

136 7 Package Diagram
7.2 Clustering
Clustering is a general technique aimed at gathering the entities that compose a system into cohesive groups (clusters). Clustering has several applications in program understanding and software reengineering [4, 54, 99], and has been recently applied to Web applications [52, 65].
Given a system consisting of entities which are characterized by a vector of properties (feature vector) and are connected by mutual relationships, there are two main approaches to clustering [4]: the sibling link and the direct link approach. In the sibling link approach, entities arc grouped together when they possess similar properties, while in the direct link approach they are grouped together when the mutual relationships form a highly interconnected sub-graph.
Main issues in the application of the sibling link approach are the choice of the features to consider in the feature vectors, the definition of an appropriate similarity measure based on such features and the steps for the computation of the clusters, given the similarity measures. The following section, Feature Vectors, examines such issues in detail.
In the direct link approach, clustering is reduced to a combinatorial optimization problem. Given the relationships that connect entities with each other, the goal of clustering is to determine a partition of the set of entities which concurrently minimizes the connections that cross the boundaries of the clusters and maximizes the connections among entities belonging to a same cluster. Details for the application of this approach are provided in the following section, Modularity Optimization.
7.2.1 Feature Vectors
A feature vector is a multidimensional vector of integer values, where each dimension in the vector corresponds to one of the features selected to describe the entities, while the coordinate value represents the number of references to such a feature found in the entity being described. Selection of the appropriate features to use with a given system is critical for the quality of the resulting clusters, and may be guided by pre-existing knowledge about the software.
In the literature, several different features have been used to characterize procedural programs, with the aim of remodularizing them [4, 54, 99]. Some of such features apply to Object Oriented software as well, and can be used to derive a package diagram from the source code of the classes in the system under analysis. Examples of such features are the following:
User-def types: Declaration of attributes, variables or method parameters whose type is a user defined type.
Method calls: Invocation of methods that belong to other classes.
The rationale behind the two kinds of features above is that classes operating on the same data types or using the same computations (method calls)
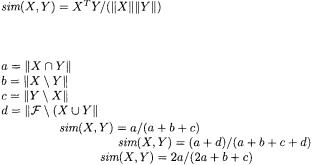
7.2 Clustering |
137 |
are likely to be functionally close to each other, so that clustering is expected to group them together.
In addition to the syntactic features considered above, informal descriptive features can be exploited for clustering as well. For example, the words used in the identifiers defined in each class under analysis or in the comments are informal descriptive features that may give a useful contribution to clustering. The main limitations of informal features are that they depend on the ability of the code to be self-documenting and that they may be not up to date, if they have not been evolved along with the code. On the other side, they are more abstract than the syntactic features, being closer to a human understanding of the system.
Once the features to be considered in the feature vectors have been selected, a proper similarity measure has to be defined. It will be used by the clustering algorithm to compare the vectors. The entities with the most similar feature vectors are inserted in a same cluster. In alternative to the similarity measure, it is possible to define a distance measure and to group vectors at minimum distance. Usually, similarity measures are favored over distance measures, because they have a better behavior in presence of empty or quasiempty descriptions. In fact, if most (all) of the entries in two feature vectors are zero, any distance measure will have a very low value, thus suggesting that the two entities should be clustered together. However, it may be the case that the two entities are very dissimilar and that the low distance is just a side effect of the quasi-empty description. Consequently, it is preferable to use similarity, instead of distance, measures, in presence of quasi-empty descriptions.
Among the various ways in which similarity between two vectors can be defined, the metrics most widely used in software clustering are the normalized product (cosine similarity) and the association coefficients.
Normalized product: Normalized vector product of the feature vectors:
Association coefficients: Derived metrics are based on the following coefficients:
Jaccard:
Simple Matching:
Sørensen-Dice:
The normalized product gives the scalar product between two vectors, reduced to unitary norm. Thus, it measures the cosine of the angle between the vectors. The normalized product is maximum (+1) when the two vectors are
138 7 Package Diagram
co-linear and have the same direction, i.e., the ratio between the respective components is a positive constant: 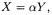 with
with 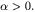 In the general case, the normalized product is minimum (-1) when the two vectors are co-linear, but have opposed directions:
In the general case, the normalized product is minimum (-1) when the two vectors are co-linear, but have opposed directions: 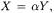 with
with 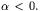 However, since feature vectors associated with software components count the number of references to each feature in each component, the coordinate values are always non negative and the normalized product is correspondingly always greater than or equal to zero. Thus, the minimum value of the normalized product is not -1 for the feature vectors we are interested in. Such a minimum, equal to 0 under the hypothesis of non negative coordinates, is obtained when the two vectors are orthogonal with each other, that is, when non-zero values occur always at different coordinates. In other words, two vectors with non negative coordinates have zero normalized product if the first has zeros in the positions where the second has positive values, and vice-versa.
However, since feature vectors associated with software components count the number of references to each feature in each component, the coordinate values are always non negative and the normalized product is correspondingly always greater than or equal to zero. Thus, the minimum value of the normalized product is not -1 for the feature vectors we are interested in. Such a minimum, equal to 0 under the hypothesis of non negative coordinates, is obtained when the two vectors are orthogonal with each other, that is, when non-zero values occur always at different coordinates. In other words, two vectors with non negative coordinates have zero normalized product if the first has zeros in the positions where the second has positive values, and vice-versa.
Association coefficients are used to compute various different similarity metrics, among which the Jaccard, the Simple Matching, and the SørensenDice similarities. These coefficients are based on a view of the feature vectors as the characteristic function of sets (of features). Thus, the first coefficient,  measures the number of features that are common to the two vectors X and Y, i.e., the intersection between the sets of features represented in the two feature vectors. Coefficients
measures the number of features that are common to the two vectors X and Y, i.e., the intersection between the sets of features represented in the two feature vectors. Coefficients 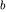 and
and  measure the number of features in the first (second) set but not in the second (first).Coefficient
measure the number of features in the first (second) set but not in the second (first).Coefficient 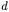 measures the number of features that are neither in X nor in Y
measures the number of features that are neither in X nor in Y 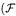 is the set of all features).
is the set of all features).
Given the four association coefficients, several similarity metrics can be defined, based on them. For example, the Jaccard similarity metric counts the number of common features  over the total number of features in the two vectors
over the total number of features in the two vectors 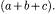 It is 1 when X and Y have exactly the same features, while it is 0 when they have no common feature. The Simple Matching similarity metric gives equal weight to the common
It is 1 when X and Y have exactly the same features, while it is 0 when they have no common feature. The Simple Matching similarity metric gives equal weight to the common  and to the missing
and to the missing 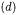 features. This metric is equal to 1 when two vectors have the same common and missing features, i.e., coefficients
features. This metric is equal to 1 when two vectors have the same common and missing features, i.e., coefficients 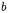 and
and  are zero. In other words, no feature exists which belong to one vector but not to the other. The Simple Matching metric is zero when each feature belongs exclusively to the first or to the second vector (no common and no commonly missing feature). Finally, the SørensenDice similarity metric is a variant of the Jaccard metric, in which the common features are counted twice, because they are present in both vectors.
are zero. In other words, no feature exists which belong to one vector but not to the other. The Simple Matching metric is zero when each feature belongs exclusively to the first or to the second vector (no common and no commonly missing feature). Finally, the SørensenDice similarity metric is a variant of the Jaccard metric, in which the common features are counted twice, because they are present in both vectors.
In the literature, several different clustering algorithms have been investigated [99], with different properties. Among them, hierarchical algorithms are the most widely used in software clustering. Hierarchical algorithms do not produce a single partition of the system. Their output is rather a tree, with the root consisting of one cluster enclosing all entities, and the leaves consisting of singleton clusters. At each intermediate level, a partition of the system is available, with the number of clusters increasing while moving downward in the tree.

7.2 Clustering |
139 |
Hierarchical algorithms can be divided into two families: divisive and agglomerative algorithms. Divisive algorithms start from the whole system at the tree root, and then divide it into smaller clusters, attached as children of each tree node. On the contrary, agglomerative algorithms start from singleton clusters and join them together incrementally.
Fig. 7.2. Agglomerative clustering algorithm.
Fig. 7.2 shows the main steps of the agglomerative clustering algorithm. After creating a singleton cluster for each feature vector, the algorithm merges the most similar clusters together, until one single cluster is produced. It will be the root of the resulting clustering hierarchy.
A critical decision in the implementation of this algorithm is associated to step 3. While it is obvious how similarity between singleton clusters is measured, since it just accounts for applying the metric chosen among those presented above, the similarity between clusters that contain more than one entity can be computed in different, alternative ways. Given two clusters 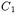 and
and 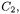 containing respectively
containing respectively 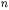 and
and  entities, their similarity is computed from the similarities
entities, their similarity is computed from the similarities 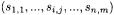 between each pair of contained entities, according to so-called linkage rules. Among the linkage rules reported in the literature, the most widely used in software clustering are the single linkage and the complete linkage:
between each pair of contained entities, according to so-called linkage rules. Among the linkage rules reported in the literature, the most widely used in software clustering are the single linkage and the complete linkage:
Single linkage (or closest neighbor):
Complete linkage (or furthest neighbor):
Single linkage is known to give less coupled clusters, while complete linkage gives more cohesive clusters (with cohesion measuring the average similarity between any two entities clustered together, and coupling measuring the average similarity between any two entities belonging to different clusters).
Since feature vectors tend to be sparse, coupling naturally tends to be low. As a consequence, more importance is typically given to cohesion, so that the complete linkage is the typical rule of choice.
An alternative approach to computing the similarity between clusters is offered by the combined clustering algorithm [70]. In this approach, clusters are also associated with feature vectors that describe them. Initially, singleton