

Операторное предшествование
Предшествование операторов
При использовании грамматик простого предшествования отношения определялись между всеми символами как операндами, так и операторами. Техника предшествования операторов формализует понятие предшествования только между терминальными символами (операторами).
Грамматика G называется операторной грамматикой, если ни одно из её правил не имеют вида
U: = …VW… , где V,WÎVN, то есть рядом не могут стоять два нетерминала. Никакая сентенциальная форма не содержит двух соседних нетерминальных символов:
R ≗ S, если U: = …RS…|…RVS…, где R,SÎVT, VÎVN.
R∘>S, если U: = …WS… и W=>+…R|…RV
R<∘S, если U: = …RW… и W=>+S…|VS…
Построим отношение для грамматики: E: = E+T|T; T: = T*F|F; F: = (E)|i .
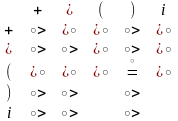
Вычисление отношений операторного предшествования. Алгоритм разбора на основе операторного предшествования
Алгоритм разбора на основе простого предшествования
Отношение Q ПЕТ R(R – первый терм из Q) имеет место тогда и только тогда, когда Q: = R…|VR…, а отношение Q ПОСТ R(R – последний терм из Q) имеет место тогда и только тогда, когда Q: = …R|…RV…, где V-нетерминальный символ.
U
… W S
∘>=(ПОСТ)Т ´ (ПОС) ´ (≐)
…Q
…R|RV
U
R W
<∘ =(≐)´(ПЕ)+´(ПЕТ)
Q…
S…|VS
Первичные фразы и их обнаружение
Для нахождения основ, состоящих из одного нетерминала, рассматриваемые отношения неприемлемы, так как по условию для нетерминалов их просто не существует. Основу с помощью операторного предшествования не отыскать. Введём подцепочку и назовём её первичной фразой.
Первичной фразой сентенциальной формы считается такая фраза, в которую входит, по крайней мере, один терминал и сама она не содержит других первичных фраз.
E
E + T
|
E + T F
| | |
T T*F i
T+T*F+i – сентенциальная форма.
Введём первичную фразу. T+T+F – некоторая подцепочка, в ней основа Т, но она не будет первичной фразой, так как не содержит терминала.
T*F – будет первичной фразой, так как содержит терминал и нет других первичных фраз.
i – будет первичной фразой, так как содержит терминал и нет других первичных фраз.
Запишем сентенциальную форму в общем виде: #N1T1N2T2N3T3…NnTn#. (N- нетерминал, Т- терминал).
Сентенциальная форма, таким образом, состоит из n- терминалов, причём между каждым соседним символом находится не более одного нетерминала.
Ti-1<∘ NiTi…NjTjNj+1∘>Tj+1 – первичная фраза.
Любой символ всегда находится в таком отношении: #<∘Tj∘># с дополнительными.
Сентенциальная форма |
Отношения |
Первичная фраза |
К чему приводится |
T+T*F+i |
#<∘+<∘* ∘>+ |
T*F |
Т |
Нетерминалы, стоящие слева и справа, принадлежат первичной фразе.
Следующий шаг: T+T+i #<∘+∘>+ T+T (нет такого правила) E.
Поэтому в процедуру разбора надо ввести некоторые семантические состояния, то есть анализ правила на наличие одного терминального символа из правила, то есть проведём замену Т на Е, такое правило есть:
-
# E+i #
# <∘+<∘i∘> #
i
F;
# E+F #
#<∘+∘>#
E+F
E.
Структура цепочки правильная и разбор окончен, если между # стоит нетерминал.