

3.1.1. Элементы теории языка и их грамматика. Символы, цепочки и операции над ними
Языком в алфавите S называют множество цепочек, состоящих из элементов этого алфавита.
Алфавит-любое множество символов.
В общем случае алфавит не обязан быть конечным, но мы будем иметь дело только с конечным.
Цепочка - последовательность символов алфавита.
Цепочка и слово - синонимы.
Символы: a,b,c,d - элементы алфавита,
M,Q,S,T - переменные, обозначающие любой символ алфавита,
u, w, v, x, y, z, t - обозначают цепочки символов. u=аbc.
Причем сцепление цепочек xyyx (сон нос).
Пример: U=abcd - цепочка,
X=cb - цепочка.
х=х=х, где - пустая цепочка - цепочка, не содержащая ни одного символа (обозначается или е).
Цепочка, содержащая i одинаковых символов – ai= aa…a(i штук).|ai|=i.
Если x=ab и y=cd, то w=xy=abcd называется конкатенацией цепочек x и y.
Обращение цепочки x обозначается xr .Если x=abc, то xr=cba.
Пусть x,y,z – произвольные цепочки в S .И пусть имеется цепочка w=xyz.
Цепочку x называют префиксом, цепочку z-суффиксом цепочки w, цепочка y-инфикс цепочки w.
Пусть имеется цепочка x=s…, s-голова цепочки, x=…s, s – хвост цепочки x.
Если A={a,b},B={c,d}-2 алфавита, то множество AB={ac,bc,ad,bd} и других комбинаций быть не может. Коммутативный закон здесь не приемлем.
Пусть L1-язык в алфавите S1,а L2-язык в алфавите S2.Тогда язык L1L2 – конкатенация языков.
Сцепление произвольного числа цепочек языка L охватывается понятием итерация и обозначается L*=L0ÈL1È…, L0=l, L+ - усечённая итерация. L*\L+=l. Пусть S1 и S2-алфавиты. Гомоморфизмом называют любое отображение h=S*1®S2*.
Пример: S1={a,b},S2={0,1}.Тогда h(a)=1,h(b)=0.
Формальное определение языка
Алфавит и совокупность правил, формализующих построение цепочек языка, называют его грамматикой. G{N,S,P,S} - грамматика, где N - нетерминальные символы, S - терминальные символы, S - некоторый начальный символ, P - правило.
Построим грамматику, которая бы генерировала произвольные целые числа:
S=0…9;
S=<чис>.
Определим правила: <чис>:=<ц>|<чис><ц>; <ц>:=0|1|2|…|9.
Выведем 4-разрядное число:
<чис>=><чис><ц>=><чис><ц><ц>=<чис><ц><ц><ц>=><ц><ц><ц><ц>=>
2<ц><ц><ц>=>23<ц><ц>=>234<ц> =>2345
Такую форму грамматики называют нормальная форма Бэкуса-Наура.
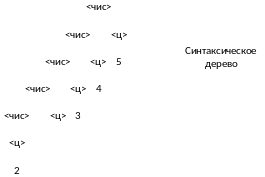
Пусть имеется вывод:W=>U0=>U1=U2=V. Говорят, что W порождает цепочку V и пишут W=>+V(без l) W=>*V(с l).Если в цепочке есть хотя бы 1 нетерминал, то из неё можно вывести новую цепочку.
Пусть G(z) грамматика. Сентенциальная форма – любое высказывание, выводимое из начального символа. Цепочка X называется сентенциальной формой, если имеет место вывод Z=>+X, Z=>*X.
Сентенциальная форма, которая содержит только терминальные символы, получила название предложения.
Пусть G(z)-грамматика и X,Y-некоторые сентенциальные формы в ней. Тогда U-полная фраза сентенциальной формы для нетерминала U,если имеется вывод U=>+u и если имеется правило U:=u.
Пример: E:=E +T|T; T:=T*F|F; F:=(E)|i
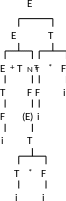
+
Если рассмотреть все висячие вершины слева направо, то получим предложение i+(i*i)+i*i. i+(E) является фразой для нетерминального символа E (2-й сверху), для этого же символа E+T является простой фразой. Основой всякой сентенциальной формы называется самая левая простая фраза.