

5.2.2. Непараметрические методы
однофакторного анализа
Если предположение о нормальности распределения выборки не является правомерным или наблюдаются качественные показатели, следует использовать различные методы непараметрического анализа, среди которых наиболее развиты ранговые методы.
Рассмотрим таблицу наблюдений (см. табл.5.1) (однофакторный дисперсионный анализ). Сформулируем гипотезу Н0 о том, что расхождение наблюдений в сериях опытов для различных уровней факторов можно объяснить только случайными причинами. На статистическом языке это предположение означает, что все данные таблицыxij принадлежат одному и тому же распределению. Рассмотрим ранговый однофакторный анализ.
Если мы ничего не знаем о распределении xij, то в этом случае проще опираться в своих выводах на отношения «больше – меньше» между наблюдениями, т.к. они не зависят от распределения наблюдений. При этом вся информация содержится в тех рангахrij, что получают числаxijпри упорядочении всей их совокупности. Ранговые критерии применяются и тогда, когда измерения сделаны впорядковой шкале, например, представлены текстовыми баллами или экспертными суммами. Здесь значенияxij вообще являются условностью, а содержательный смысл имеют лишь отношения «больше – меньше» между ними (например, оценки 2,3,4,5). Будем рассматривать наиболее простой случай, когда среди чиселxij нет совпадающих. В этом случае преобразование табл.5.1 в табл. 5.4 будет однозначным.
Таблица 5.4. Форма представления преобразованных данных
|
Ранги результатов наблюдений |
Уровни | |||||
|
1-й |
2-й |
… |
i-й |
… |
k-й | |
|
1 |
|
|
|
|
|
|
|
|
… |
… |
|
… |
|
… |
|
j |
|
|
|
|
|
|
|
|
… |
… |
|
… |
|
… |
|
n |
|
|
|
|
|
|
Для проверки гипотезы Н0необходимо сконструировать некоторую статистику, т.е. функцию от ранговrij, которая легла бы в основу критерия проверки гипотезы. Основные требования к этой статистике следующие: ее значение при гипотезеН0должно заметно отличаться от ее значений при альтернативах. Рассмотрим два метода.
5.2.2.1. Однофакторный непараметрический анализ
на основе критерия Краскела–Уоллеса (произвольные
альтернативы)
Этот метод используется, когда невозможно сказать что-либо определенное об альтернативах Н0, т.к. он свободен от распределения. Заменим наблюдения xij их рангами rij, упорядочивая всю совокупность ||xij|| в порядке возрастания. Затем для каждой обработки i (уровня фактора, столбца таблицы) надо вычислить суммарный и средний ранги:
|
|
(5.13) |
Если между столбцами
нет систематических различий, то средние
ранги
![]() не должны значительно отличаться от
среднего, рассчитанного по всей
совокупности ||rij||.
Значение последнего
не должны значительно отличаться от
среднего, рассчитанного по всей
совокупности ||rij||.
Значение последнего![]() .
ЗдесьN– общее
число наблюдений.
.
ЗдесьN– общее
число наблюдений.![]() .
Вычислим величины дисперсий
.
Вычислим величины дисперсий![]() для каждого уровня фактора
для каждого уровня фактора![]() ,
...,
,
...,![]() .
.
Эти значения при Н0в совокупности должны быть небольшими. Составляя общую характеристику, разумно учесть различия в числе наблюдений для разных обработок (уровней факторов) и взять в качестве меры отступления от чистой случайности величину
|
|
(5.14) |
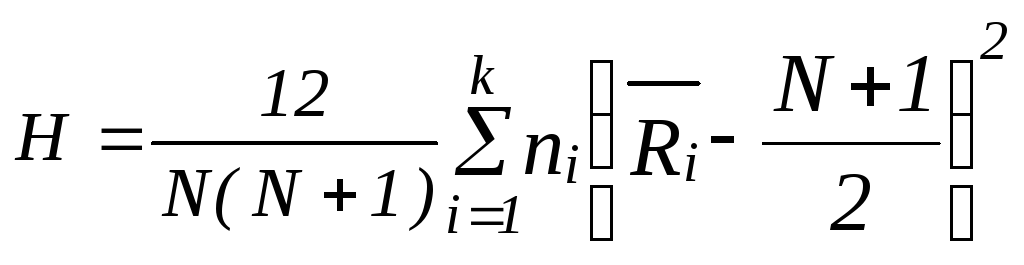 .
.
Эта
величина называется статистикой
Краскела–Уоллеса.
Множитель
![]() присутствует в качестве нормировочного
для обеспечения сходимости распределения
статистикиН
и
присутствует в качестве нормировочного
для обеспечения сходимости распределения
статистикиН
и
![]() с
числом степеней свободы
с
числом степеней свободы![]() .
ГипотезаН0
отвергается
при уровне значимости q;
если
.
ГипотезаН0
отвергается
при уровне значимости q;
если
![]() ,
то фактор считается значимым.
,
то фактор считается значимым.
Если среди xij
есть совпадающие значения, то при
ранжировании и переходе кrij
надо использовать средние
ранги (например, если 2 значения (5 и 5)
занимают ранги 11, 12, то средний ранг
(11,5) надо присвоить им обоим). Если
совпадений много, рекомендуется
использовать модифицированную форму
статистики![]() :
:
|
|
, (5.15) |
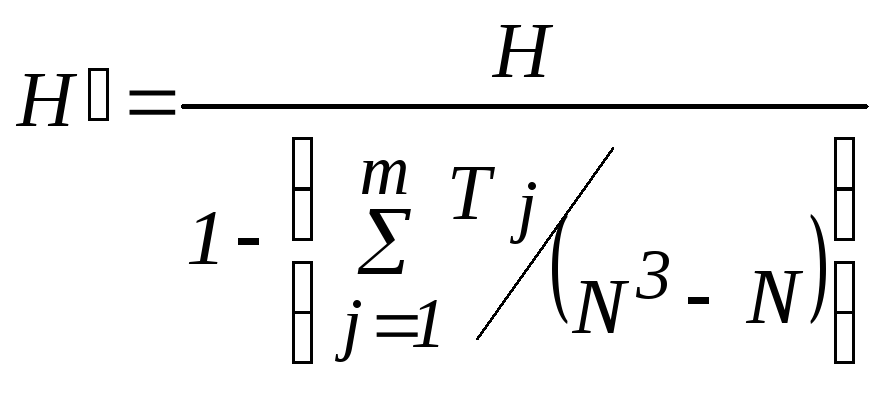
где
m
– число групп совпадающих наблюдений
![]() (
(![]() –число совпадающих наблюдений в
группеj).
–число совпадающих наблюдений в
группеj).
При числе уровней фактора k = 2 статистика Краскела Н по своему действию эквивалентна статистике Уилконсона, W – ранговый критерий в парных наблюдениях.
Пример 5.2. Для выяснения влияния денежного стимулирования на производительность труда шести однородным группам из 5 человек были предложены задания одинаковой трудности. Задания предлагались каждому испытуемому независимо от остальных. Группы отличались величиной денежного вознаграждения за решаемую задачу. Данные (число решаемых задач) приведены в табл. 5.5.
Таблица 5.5. Исходные данные к примеру 5.2
|
Наблюдения |
Уровни | |||||
|
Гр.1 |
Гр.2 |
Гр.3 |
Гр.4 |
Гр.5 |
Гр.6 | |
|
1 |
10 |
8 |
12 |
12 |
24 |
19 |
|
2 |
11 |
10 |
17 |
15 |
16 |
18 |
|
3 |
9 |
16 |
14 |
16 |
22 |
27 |
|
4 |
7 |
13 |
9 |
16 |
18 |
25 |
|
5 |
13 |
12 |
16 |
19 |
20 |
24 |
Решение. Проверим гипотезу Н0 об отсутствии эффектов обработки (отсутствии влияния денежного вознаграждения). Поскольку закон распределения xij неизвестен, воспользуемся ранговыми критериями.
В связи с наличием совпадений необходимо воспользоваться средними рангами. Так, xij = 10 встречается дважды и при упорядочении xij занимает 5-е и 6-е места. Поэтому средний ранг xij = 10 равен 5,5. В результате ранжирования получаем таблицу (табл. 5.6).
Таблица 5.6. Ранжированные данные
|
Наблюдения |
Уровни | |||||
|
Гр.1 |
Гр.2 |
Гр.3 |
Гр.4 |
Гр.5 |
Гр.6 | |
|
1 |
5,5 |
2 |
9 |
9 |
27,5 |
23,5 |
|
2 |
7 |
5,5 |
20 |
14 |
17 |
21,5 |
|
3 |
3,5 |
17 |
13 |
17 |
26 |
30 |
|
4 |
1 |
11,5 |
3,5 |
17 |
21,5 |
29 |
|
5 |
11,5 |
9 |
17 |
23,5 |
25 |
27,5 |
|
Ri |
28,5 |
45 |
62,5 |
80,5 |
117 |
131,5 |
|
|
5,7 |
9 |
12,5 |
16,1 |
23,4 |
26,3 |
В двух нижних
строках приведены суммы рангов Ri
и средние ранги![]() по столбцам. Вычислим статистику
Краскела–Уоллеса при общем числе
наблюденийN =30, числе опытов
при каждом значении фактораnj
=5,j = 1,2,3...6. Подставляя эти
значения, получим
по столбцам. Вычислим статистику
Краскела–Уоллеса при общем числе
наблюденийN =30, числе опытов
при каждом значении фактораnj
=5,j = 1,2,3...6. Подставляя эти
значения, получим .
.
Величина Нимеет распределение![]() .
По таблицам распределения
.
По таблицам распределения![]() для степеней свободы
для степеней свободы
![]() находим,
что минимальный уровень значимостиq
чуть больше 0,001, что слишком мало,
чтобы принять гипотезуН0.
находим,
что минимальный уровень значимостиq
чуть больше 0,001, что слишком мало,
чтобы принять гипотезуН0.
Для учета влияния
совпадений в ||xij||
можно воспользоваться статистикой![]() .
.
В нашем случае 8групп совпадающих наблюдений:
9,9; 10,10; 12,12,12; 13,13; 16,16,16,16,16; 18,18; 19,19; 24,24.
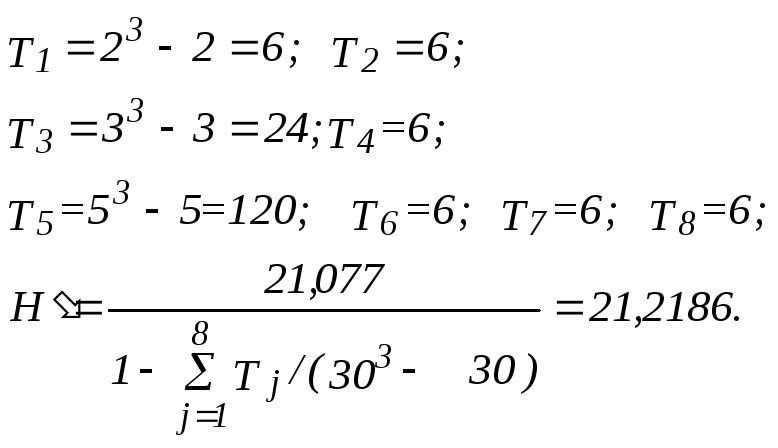
Так как
скорректированное значение
![]() мало
отличается отН, мы можем отвергнуть
гипотезуН0при минимальном уровне значимостиq= 0,001.
мало
отличается отН, мы можем отвергнуть
гипотезуН0при минимальном уровне значимостиq= 0,001.
Задания для самостоятельной работы
1. На предприятии сделана выборка дневного объема реализации одного и того же товара (в тыс.ед.), но различных его сортов (фактор А). Число наблюдений n = 7 (неделя). Установите, влияет ли сорт на объем реализации товара (табл. 5.7).
Таблица 5.7. Исходные данные
|
Наблюдения (дни) |
Уровни фактора А (сорт) | ||
|
1-й сорт |
2-й сорт |
3-й сорт | |
|
1 |
14,5 |
7,9 |
5,3 |
|
2 |
12,5 |
8,6 |
6,0 |
|
3 |
16,2 |
5,5 |
4,0 |
|
4 |
14,7 |
9,3 |
6,4 |
|
5 |
15,1 |
8,5 |
6,0 |
|
6 |
14,5 |
6,8 |
5,0 |
|
7 |
13,8 |
9,4 |
4,5 |
2. Сформулируйте задачу обработки экспериментальных данных с использованием критерия Краскела–Уоллеса. Подготовьте выборку исходных данных статистической задачи и приведите её решение.