

3.3. Грамматики простого предшествования
3.3.1. Простые предшествования.
При использовании этого метода в текущей сентенциальной форме осуществляется поиск основы, которая в соответствии с правилами этой грамматики приводится к нетерминальному символу, стоящему в левой части. Будем искать основу сентенциальной формы, двигаясь слева направо, и рассматривать одновременно два соседних символа.
Пусть имеется цепочка … RS … . Здесь возможны ситуации:
Оба символа принадлежат основе (правой части правила)(U:= …RS…)
R≐S (одновременно)
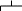 U
U
… R S …
R принадлежит основе, а S – нет (U:=…WS…; W=>+…R)
R⋗S (R раньше S)
U
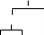
W
… R S
S принадлежит основе, а R – нет (U: = …RW…; W=>+S…)
R⋖S (R позже S)
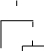 U
U
W
R S …
Пример: Имеется грамматика G(Z).
Z: = bMb;
M: = (L|a;
L: = Ma).
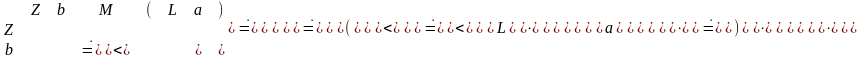
 Z
Z
b M b
( L
M a )
a
Если между какой-либо парой символов определено более чем одно отношение, использование матрицы невозможно. Если отношение единственно, то можно утверждать, что основой сентенциальной формы S1…Sn является подцепочка Si…Sj, для которой выполнено условие:
…Si-1⋖ Si ≐ Si+1 ≐ … ≐ Sj-1 ≐ Sj ⋗ Sj+1…
Пример: Возьмем цепочку b(аа)b.
-
Сентенциальная форма
Основа
Нетерминал, к которой приводится цепочка
Непосред-ственный вывод
#⋖b⋖(⋖a⋗a≐)⋗b#
a
M
M=> a
#⋖b⋖(⋖M≐a≐)⋗b#
Ma)
L
L=> Ma)
#⋖b⋖(≐L⋗b#
(L
M
M=>(L
#⋖b≐M≐b⋗#
bMb
Z
Z=>bMb
Отношения предшествования и их вычисление
R≐S тогда и только тогда, когда в грамматике G(Z) существуют правила: U: = … RS …
R⋗S тогда и только тогда, когда в грамматике существуют правила вида: U: = … R и имеется вывод W=>+S…, т.е. W PR+ S (S – префикс W).
R⋖S тогда и только тогда, когда в грамматике существуют правила вида: U: = …VW… и имеются выводы W=>+S…, V=>+…R (R – суффикс V).
U V S+ R , W PR+ S.
… V W …
… R S …
Вычисление отношений предшествования
R≐S, U: = …RS…
R⋖S, U: = …RW, W=>+S…
⋖ = (≐) ´ (PR+)
R⋗S, U: = …VW…, V=>+…R, W=>+S…
⋗ = (S+)T ´ (≐) ´ (1+PR+)
Грамматика G(Z) называется грамматикой простого предшествования или грамматикой 1.1 предшествования, если между двумя любыми символами из словаря определено не более чем одно отношение и ни у каких двух правил нет одинаковых правых частей. Запись 1.1 означает, что для принятия решения о том, действительно ли рассматриваемая часть сентенциальной формы является основой, используют по одному символу слева и справа от неё. Если S1 – начальный символ основы и вместе с тем
первый символ рассматриваемого предложения(сентенциальной формы), то символа S0 не существует. Для фиксации этого факта заключают предложение между некоторыми символами, не являющимися символами грамматики: Sj ⋗ # или # ⋖ Sj .
Алгоритм разбора
Отношение предшествования представляется двумерным массивом, элементы которого имеют следующие значения:
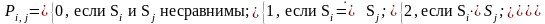
Правила находятся в таблице. Организация таблицы должна позволять по заданной правой части указать соответствующую левую. Символы входной цепочки просматриваются слева направо и заносятся в стек до тех пор, пока не окажется, что верхний символ стека находится в отношении раньше(⋗) следующему сканируемому символу предложения. Это означает, что верхний символ стека является концом основы. Затем, двигаясь в обратном направлении, определяют верхнюю границу основы, далее её находят в списке правил (основу), и она заменяется соответствующим нетерминалом. Процесс продолжается до тех пор, пока в стеке не окажется символ Z и следующим входным символом не станет #.