3.3.8. Ограниченный контекст
Недопустимость существования двух правил с одинаковыми правыми частями, ограничивает использование для синтаксического разбора техники предшествования.
Рассмотрим следующую грамматику:
R := aUa;
Q := bVb;
U := c;
V := c.
К примеру есть цепочка: аса. Это не контекстно-свободная грамматика и не грамматика простого предшествования, но по контексту легко установить, на какой символ (U или на V) следует заменить символ "с". Данный вывод становится возможным на основе анализа ограниченного числа элементов. В данном случае используется 1:1 ограниченный контекстный преобразователь.
Определение 1:1 ограниченного контекстного распознавателя
Пусть в грамматике G(Z) имеется вывод Z => +xTuRy.
Также пусть имеется правило: U := u.
Тогда, если в процессе разбора сентенциальной формы в стеке окажется …xTu, а входной символ будет R, то цепочку u следует привести к нетерминалу U. При такой конструкции: …TuR… необходимо уметь определить, является ли цепочка u простой фразой для нетерминала U.
Пример:
Цепочка: Z => …VR…;
Правило: V := Tu;
То имеем вывод: Z => +…TuR.
Но так как правила U := u у нас нет, мы не можем произвести замену цепочки u на нетерминал U. Если бы такое правило было, то можно было построить 1:1 ограниченный контекстный преобразователь.
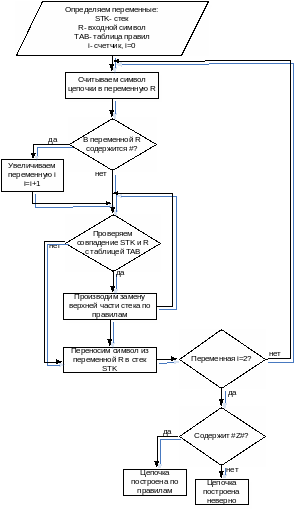
Алгоритм 1:1 ограниченного контекстного преобразователя
Распознаватель пользуется единственной таблицей, которая содержит 3 столбца. В первом находится возможное содержимое стека в форме Tu.
Т - любой символ или ограничитель.
U - правая часть правила.
Во втором столбце находятся соответствующие правые контексты. В третьем столбце указывается номер правила, которое используется в этом случае.
На каждом шаге работы распознаватель среди строк таблицы ищет ту, в которой содержимое первого столбца совпадает с верхней частью стека. А содержимое второго столбца совпадает с последним считанным символом. Если такая строка найдена, осуществляется редукция. Основа в стеке заменяется в соответствии с правилом, номер которого указан в третьем столбце. Если такой строки нет, то редукция невозможна. Последний сканируемый символ помещается в стек, и сканируется следующий символ.
Таблица содержит все возможные конфигурации вида:
Tu |
R |
i |
Если в любой момент можно найти совпадение не более чем с одной строкой в верхней части стека и входного символа, то всякая редукция может быть выполнена.
Для пояснения работы алгоритма рассмотрим следующий пример.
Пусть у нас есть следующие привила:
Z:=V;
Z:=aW;
V:=V1;
V:=bU;
U:=U0;
U:=0;
W:=0W1;
W:=01.
Используя эти правила, можно составить следующую таблицу для алгоритма:
|
Tu |
R |
|
1 |
a01 |
# |
8 |
2 |
001 |
1 |
8 |
3 |
#aW |
# |
2 |
4 |
#bU |
1 |
4 |
5 |
bU0 |
1 |
5 |
6 |
bU0 |
0 |
5 |
7 |
#V1 |
1 |
3 |
8 |
#V1 |
# |
3 |
9 |
#V |
# |
1 |
10 |
a0W1 |
# |
7 |
11 |
b0 |
# |
6 |
Ниже приведены несколько цепочек, разобранных по данному алгоритму:
3)
#a0011#
2)
1
0
W
a
![]()
1
0
W
b
V
U
#
V
Z
# 6)
# 5)
1
5, 6)
1#
V
U
#
V
b
Z
4)
#
#
7)
1
0
W
Z
W
a
#a01#
1)
1
0
W
a
Z
Теперь рассмотрим разбор первой цепочки более подробно:
Цепочка: Алгоритм разбора:
|
|
W |
a |
# |
2
-
#
Z
#

8
1 |
0 |
0 |
a |
# |
7
1 |
W |
0 |
a |
# |
#a0011#
1
0
W
a
Z
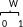
Блок-схема работы по алгоритму 1:1 ограниченного контекста