так как к неизвестным относятся аj и e i , их количество n + т – 1, т.е. всегда больше количества уравнений п. Аналогичные рассуждения справедливы и для полиномов степени, выше первой.
Для выбора вида функциональной зависимости можно рекомендовать следующий подход:
в пространстве параметров графически отображают точки со значениями показателя. При большом количестве параметров можно строить точки применительно к каждому из них, получая двумерные распределения значений;
- по расположению точек и на основе анализа сущности взаимосвязи показателя и параметров объекта делают заключение о примерном виде регрессии или ее возможных вариантах;
- после расчета параметров оценивают качество аппроксимации, т.е. оценивают степень близости расчетных и фактических значений;
- если расчетные и фактические значения близки во всей области задания, то задачу регрессионного анализа можно считать решенной. В противном случае можно попытаться выбрать другой вид полинома или другую аналитическую функцию, например периодическую.
Вычисление коэффициентов уравнения регрессии. Систему уравнений (4.8) на основе имеющихся ЭД однозначно решить невозможно, так как количество неизвестных всегда больше количества уравнений. Для преодоления этой проблемы нужны дополнительные допущения. Здравый смысл подсказывает: желательно выбрать коэффициенты полинома так, чтобы обеспечить минимум ошибки аппроксимации ЭД. Могут применяться различные меры для оценки ошибок аппроксимации. В качестве такой меры нашла широкое применение среднеквадратическая ошибка. На ее основе разработан специальный метод оценки коэффициентов уравнений регрессии – метод наименьших квадратов (МНК). Этот метод позволяет получить оценки максимального правдоподобия неизвестных коэффициентов уравнения регрессии при нормальном распределения вариант, но его можно применять и при любом другом распределении факторов. В основе МНК лежат следующие положения:
- значения величин ошибок и факторов независимы, а значит, и некоррелированы, т.е. предполагается, что механизмы порождения помехи не связаны с механизмом формирования значений факторов;
- математическое ожидание ошибки e должно быть равно нулю (постоянная составляющая входит в коэффициент a0), иначе говоря, ошибка является центрированной величиной;
- выборочная оценка дисперсии ошибки
![]() должна
быть минимальна.
должна
быть минимальна.
Рассмотрим применение МНК применительно к линейной регрессии стандартизованных величин. Для центрированных величин uj коэффициент a0 равен нулю, тогда уравнения линейной регрессии
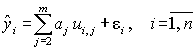 .
.
(4.9)
Здесь введен специальный знак "^", обозначающий значения показателя, рассчитанные по уравнению регрессии, в отличие от значений, полученных по результатам наблюдений.
По МНК определяются такие значения коэффициентов уравнения регрессии, которые обеспечивают безусловный минимум выражению
 .
.
(4.10)
Минимум находится приравниванием нулю всех частных производных выражения (4.10), взятых по неизвестным коэффициентам, и решением системы уравнений
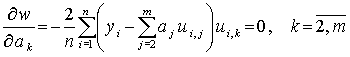
(4.11)
Последовательно проведя преобразования и используя введенные ранее оценки коэффициентов корреляции
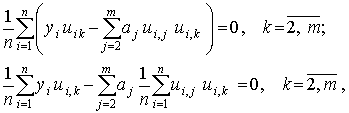
получим
.

(4.12)
Итак, получено m–1 линейных уравнений, что позволяет однозначно вычислить значения a2, a3, …, am.
Если же линейная модель неточна или параметры измеряются неточно, то и в этом случае МНК позволяет найти такие значения коэффициентов, при которых линейная модель наилучшим образом описывает реальный объект в смысле выбранного критерия среднеквадратического отклонения.
Когда имеется только один параметр,
уравнение линейной регрессии примет
вид
![]() = a2 u2 . Коэффициент a2 находится из уравнения
r y,2 – a2 r 2,2 = 0. Тогда, учитывая, что r 2,2 =
1, искомый коэффициент
= a2 u2 . Коэффициент a2 находится из уравнения
r y,2 – a2 r 2,2 = 0. Тогда, учитывая, что r 2,2 =
1, искомый коэффициент
a2 = r y,2.
(4.13)
Соотношение (4.13) подтверждает ранее высказанное утверждение, что коэффициент корреляции является мерой линейной связи двух стандартизованных параметров.
Подставив найденное значение коэффициента
a2 в выражение для w, с учетом свойств
центрированных и нормированных величин,
получим минимальное значение этой
функции, равное 1– r 2y,2. Величину 1– r
2y,2 называют остаточной дисперсией
случайной величины y относительно
случайной величины u2. Она характеризует
ошибку, которая получается при замене
показателя функцией от параметра
![]() .
Только при |r y,2 | = 1 остаточная дисперсия
равна нулю, и, следовательно, не возникает
ошибки при аппроксимации показателя
линейной функцией.
.
Только при |r y,2 | = 1 остаточная дисперсия
равна нулю, и, следовательно, не возникает
ошибки при аппроксимации показателя
линейной функцией.
Переходя от центрированных и нормированных значений показателя и параметра
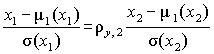 ,
,
можно получить для исходных величин
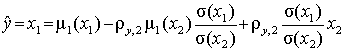 .
.
(4.14)
Это уравнение также линейно относительно коэффициента корреляции. Нетрудно заметить, что центрирование и нормирование для линейной регрессии позволяет понизить на единицу размерность системы уравнений, т.е. упростить решение задачи определения коэффициентов, а самим коэффициентам придать ясный смысл.
Применение МНК для нелинейных функцийпрактически ничем не отличается от рассмотренной схемы (только коэффициент a0 в исходном уравнении не равен нулю).
Например, пусть необходимо определить коэффициенты параболической регрессии
= a0 + a2 u2 + a22 u22.
Выборочная дисперсия ошибки
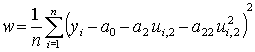 .
.
На ее основе можно получить следующую систему уравнений
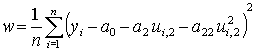
После преобразований система уравнений примет вид
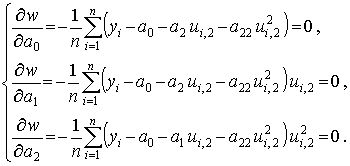
Учитывая свойства моментов стандартизованных величин, запишем
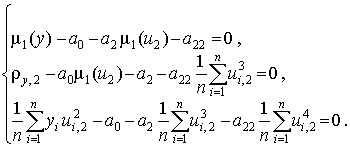
Определение коэффициентов нелинейной регрессии основано на решении системы линейных уравнений. Для этого можно применять универсальные пакеты численных методов или специализированные пакеты обработки статистических данных.
С ростом степени уравнения регрессии возрастает и степень моментов распределения параметров, используемых для определения коэффициентов. Так, для определения коэффициентов уравнения регрессии второй степени используются моменты распределения параметров до четвертой степени включительно. Известно, что точность и достоверность оценки моментов по ограниченной выборке ЭД резко снижается с ростом их порядка. Применение в уравнениях регрессии полиномов степени выше второй нецелесообразно.
Качество полученного уравнения регрессии оценивают по степени близости между результатами наблюдений за показателем и предсказанными по уравнению регрессии значениями в заданных точках пространства параметров. Если результаты близки, то задачу регрессионного анализа можно считать решенной. В противном случае следует изменить уравнение регрессии (выбрать другую степень полинома или вообще другой тип уравнения) и повторить расчеты по оценке параметров.
При наличии нескольких показателей задача регрессионного анализа решается независимо для каждого из них.
Анализируя сущность уравнения регрессии, следует отметить следующие положения. Рассмотренный подход не обеспечивает раздельной (независимой) оценки коэффициентов – изменение значения одного коэффициента влечет изменение значений других. Полученные коэффициенты не следует рассматривать как вклад соответствующего параметра в значение показателя. Уравнение регрессии является всего лишь хорошим аналитическим описанием имеющихся ЭД, а не законом, описывающим взаимосвязи параметров и показателя. Это уравнение применяют для расчета значений показателя в заданном диапазоне изменения параметров. Оно ограниченно пригодно для расчета вне этого диапазона, т.е. его можно применять для решения задач интерполяции и в ограниченной степени для экстраполяции.
Главной причиной неточности прогноза является не столько неопределенность экстраполяции линии регрессии, сколько значительная вариация показателя за счет неучтенных в модели факторов. Ограничением возможности прогнозирования служит условие стабильности неучтенных в модели параметров и характера влияния учтенных факторов модели. Если резко меняется внешняя среда, то составленное уравнение регрессии потеряет свой смысл. Нельзя подставлять в уравнение регрессии такие значения факторов, которые значительно отличаются от представленных в ЭД. Рекомендуется не выходить за пределы одной трети размаха вариации параметра, как за максимальное, так и за минимальное значения фактора.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения параметра, является точечным. Вероятность реализации такого прогноза ничтожна мала. Целесообразно определить доверительный интервал прогноза. Для индивидуальных значений показателя интервал должен учитывать ошибки в положении линии регрессии и отклонения индивидуальных значений от этой линии. Средняя ошибка прогноза показателя y для фактора х составит
![]() ,
,
где
 – средняя ошибка положения линии
регрессии в генеральной совокупности
при x = xk;
– средняя ошибка положения линии
регрессии в генеральной совокупности
при x = xk;
s 2(y)=
![]() – оценка дисперсии отклонения показателя
от линии регрессии в генеральной
совокупности;
– оценка дисперсии отклонения показателя
от линии регрессии в генеральной
совокупности;
xk – ожидаемое значение фактора.
Доверительные границы прогноза, например, для уравнения регрессии (4.14), определяются выражением y[xk] ± mош[xk].
Отрицательная величина свободного члена а0 в уравнении регрессии для исходных переменных означает, что область существования показателя не включает нулевых значений параметров. Если же а0 > 0, то область существования показателя включает нулевые значения параметров, а сам коэффициент характеризует среднее значение показателя при отсутствии воздействий параметров.
Задача 4.2.Построить уравнение регрессии для пропускной способности канала по выборке, заданной в табл. 4.1.
Решение. Применительно к указанной выборке построение аналитической зависимости в основной своей части выполнено в рамках корреляционного анализа: пропускная способность зависит только от параметра "соотношение сигнал/шум". Остается подставить в выражение (4.14) вычисленные ранее значения параметров. Уравнение для пропускной способности примет вид
= 26,47– 0,93 . 41,68 . 5,39/6,04+0,93 . 5,39/6,03 . х = – 8,121+0,830х.
Результаты расчетов представлены в табл. 4.5.
Таблица 4.5
|
№ пп |
Пропускная способность |
Соотношение сигнал/шум |
Значение функции, кбит/с |
Погрешность, кбит/с |
|
канала, кбит/с |
дБ | |||
|
Y |
X |
|
e | |
|
1 |
26,37 |
41,98 |
26,72 |
–0,35 |
|
2 |
28,00 |
43,83 |
28,25 |
–0,25 |
|
3 |
27,83 |
42,83 |
27,42 |
0,41 |
|
4 |
31,67 |
47,28 |
31,12 |
0,55 |
|
5 |
23,50 |
38,75 |
24,04 |
–0,54 |
|
6 |
21,04 |
35,12 |
21,03 |
0,01 |
|
7 |
16,94 |
32,07 |
18,49 |
–1,55 |
|
8 |
37,56 |
54,25 |
36,90 |
0,66 |
|
9 |
18,84 |
32,70 |
19,02 |
–0,18 |
|
10 |
25,77 |
40,51 |
25,50 |
0,27 |
|
11 |
33,52 |
49,78 |
33,19 |
0,33 |
|
12 |
28,21 |
43,84 |
28,26 |
–0,05 |
|
13 |
28,76 |
44,03 |
28,42 |
0,34 |
|
14 |
24,60 |
39,46 |
24,63 |
–0,03 |
|
15 |
24,51 |
38,78 |
24,06 |
0,45 |
Остаточная дисперсия стандартизованной величины Y относительно стандартизованной величины Х равна 1– 0,932 = 0,14, т.е. является малой величиной. Погрешность аппроксимации и величина остаточной дисперсии показывают высокую точность линейной модели, поэтому задачу регрессионного анализа можно считать решенной. Свободный член уравнения регрессии отрицательный, следовательно, область существования показателя не включает нулевое значение параметра "отношение сигнал/шум", что вытекает из сущности параметра (при нулевом уровне сигнала передача информации невозможна).
Дискриминантный анализ. Основная цельДискриминантный анализ используется для принятия решения о том, какие переменные различают (дискриминируют) две или более возникающие совокупности (группы). Например, некий исследователь в области образования может захотеть исследовать, какие переменные относят выпускника средней школы к одной из трех категорий: (1) поступающий в колледж, (2) поступающий в профессиональную школу или (3) отказывающийся от дальнейшего образования или профессиональной подготовки. Для этой цели исследователь может собрать данные о различных переменных, связанных с учащимися школы. После выпуска большинство учащихся естественно должно попасть в одну из названных категорий. Затем можно использовать Дискриминантный анализ для определения того, какие переменные дают наилучшее предсказание выбора учащимися дальнейшего пути.
Вычислительный подход. С вычислительной точки зрения дискриминантный анализ очень похож на дисперсионный анализ (см. раздел Дисперсионный анализ). Рассмотрим следующий простой пример. Предположим, что вы измеряете рост в случайной выборке из 50 мужчин и 50 женщин. Женщины в среднем не так высоки, как мужчины, и эта разница должна найти отражение для каждой группы средних (для переменной Рост). Поэтому переменная Рост позволяет вам провести дискриминацию между мужчинами и женщинами лучше, чем, например, вероятность, выраженная следующими словами: "Если человек большой, то это, скорее всего, мужчина, а если маленький, то это вероятно женщина".
Вы можете обобщить все эти доводы на менее "тривиальные" группы и переменные. Например, предположим, что вы имеете две совокупности выпускников средней школы - тех, кто выбрал поступление в колледж, и тех, кто не собирается это делать. Вы можете собрать данные о намерениях учащихся продолжить образование в колледже за год до выпуска. Если средние для двух совокупностей (тех, кто в настоящее время собирается продолжить образование, и тех, кто отказывается) различны, то вы можете сказать, что намерение поступить в колледж, как это установлено за год до выпуска, позволяет разделить учащихся на тех, кто собирается и кто не собирается поступать в колледж (и эта информация может быть использована членами школьного совета для подходящего руководства соответствующими студентами).
В завершение заметим, что основная идея дискриминантного анализазаключается в том, чтобы определить, отличаются ли совокупности по среднему какой-либо переменной (или линейной комбинации переменных), и затем использовать эту переменную, чтобы предсказать для новых членов их принадлежность к той или иной группе.
Дисперсионный анализ. Поставленная таким образом задача о дискриминантной функции может быть перефразирована как задача одновходового дисперсионного анализа (ANOVA). Можно спросить, в частности, являются ли две или более совокупности значимо отличающимися одна от другой по среднему значению какой-либо конкретной переменной. Для изучения вопроса о том, как можно проверить статистическую значимость отличия в среднем между различными совокупностями, вы можете прочесть раздел Дисперсионный анализ. Однако должно быть ясно, что если среднее значение определенной переменной значимо различно для двух совокупностей, то вы можете сказать, что переменная разделяет данные совокупности.
В случае одной переменной окончательный критерий значимости того, разделяет переменная две совокупности или нет, дает F-критерий. Как описано в разделах Элементарные понятия статистики и Дисперсионный анализ, F статистика по существу вычисляется, как отношение межгрупповой дисперсии к объединенной внутригрупповой дисперсии. Если межгрупповая дисперсия оказывается существенно больше, тогда это должно означать различие между средними.
Многомерные переменные. При применении дискриминантного анализа обычно имеются несколько переменных, и задача состоит в том, чтобы установить, какие из переменных вносят свой вклад в дискриминацию между совокупностями. В этом случае вы имеете матрицу общих дисперсий и ковариаций, а также матрицы внутригрупповых дисперсий и ковариаций. Вы можете сравнить эти две матрицы с помощью многомерного F-критерия для того, чтобы определить, имеются ли значимые различия между группами (с точки зрения всех переменных). Эта процедура идентична процедуре Многомерного дисперсионного анализа (MANOVA). Так же как в MANOVA, вначале можно выполнить многомерный критерий, и затем, в случае статистической значимости, посмотреть, какие из переменных имеют значимо различные средние для каждой из совокупностей. Поэтому, несмотря на то, что вычисления для нескольких переменных более сложны, применимо основное правило, заключающееся в том, что если вы производите дискриминацию между совокупностями, то должно быть заметно различие между средними. В начало
Пошаговый дискриминантный анализ Вероятно, наиболее общим применением дискриминантного анализа является включение в исследование многих переменных с целью определения тех из них, которые наилучшим образом разделяют совокупности между собой. Например, исследователь в области образования, интересующийся предсказанием выбора, который сделают выпускники средней школы относительно своего дальнейшего образования, произведет с целью получения наиболее точных прогнозов регистрацию возможно большего количества параметров обучающихся, например, мотивацию, академическую успеваемость и т.д.
Модель. Другими словами, вы хотите построить "модель", позволяющую лучше всего предсказать, к какой совокупности будет принадлежать тот или иной образец. В следующем рассуждении термин "в модели" будет использоваться для того, чтобы обозначать переменные, используемые в предсказании принадлежности к совокупности; о неиспользуемых для этого переменных будем говорить, что они "вне модели".
Пошаговый анализ с включением. В пошаговом анализе дискриминантных функций модель дискриминации строится по шагам. Точнее, на каждом шаге просматриваются все переменные, и находится та из них, которая вносит наибольший вклад в различие между совокупностями. Эта переменная должна быть включена в модель на данном шаге, и происходит переход к следующему шагу.
Пошаговый анализ с исключением. Можно также двигаться в обратном направлении, в этом случае все переменные будут сначала включены в модель, а затем на каждом шаге будут устраняться переменные, вносящие малый вклад в предсказания. Тогда в качестве результата успешного анализа можно сохранить только "важные" переменные в модели, то есть те переменные, чей вклад в дискриминацию больше остальных.
F для включения, F для исключения. Эта пошаговая процедура "руководствуется" соответствующим значением F для включения и соответствующим значением F для исключения. Значение F статистики для переменной указывает на ее статистическую значимость при дискриминации между совокупностями, то есть, она является мерой вклада переменной в предсказание членства в совокупности. Если вы знакомы с пошаговой процедурой множественной регрессии, то вы можете интерпретировать значение F для включения/исключения в том же самом смысле, что и в пошаговой регрессии.
Расчет на случай. Пошаговый дискриминантный анализ основан на использовании статистического уровня значимости. Поэтому по своей природе пошаговые процедуры рассчитывают на случай, так как они "тщательно перебирают" переменные, которые должны быть включены в модель для получения максимальной дискриминации. При использовании пошагового метода исследователь должен осознавать, что используемый при этом уровень значимости не отражает истинного значения альфа, то есть, вероятности ошибочного отклонения гипотезы H0 (нулевой гипотезы, заключающейся в том, что между совокупностями нет различия). В начало
Интерпретация функции дискриминации для двух групп Для двух групп дискриминантный анализ может рассматриваться также как процедура множественной регрессии (и аналогичная ей) С вычислительной точки зрения все эти подходы аналогичны. Если вы кодируете две группы как 1 и 2, и затем используете эти переменные в качестве зависимых переменных в множественной регрессии, то получите результаты, аналогичные тем, которые получили бы с помощью Дискриминантного анализа. В общем, в случае двух совокупностей вы подгоняете линейное уравнение следующего типа:
Группа = a + b1*x1 + b2*x2 + ... + bm*xm,
где a является константой, и b1...bm являются коэффициентами регрессии. Интерпретация результатов задачи с двумя совокупностями тесно следует логике применения множественной регрессии: переменные с наибольшими регрессионными коэффициентами вносят наибольший вклад в дискриминацию.
Дискриминантные функции для нескольких групп. Если имеется более двух групп, то можно оценить более чем одну дискриминантную функцию подобно тому, как это было сделано ранее. Например, когда имеются три совокупности, вы можете оценить: (1) - функцию для дискриминации между совокупностью 1 и совокупностями 2 и 3, взятыми вместе, и (2) - другую функцию для дискриминации между совокупностью 2 и совокупности 3. Например, вы можете иметь одну функцию, дискриминирующую между теми выпускниками средней школы, которые идут в колледж, против тех, кто этого не делает (но хочет получить работу или пойти в училище), и вторую функцию для дискриминации между теми выпускниками, которые хотят получить работу против тех, кто хочет пойти в училище. Коэффициенты b в этих дискриминирующих функциях могут быть проинтерпретированы тем же способом, что и ранее.
Канонический анализ. Когда проводится дискриминантный анализ нескольких групп, вы не должны указывать, каким образом следует комбинировать группы для формирования различных дискриминирующих функций. Вместо этого, вы можете автоматически определить некоторые оптимальные комбинации переменных, так что первая функция проведет наилучшую дискриминацию между всеми группами, вторая функция будет второй наилучшей и т.д. Более того, функции будут независимыми или ортогональными, то есть их вклады в разделение совокупностей не будут перекрываться. С вычислительной точки зрения система вы проводите анализ канонических корреляций (см. также раздел Каноническая корреляция), которые будут определять последовательные канонические корни и функции. Максимальное число функций будет равно числу совокупностей минус один или числу переменных в анализе в зависимости от того, какое из этих чисел меньше.
Интерпретация дискриминантных функций. Как было установлено ранее, вы получите коэффициенты b (и стандартизованные коэффициенты бета) для каждой переменной и для каждой дискриминантной (теперь называемой также и канонической) функции. Они могут быть также проинтерпретированы обычным образом: чем больше стандартизованный коэффициент, тем больше вклад соответствующей переменной в дискриминацию совокупностей. (Отметим также, что вы можете также проинтерпретировать структурные коэффициенты; см. ниже.) Однако эти коэффициенты не дают информации о том, между какими совокупностями дискриминируют соответствующие функции. Вы можете определить характер дискриминации для каждой дискриминантной (канонической) функции, взглянув на средние функций для всех совокупностей. Вы также можете посмотреть, как две функции дискриминируют между группами, построив значения, которые принимают обе дискриминантные функции (см., например, следующий график).

В этом примере Корень1 (root1), похоже, в основном дискриминирует между группой Setosa и объединением групп Virginic и Versicol. По вертикальной оси (Корень2) заметно небольшое смещение точек группы Versicol вниз относительно центральной линии (0).
Матрица факторной структуры. Другим способом определения того, какие переменные "маркируют" или определяют отдельную дискриминантную функцию, является использование факторной структуры. Коэффициенты факторной структуры являются корреляциями между переменными в модели и дискриминирующей функцией. Если вы знакомы с факторным анализом (см. раздел Факторный анализ), то можете рассматривать эти корреляции как факторные нагрузки переменных на каждую дискриминантную функцию.
Некоторые авторы согласны с тем, что структурные коэффициенты могут быть использованы при интерпретации реального "смысла" дискриминирующей функции. Объяснения, даваемые этими авторами, заключаются в том, что: (1) - вероятно структура коэффициентов более устойчива и (2) - они позволяют интерпретировать факторы (дискриминирующие функции) таким же образом, как и в факторном анализе. Однако последующие исследования с использованием метода Монте-Карло (Барсиковский и Стивенс (Barcikowski, Stevens, 1975); Хьюберти (Huberty, 1975)) показали, что коэффициенты дискриминантных функций и структурные коэффициенты почти одинаково нестабильны, пока значение размер выборки не станет достаточно большим (например, если число наблюдений в 20 раз больше, чем число переменных). Важно помнить, что коэффициенты дискриминантной функции отражают уникальный (частный) вклад каждой переменной в отдельную дискриминантную функцию, в то время как структурные коэффициенты отражают простую корреляцию между переменными и функциями. Если дискриминирующей функции хотят придать отдельные "осмысленные" значения (родственные интерпретации факторов в факторном анализе), то следует использовать (интерпретировать) структурные коэффициенты. Если же хотят определить вклад, который вносит каждая переменная в дискриминантную функцию, то используют коэффициенты (веса) дискриминантной функции.
Значимость дискриминантной функции. Можно проверить число корней, которое добавляется значимо к дискриминации между совокупностями. Для интерпретации могут быть использованы только те из них, которые будут признаны статистически значимыми. Остальные функции (корни) должны быть проигнорированы.
Итог. Итак, при интерпретации дискриминантной функции для нескольких совокупностей и нескольких переменных, вначале хотят проверить значимость различных функций и в дальнейшем использовать только значимые функции. Затем, для каждой значащей функции вы должны рассмотреть для каждой переменной стандартизованные коэффициенты бета. Чем больше стандартизованный коэффициент бета, тем большим является относительный собственный вклад переменной в дискриминацию, выполняемую соответствующей дискриминантной функцией. В порядке получения отдельных "осмысленных" значений дискриминирующих функций можно также исследовать матрицу факторной структуры с корреляциями между переменными и дискриминирующей функцией. В заключение, вы должны посмотреть на средние для значимых дискриминирующих функций для того, чтобы определить, какие функции и между какими совокупностями проводят дискриминацию.
Предположения Как говорилось ранее, дискриминантный анализ в вычислительном смысле очень похож на многомерный дисперсионный анализ (MANOVA), и поэтому применимы все предположения для MANOVA, упомянутые в разделе Дисперсионный анализ. Фактически, вы можете использовать широкий набор диагностических правил и статистических критериев для проверки предположений, чтобы вы имели законные основания применения Дискриминантного анализа к вашим данным.
Нормальное распределение. Предполагается, что анализируемые переменные представляют выборку из многомерного нормального распределения. Поэтому вы можете проверить, являются ли переменные нормально распределенными. Отметим, однако, что пренебрежение условием нормальности обычно не является "фатальным" в том смысле, что результирующие критерии значимости все еще "заслуживают доверия". Вы также можете воспользоваться специальными критериями нормальности и графиками.
Однородность дисперсий/ковариаций. Предполагается, что матрицы дисперсий/ковариаций переменных однородны. Как и ранее, малые отклонения не фатальны, однако прежде чем сделать окончательные выводы при важных исследованиях, неплохо обратить внимание на внутригрупповые матрицы дисперсий и корреляций. В частности, можно построить матричную диаграмму рассеяния, весьма полезную для этой цели. При наличии сомнений попробуйте произвести анализ заново, исключив одну или две малоинтересных совокупности. Если общий результат (интерпретация) сохраняется, то вы, по-видимому, имеете разумное решение. Вы можете также использовать многочисленные критерии и способы для того, чтобы проверить, нарушено это предположение в ваших данных или нет. Однако, как упомянуто в разделе Дисперсионный анализ, многомерный M-критерий Бокса для проверки однородности матриц дисперсий/ковариаций, в частности, чувствителен к отклонению от многомерной нормальности и не должен восприниматься слишком "серьезно".
Корреляции между средними и дисперсиями. Большинство "реальных" угроз корректности применения критериев значимости возникает из-за возможной зависимости между средними по совокупностям и дисперсиями (или стандартными отклонениями) между собой. Интуитивно ясно, что если имеется большая изменчивость в совокупности с высокими средними в нескольких переменных, то эти высокие средние ненадежны. Однако критерии значимости основываются на объединенных дисперсиях, то есть, на средней дисперсии по всем совокупностям. Поэтому критерии значимости для относительно больших средних (с большими дисперсиями) будут основаны на относительно меньших объединенных дисперсиях и будут ошибочно указывать на статистическую значимость. На практике этот вариант может произойти также, если одна из изучаемых совокупностей содержит несколько экстремальных выбросов, которые сильно влияют на средние и, таким образом, увеличивают изменчивость. Для определения такого случая следует изучить описательные статистики, то есть средние и стандартные отклонения или дисперсии для таких корреляций.
Задача с плохо обусловленной матрицей. Другое предположение в дискриминантном анализе заключается в том, что переменные, используемые для дискриминации между совокупностями, не являются полностью избыточными. При вычислении результатов дискриминантного анализа происходит обращение матрицы дисперсий/ковариаций для переменных в модели. Если одна из переменных полностью избыточна по отношению к другим переменным, то такая матрица называется плохо обусловленной и не может быть обращена. Например, если переменная является суммой трех других переменных, то это отразится также и в модели, и рассматриваемая матрица будет плохо обусловленной.
Значения толерантности. Чтобы избежать плохой обусловленности матриц, необходимо постоянно проверять так называемые значения толерантности для каждой переменной. Значение толерантности вычисляется как 1 минус R-квадрат, где R-квадрат - коэффициент множественной корреляции для соответствующей переменной со всеми другими переменными в текущей модели. Таким образом, это есть доля дисперсии, относящаяся к соответствующей переменной. Вы можете также обратиться к разделу Множественная регрессия, чтобы узнать больше о методах множественной регрессии и об интерпретации значения толерантности. В общем случае, когда переменная почти полностью избыточна (и поэтому матрица задачи является плохо обусловленной), значение толерантности для этой переменной будет приближаться к нулю.
Классификация.Другой главной целью применения дискриминантного анализа является проведение классификации. Как только модель установлена и получены дискриминирующие функции, возникает вопрос о том, как хорошо они могут предсказывать, к какой совокупности принадлежит конкретный образец?
Априорная и апостериорная классификация. Прежде чем приступить к изучению деталей различных процедур оценивания, важно уяснить, что эта разница ясна. Обычно, если вы оцениваете на основании некоторого множества данных дискриминирующую функцию, наилучшим образом разделяющую совокупности, и затем используете те же самые данные для оценивания того, какова точность вашей процедуры, то вы во многом полагаетесь на волю случая. В общем случае, получают, конечно худшую классификацию для образцов, не использованных для оценки дискриминантной функции. Другими словами, классификация действует лучшим образом для выборки, по которой была проведена оценка дискриминирующей функции (апостериорная классификация), чем для свежей выборки (априорная классификация). (Трудности с (априорной) классификацией будущих образцов заключается в том, что никто не знает, что может случиться. Намного легче классифицировать уже имеющиеся образцы.) Поэтому оценивание качества процедуры классификации никогда не производят по той же самой выборке, по которой была оценена дискриминирующая функция. Если желают использовать процедуру для классификации будущих образцов, то ее следует "испытать" (произвести кросс-проверку) на новых объектах.
Функции классификации. Функции классификации не следует путать с дискриминирующими функциями. Функции классификации предназначены для определения того, к какой группе наиболее вероятно может быть отнесен каждый объект. Имеется столько же функций классификации, сколько групп. Каждая функция позволяет вам для каждого образца и для каждой совокупности вычислить веса классификации по формуле:
Si = ci + wi1*x1 + wi2*x2 + ... + wim*xm
В этой формуле индекс i обозначает соответствующую совокупность, а индексы 1, 2, ..., m обозначают m переменных; ci являются константами для i-ой совокупности, wij - веса для j-ой переменной при вычислении показателя классификации для i-ой совокупности; xj - наблюдаемое значение для соответствующего образца j-ой переменной. Величина Si является результатом показателя классификации.
Поэтому вы можете использовать функции классификации для прямого вычисления показателя классификации для некоторых новых значений.
Классификация наблюдений. Как только вы вычислили показатели классификации для наблюдений, легко решить, как производить классификацию наблюдений. В общем случае наблюдение считается принадлежащим той совокупности, для которой получен наивысший показатель классификации (кроме случая, когда вероятности априорной классификации становятся слишком малыми; см. ниже). Поэтому, если вы изучаете выбор карьеры или образования учащимися средней школы после выпуска (поступление в колледж, в профессиональную школу или получение работы) на основе нескольких переменных, полученных за год до выпуска, то можете использовать функции классификации, чтобы предсказать, что наиболее вероятно будет делать каждый учащийся после выпуска. Однако вы хотели бы определить вероятность, с которой учащийся сделает предсказанный выбор. Эти вероятности называются апостериорными, и их также можно вычислить. Однако для понимания, как эти вероятности вычисляются, вначале рассмотрим так называемое расстояние Махаланобиса.
Расстояние Махаланобиса. Вы можете прочитать об этих расстояниях в других разделах. В общем, расстояние Махаланобиса является мерой расстояния между двумя точками в пространстве, определяемым двумя или более коррелированными переменными. Например, если имеются всего две некоррелированных переменные, то вы можете нанести точки (образцы) на стандартную 2М диаграмму рассеяния. Расстояние Махаланобиса между точками будет в этом случае равно расстоянию Евклида, т.е. расстоянию, измеренному, например, рулеткой. Если имеются три некоррелированные переменные, то для определения расстояния вы можете по-прежнему использовать рулетку (на 3М диаграмме). При наличии более трех переменных вы не можете более представить расстояние на диаграмме. Также и в случае, когда переменные коррелированы, то оси на графике могут рассматриваться как неортогональные (они уже не направлены под прямыми углами друг к другу). В этом случае простое определение расстояния Евклида не подходит, в то время как расстояние Махаланобиса является адекватно определенным в случае наличия корреляций.
Расстояние Махаланобиса и классификация. Для каждой совокупности в выборке вы можете определить положение точки, представляющей средние для всех переменных в многомерном пространстве, определенном переменными рассматриваемой модели. Эти точки называются центроидами группы. Для каждого наблюдения вы можете затем вычислить его расстояние Махаланобиса от каждого центроида группы. Снова, вы признаете наблюдение принадлежащим к той группе, к которой он ближе, т.е. когда расстояние Махаланобиса до нее минимально.
Апостериорные вероятности классификации. Используя для классификации расстояние Махаланобиса, вы можете теперь получить вероятность того, что образец принадлежит к конкретной совокупности. Это значение будет не вполне точным, так как распределение вокруг среднего для каждой совокупности будет не в точности нормальным. Так как принадлежность каждого образца вычисляется по априорному знанию модельных переменных, эти вероятности называются апостериорными вероятностями. Короче, апостериорные вероятности - это вероятности, вычисленные с использованием знания значений других переменных для образцов из частной совокупности. Некоторые пакеты автоматически вычисляют эти вероятности для всех наблюдений (или для выбранных наблюдений при проведении кросс-проверки).
Априорные вероятности классификации. Имеется одно дополнительное обстоятельство, которое следует рассмотреть при классификации образцов. Иногда вы знаете заранее, что в одной из групп имеется больше наблюдений, чем в другой. Поэтому априорные вероятности того, что образец принадлежит такой группе, выше. Например, если вы знаете заранее, что 60% выпускников вашей средней школы обычно идут в колледж, (20% идут в профессиональные школы и остальные 20% идут работать), то вы можете уточнить предсказание таким образом: при всех других равных условиях более вероятно, что учащийся поступит в колледж, чем сделает два других выбора. Вы можете установить различные априорные вероятности, которые будут затем использоваться для уточнения результатов классификации наблюдений (и для вычисления апостериорных вероятностей).
На практике, исследователю необходимо задать себе вопрос, является ли неодинаковое число наблюдений в различных совокупностях в первоначальной выборке отражением истинного распределения в популяции, или это только (случайный) результат процедуры выбора. В первом случае вы должны положить априорные вероятности пропорциональными объемам совокупностей в выборке; во втором - положить априорные вероятности одинаковыми для каждой совокупности. Спецификация различных априорных вероятностей может сильно влиять на точность классификации.
Итог классификации. Общим результатом, на который следует обратить внимание при оценке качества текущей функции классификации, является матрица классификации. Матрица классификации содержит число образцов, корректно классифицированных (на диагонали матрицы) и тех, которые попали не в свои совокупности (группы).
Другие предостережения.При повторной итерации апостериорная классификация того, что случилось в прошлом, не очень трудна. Нетрудно получить очень хорошую классификацию тех образцов, по которым была оценена функция классификации. Для получения сведений, насколько хорошо работает процедура классификации на самом деле, следует классифицировать (априорно) различные наблюдения, то есть, наблюдения, которые не использовались при оценке функции классификации. Вы можете гибко использовать условия отбора для включения или исключения из вычисления наблюдений, поэтому матрица классификации может быть вычислена по "старым" образцам столь же успешно, как и по "новым". Только классификация новых наблюдений позволяет определить качество функции классификации (см. также кросс-проверку); классификация старых наблюдений позволяет лишь провести успешную диагностику наличия выбросов или области, где функция классификации кажется менее адекватной.
Итог.В общем, Дискриминантный анализ - это очень полезный инструмент (1) - для поиска переменных, позволяющих относить наблюдаемые объекты в одну или несколько реально наблюдаемых групп, (2) - для классификации наблюдений в различные группы.
Факторный анализ. Под факторным анализом понимается методика комплексного и системного изучения и измерения воздействия факторов на величину результативных показателей. В общем случае можно выделить следующие основные этапы факторного анализа:
1. Постановка цели анализа.
2. Отбор факторов, определяющих исследуемые результативные показатели.
3. Классификация и систематизация факторов с целью обеспечения комплексного и системного подхода к исследованию их влияния на результаты хозяйственной деятельности.
4. Определение формы зависимости между факторами и результативным показателем.
5. Моделирование взаимосвязей между результативным и факторными показателями.
6. Расчет влияния факторов и оценка роли каждого из них в изменении величины результативного показателя.
7. Работа с факторной моделью (практическое ее использование для управления экономическими процессами).
Отбор факторов для анализатого или иного показателя осуществляется на основе теоретических и практических знаний в конкретной отрасли. При этом обычно исходят из принципа: чем больший комплекс факторов исследуется, тем точнее будут результаты анализа. Вместе с тем необходимо иметь в виду, что если этот комплекс факторов рассматривается как механическая сумма, без учета их взаимодействия, без выделения главных, определяющих, то выводы могут быть ошибочными. В анализе хозяйственной деятельности (АХД) взаимосвязанное исследование влияния факторов на величину результативных показателей достигается с помощью их систематизации, что является одним из основных методологических вопросов этой науки.
Важным методологическим вопросом в факторном анализе является определение формы зависимости между факторами и результативными показателями: функциональная она или стохастическая, прямая или обратная, прямолинейная или криволинейная. Здесь используется теоретический и практический опыт, а также способы сравнения параллельных и динамичных рядов, аналитических группировок исходной информации, графический и др.
Моделирование экономических показателейтакже представляет собой сложную проблему в факторном анализе, решение которой требует специальных знаний и навыков.
Расчет влияния факторов- главный методологический аспект в АХД. Для определения влияния факторов на конечные показатели используется множество способов, которые будут подробнее рассмотрены ниже.
Последний этап факторного анализа - практическое использованиефакторной моделидля подсчета резервов прироста результативного показателя, для планирования и прогнозирования его величины при изменении ситуации.
В зависимости от типа факторной модели различают два основных вида факторного анализа - детерминированный и стохастический.
Детерминированный факторный анализпредставляет собой методику исследования влияния факторов, связь которых с результативным показателем носит функциональный характер, т. е. когда результативный показатель факторной модели представлен в виде произведения, частного или алгебраической суммы факторов.
Данный вид факторного анализа наиболее распространен, поскольку, будучи достаточно простым в применении (по сравнению со стохастическим анализом), позволяет осознать логику действия основных факторов развития предприятия, количественно оценить их влияние, понять, какие факторы и в какой пропорции возможно и целесообразно изменить для повышения эффективности производства. Подробно детерминированный факторный анализ мы рассмотрим в отдельной главе.
Стохастический анализпредставляет собой методику исследования факторов, связь которых с результативным показателем в отличие от функциональной является неполной, вероятностной (корреляционной). Если при функциональной (полной) зависимости с изменением аргумента всегда происходит соответствующее изменение функции, то при корреляционной связи изменение аргумента может дать несколько значений прироста функции в зависимости от сочетания других факторов, определяющих данный показатель. Например, производительность труда при одном и том же уровне фондовооруженности может быть неодинаковой на разных предприятиях. Это зависит от оптимальности сочетания других факторов, воздействующих на этот показатель.
Стохастическое моделированиеявляется в определенной степени дополнением и углублением детерминированного факторного анализа. В факторном анализе эти модели используются по трем основным причинам:
- необходимо изучить влияние факторов, по которым нельзя построить жестко детерминированную факторную модель (например, уровень финансового левериджа);
- необходимо изучить влияние сложных факторов, которые не поддаются объединению в одной и той же жестко детерминированной модели;
- необходимо изучить влияние сложных факторов, которые не могут быть выражены одним количественным показателем (например, уровень научно-технического прогресса).
В отличие от жестко детерминированного стохастический подход для реализации требует ряда предпосылок:
- наличие совокупности;
- достаточный объем наблюдений;
- случайность и независимость наблюдений;
- однородность;
- наличие распределения признаков, близкого к нормальному;
- наличие специального математического аппарата.
Построение стохастической модели проводится в несколько этапов:
- качественный анализ (постановка цели анализа, определение совокупности, определение результативных и факторных признаков, выбор периода, за который проводится анализ, выбор метода анализа);
- предварительный анализ моделируемой совокупности (проверка однородности совокупности, исключение аномальных наблюдений, уточнение необходимого объема выборки, установление законов распределения изучаемых показателей);
- построение стохастической (регрессионной) модели (уточнение перечня факторов, расчет оценок параметров уравнения регрессии, перебор конкурирующих вариантов моделей);
- оценка адекватности модели (проверка статистической существенности уравнения в целом и его отдельных параметров, проверка соответствия формальных свойств оценок задачам исследования);
- экономическая интерпретация и практическое использование модели (определение пространственно-временной устойчивости построенной зависимости, оценка практических свойств модели).
Кроме деления на детерминированный и стохастический, различают следующие типы факторного анализа:
- прямой и обратный;
- одноступенчатый и многоступенчатый;
- статический и динамичный;
- ретроспективный и перспективный (прогнозный).
При прямом факторном анализеисследование ведется дедуктивным способом - от общего к частному. Обратный факторный анализ осуществляет исследование причинно-следственных связей способом логичной индукции - от частных, отдельных факторов к обобщающим.
Факторный анализ может быть
одноступенчатым и многоступенчатым.
Первый тип используется для исследования
факторов только одного уровня (одной
ступени) подчинения без их детализации
на составные части. Например,![]() .
При многоступенчатом факторном анализе
проводится детализация факторов a и b
на составные элементы с целью изучения
их поведения. Детализация факторов
может быть продолжена и дальше. В этом
случае изучается влияние факторов
различных уровней соподчиненности.
.
При многоступенчатом факторном анализе
проводится детализация факторов a и b
на составные элементы с целью изучения
их поведения. Детализация факторов
может быть продолжена и дальше. В этом
случае изучается влияние факторов
различных уровней соподчиненности.
Необходимо также различать статический и динамический факторныйанализ. Первый вид применяется при изучении влияния факторов на результативные показатели на соответствующую дату. Другой вид представляет собой методику исследования причинно-следственных связей в динамике.
И, наконец, факторный анализ может быть ретроспективным, который изучает причины прироста результативных показателей за прошлые периоды, и перспективным, который исследует поведение факторов и результативных показателей в перспективе.
Кластерный анализ. Кластерный анализ предназначен для разбиения совокупности объектов на однородные группы (кластеры или классы). По сути это задача многомерной классификации данных. Существует около 100 разных алгоритмов кластеризации, однако наиболее часто используемые: иерархический кластерный анализ и кластеризация методов k-средних.
Где применяется кластерный анализ? В маркетинге это сегментация конкурентов и потребителей. В менеджменте: разбиение персонала на различные по уровню мотивации группы, классификация поставщиков, выявление схожих производственных ситуаций, при которых возникает брак. В медицине - классификация симптомов, пациентов, препаратов. В социологии - разбиение респондентов на однородные группы. По сути кластерный анализ хорошо зарекомендовал себя во всех сферах жизнедеятельности человека.
Прелесть данного метода - он работает даже тогда, когда данных мало и невыполняются требования нормальности распределений случайных величин и другие требования классических методов статистического анализа.
Поясним суть кластерного анализа, не прибегая к строгой терминологии: допустим, Вы провели анкетирование сотрудников и хотите определить, каким образом можно наиболее эффективно управлять персоналом. То есть Вы хотите разделить сотрудников на группы и для каждой из них выделить наиболее эффективные рычаги управления. При этом различия между группами должны быть очевидными, а внутри группы респонденты должны быть максимально похожи.
Для решения задачи предлагается использовать иерархический кластерный анализ. В результате мы получим дерево, глядя на которое мы должны определиться, на сколько классов (кластеров) мы хотим разбить персонал. Предположим, что мы решили разбить персонал на три группы, тогда для изучения респондентов, попавших в каждый кластер, получим табличку примерно следующего содержания:
|
Кластер |
Муж |
30-50 лет |
>50 лет |
Рук. |
Мед |
Льготы |
з/п |
стаж |
Образов. |
|
1 |
80% |
90% |
5% |
70% |
10% |
12% |
95% |
30% |
30% |
|
2 |
40% |
35% |
45% |
13% |
60% |
70% |
60% |
40% |
20% |
|
3 |
50% |
70% |
10% |
5% |
30% |
20% |
70% |
20% |
50% |
Поясним, как сформирована приведенная выше таблица:
В первом столбце расположен номер кластера - группы, данные по которой отражены в строке. Например, первый кластер на 80% составляют мужчины. 90% первого кластера попадают в возрастную категорию от 30 до 50 лет, а 12% респондентов считает, что льготы очень важны. И так далее. Попытаемся составить портреты респондентов каждого кластера.
Первая группа- в основном мужчины зрелого возраста, занимающие руководящие позиции. Соцпакет (MED, LGOTI, TIME-своб время) их не интересует. Они предпочитают получать хорошую зарплату, а не помощь от работодателя.
Группа дванаоборот отдает предпочтение соцпакету. Состоит она, в основном, из людей "в возрасте", занимающих невысокие посты. Зарплата для них, безусловно, важна, но есть и другие приоритеты.
Третья группанаиболее "молодая". В отличие от предыдущих двух, очевиден интерес к возможностям обучения и профессионального роста. У этой категории сотрудников есть хороший шанс в скором времени пополнить первую группу.
Таким образом, планируя кампанию по внедрению эффективных методов управления персоналом, очевидно, что в нашей ситуации можно увеличить соцпакет у второй группы в ущерб, к примеру, зарплате. Если говорить о том, каких специалистов следует направлять на обучение, то можно однозначно рекомендовать обратить внимание на третью группу.
Многомерное шкалирование.Общая цель. Многомерное шкалирование (МНШ) можно рассматривать как альтернативу факторному анализу (см. Факторный анализ). Целью последнего, вообще говоря, является поиск и интерпретация "латентных (т.е. непосредственно не наблюдаемых) переменных", дающих возможность пользователю объяснить сходства между объектами, заданными точками в исходном пространстве признаков. Для определенности и краткости, далее, как правило, будем говорить лишь о сходствах объектов, имея ввиду, что на практике это могут быть различия, расстояния или степени связи между ними. В факторном анализе сходства между объектами (например, переменными) выражаются с помощью матрицы (таблицы) коэффициентов корреляций. В методе МНШ дополнительно к корреляционным матрицам, в качестве исходных данных можно использовать произвольный тип матрицы сходства объектов. Таким образом, на входе всех алгоритмов МНШ используется матрица, элемент которой на пересечении ее i-й строки и j-го столбца, содержит сведения о попарном сходстве анализируемых объектов (объекта [i] и объекта [j]). На выходе алгоритма МНШ получаются числовые значения координат, которые приписываются каждому объекту в некоторой новой системе координат (во "вспомогательных шкалах", связанных с латентными переменными, откуда и название МНШ), причем размерность нового пространства признаков существенно меньше размерности исходного (за это собственно и идет борьба).
Логика многомерного шкалирования. Логику МНШ можно проиллюстрировать на следующем простом примере. Предположим, что имеется матрица попарных расстояний (т.е. сходства некоторых признаков) между крупными американскими городами. Анализируя матрицу, стремятся расположить точки с координатами городов в двумерном пространстве (на плоскости), максимально сохранив реальные расстояния между ними. Полученное размещение точек на плоскости впоследствии можно использовать в качестве приближенной географической карты США.
В общем случае метод МНШ позволяет таким образом расположить "объекты" (города в нашем примере) в пространстве некоторой небольшой размерности (в данном случае она равна двум), чтобы достаточно адекватно воспроизвести наблюдаемые расстояния между ними. В результате можно "измерить" эти расстояния в терминах найденных латентных переменных. Так, в нашем примере можно объяснить расстояния в терминах пары географических координат Север/Юг и Восток/Запад.
Ориентация осей координат. Как и в Факторном анализе, ориентация осей может быть выбрана произвольной. Возвращаясь к нашему примеру, можно поворачивать карту США произвольным образом, но расстояния между городами при этом не изменятся. Таким образом, окончательная ориентация осей на плоскости или в пространстве является, в большей степени результатом содержательного решения в конкретной предметной области (т.е. решением пользователя, который выберет такую ориентацию осей, которую легче всего интерпретировать). В примере можно было бы выбрать ориентацию осей, отличающуюся от пары Север/Юг и Восток/Запад, однако последняя удобнее, как "наиболее осмысленная" и естественная. В начало
Вычислительные методы. Многомерное шкалирование - это не просто определенная процедура, а скорее способ наиболее эффективного размещения объектов, приближенно сохраняющий наблюдаемые между ними расстояния. Другими словами, МНШ размещает объекты в пространстве заданной размерности и проверяет, насколько точно полученная конфигурация сохраняет расстояния между объектами. Говоря более техническим языком, МНШ использует алгоритм минимизации некоторой функции, оценивающей качество получаемых вариантов отображения.
Меры качества отображения: стресс. Мерой, наиболее часто используемой для оценки качества подгонки модели (отображения), измеряемого по степени воспроизведения исходной матрицы сходств, является так называемый стресс. Величина стресса Phi в для текущей конфигурации определяется так:
Phi =
![]() [dij - f (
[dij - f (![]() ij)]2.
ij)]2.
Здесь dij - воспроизведенные расстояния в пространстве заданной размерности, а ij (дельта ij) - исходное расстояние. Функция f (ij) обозначает неметрическое монотонное преобразование исходных данных (расстояний). Таким образом, МНШ воспроизводит не количественные меры сходств объектов, а лишь их относительный порядок.
Обычно используется одна из несколько похожих мер сходства. Тем не менее, большинство из них сводится к вычислению суммы квадратов отклонений наблюдаемых расстояний (либо их некоторого монотонного преобразования) от воспроизведенных расстояний. Таким образом, чем меньше значение стресса, тем лучше матрица исходных расстояний согласуется с матрицей результирующих расстояний.
Диаграмма Шепарда. Можно построить
для текущей конфигурации точек график
зависимости воспроизведенных расстояния
от исходных расстояний. Такая диаграмма
рассеяния называется диаграммой Шепарда.
По оси ординат OY показываются
воспроизведенные расстояния (сходства),
а по оси OX откладываются истинные
сходства (расстояния) между объектами
(отсюда обычно получается отрицательный
наклон). На этом график также строится
график ступенчатой функции. Ее линия
представляет так называемые величины
D-с крышечкой, то есть, результат
монотонного преобразования f(![]() )
исходных данных. Если бы все воспроизведенные
результирующие расстояния легли на эту
ступенчатую линию, то ранги наблюдаемых
расстояний (сходств) был бы в точности
воспроизведен полученным решением
(пространственной моделью). Отклонения
от этой линии показывают на ухудшение
качества согласия (т.е. качества подгонки
модели).
)
исходных данных. Если бы все воспроизведенные
результирующие расстояния легли на эту
ступенчатую линию, то ранги наблюдаемых
расстояний (сходств) был бы в точности
воспроизведен полученным решением
(пространственной моделью). Отклонения
от этой линии показывают на ухудшение
качества согласия (т.е. качества подгонки
модели).
Задание размерности пользователем. Если вы уже знакомы с факторным анализом, вы вполне можете пропустить этот раздел. В противном случае вы можете перечитать раздел Факторный анализ. Однако это не является необходимым для понимания идей многомерного шкалирования.
Вообще говоря, чем больше размерность пространства, используемого для воспроизведения расстояний, тем лучше согласие воспроизведенной матрицы с исходной (меньше значение стресса). Если взять размерность пространства равной числу переменных, то возможно абсолютно точное воспроизведение исходной матрицы расстояний. Однако нашей целью является упрощение решаемой задачи, с тем, чтобы объяснить матрицу сходства (расстояний) в терминах лишь нескольких важнейших факторов (латентных переменных или вспомогательных шкал). Возвращаясь к нашему примеру с расстояниями между городами, если получена двумерная карта, намного проще представить себе, расположение городов и планировать передвижение между ними, чем, если бы имелась только матрица попарных расстояний.
Причины плохого качества отображения. Обсудим, почему уменьшение числа факторов (или вспомогательных шкал) может приводить к ухудшению представления исходной матрицы. Обозначим буквами A, B, C и D, E, F две тройки городов. Соответствующие им точки и попарные расстояния между ними показаны в двух табличках (матрицах).
|
А В С |
A 0 90 90 |
B
0 90 |
C
0 |
D E F
|
D 0 90 180 |
E
0 90 |
F
0 |
Первой матрице соответствует случай когда города удалены друг от друга в точности на 90 километров, а второй - когда города D и F удаляются на 180 километров. Можно ли три точки, соответствующие городам (объектам) расположить в одномерном пространстве (на прямой)? Действительно, три точки, соответствующие городам D, E и F могут быть расположены на прямой линии:
D---90 км---E---90 км---F
D удален на 90 км от города E, и E - на 90 км от F, а город D удален на 90+90=180 км от F. Если попытаться проделать тоже самое с городами A, B и C, то видно, что соответствующие им точки уже нельзя разместить на прямой с сохранением исходной структуры расстояний. Однако эти точки можно расположить на плоскости, например, в виде треугольника: A
90 км 90 км
B 90 км C
Располагая эти три точки так, можно в точности воспроизвести все расстояния между ними. Без лишних деталей, этот пример показывает, как конкретная матрица расстояний (сходств) связана с числом искомых латентных переменных (размерностью результирующего пространства). Конечно, "реальные" данные никогда не являются такими "точными", и содержат случайный шум, т.е. случайную изменчивость, влияющую на различие между воспроизведенной и исходной матрицей.
Критерий "каменистой осыпи". Обычно, для выбора размерности пространства, в котором будет воспроизводится наблюдаемая матрица, используют график зависимости стресса от размерности (график каменистой осыпи). Этот критерий впервые был предложен Кэттелом (Cattell (1966)) в контексте решения задачи снижения размерности в факторном анализе (см. Факторный анализ); Краскал и Виш (Kruskal and Wish (1978; стр. 53-60)) обсуждали применение этого графика в методе МНШ.
Кэттел предложил найти такую абсциссу на графике (в методе ФА, по оси абсцисс идут собственные значения), в которой график стресса начинает визуально сглаживаться в направлении правой, пологой его части, и, таким образом, уменьшение стресса максимально замедляется. Образно говоря, линия на рисунке напоминает скалистый обрыв, а черные точки на графике напоминают камни, которые ранее упали вниз. Таким образом, внизу наблюдается как бы каменистая осыпь из таких точек. Справа от выбранной точки на оси абсцисс, лежит только "факторная осыпь". Согласно этому критерию, на приведенном рисунке, скорее всего, следует выбрать для воспроизведения двумерное пространство.
Интерпретируемость конфигурации. Вторым критерием для решения вопроса о размерности с целью интерпретации является "ясность" полученной конфигурации точек. Иногда, как в нашем примере с городами, результирующие координаты легко интерпретируются. В других случаях, точки на графике могут образовывать ту или иную разновидность "случайного облака", и не существует непосредственного способа для интерпретации латентных переменных. В последнем случае следует постараться немного увеличить число координатных осей и рассмотреть получаемые в результате конфигурации. Чаще всего, получаемые решения проще удается проинтерпретировать. Однако если точки на графике не следуют какому-либо образцу, а также если график стресса не показывает какого-либо явного "изгиба" (и не похож на "край обрыва"), то данные, скорее всего, являются случайным "шумом". В начало
Интерпретация осей координат. Интерпретация осей обычно представляет собой заключительный этап анализа по методу многомерного шкалирования. Как уже упоминалось ранее, в принципе, ориентация осей в методе МНШ может быть произвольной, и систему координат можно повернуть в любом направлении. Поэтому на первом шаге получают диаграмму рассеяния точек, соответствующих объектам, на различных плоскостях.
Трехмерные решения также можно проинтерпретировать графически.

Однако эта интерпретация является несколько более сложной.
Заметим, что в дополнение к существенным осям координат, также следует искать кластеры точек, а также те или иные конфигурации точек (окружности, многообразия и др.). Более подробное обсуждение интерпретации полученных конфигураций, см. в работах Borg and Lingoes (1987), Borg and Shye (в печати) или Gutman, (1968).
Использование методов множественной регрессии. Аналитическим способом интерпретации осей координат (описанным в работе Kruskal и Wish, 1978) является применение методов множественной регрессии для регрессирования некоторых имеющих смысл переменных на оси координат. Это легко сделать с помощью модуля Множественная регрессия.
Приложения. "Красота" метода МНШ в том, что вы можете анализировать произвольный тип матрицы расстояний или сходства. Эти сходства могут представлять собой оценки экспертов относительно сходства данных объектов, результаты измерения расстояний в некоторой метрике, процент согласия между судьями по поводу принимаемого решения, количество раз, когда субъект затрудняется различить стимулы и мн.др. Например, методы МНШ весьма популярны в психологическом исследовании восприятия личности. В этом исследовании анализируются сходства между определенными чертами характера с целью выявления основополагающими личностных качеств (см., например, Rosenberg, 1977). Также они популярны в маркетинговых исследованиях, где их используют для выявления числа и сущности латентных переменных (факторов), например, с целью изучения отношения людей к товарам известных торговых марок (подробнее см. Green и Carmone, 1970).
В общем случае, методы МНШ позволяют исследователю задать клиентам в анкете относительно ненавязчивые вопросы ("насколько похож товар фирмы A на товар фирмы B") и найти латентные переменные для этих анкет незаметно для респондентов.
Многомерное шкалирование и факторный анализ. Даже, несмотря на то, что имеется много сходства в характере исследуемых вопросов, методы МНШ и факторного анализа имеют ряд существенных отличий. Так, факторный анализ требует, чтобы исследуемые данные подчинялись многомерному нормальному распределению, а зависимости были линейными. Методы МНШ не накладывают таких ограничений. Методы МНШ могут быть применимы, пока сохраняет смысл порядок следования рангов сходств. В терминах различий получаемых результатов, факторный анализ стремится извлечь больше факторов (координатных осей или латентных переменных) по сравнению с МНШ; в результате чего МНШ часто приводит к проще интерпретируемым решениям. Однако более существенно то, что методы МНШ можно применять к любым типам расстояний или сходств, тогда как методы ФА требуют, чтобы первоначально была вычислена матрица корреляций. Методы МНШ могут быть основаны на прямом оценивании сходств между стимулами субъектов, тогда как ФА требует, чтобы субъекты были оценены через их стимулы по некоторому списку атрибутов.
Суммируя вышесказанное, можно сказать, что методы МНШ потенциально применимы к более широкому классу исследовательских задач.
Совместный анализ. Совместный анализ — один из лучших методов определения оптимальных характеристик продукта и его цены на основе моделирования поведения потребителей. В то же время следует отметить, что совместный анализ является достаточно сложным методом и обладает рядом недостатков. Непонимание этих недостатков и различных тонкостей применения совместного анализа не позволяет исследователю устранить или минимизировать их влияние на этапе разработки инструментария и анализа данных, что, в свою очередь, может привести к существенным проблемам с достоверностью полученных результатов.
Введение.Суть метода заключена в его названии: conjoint – consider jointly, т. е. “рассматривать совместно”. В отличие от композиционных методов, где каждая характеристика оценивается по отдельности, в совместном анализе респондент оценивает все характеристики
Набор профилей продуктов
Марка: Nokia
Вес: 90г.
Цвет: красный
Цена: $350
Батарея: 5 часов
Марка: Siemens
Вес: 190 г.
Цвет: Черный
Цена: $150
Батарея: 4,5 часа
Марка: Benefon
Вес: 140 г.
Цвет: синий
Цена: $250
Батарея: 4 часа
продукта в комплексе, т. е. совместно. Варианты продуктов, которые оценивают респонденты, называются профилями. Они представляют собой описание продукта, состоящее из набора уровней различных атрибутов. Атрибутами являются характеристики продукта — например, цвет мобильного телефона, — а уровни представляют собой их значения: красный, черный, синий и т. п. Собрав суждения респондентов о различных профилях продуктов, можно вычислить важность каждого атрибута и полезность каждого его уровня. Используя эти данные, можно оценить привлекательность любого продукта, в том числе еще не существующего, и определить его потенциальную долю рынка.
Совместный анализ— один из лучших методов, позволяющих определять оптимальные характеристики продукта и его цену на основе моделирования поведения потребителей. В то же время следует отметить, что совместный анализ является достаточно сложным методом и обладает рядом недостатков. Непонимание этих недостатков и различных тонкостей применения совместного анализа не позволяет исследователю устранить или минимизировать их влияние на этапе разработки инструментария и анализа данных, что, в свою очередь, может привести к существенным проблемам с достоверностью полученных результатов. Приведем поэтапную процедуру применения совместного анализа с описанием тех проблем, которые могут возникнуть на каждом ее этапе.
Этап 1:Формирование списка характеристик. Разработка дизайна проекта совместного анализа начинается с определения атрибутов, из которых будут сформированы профили продуктов. Для того чтобы не упустить важные для потребителей характеристики продукта, необходимо, прежде всего, составить их список, из которого затем будут выбраны атрибуты. Среди характеристик, включаемых в профили продуктов, можно отметить две универсальные характеристики: торговая марка и цена. Эти характеристики используются в большинстве проектов, в то время как остальные зависят от изучаемого рынка и продукта. В список необходимо включать характеристики всех продуктов, представленных на рынке, в том числе продуктов конкурентов, даже если они отсутствуют в продукте компании. Очень важно также рассматривать не только позитивные, но и негативные характеристики продукта, так как концентрация респондентов только на положительных аспектах может внести существенные искажения в оценки. Более того, если какая-либо характеристика, присущая реальным продуктам, отсутствует в дизайне проекта, респонденты могут искусственно присвоить ее продуктам, описанным в представленных им профилях. Так, например, исследователь, разрабатывая дизайн проекта, мог не учитывать наличие или отсутствие русифицированного меню в телефоне, предполагая, что все компании предлагают эту функцию. Однако респонденты могли знать, что одна из компаний никогда не предлагала меню на русском языке, а потому предположить, что и в представленных на профилях телефонах этой марки не будет возможности использовать русский язык.
Для того чтобы выявить как можно большее количество характеристик, необходимо провести ряд предварительных исследований. Прежде всего, нужно провести интервью с менеджерами и сотрудниками компании. Хорошие результаты в данном случае может дать метод “мозгового штурма”. Затем можно провести несколько глубинных интервью с представителями компаний-посредников, осуществляющих реализацию продукта конечному потребителю. Мы также настоятельно рекомендуем провести несколько групповых дискуссий непосредственно с потребителями продукции. Безусловно, проведение подобных исследований требует дополнительных затрат, однако только так исследователь может быть уверен в том, что он выявил все необходимые характеристики.
Этап 2. Выбор атрибутов. Одним из недостатков совместного анализа является ограничение, накладываемое этим методом на количество атрибутов. Это связано с тем, что при оценке профилей респонденту приходится одновременно рассматривать все представленные в нем атрибуты, в то время как мозг человека может одновременно обрабатывать не более 7 элементов информации. Если в профилях продуктов будет содержаться более 5—7 атрибутов, это может привести к информационной перегрузке респондентов и снижению точности их оценок. Поэтому на втором этапе необходимо принять решение о том, какие характеристики продукта из общего списка будут включаться в дизайн проекта в виде атрибутов.
Атрибуты, включаемые в дизайн проекта, должны удовлетворять ряду условий. Прежде всего, они должны быть важными для потребителей. Атрибуты, не представляющие существенной ценности, не рассматриваются потребителями при покупке продукта и, следовательно, не влияют на их выбор. Необходимо также удостовериться в том, что эти атрибуты не только важны, но и определяют как можно более сильные отличия продуктов друг от друга и, следовательно, реально оказывают влияние на решения, принимаемые потребителями. Так, например, возможность вызова последнего набранного номера нажатием одной кнопки может быть очень важной для потребителей, однако этот фактор не оказывает влияния на выбор телефона, так как эта функция предусмотрена во всех моделях. В идеальном варианте для определения важности атрибутов должен быть проведен предварительный количественный опрос. Учитывая, что нам необходимо лишь приблизительно оценить важность характеристик, можно ограничиться выборкой в 200—300 респондентов. Данные о важности характеристик могут быть также получены из отчетов по предыдущим исследованиям, если они проводились. Следует отметить, что в любом случае необходимо вставлять дополнительный блок вопросов о важности характеристик в расширенном составе хотя бы в основную анкету. По крайней мере, это позволит своевременно обнаружить проблему с характеристиками, ошибочно исключенными из рассмотрения в совместном анализе.
В состав атрибутов не должны также включаться абстрактные характеристики продукта, такие, как “качество связи” или “удобство пользования телефоном”. Если подобные характеристики все же необходимо включить в рассмотрение, то это может быть сделано в два этапа. На первом этапе необходимо провести опрос потребителей, в ходе которого определить факторы, от которых зависят оценки этих абстрактных характеристик. На втором этапе наиболее значимые из этих факторов включаются в описание профилей продукта в более четких терминах. Так, например, в ходе проведения предварительного исследования можно выяснить, что потребители связывают “удобство пользования телефоном” с размерами экрана и расстоянием между кнопками. Именно эти атрибуты и должны включаться в профили.
Этап 3: определение диапазона значений атрибутов. После того, как выбраны атрибуты, необходимо определить диапазон их возможных значений. Особое внимание на этом этапе следует уделить тому, чтобы этот диапазон включал в себя все возможные значения атрибутов, которые могут быть использованы при проведении последующего анализа. Необходимо помнить о том, что во время анализа мы сможем провести интерполяцию данных между значениями уровней атрибутов, но не сможем экстраполировать полученные результаты за пределы крайних значений. Так, если в исследовании использовались такие уровни цен, как $150, $250 и $350, то в дальнейшем мы сможем вычислить значение полезности любой цены между ними, например, $200 или $300, но не сможем определить полезность уровней цен, выходящих за этот диапазон, — скажем, $100 или $400.
При определении диапазона уровней атрибута необходимо также избегать нереальных значений, не встречающихся на рынке. Профили, описанные нереальными значениями, могут сбить с толку респондента, снизить его доверие к компетентности интервьюера и привести к тому, что он будет несерьезно относиться к проводимому исследованию. Это также может привести к переоценке значимости атрибута, определяемой как разница между полезностью наиболее и наименее привлекательных уровней. Если нереальные уровни обнаруживаются после проведения исследования, то исследователь имеет два варианта решения этой проблемы. Во-первых, он может полностью исключить из анализа все профили продуктов, содержащие нереальные значения. Другим возможным решением может стать уменьшение полезности этих уровней до таких значений, при которых ни один продукт с нереальным уровнем не будет выбран респондентом при проведении анализа. Эта мера позволит избежать неточностей при прогнозировании доли рынка различных продуктов.
Диапазон необходимых значений зависит от того, какие варианты продуктов необходимо будет рассматривать в дальнейшем. Для того чтобы выявить диапазон возможных значений, необходимо, прежде всего, определить период времени, на который будут распространяться результаты проводимого анализа. После этого необходимо определить спектр возможных вариантов продуктов, которые могут быть предложены компанией и ее конкурентами на протяжении этого периода. Мы рекомендуем использовать в качестве крайних уровней значения, немного выходящие за пределы имеющегося диапазона, для того чтобы иметь большую свободу в выборе уровней при формировании продукта.
Этап 4. Определение количества уровней. Определяя привлекательность для потребителей какого-либо продукта, исследователь может использовать для его описания только те уровни атрибутов, которые рассматривались респондентами при оценке профилей. Поэтому при разработке дизайна проекта желательно включить в него как можно большее количество уровней. Так, например, если в исследование были включены такие марки телефонов, как Nokia, Siemens, Benefon, то в дальнейшем исследователь ничего не сможет сказать о том, насколько привлекательна для потребителей марка Motorola. Более того, невозможно будет также определить реальные доли рынка изученных марок, так как неизвестна привлекательность других марок, представленных на рынке.
Увеличение количества уровней атрибутов приводит также и к повышению точности оценок. Ранее мы говорили о том, что можем интерполировать результаты проведенного анализа. Однако, как известно, любая интерполяция является не более чем приближением к реальности. Реальные значения могут отличаться от значений, полученных в результате интерполяции. Чем больше уровней будет включено в дизайн проекта, тем более точные результаты могут быть получены. Особое значение это имеет для такого важного атрибута, как цена продукта. Мы рекомендуем включать в дизайн проекта не менее 4—5 уровней цен.
Недостаточное количество уровней снижает достоверность получаемых результатов, в то время как их избыточное количество снижает надежность получаемых оценок. Это связано с тем, что при увеличении количества уровней возрастает и количество профилей продуктов, которые необходимо оценивать респондентам, а это приводит к большей продолжительности интервью, утомляемости респондентов и, как следствие, снижению качества результатов. Таким образом, исследователь должен найти компромиссное решение при определении количества уровней атрибутов, которое, с одной стороны, не сильно увеличит продолжительность интервью, а с другой, не окажет существенного влияния на достоверность результатов. Не существует какого-либо жесткого ограничения на количество уровней, однако по собственному опыту мы считаем, что их максимальное количество не должно превышать 5—7 значений для любого атрибута.
Исследователь должен также стараться как можно лучше сбалансировать количество уровней между атрибутами. Это связано с тем, что относительная важность атрибута возрастает при увеличении количества уровней, даже при неизменности рассматриваемого диапазона значений. Одна из возможных причин этого эффекта заключается в том, что большее количество уровней одного из атрибутов привлекает к нему повышенное внимание респондентов. Так, например, можно представить два варианта уровней цены: первый вариант с тремя уровнями ($150, $250 и $350) и второй вариант с пятью уровнями ($150, $200, $250, $300 и $350). Несмотря на то, что в обоих вариантах представлен одинаковый диапазон цен (от $150 до $350), во втором случае цена будет оказывать большее влияние на выбор продукта респондентом, чем в первом.
Исследователь может снизить влияние этого эффекта за счет установления одинакового количества уровней для всех атрибутов. Однако на практике, к сожалению, этого не всегда можно добиться, особенно когда в исследовании участвуют атрибуты, принимающие только два значения — “да” или “нет”. Как бы то ни было, необходимо стремиться к тому, чтобы количество уровней у различных атрибутов отличалось как можно меньше. Одним из вариантов решения этой проблемы может быть разделение атрибута на два субатрибута с меньшим количеством уровней. В том случае, если исследователь не в состоянии соблюсти необходимый баланс, он может установить большее количество уровней для более важного атрибута с тем, чтобы получить по нему дополнительную информацию.
Этап 5. Определение значений уровней.Уровни атрибутов, отобранные для формирования профилей продуктов, должны удовлетворять двум условиям: они должны быть понятны респондентам, а компания должна иметь возможность реализовать их изменения в продукте. Первое условие означает, что интервьюеры смогут легко объяснить респондентам, что представляют собой те или иные характеристики и их значения. Второе условие связано с тем, что результаты совместного анализа должны давать компании возможность четко понять, что необходимо предпринять для улучшения своего продукта. В профилях не должно содержаться уровней, описываемых качественными значениями, такими, как “тяжелый” или “легкий”. Каждый респондент по-своему воспринимает значения этих терминов, что приводит к неоднозначным оценкам представленных альтернатив. С другой стороны, подобные определения не понятны и менеджерам компании - насколько нужно снизить вес телефона, чтобы он стал легким?
При выборе уровней атрибутов необходимо также избегать использования диапазонов значений. Такие качественные значения, как “тяжелый” и “легкий”, могут быть заменены количественными уровнями: “160—200 г” и “80—120 г”. Несмотря на то, что в новом варианте уровни атрибута представлены количественными значениями, они по-прежнему являются неоднозначными, так как содержат диапазоны значений. Оценивая профиль с уровнем “80—120 г”, респондент может подразумевать как 80 г, так и 120 г в зависимости от ситуации. Корректные значения уровней цены могли бы выглядеть следующим образом: “100 г” и “180 г”. Представленные в описаниях профилей уровни атрибутов должны быть однозначными и не должны содержать ни качественных описаний, ни диапазонов значений.
Этап 6. Выбор функции предпочтения. Функция предпочтения определяет некое связующее правило между полезностью атрибута и его уровнями. Возможность выбора разнообразных функций предпочтения добавляет гибкости совместному анализу. Как правило, исследователь имеет возможность выбрать один из трех основных вариантов: модель идеального вектора (ideal vector), модель идеальной точки (ideal point) и дискретная модель (partial benefit).
Модель идеального вектора представляет собой линейную функцию зависимости полезности атрибута от его уровня . Это означает, что при увеличении или уменьшении значения атрибута происходит соответствующее увеличение или уменьшение его полезности. Так, например, чем на большее время разговора хватает зарядки батареи телефона, тем большую ценность он представляет для пользователей. Модель идеального вектора представляет собой самую простую форму зависимости (у = кх), для установления которой необходимо вычислить лишь один параметр (к), определяющий угол наклона прямой. Однако эта модель имеет и очевидные недостатки, так как предполагает строго линейную зависимость полезности и уровней атрибута, что не всегда соответствует реальности. Модель идеальной точки представляет собой параболу . Эта зависимость отражает увеличение или уменьшение полезности при отклонении значения атрибута от некоторого идеального уровня. Такой функцией может быть описана привлекательность телефона в зависимости от его размеров. До определенного момента уменьшение размеров повышает его привлекательность, однако после достижения определенных (оптимальных) размеров дальнейшее их уменьшение ведет к снижению привлекательности из-за чрезмерного уменьшения размеров кнопок и экрана. Модель идеальной точки представляет собой параболическую зависимость (у = ах2 + bх), для определения которой необходимо вычислить два параметра (а, Ь). Обе эти модели позволяют описать зависимость простыми функциями, для которых необходимо вычислить лишь один или два параметра, что повышает надежность получаемых оценок. Однако надежность оценок, как известно, не гарантирует их достоверности. Проблема, связанная с применением этих двух моделей, заключается в строгих ограничениях, накладываемых ими на форму зависимости полезности и значений атрибутов. При этом следует отметить, что в реальности редко встречаются зависимости, описываемые строго линейными или параболическими функциями. Это ограничение может быть снято за счет применения дискретной модели. Данная модель не предполагает наличия какой-либо функции и вычисляет полезности каждого уровня по отдельности. Она является наиболее гибкой и включает в себя обе предыдущие модели как частный случай. Однако эта гибкость имеет и негативную сторону, о которой часто забывают при проведении исследования. Недостаток этой модели связан с тем, что количество параметров, которые необходимо вычислить, возрастает прямо пропорционально количеству уровней, что может привести к снижению точности получаемых результатов.
При спецификации атрибутов исследователь должен всегда искать компромисс между надежностью оценок и соответствием выбранной модели реальной зависимости. Существует несколько различных путей, облегчающих выбор той или иной модели. Прежде всего, исследователь может обратиться к “физическому смыслу” значений атрибутов и логически обосновать оптимальную для каждого из них функцию предпочтения. Выбор оптимальной функции может быть также основан на результатах ранее проведенных исследований. Более того, выбор функции предпочтения не влияет на дизайн профилей продукта, а потому исследователь может выбрать модель после проведения полевых работ. Исследователь может также провести анализ для различных вариантов функций предпочтения и выбрать тот из них, который обеспечивает наиболее правдоподобные результаты. Однако мы не рекомендуем использовать эту возможность при отсутствии каких-либо предварительных гипотез. Выбор функции предпочтения должен всегда основываться на теоретическом или эмпирическом обосновании формы изучаемой зависимости.
Одна из наиболее распространенных ошибок, совершаемых на данном этапе, связана со спецификацией такого атрибута, как цена. Некоторые исследователи принимают решение о выборе линейной функции на основе постулатов классической экономической теории, представляющей функцию спроса и цены как прямую линию или, в лучшем случае, гладкую гиперболу. Однако вряд ли кто-либо из исследователей на практике имел дело с кривыми такой формы. В реальности кривые цен встречаются в самых различных формах, далеких от классических моделей. Аппроксимация этой кривой с помощью каких-либо стандартных функций может привести к ошибочным решениям в ценообразовании. При изучении ценовой чувствительности покупателей необходимо стремиться к тому, чтобы как можно точнее определить ценовую эластичность в каждой конкретной точке, а не применять вместо этого простые усредненные модели. Мы считаем, что только применение дискретной модели с максимально возможным количеством уровней цены позволит выявить точки перегиба кривой, необходимые для принятия решения об оптимальном уровне цен.
Этап 7. Определение количества профилей. Важность атрибутов и полезность их уровней вычисляются из оценок профилей продуктов. В идеальном варианте респонденты должны оценить профили со всеми возможными комбинациями уровней атрибутов. Этот подход, предполагающий формирование всех возможных комбинаций, называется полным факториальным дизайном. Однако в большинстве случаев его невозможно реализовать на практике из-за чрезмерно большого количества профилей, которые необходимо будет оценивать респондентам. Так, например, если у нас имеется 5 атрибутов, каждый из которых представлен 4 уровнями, то общее количество профилей составит: 45=1024. Очевидно, что ни один респондент не в состоянии оценить столь большое количество профилей. Выход из этой ситуации заключается в создании усеченного факториального дизайна. Данный подход предполагает формирование некой выборки из всех возможных вариантов профилей, что позволяет существенно сократить продолжительность интервью, получая при этом достаточно точные и надежные оценки. Следует помнить о том, что применение выборочных методов приводит к снижению точности результатов. Чем больше профилей будет включено в выборку, тем более точные результаты могут быть получены. Минимальное количество профилей, которые должны быть оценены респондентами, может быть вычислено по следующей формуле.
Следовательно, в нашем примере достаточно оценить лишь 16 профилей из более чем 1000 возможных вариантов, что представляется вполне осуществимым. Однако следует отметить, что эта формула позволяет определить лишь минимально приемлемое количество профилей. Для получения оптимального количества профилей это значение рекомендуется увеличить в 1,5—3 раза. Несмотря на то, что использование усеченного дизайна позволяет существенно сократить количество профилей, оно может оставаться по-прежнему слишком большим, чтобы не вызывать проблем у респондентов. По нашему опыту, респонденты могут оценить не более 10 — 15 профилей за раз. В большинстве же исследований необходимое количество профилей может превышать эти значения.
Если исследователь сталкивается с чрезмерным количеством профилей, он может попытаться уменьшить количество уровней или исключить какие-либо атрибуты. В том случае, если это невозможно, а количество профилей не превышает 30, исследователь может предложить респондентам выполнить задание в два этапа. На первом этапе респонденты распределяют все профили на две или три примерно равные группы (например, привлекательные и непривлекательные). На втором этапе они оценивают профили каждой группы по отдельности. Другой подход заключается в том, чтобы предложить различным группам респондентов оценить разные профили из набора. При таком подходе каждый респондент должен оценить лишь несколько профилей, однако это требует большей выборки респондентов и позволяет анализировать данные лишь в агрегированном виде.
Этап 8. Формирование профилей.На данном этапе необходимо выбрать из множества возможных вариантов лишь несколько профилей, которые должны быть оценены респондентами. Один из наиболее простых подходов к формированию профилей заключается в случайном выборе необходимого количества профилей из общего списка возможных вариантов. Однако этот подход почти никогда не применяется на практике. Одна из особенностей совместного анализа заключается в том, что он, в отличие от многих других методов, не требует каких-либо проверок на нормальность, гетероскедастичность или независимость переменных. Это достигается, главным образом, за счет того, что дизайн профилей формируется особым, систематическим методом.
Отсутствие каких-либо проверок при анализе данных требует соответствия дизайна профилей двум условиям: ортогональности и сбалансированности. Ортогональность дизайна предполагает отсутствие корреляции уровней между атрибутами, т. е. уровень одного атрибута должен встречаться в комбинации с каждым уровнем другого атрибута одинаковое количество атрибутов. Например, самый маленький, но самый тяжелый телефон.
Существует несколько возможных вариантов устранения этих проблем. Прежде всего, необходимо попытаться заново сгенерировать профили продуктов. Возможно, в новом наборе эта проблема исчезнет сама собой. Если же избавиться от проблемных профилей, таким образом, не удается, то исследователь может просто удалить эти профили из набора. Если количество удаляемых профилей невелико, то даже если этот дизайн не будет являться полностью ортогональным, это не сильно скажется на результатах анализа. В подобных ситуациях мы также рекомендуем использовать специальные программные продукты, позволяющие создавать так называемые “околоортогональные” дизайны. Эти программные модули позволяют указать различные варианты недопустимых сочетаний уровней атрибутов и даже самих атрибутов. Они также позволяют контролировать этот процесс с помощью показателя эффективности дизайна, указывающего, насколько данный дизайн отклоняется от полностью ортогонального. Еще одним вариантом решения проблемы нереальных сочетаний может стать объединение двух атрибутов в один “супер атрибут”, описываемый только реальными уровнями. Однако подобное решение ведет к увеличению количества уровней и, соответственно, количества профилей.
Этап 9. Выбор метода измерений. Существует несколько методов измерений, с помощью которых респонденты могут выразить свое отношение к профилям. Один из них основан на ранжировании профилей: подразумевается, что респонденты ознакомятся со всеми предложенными им альтернативами, после чего упорядочат их по убыванию привлекательности. Для этого респондент может выбрать самый лучший (с его точки зрения) профиль и присвоить ему ранг “1”, затем выбрать самый лучший профиль среди оставшихся и присвоить ему ранг “2” и т. д. Ранжирование представляет собой достаточно простую и понятную для респондентов задачу, а потому дает более надежные результаты. Однако этот метод можно использовать только для небольшого количества профилей (не более 10). Другой метод основан на оценке профилей по предложенной шкале. Респонденту предлагают оценить привлекательность или вероятность покупки описанных в профилях продуктов, например, по 11-балльной шкале, где 0 — “точно не куплю”, а 11 — “точно куплю”. При этом для оценки 16 или менее профилей можно использовать шкалу с 11
Вариант профилей для парного сравнения
КАКОЙ ИЗ ЭТИХ ТЕЛЕФОНОВ ВЫ ПРЕДПОЧИТАЕТЕ?
Nokia
90г.
Красный
$350 5 часов
Benefon
140г.
Синий
$250 4 часа
Точно ОДИНАКОВО Точно
Левый 1 2 3 4 5 6 7 8 9 правый
категориями, а для оценки более 16 профилей необходимо использовать 21-балльную шкалу. К основным достоинствам оценки можно отнести то, что этот метод, в отличие от ранжирования, позволяет не только определить более предпочитаемые варианты, но и оценить степень их предпочтения. К основным недостаткам метрических шкал можно отнести то, что респонденты не всегда понимают, что означает та или иная оценка, а также часто пользуются лишь крайними значениями шкалы. Третий метод основан на парном сравнении. Респонденту предъявляют два профиля и просят выбрать тот, который нравится ему больше. Затем его могут спросить, насколько больше он готов заплатить за понравившийся ему продукт. Респондента могут также попросить оценить степень предпочтения одного продукта другому по какой-либо метрической шкале (рис. 2). Данный метод не представляет сложности для респондентов, позволяет легко оценить понравившийся продукт и дает хорошие результаты. Однако парное сравнение требует в два раза большего количества заданий для респондентов.
Этап 10. Проведение полевых работ. При проведении совместного анализа могут использоваться различные методы сбора данных. Оптимальным методом является личное интервью, в ходе которого интервьюер имеет возможность использовать различные варианты визуального представления профилей, а также может помочь респонденту выполнить задание. В то же время личное интервью является одним из самых дорогих методов сбора данных. Снизить затраты на проведение исследования можно с помощью почтового опроса. Однако этот метод характеризуется низким процентом возвращаемых анкет. Этой проблемы можно избежать, проводя опрос по телефону. Но проведение телефонных интервью возможно только при небольшом количестве атрибутов и уровней, не нуждающихся в графическом представлении. Хорошие результаты может дать комбинация телефонного интервью и почтового опроса. При таком подходе респондентам сначала звонят по телефону и получают их согласие на участие в исследовании, после чего отправляют анкету по почте. Далее интервьюер снова связывается с респондентом по телефону, дает советы по заполнению анкеты и проводит интервью. На результаты исследования может повлиять очередность представления профилей для оценки с использованием метрических шкал. Уменьшить влияние этого фактора можно, ротируя предъявляемые профили продуктов. Необходимо также менять порядок расположения атрибутов на профилях, вне зависимости от метода измерений. Искажения в оценки респондентов могут также внести порядковые номера, проставленные на профилях для их идентификации. Чтобы не смущать респондента, их нужно располагать на обратной стороне карточек с профилями. Необходимо также убедиться в том, что респонденты правильно понимают суть задания и адекватно воспринимают атрибуты и их уровни, указанные в профилях. С этой целью перед “запуском” исследования должен быть проведен “пилотаж”, в ходе которого требуется выяснить, как воспринимаются несколькими респондентами вопросы, содержащиеся в анкете.
Этап 11. Анализ данных. Вычисление важности атрибутов и полезности их уровней в совместном анализе представляет собой достаточно сложную процедуру. Однако от исследователя не требуется проводить ее “вручную”, так как это делается с помощью специальных программных продуктов. Существуют различные алгоритмы, по которым из общих оценок профилей выделяются полезности отдельных уровней атрибутов. Одним из наиболее популярных методов анализа, применяемых для метрических шкал, является регрессионный анализ с фиктивными переменными (ОLS). Он представляет собой обычную регрессию методом наименьших квадратов, где оценка респондента является зависимой переменной, а уровни атрибутов — фиктивными объясняющими переменными, принимающими значения 0 или 1. Этот метод не применяется, если используются неметрические шкалы, например, ранги. В таких случаях часто используют монотонную регрессию. Суть данной процедуры заключается в следующем. Вначале каждому атрибуту произвольно присваивают значения полезности. Затем определяют общую полезность профилей как сумму полезностей их уровней. Далее для каждой пары профилей определяют разность их общих полезностей. Если профиль с большим значением полезности имеет меньший ранг, т. е. респондент считает его более привлекательным, то этой разности присваивают положительный знак, и наоборот. После этого определяют коэффициент соответствия вычисленных значений полезностей и проставленных респондентом рангов.
Вычисленный подобным образом коэффициент отражает долю “неправильных” полезностей и может принимать значения от 0 (идеальное соответствие) до 1 (отсутствие соответствия). Затем значения полезностей изменяют, используя градиентный вектор как направление оптимизации, и повторяют все шаги заново. Цель данной процедуры заключается в том, чтобы найти такие значения полезностей, которые максимально соответствовали бы указанным респондентом рангам. Важность атрибута определяется через разницу максимального и минимального значения полезностей уровней. Чем больше разница этих значений, тем большее влияние может быть оказано этими уровнями на общую полезность продукта и, следовательно, тем более важным является атрибут. Относительная важность атрибута рассчитывается по следующей формуле.
После проведения расчетов необходимо проверить достоверность полученной модели. Для этого можно проверить коэффициенты корреляции, отражающие соответствие вычисленных оценок полезности, рангам или оценкам профилей, указанным респондентами. Более надежным способом определения достоверности модели является использование проверочных профилей (noldout). Эти профили внешне ничем не отличаются от обычных и формируются отдельно от основного набора. Проверочные профили оцениваются респондентами, но не включаются в анализ при расчете полезности уровней атрибутов. Эти полезности, рассчитанные на основном наборе, используются затем для вычисления общей полезности проверочных профилей, а вычисленные значения сравниваются с оценками, указанными для них респондентами. Респонденты, у которых вычисленные и указанные ими оценки проверочных профилей имеют существенные расхождения, должны быть исключены из анализа. Помимо своего основного предназначения проверочные профили могут быть использованы для получения прямых оценок респондентов по тем вариантам продукта, которые особенно интересуют исследователя.
Этап 12. Определение доли рынка. `На завершающем этапе исследователь может использовать вычисленные полезности уровней для определения оптимальных характеристик и цены продукта, а также его доли рынка на основе моделирования поведения потребителей. Для этого необходимо, прежде всего, вычислить общие полезности продуктов компании и конкурентов, определяемые как сумма полезностеи уровней атрибутов (рис. 3).
Полученные значения полезности продуктов необходимо затем перевести в доли рынка. Для этого может быть использована модель одиночного выбора (First Choice), в основе которой лежит предположение о том, что потребитель выбирает продукт с максимальной полезностью. Так, в примере на рисунке 3 потребитель выберет продукт нашей компании как наиболее полезный. Данная модель позволяет получить хорошие результаты при условии, что рынок сильно сегментирован и продукты отличаются друг от друга. Ее также можно использовать на рынках с высоко вовлеченными потребителями. Однако эта модель не может использоваться при анализе агрегированных данных, так как в этом случае все 100% рынка будут отданы одному продукту. Основной же недостаток модели одиночного выбора заключается в завышении доли рынка наиболее привлекательного продукта, безраздельно получающего предпочтение потребителя, даже если его полезность лишь немного превышает полезность продукта ближайшего конкурента.
Рис. 3. Расчет итоговых полезностей и долей рынка продуктов
КОМПАНИЯ
КОНКУРЕНТ 1
КОНКУРЕНТ 2
|
Уровни |
Полезность |
Уровни |
Полезность |
Уровни |
Полезность |
|
Siemens |
2,76 |
Nokia |
2,80 |
Benefon |
2,44 |
|
90 г |
2,91 |
100 г |
2,15 |
135 г |
1,73 |
|
Черный |
1,72 |
Черный |
1,72 |
Красный |
1,22 |
|
$275 |
1,74 |
$340 |
1,52 |
$200 |
2,10 |
|
4,5 часа |
2,23 |
5 часов |
2,34 |
3 часа |
1,74 |
|
ИТОГО |
11,36 |
ИТОГО |
10,53 |
ИТОГО |
9,23 |
|
First Choice |
100% |
First Choice |
0% |
First Choice |
0% |
|
BTL |
36,5% |
BTL |
33,8% |
BTL |
29,7% |
|
Logit |
64,3% |
Logit |
28,1% |
Logit |
7,6% |
В реальности потребители не проводят детального анализа полезности продуктов, а потому могут выбирать не самые привлекательные варианты. Вероятностный подход оставляет шанс любому продукту быть купленным. В основе одного из таких подходов лежит предположение о том, что вероятность покупки продукта пропорциональна его полезности (модель ВТL). При таком подходе доля рынка продукта компании (рис. 3) составит: 11,367(11,36 + 10,53 + 9,23) = 36,5%. Данная модель может применяться как на индивидуальном, так и на агрегированном уровне. Она больше всего подходит для ситуаций частых повторных покупок, когда выбор продукта может быть обусловлен обстоятельствами. Несмотря на то, что эта модель дает лучшие, чем модель First Choice, результаты для не самых привлекательных продуктов, она переоценивает их долю рынка, особенно в ситуации с большим количеством продуктов-подражателей (“me too”). Еще одна модель, применяемая для перевода относительных полезностеи продукта в доли рынка, представляет собой некий компромисс между моделью First Choice и моделью BTL. В основе этой модели заложена экспоненциальная зависимость между полезностью продукта и его долей рынка (модельLogit):
Такой подход к оценке доли рынка позволяет определять ее не как линейную функцию от значения полезности (модель BTL), а как функцию, непропорционально завышающую или занижающую значения доли рынка для продуктов с большими и меньшими значениями полезности соответственно. Так, в примере на рисунке 3 доля рынка компании составит:
Модель Logit сочетает в себе достоинства двух предыдущих моделей, а ее основным недостатком является завышение доли рынка продуктов-подражателей, что свойственно также и модели BTL. Для решения этой проблемы применяются различные корректирующие процедуры.
Заключение.Совместный анализ предоставляет исследователю большие возможности по изучению мотивации и моделированию поведения потребителей. Однако достоверность и применимость результатов, полученных с его помощью, во многом зависят от решений, принятых исследователем на стадии разработки дизайна проекта. Принимая во внимание этот факт, исследователь должен уделять повышенное внимание процессу разработки дизайна, так как ошибки, допущенные на этой стадии, будет невозможно исправить в дальнейшем. Более того, некоторые ошибки невозможно будет не только исправить, но и обнаружить, что может привести к неадекватным выводам и решениям, основанным на результатах некорректно проведенного анализа.
Несмотря на то, что проведение совместного анализа сопряжено с определенными сложностями, это не должно являться причиной отказа от него в пользу более простых методов, так как они не могут предоставить исследователю ту информацию, которую он может получить в результате проведения совместного анализа. Учитывая множество нюансов, связанных с проведением совместного анализа, и важность решений, принимаемых на основе его результатов, рекомендуется доверять эту работу маркетинговым агентствам, имеющим опыт проведения подобных проектов. Если же вы все-таки решите проводить совместный анализ своими силами, то уделите повышенное внимание стадии разработки дизайна проекта.