

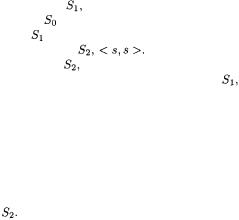
170 8 Conclusions
no invocation of addReservation (neither of the removal methods) can ever occur in 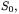 due to the checks performed in the code issuing such invocations. Specifically, the only invocation to addReservation is inside method reserveDocument of class Library, where the call is issued only if the document being reserved is not available. This implies that at least one loan must exist
due to the checks performed in the code issuing such invocations. Specifically, the only invocation to addReservation is inside method reserveDocument of class Library, where the call is issued only if the document being reserved is not available. This implies that at least one loan must exist 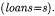
In |
state |
loans can be added and removed. In the latter case, the new |
|
state is |
when no loan remains inside the Collection loans. Moreover, in |
||
state |
reservations can be made, since not all documents are available. This |
||
leads to state |
|
||
In state |
loans and reservations can be added and removed. If eventually |
||
no reservation remains, the new state is |
a state already described above. |
||
If method removeLoan is called when exactly one loan is active in the library, the new state is a fourth one 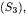 never encountered before, characterized by an empty set of loans and some reservations pending. It should be noted that this state is not reachable directly from the initial state
never encountered before, characterized by an empty set of loans and some reservations pending. It should be noted that this state is not reachable directly from the initial state 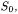 since reservations cannot be added when no loans are present. Thus, the only way to reach it is to go through all the other states,
since reservations cannot be added when no loans are present. Thus, the only way to reach it is to go through all the other states, 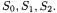
If all reservations are cleared in state 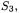 the final state that is reached is
the final state that is reached is 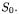 On the other side, if loans are added, the state of the library goes back to
On the other side, if loans are added, the state of the library goes back to
State diagrams are useful in understanding how the introduction of the reservation mechanism affects the internal states of the classes. The new attributes reservations and reservation inside the classes User and Document are not influenced by the other class attributes, similarly to the original attributes loans and loan in the same classes. On the contrary, in the class Library, loans and reservations are mutually related. Their joint description given in the state diagram of Fig. 8.8 highlights the permitted transitions in each state and the possible paths from one state to another one. This is potentially useful to support comprehension of the changed system and of the differences with respect to the original one. It will also help in the definition of test cases for the changed classes, particularly when the state-based testing approach is being used [6, 92]. In fact, this may turn out to be its primary use.
8.3 Perspectives
The authors’ position is that all the information about a program should be in the source code. From a purely observational point of view, the well-known effects of software evolution, consisting of a progressive misalignment of source code and other sources of information about a program, entail that only the source code is reliable. So, de-facto, most information about a program is in the source code. On the prescriptive side, one could take as the extreme
8.3 Perspectives |
171 |
consequence the fact that everything should be part of the code (including design, documentation, etc.).
The first view gives a central role to reverse engineering in the future of software development. Although this discipline was born with the problems of legacy systems in mind, new software systems, developed according to modern programming paradigms such as the Object Oriented one, are not free from the problems related to program comprehension and modification. As described in this book, the comprehension problems involved in understanding Object Oriented systems are different from those arising with more traditional software, but remain the main concerns during the evolution phase. Reverse engineering has the potential to address them.
The view in which all relevant information about a program is centralized in a single source, the code, comes from the Extreme Programming (XP) development process [36]. In this methodology, limited effort is devoted to design and design documents are not maintained over time. They are considered a temporary support to communication and understanding, that is abandoned when software engineers move to the implementation. The absence of design information is mitigated by pair programming, by continuous execution of refactoring, and by the description of functionalities in terms of test cases. Reverse engineering can make an important contribution here [93]. In fact, understanding the organization of an application and of the interactions among its objects is a quite difficult task in the XP setting. As discussed in this book, there are several diagrams that can be extracted automatically from the source code and approximate quite well this kind of information.
Looking at the emerging programming languages and paradigms, we can hypothesize an increasing role of reverse engineering. Programming languages tend to evolve so as to maintain very precise information about the program’s behavior in the source code. Modern compilers rely on this information to perform several checks, optimizations and transformations. Examples of this kind of information are type parameters (genericity) and metadata (e.g., annotations), that will be included in the next version (1.5) of the Java language. Aspect Oriented Programming [40] and introspection capabilities (e.g., Java reflection, OpenJava) are going in the same direction, in that they support a programmable interface to the internal units of a program.
All this has a twofold effect. On one hand, it simplifies reverse engineering, in that the source code becomes a richer information repository, that can be queried automatically by tools. On the other hand, it makes the design diagrams reverse engineered from the source code much more meaningful and useful, in that they are based on information directly encoded in the program (and checked by the compiler), instead of using information inferred by means of approximate static or dynamic analysis methods. Availability of accurate diagrams easily extracted from the code will make the reverse engineering option even more appealing, getting closer to the XP vision that everything is in the source code. In fact, maintaining and evolving multiple descriptions of a software system is much too expensive and error prone. Only by focusing on