

Перевод индексной записи в тетрады
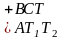 - префиксная запись.
- префиксная запись.
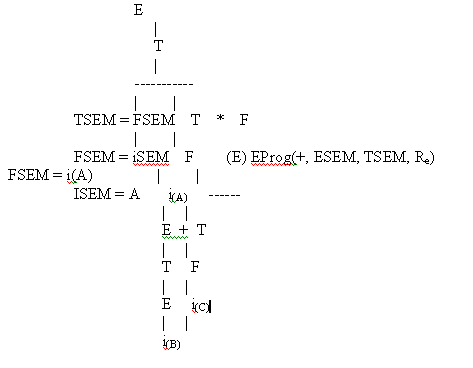
Сканер, распознавая идентификатор, выдает два значения: некоторую внутреннюю форму и его физические имя. На имя, где происходит замена Е+Т на Е, семантическая программа должна выдать тетраду. Однако это сделать нельзя, так как сентенциальная форма не содержит информации о физических именах Е и Т, эта информация была потеряна в первой редукции, когда было использовано правило F:=i.
При польской записи эта проблема не возникала, так как выходная цепочка формировалась при первой редукции. Для решения этой задачи используем некоторую семантическую подпрограмму, которая будет передавать имя встретившегося идентификатора поэтапно в процессе редукции.
Назовем ее:
FSEM = i(A); EProg(+, ESEM, TSEM, Re);
TSEM = FSEM; вызывается, как только встречается Е+Т;
ESEM = TSEM; Re – результат.


3.5. Теория перевода
3.5.1. Формализмы определения перевода
Перевод (трансляция) – это некоторое отношение между цепочками, т.е. некоторое множество пар цепочек. Существует два метода определения перевода:
Схема перевода – грамматика, снабженная механизмом, обеспечивающим выходную цепочку для каждой порождаемой.
Распознаватель с выходом, который на каждом такте анализируемой цепочки в алфавите S может выдать цепочку ограниченной длины в алфавите D.
Пусть:
S - входной алфавит;
D - выходной;
 .
.
Тогда переводом языка L1 в L2 назовем отношение Т, такое, что
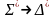 ,
где
,
где
L1 – область определения,
L2 – множество значений.
Если
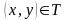 ,
то цепочка х – входная, а у – выходная.
,
то цепочка х – входная, а у – выходная.
В общем случае в переводе Т для каждой входной цепочки может быть более одной выходной, однако в языках программирования перевод должен быть с однозначной функцией.
Рассмотрим следующий пример: пусть требуется греческий алфавит перевести в русский:
Греческий алфавит |
Русский алфавит |
A, a |
Альфа |
B, b |
Вета |
Такой тип перевода называется гомоморфизмом, он для программирования не приемлем.
3.5.2. Синтаксически управляемый перевод
Транслятором, реализующим перевод Т, назовем устройство, которое по данной входной цепочке х вычисляет выходную цепочку у, такую, что .
Определим основные требования к такому транслятору:
определение перевода должно устанавливать однозначное соответствие между парами цепочек;
определение перевода должно быть легко алгоритмизировано;
время обработки входной цепочки должно линейно зависеть от
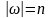 ;
;программа транслятора должна проверяться тестом конечной длины, гарантирующим правильность его работы.
Схема синтаксически управляемого перевода (СУ-перевода) представляет собой грамматику, в которой каждому правилу присоединяется элемент перевода.
Всякий раз, когда правило участвует в выводе входной цепочки, с помощью элемента перевода вычисляется часть выходной цепочки, порождаемой этим правилом.
Рассмотрим следующий пример:
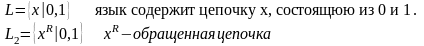 Пусть
имеется цепочка – 0011, необходимо
получить - 1100.
Пусть
имеется цепочка – 0011, необходимо
получить - 1100.
Порождающие правила |
Преобразующие правила |
S:=0S |
S:=S0 |
S:=1S |
S:=S1 |
S:=e |
S:=e |
|
|
Преобразование по правилам:
S=>0S, S0=>00S, S00=>001S, S100=>0011S, S1100=> 0011, 1100.
Схема
трансляции определяет перевод Т. По
этой схеме можно построить транслятор,
реализующий перевод
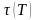 ,
работающий следующим образом: по данной
входной цепочке х с помощью правил схемы
трансляции должен быть построен некоторый
вывод цепочки у.
,
работающий следующим образом: по данной
входной цепочке х с помощью правил схемы
трансляции должен быть построен некоторый
вывод цепочки у.
-
Правила порождающей грамматики Pi
Правила выходной грамматики P0
E+T
T
T*F
F
(E)
ET+
T
TF*
F
E
Польская запись
Пусть имеется цепочка: i+i*i.
Преобразование по правилам:
E=>E+T, ET+=>T+T, TT+=>F+T, FT+=>i+T, iT+=>i+T*F, iTF*+=>i+F*F, iFF*+=>i+i*F, iiF*+=>i+i*i, iii*+.
Этот метод проще, так как здесь нет необходимости в подпрограмме, но преобразование по нему происходит дольше.
Схемой СУ-перевода называют цепочку символов:
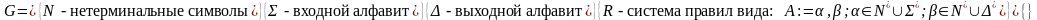
Пусть А:=a,b. Каждому вхождению некоторого нетерминала в цепочку a, соответствует вхождение того же нетерминала в цепочку b. Если нетерминал (В) входит в цепочку 1 раз, то соответствие очевидно, если больше одного раза, то требуется индексировать.
Пусть
A:=BcB, BBc. Если
 ,
то не ясно, где какое В брать. При
индексации же этой проблемы не возникает:
A:=B1cB2, B1B2c.
,
то не ясно, где какое В брать. При
индексации же этой проблемы не возникает:
A:=B1cB2, B1B2c.
Если
 - СУ-схема, то
называется СУ-транслятором.
- СУ-схема, то
называется СУ-транслятором.
Грамматики:
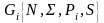 называется
входной;
называется
входной;
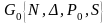 называется
выходной.
называется
выходной.
СУ-перевод можно трактовать как метод преобразования деревьев вывода входной грамматики G1 в деревья вывода выходной грамматики G0. Перевод цепочки х можно получить, построив дерево вывода, затем преобразовать это дерево в системе правил выходной грамматики и в качестве выходной цепочки взять крону выходного дерева.
Алгоритм работы синтаксически управляемого перевода
Вход: СУ – схема с входной грамматикой Gi {N, S, Pi, S}и дерево вывода D.
Выход: Дерево D’ в грамматике G0 {N, D, P0, S}.
Шаг 1: Применять шаг 2 начиная с корня D.
Шаг 2: Пусть этот шаг (2) применяется к вершине n, внутренней в дереве D, и пусть n1, nk – прямые потомки. Пусть А:=a - правило из Pi, соответствующее вершине n.
Цепочка a образуется конкатенацией меток n1…nk .
Выбрать из R правило А:=a, b и переставить вершины согласно соответствию, установленному этими правилами.
Применять шаг 2 к вершинам, не являющимся листьями.
Рассмотрим следующий пример, поясняющий алгоритм синтаксически управляемого перевода:
T= {(S,A), (0,1), (a,b), R, S};
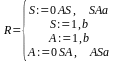
СУ – схема, у которой в правилах соответствия нетерминалов, однозначное называется простой.
D
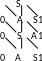 :
D’:
:
D’:
000111 bbbbaaa
S=> 0AS, SAa =>00SAS, SASaa =>000ASAS, SASAaaa => 0001111, bbbbaaa.
Необходима индексация.
Простые СУ – переводы образуют важный класс трансляторов, так как легко реализуются преобразованиями с магазинной памятью.