

Лекция 6. Постановка задачи кодирования. Первая теорема Шеннона.
Теория кодирования информации является одним из разделов теоретической информатики. К основным задачам, решаемым в данном разделе информатики, необходимо отнести следующие:
разработка принципов наиболее экономичного кодирования информации;
согласование параметров передаваемой информации с особенностями канала связи;
разработка приемов, обеспечивающих надежность передачи информации по каналам связи, то есть отсутствие потерь информации.
Как отмечалось при рассмотрении исходных понятий информатики, для представления дискретных сообщений используется некоторый алфавит. Однако часто однозначное соответствие между содержащейся в сообщении информацией и его (сообщения) алфавитом отсутствует.
В целом ряде практических приложений возникает необходимость перевода сообщения из одного алфавита в другой, причем такое преобразование не должно приводить к потере информации.
Введем ряд определений.
Будем считать, что источник информации представляет информацию в форме дискретного сообщения, используя для этого алфавит, который мы условимся называть первичным алфавитом. Далее это сообщение попадает в устройство, преобразующее и представляющее сообщение в другом алфавите – этот алфавит мы назовемвторичным алфавитом.
Код – это правило, описывающее соответствие знаков или сочетаний знаков первичного алфавита знакам или сочетаниям знаков вторичного алфавита.
При этом существует и другое определение:
Код – это набор знаков или сочетаний знаков вторичного алфавита, используемый для представления знаков или сочетаний знаков первичного алфавита.
Кодирование – это перевод информации, представленной сообщением в первичном алфавите, в последовательность кодов.
Декодирование – это операция, обратная кодированию, то есть восстановление информации в первичном алфавите по полученной последовательности кодов.
Кодер – это устройтство, обеспечивающее выполнение операции кодирования.
Декодер – это устройство, производящее декодирование.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо ее потерь.
Примером обратимогокодирования является представление знаков в телеграфном коде и их восстановление (получателем) после передачи.
Примером необратимогокодирования может служить перевод с одного естественного языка на другой. При этом обратный перевод, вообще говоря, не восстанавливает исходного текста. Здесь важно понимать, что исходная информация восстанавливается с потерями как в смысловом отношении, так и в смысле искажения в форме представления (полученная после обратного перевода последовательность знаков первичного алфавита практически всегда уже другая по сравнению с исходным текстом).
Безусловно, для практических задач, связанных со знаковым представлением информации, возможность восстановления информации по ее коду является необходимым условием применимости кода, поэтому в дальнейшем мы ограничимся только рассмотрением обратимого кодирования.
Кодирование информации предшествует передаче и хранению информации. При этом хранение информации связано с фиксацией некоторого состояния носителя информации, а передача информации связана с процессом изменения состояния носителя информации (среды), то есть с сигналами. Эти состояния или сигналы мы будем называть элементарными сигналами.Совокупность элементарных сигналов и составляет вторичный алфавит.
Сейчас мы не будем обсуждать технические стороны передачи и хранения сообщения, то есть не будем обсуждать то, каким образом технически реализованы передача и прием последовательности сигналов или фиксация состояний носителя информации (запись информации).
Попробуем сделать математическуюпостановку задачи кодирования информации.
Пусть первичный алфавит
![]() состоит из
состоит из![]() знаков со средней информацией на знак
знаков со средней информацией на знак![]() ,
а вторичный алфавит
,
а вторичный алфавит![]() состоит из
состоит из![]() знаков со средней информацией на знак
знаков со средней информацией на знак![]() .
Пусть также исходное сообщение,
представленное в первичном алфавите,
содержит
.
Пусть также исходное сообщение,
представленное в первичном алфавите,
содержит![]() знаков, а закодированное сообщение
(представленное во вторичном алфавите)
содержит
знаков, а закодированное сообщение
(представленное во вторичном алфавите)
содержит![]() знаков. Таким образом, исходное сообщение
содержит
знаков. Таким образом, исходное сообщение
содержит![]() информации, а закодированное сообщение
содержит
информации, а закодированное сообщение
содержит![]() информации.
информации.
Операция обратимого кодирования может увеличить количество информации в сообщении, но не может его уменьшить:
![]() .
.
Это неравенство можно переписать как
![]() или
или
![]() .
.
Отношение
![]() характеризует среднее число знаков
вторичного алфавита, которое приходится
использовать для кодирования одного
знака первичного алфавита.
характеризует среднее число знаков
вторичного алфавита, которое приходится
использовать для кодирования одного
знака первичного алфавита.
Величину
![]() будем называть длиной кода или длиной
кодовой цепочки:
будем называть длиной кода или длиной
кодовой цепочки:
![]() .
.
Из предыдущего неравенства
![]() следует, что
следует, что![]() ,
поэтому:
,
поэтому:
![]() . (7.1)
. (7.1)
Обычно на практике процедуру кодирования реализуют таким образом, что выполняется условие
![]() ,
,
поэтому
![]() ,
то есть один знак первичного алфавита
представляется несколькими знаками
вторичного алфавита.
,
то есть один знак первичного алфавита
представляется несколькими знаками
вторичного алфавита.
Способов построения кодов при фиксированных
алфавитах
![]() и
и![]() существует множество. Поэтому возникает
проблема выбора (или построения)
наилучшего варианта кода – будем
называть егооптимальным кодом.
существует множество. Поэтому возникает
проблема выбора (или построения)
наилучшего варианта кода – будем
называть егооптимальным кодом.
Выгодность применения оптимального кода при передаче и хранении информации – это экономический фактор, так как более эффективный код может позволить затратить на передачу сообщения меньше энергии и времени. В случае применения оптимального кода при передаче информации может меньшее время заниматься линия связи. Применение оптимального кода при хранении информации может позволить использовать меньше площади поверхности (объема) носителя информации.
При этом следует осознавать, что выгодность кода не всегдаидентична временной выгодности всего процесса «кодирование–передача– декодирование». Возможна ситуация, когда за использование эффективного кода при передаче информации придется расплачиваться тем, что операции кодирования и декодирования будут занимать больше времени и/или иных ресурсов (памяти технического устройства, если эти операции производятся с его помощью).
Как следует из условия (7.1), минимально возможное значение средней длины кодаравно:
![]() . (7.2)
. (7.2)
Данное выражение следует воспринимать
как соотношение оценочногохарактера,
устанавливающее нижний предел длины
кода. Однако, из (7.2) неясно, в какой
степени в реальных схемах кодирования
возможно приближение величины![]() к значению
к значению![]() .
.
По этой причине для теории кодирования и теории связи важное значение имеют теоремы, доказанные Шенноном. Первая теорема Шеннона затрагивает ситуацию с кодированием при отсутствии помех, искажающих сообщение. Вторая теорема Шеннона относится к реальным линиям связи с помехами и будет обсуждаться нами позже.
Первая теорема Шеннона, илиосновная теорема о кодировании при отсутствии помех, формулируется так:
При отсутствии помех всегда возможен такой вариант кодирования, при котором среднее число знаков кода, приходящихся на один знак первичного алфавита, будет сколь угодно близко к отношению средних информаций на знак первичного и вторичного алфавитов.
Данная теорема утверждает принципиальную
возможность оптимального кодирования,
то есть построения кода со средней
длиной, имеющей значение
![]() .
.
Однако необходимо сознавать, что из самой этой теоремы никоим образом не следует, как такое кодирование осуществить практически. Для разработки практической реализации оптимального кодирования должны привлекаться дополнительные соображения, которые мы обсудим далее.
Из (7.2) видно, что имеются два пути
сокращения величины
![]() :
:
Уменьшение числителя, то есть
 .
Это возможно, если при кодировании
учесть различие частот появления разных
знаков в сообщении, учесть корреляции
двухбуквенные, трехбуквенные и так
далее (
.
Это возможно, если при кодировании
учесть различие частот появления разных
знаков в сообщении, учесть корреляции
двухбуквенные, трехбуквенные и так
далее ( );
);Увеличение знаменателя, то есть
 .
Для этого необходимо применить такой
способ кодирования, при котором появление
знаков вторичного алфавита было бы
равновероятным, то есть
.
Для этого необходимо применить такой
способ кодирования, при котором появление
знаков вторичного алфавита было бы
равновероятным, то есть .
Как известно, при равенстве частот
появления знаков некоторого алфавита
в сообщении информация на знак этого
алфавита максимальна.
.
Как известно, при равенстве частот
появления знаков некоторого алфавита
в сообщении информация на знак этого
алфавита максимальна.
К. Шеннон подробно рассмотрел следующую
частную ситуацию. В этой ситуации при
кодировании сообщения учитывается
различная вероятность появления знаков
в первичном алфавите, то есть величина
информации, приходящейся на знак
первичного алфавита, рассчитывается в
первом приближении:
![]() . Однако корреляции знаков первичного
алфавита не учитываются. Источники
подобных сообщенийназываются
источниками без памяти(на корреляции
знаков первичного – своего – алфавита).
Если при этом обеспечена равная
вероятность появления знаков вторичного
алфавита, то, как следует из (7.2), для
минимальной средней длины кода
. Однако корреляции знаков первичного
алфавита не учитываются. Источники
подобных сообщенийназываются
источниками без памяти(на корреляции
знаков первичного – своего – алфавита).
Если при этом обеспечена равная
вероятность появления знаков вторичного
алфавита, то, как следует из (7.2), для
минимальной средней длины кода![]() оказывается справедливым соотношение:
оказывается справедливым соотношение:
![]() . (7.3)
. (7.3)
В качестве меры превышения
![]() над
над![]() можно ввестиотносительную избыточность
кода
можно ввестиотносительную избыточность
кода![]() :
:
![]() .
.
С учетом (7.2) последнюю формулу можно переписать в виде
 , (7.4)
, (7.4)
причем
![]() .
.
Величина
![]() показывает, как сильно операция
кодирования увеличила длину исходного
сообщения. Очевидно, что
показывает, как сильно операция
кодирования увеличила длину исходного
сообщения. Очевидно, что
![]() при
при
![]() .
.
Таким образом, решение проблемы
оптимизации кодирования состоит в
нахождении таких схем кодирования,
которые обеспечили бы приближение
средней длины кода к значению
![]() ,
а относительной избыточности
,
а относительной избыточности![]() кода – к нулю. Чем меньше значение
кода – к нулю. Чем меньше значение![]() ,
тем возникает меньше избыточной
информации, то есть информации, связанной
с кодированием; более выгодным оказывается
код и более эффективной становится
операция кодирования.
,
тем возникает меньше избыточной
информации, то есть информации, связанной
с кодированием; более выгодным оказывается
код и более эффективной становится
операция кодирования.
Используя понятие избыточности кода, можно построить иную формулировку первой теоремы Шеннона:
При отсутствии помех всегда возможен такой вариант кодирования сообщения, при котором избыточность кода будет сколь угодно близкой к нулю.
Наиболее важной для практики оказывается
ситуация, когда во вторичном алфавите
![]() ,
то есть когда для представления кодов
в линии связи используется лишь два
типа сигналов. Такое кодирование
называетсядвоичным кодированием.
Технически это наиболее просто реализуемый
вариант. Например, существование
напряжения в проводе (импульс) или его
отсутствие (пауза); наличие или отсутствие
отверстия на перфокарте; наличие или
отсутствие намагниченной области на
дискете и так далее
,
то есть когда для представления кодов
в линии связи используется лишь два
типа сигналов. Такое кодирование
называетсядвоичным кодированием.
Технически это наиболее просто реализуемый
вариант. Например, существование
напряжения в проводе (импульс) или его
отсутствие (пауза); наличие или отсутствие
отверстия на перфокарте; наличие или
отсутствие намагниченной области на
дискете и так далее
Знаки двоичного алфавита принято
обозначать «0» и «1», эти знаки нужно
воспринимать как буквы. Удобство двоичных
кодов также и в том, что при равных
длительностях и вероятностях каждый
элементарный сигнал (0 или 1) несет в себе
ровно 1 бит информации (![]() ).
).
В случае двоичного вторичного алфавита
(обозначим
![]() )
из формулы (7.3) получаем:
)
из формулы (7.3) получаем:
![]() ,
,
и первая теорема Шеннона получает еще одну (третью) формулировку:
При отсутствии помех средняя длина двоичного кода может быть сколь угодно близкой к средней информации, приходящейся на знак первичного алфавита.
Таким образом, при кодировании сообщений источника без памяти двоичными знаками равной вероятности по формуле (7.4) находим:
![]() . (7.5)
. (7.5)
При декодировании двоичных сообщений возникает проблема выделения из потока сигналов (последовательности импульсов и пауз) кодовых слов(групп элементарных сигналов), соответствующих отдельным знакам первичного алфавита. При этом приемное устройство фиксируетинтенсивностьидлительностьсигналов, а также может соотносить последовательность поступающих сигналов с эталонными последовательностями (стаблицей кодов).
Отметим следующие особенности двоичноговторичного алфавита, используемого при кодировании:
Элементарные сигналы (0 и 1) могут иметь одинаковые длительности (
 )
или разные длительности (
)
или разные длительности (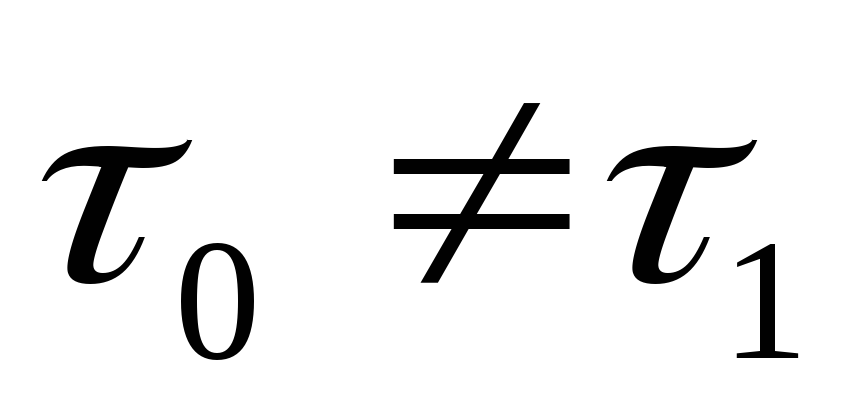 );
);Длинакода может бытьодинаковойдля всех знаков первичного алфавита (в этом случаекодназываетсяравномерным); или же коды разных знаков первичного алфавита могут иметьразличнуюдлину (неравномерный код);
Коды могут строиться для отдельногознака первичного алфавита (алфавитноекодирование) или длякомбинацийзнаковпервичного алфавита (кодирование слов, блоков –блочноекодирование).
Комбинации перечисленных особенностей вторичного алфавита определяют основу конкретного способа кодирования сообщений. Однако, даже при одинаковой основе возможны различные варианты построения кодов, которые будут отличаться своей эффективностью.