


2
The Object Flow Graph
The Object Flow Graph (OFG) is the basic program representation for the static analysis described in the following chapters. The OFG allows tracing the flow of information about objects from the object creation by allocation statements, through object assignment to variables, up until the storage of objects in class fields or their usage in method invocations.
The kind of information that is propagated in the OFG varies, depending on the purposes of the analysis in which it is employed. For example, the type to which objects are converted by means of cast expressions can be the information being propagated, when an analysis is defined to statically determine a more precise object type than the one in the object declaration. Thus, in this chapter a flow propagation algorithm is described, with a generic indication of the object information being processed.
In the first section of this chapter, the Java language is simplified into an abstract language, where all features related to the object flow are maintained, while the other syntactic details are dropped. This language is the basis for the definition of the OFG, whose nodes and edges are constructed according to the rules given in Section 2.2. Objects may flow externally to the analyzed program. For example, an object may flow into a library container, from which it is later extracted. Section 2.3 deals with the representation of such external object flows in the OFG. The generic flow propagation algorithm working on the OFG is described in Section 2.4. Section 2.5 considers the differences between an object insensitive and an object sensitive OFG. Details of OFG construction are given for the eLib program in the next Section. A discussion of the related works concludes this chapter.
2.1 Abstract Language
The static analysis conducted on Java programs to reverse engineer design diagrams from the code is data flow sensitive, but control flow insensitive. This means that programs with different control flows and the same data flows are
22 2 The Object Flow Graph
associated with the same analysis results. Data flow sensitivity and control flow insensitivity are achieved by defining the analyses with reference to a program representation called the Object Flow Graph (OFG). A consequence of the control flow insensitivity is that the construction of the OFG can be described with reference to a simplified, abstract version of the Java language. All Java instructions that refer to data flows are properly represented in the abstract language, while instructions that do not affect the data flows at all are safely ignored. Thus, all control flow statements (conditionals, loops, etc.) are not part of the simplified language. Moreover, in the abstract language name resolution is also simplified. All identifiers are given fully scoped name, being preceded by a dot separated list of enclosing packages, classes and methods. In this way, no name conflict can ever occur.
The choice of a data flow sensitive/control flow insensitive program representation is motivated by two main reasons: computational complexity and the “nature” of the Object Oriented programs. As discussed in Section 2.4, the theoretical computational complexity and the practical performances of control flow insensitive algorithms are substantially superior to those of the control flow sensitive counterparts. Moreover, the Object Oriented code is typically structured so as to impose more constraints on the data flows than on the control flows. For example, the sequence of method invocations may change when moving from an application which uses a class to another one, while the possible ways to copy and propagate object references remains more stable. Thus, for Object Oriented code, where the actual method invocation sequence is unknown, it makes sense to adopt control flow insensitive/data flow sensitive analysis algorithms, which preserve the way object references are handled.
Fig. 2.1 shows the abstract syntax of the simplified Java language. A Java program P consists of zero or more occurrences of declarations ( D), followed by zero or more statements ( S ) . The actual ordering of the declarations and of the statements is irrelevant, due to the control flow insensitivity. The nesting structure of packages, classes and methods is completely flattened. For example, statements belonging to different methods are not divided into separate groups. However, the full scope is explicitly retained in the names (see below). Consequently, a fine grain identification of the data elements is possible, while this is not the case for the control elements (control flow insensitivity).
Transformation of a given Java program into its abstract language representation is an easy task, that can be fully automated. Program transformation tools can be employed to achieve this aim.
2.1.1 Declarations
Declarations are of three types: attribute declarations (production (2)), method declarations (production (3)) and constructor declarations (4). An attribute declaration consists just of the fully scoped name  of the attribute, that is, a dot-separated list of packages, followed by a dot-separated list of
of the attribute, that is, a dot-separated list of packages, followed by a dot-separated list of

2.1 Abstract Language |
23 |
Fig. 2.1. Abstract syntax of the simplified Java language.
classes, followed by the attribute identifier. A method declaration consists of the fully scoped method name  (constructed similarly to the class attribute name
(constructed similarly to the class attribute name 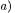 followed by the list of formal parameters
followed by the list of formal parameters 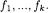 In turn, each formal parameter
In turn, each formal parameter  has
has 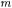 (the fully scoped method name) as prefix, and the parameter identifier as dot-separated suffix. Constructors have an abstract syntax similar to that of methods, with class names (<cid>) instead of method names (<mid>). Declarations do not include type information, since this is not required for OFG construction.
(the fully scoped method name) as prefix, and the parameter identifier as dot-separated suffix. Constructors have an abstract syntax similar to that of methods, with class names (<cid>) instead of method names (<mid>). Declarations do not include type information, since this is not required for OFG construction.

24 2 The Object Flow Graph
e.Lib example
Let us consider the class Library of the eLib program (see Appendix A). The abstraction of its attribute loans, of type Collection (line 6), consists just of the fully scoped attribute name:
The declaration of its method borrowDocument (line 56) is abstracted into:
The declaration of its implicit constructor (with no argument) is abstracted into:
2.1.2 Statements
Statements are of three types (see Fig. 2.1): allocation statements (production (5)), assignment statements (production (6)) and method invocations (production (7)). The left hand side  of all statements (optional for method invocations) is a program location. The right hand side
of all statements (optional for method invocations) is a program location. The right hand side 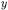 of assignment statements, as well as the target
of assignment statements, as well as the target 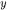 of method invocations, is also a program location. Program locations (<progloc>) are either local variables, class attributes or method parameters. The former have a structure identical to that of formal parameters: dot-separated package/class prefix, followed by a method identifier, followed by variable identifier. Chains of attribute accesses are replaced by the last field only, fully scoped (e.g., a.b.c becomes B.c, assuming b of class B and class B containing field c). The actual parameters
of method invocations, is also a program location. Program locations (<progloc>) are either local variables, class attributes or method parameters. The former have a structure identical to that of formal parameters: dot-separated package/class prefix, followed by a method identifier, followed by variable identifier. Chains of attribute accesses are replaced by the last field only, fully scoped (e.g., a.b.c becomes B.c, assuming b of class B and class B containing field c). The actual parameters  in allocations and method invocations are also program locations (<progloc>). The variable identifier (<vid>) that terminates a program location admits two special values: this, to represent the pointer to the current object, and return, to represent the return value of a method. Program locations (including formal and actual parameters) of non object type (e.g., int variables) are omitted in the chosen program representation, in that they are not associated to any object flow. Class names in allocation statements (production (5)) consist of a dot-separated list of packages followed by a dot-separated list of classes.
in allocations and method invocations are also program locations (<progloc>). The variable identifier (<vid>) that terminates a program location admits two special values: this, to represent the pointer to the current object, and return, to represent the return value of a method. Program locations (including formal and actual parameters) of non object type (e.g., int variables) are omitted in the chosen program representation, in that they are not associated to any object flow. Class names in allocation statements (production (5)) consist of a dot-separated list of packages followed by a dot-separated list of classes.