

3.2. Сканеры (лексические анализаторы)
Сканер представляет собой ту часть транслятора, которая читает литеры исходной программы и строит из них слова (лексемы).
Подмножества формальных языков (синтаксический класс):
Служебные слова.
Целые числа.
Разделители.
Идентификаторы.
Оператор.
Сущности языка можно разделить на пять подмножеств.
Этапы работы транслятора
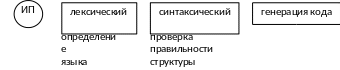
При выполнении полного лексического анализа происходит разбор входного текста на подмножества формальных языков и исходная программа содержится в таблице в форме внутренних представлений. На данном этапе анализатору совершенно не важно, какой идентификатор ему встретился, важно лишь то, что это идентификатор.
Составленная таблица передается синтаксическому анализатору.
Строчка исходной программы А=В+С+10 будет разобрана
-
Служебные
слова
Идентифи-каторы
Целые числа
Оператор
Разделитель
i
i
i
10
=
+
Исходя из этой таблицы, предложение превратится в: i=i+i+10. Это задача сканера – проанализировав предложение, построить цепочку.
Но данный вид лексического анализа менее эффективен, так как необходимо хранить ис-ходную программу в форме внутренних представлений.
Более целесообразно использовать подпрограмму, к которой обращается синтаксический анализатор всякий раз, когда ему необходим новый символ. Сканер формирует лексему исходной программы и отсылает ее на синтаксический анализ. Сканер может быть задан конечным автоматом.
В принципе построение языка программирования может быть построено (освоено) с помощью языка регулярной грамматики.
Символы исходного языка
Символами в языке являются разделители и операторы ( /, +, –, , (, ), и //), служебные слова (BEGIN, ABS и END), идентификаторы (которые не могут быть служебными словами), и целые числа. По крайней мере, один пробел должен отделять смежные идентификаторы, целые числа и/или служебные слова. Ни одного пробела не должно появляться между литерами в слове.
Идентификаторы и целые числа имеют вид
буква {буква | цифра} и цифра {цифра}.
В добавление ко всему сканер должен распознавать и исключать комментарий. Комментарий начинается с двулитерного символа / и заканчивается при первом появлении двулитерного символа /. Следующая строка является примером одного комментария:
/ Это / / один комментарий /.
Сканер строит внутреннее представление для каждого символа. В большинстве случаев это целое число фиксированной длины (байт, полуслово, слово и т.д.). В других частях компилятора гораздо эффективнее обрабатываются эти целые числа, чем цепочки переменной длины, которыми фактически представляются символы.
3.2.1. Автоматные грамматики и диаграмма состояний
Рассмотрим грамматику G(Z), которая содержит правила:
Z: = U0|V1; U: = Z1|1; V: = Z0|0.
Изобразим графически процесс построения сентенциальных форм. Назовём это диаграммой состояния, где каждый нетерминал есть некоторое состояние. Существует также начальный символ S – начальное состояние, SNU.. Каждому правилу вида Q:=T, где TÎVT, QÎVN поставим в соответствие дугу, исходящую из начального символа и направленную в состояние, помеченное Q, а каждому правилу вида Q: = RT, где TÎVT, Q,RÎVN поставим в соответствие дугу, исходящую из вершины R и направленную в вершину, помеченную Q. Будем использовать диаграмму состояний для распознавания цепочки.
Диаграмма состояний:

Алгоритм распознавания на основе диаграммы состояний
Пусть имеем цепочку x , содержащую n терминальных символов. Первым текущим состоянием считать начальное состояние S.
Начать с самого левого терминала цепочки и повторять шаг 2, пока не будет достигнут правый её конец.
Сканировать следующую литеру цепочки x. Продвинуться по дуге, помеченной этим терминалом, переходя к следующему текущему состоянию. Если на каком-то шаге такой дуги не оказывается, то цепочка x не является предложением языка, генерированного рассматриваемой грамматикой. Если конец цепочки достигнут, она является предложением тогда и только тогда, когда последнее текущее состояние есть Z(начальный символ).
Разберём цепочку
0 1 1 0 0 1
V Z
V Z
Цепочка является предложением языка сгенерированного данной грамматикой.
Если взять цепочку 111111, сразу будет ошибка.