

Алгоритм восходящего разбора
Восходящий разбор представляет собой правый анализатор, который перебирает всевозможные обращённые правые выводы, совместимые с входной цепочкой.
Шаг алгоритма состоит в считывании цепочки, расположенной в верхней части магазина. На этом шаге выясняется, образуют ли верхние символы стека правую часть какого либо правила, если да, то производится свёртка. Если свёртка невозможна, то в магазин переносится следующий входной символ.
Если возможна более чем одна свёртка, то последние упорядочиваются и применяется правая. Всегда перед переносом делается попытка свёртки. Если цепочка исчерпана, то следует вернуться к последнему шагу, на котором была произведена свёртка, и если возможна альтернатива, использовать её.
Алгоритм:
Описывается, как и предыдущий, в терминах четырёх компонентных конфигураций:
S - состояния q, b, t;
q – нормальное рабочее состояние (удачное сравнение и процесс восхождения от листьев дерева к вершине);
b – неудачное сравнение и возврат по дереву;
t – заключительное состояние;
i – указатель позиции;
L1 – стек, хранящий историю переноса свёртки (верх справа);
L2 – стек для хранения результата и факта переноса.
Правила:
(q,1,$,e) – начальное состояние;
(q, i, $α, γ) |¾ (q, i+1, $αa, Sγ) – перенос;
S - символ характеризующий факт переноса;
γ - некоторая цепочка.
(q, i, $αβ, γ) |¾ (q, i, $αB, jγ) – свёртка;
Если есть B=β, то j - номер правила.
(q, n+1, $αB, jγ) |¾ (b, n+1, $α, γ) - состояние возврата;
n- количество символов.
(q, n+1, $E, γ) |¾ (t, n+1, $E, γ) - последнее состояние.
Пример:
E:=E+T;
E:=T;
T:=T*F;
T:=F;
F:=a.
Рассмотрим входную цепочку: a*a
(q, 1, $, e) |¾ (q, 2, $a, S) |¾ (q, 2, $F, 5S) |¾ (q, 2, $T, 45S) |¾ (q, 2, $E, 245S)|¾
(q, 3, $E*, S245S) |¾ (q, 4, $E*a, SS245S) |¾ (q, 4, $E*F, 5SS245S) |¾
(q, 4, $E*T, 45SS245S) |¾ (q, 4, $E*E, 245SS245S) |¾ (b, 4, $E*a, SS245S) |¾
(b, 3, $E*, S245S) |¾ (b, 2, $E, 245S) |¾ (b, 2, $T, 45S) |¾ (q, 3, $T*, S45S) |¾
(q, 4, $T*a, SS45S) |¾ (q, 4, $T*F, 5SS45S) |¾ (q, 4, $T, 35SS45S) |¾ (q, 4, $E, 235SS45S) |¾
(t, 4, $E, 235SS45S).
Получили дерево:
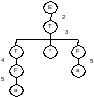
Рис. 3. Дерево
3.4.2. Польская запись, тетрады, триады, деревья.
Атрибутное дерево разбора
Атрибутное дерево разбора является, наверное, самой распространенной формой организации внутреннего представления программы. При таком подходе каждая исходная конструкция языка представляется в виде узла дерева, содержащего ссылки на все возможные элементы этой конструкции (естественно, каждый отдельный элемент тоже может иметь сложную структуру и, таким образом, также может быть поддеревом). Кроме того, каждый узел дерева может нагружаться дополнительными атрибутами, такими как ссылки в таблицы представлений или таблицы идентификаторов. В итоге, вся программа представляется в виде единого дерева разбора.
Деревья разбора привлекательны прежде всего своей гибкостью и возможностью использования в самых разных этапах компиляции. Их можно спроектировать таким образом, чтобы они мало зависели от исходного языка и целевой платформы. Деревья разбора легко строить во время анализа исходной программы, а все последующие просмотры компилятора могут быть реализованы в виде самостоятельных обходов этого дерева. Кроме того, некоторые просмотры, такие как оптимизация программы, удобнее всего выполнять именно над деревьями разбора.
Польская запись
Польская запись была предложена польским логиком Лукасевичем. В этой форме записи все операторы непосредственно предшествуют операндам. Так, обычное выражение (a+b)*(c-d) в польской записи может быть представлено как *+ab-cd.
Такую форму записи называют также префиксной. Аналогичным образом вводится обратная, или постфиксная, польская запись, в которой все операторы выписываются после операндов. Скажем, пример, приведенный выше, в обратной польской записи будет записан следующим образом: ab+cd-*. Для представления унарных операций в польской записи можно воспользоваться эквивалентными выражениями, использующими бинарные операции, как в следующем примере: -b -> 0 - b, а можно ввести новый знак операции, скажем, @b . Польская запись может быть распространена не только на арифметические выражения, но и на прочие конструкции языка. Например, оператор a := a + b может быть записан в польской записи как :=a+ab, а условный оператор if <expr> then <instr1> else <instr2> может быть записан как следующая последовательность операторов:
<expr> <c1> BZ <instr1> <c2> BR <instr2>,
где c1 указывает на первую инструкцию <instr2>, а c2 - на первую инструкцию, следующую за <instr2>, BR - безусловный переход на адрес <c2>, а BZ - переход на <c1> при условии равенства нулю выражения <expr1>.
Пользуясь такой терминологией, мы можем называть традиционную форму записи выражений инфиксной, так как в ней знаки операций расположены между операндами. Понятно, что любое выражение может быть переведено из инфиксной формы в польскую запись и наоборот. Польская запись замечательна тем, что при ее использовании исчезает потребность в приоритетах операций - каждая операция выполняется в порядке появления в исходной цепочке (хотя очевидно, что приоритет операций необходимо учитывать при преобразованиях из инфиксной формы).
Польская запись (особенно обратная) очень хорошо накладывается на стековую модель: каждый встреченный операнд загружается в стек, а операции производятся только на вершине стека: каждая операция снимает необходимое количество операндов с вершины стека и кладет на стек свой результат. Именно такая модель используется в MSIL для реализации большинства операций.
Перевод инфиксной записи в суффиксную
Будем полагать, что в некоторой сентенциальной форме основа Х найдена и ее можно заменить на нетерминал в соответствии с правилам u:=X.
Синтаксический распознаватель обратится к некоторой семантической программе и осуществит преобразование, т.е. перевод ее (основы) в суффиксную форму.
Генерируемую цепочку будем хранить в одномерном массиве Р, который содержит индекс, указывающий на первый свободный элемент массива. Каждый элемент массива содержит один символ. Имеется возможность доступа к стеку, где хранится цепочка. Нужно занести в массив код переменной и код операции их связывающий:
Е:=Е+Т. Если встретили цепочку Е+Т, то польская (суффиксная) запись уже получена: коды <E> и <T> уже существуют, а программа должна занести в массив "+":
Р(р)="+";
Inc(p).
Есть входная цепочка: A*(B+C), мы должны преобразовать ее в АВС+*, предварительно проверив, правильно ли она получена синтаксически.
Сработал лексический анализатор и выдал i*(i+i). С каждым i связано его физическое имя. Мы могли бы и оставить свои физические имена (А, В, С), но тогда бы пришлось резервировать большую область памяти.
А * ( В + С )
| | | | | | | - эти связи должны храниться;
1 2 4 1 3 1 5 - на стадии лексического анализатора каждый символ получает свое индивидуальное имя, проверяется синтаксис (см. прошлый семестр).
1. E:=E+T
2. E:=T
3. T:=T*F
4. T:=F
5. F:=(E)
6. F:=i
Для "6." P(p)=S(j);
Inc(p);
Для "5." и "4." ничего не делаем, продолжаем синтаксический анализ;
Для "3." P(p)='*'; // <T> и <F> уже существуют;
Inc(p); // заносим только '*';
Для "2." ничего не делаем, продолжаем синтаксический анализ;
Для "1." P(p)='+';
Inc(p).
Содержание стека |
R – текущий символ входной цепочки |
Остаток цепочки |
Результат – польская запись |
|
# |
|
— |
i*(i+i)# |
— |
# |
|
(A) – i |
*(i+i)# |
|
#i(A) #F |
Синтаксический анализатор вызвал п.6 и сразу заменил i на F |
* |
(i+i)# |
A |
#T* |
Замена по п.4 |
( |
i+i)# |
A |
#T*( |
|
(B) – i |
+i)# |
A |
#T*(i(B) #T*(F |
Замена по п.6 |
+ |
i)# |
AB |
#T*(E+ |
Замена по п.4, п.2 |
(C) - i |
)# |
AB |
#T*(E+i(C) #T*(E+F |
|
) |
# |
ABC |
#T*(E+T) #T*(E) |
Замена и вызов программы п.1 |
# |
— |
ABC+ |
#T*F #T |
Замена и вызов программы п.3 |
# |
— |
ABC+* |
#E |
|
# |
— |
ABC+* |
Триады и тетрады
Триады и тетрады представляют собой низкоуровневые формализмы записи промежуточного представления программы, приближающие программу к объектному коду. В этих формализмах все операции записываются в виде последовательности действий, выдающих результаты.
Тетрады (также называемые "четверками" или трехадресным кодом), состоят из двух операндов, разделенных операцией, и результата операции, записываемого с помощью равенства и обозначаемого целым числом (см. пример на слайде). Таким образом, тетрады содержат явную ссылку на результат операции. В каком-то смысле, это может считаться недостатком тетрад, так как при прямолинейной генерации кода приходится порождать по одной временной переменной на каждую операцию в программе.
Триады (также называемые "тройками" или двухадресным кодом), построены аналогичным образом, но не содержат явного указания на результат операции, хотя на эти результаты по-прежнему можно ссылаться в последующих командах. Подразумевается, что задачу отслеживания и нумерации всех триад выполняет сам компилятор. Понятно, что триады компактнее тетрад, но, с другой стороны, отсутствие явного указания на результат операции может затруднить фазу оптимизации. Эту проблему можно решить путем использования косвенных триад, в которых вместо ссылки на ранее использовавшуюся триаду используется ссылка на элемент специальной таблицы указателей на триады.
Естественно, триады и тетрады также могут быть расширены для записи всех операций, поддерживаемых на данной целевой платформе.