

Методи обробки текстової інформації.
В процессе обработки текстовой информации возникают два направления:
1) Анализ содержания информации: синтаксический и семантический
2) Форматирование текста для последующего представления или печати.
Общая
схема синтаксической обработки
содержания текстовой информации
инвариантна по отношению к естественному
языку. И может быть представлена на
рисунке
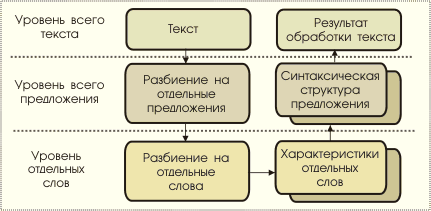
Каждая стадия разбивается на этапы, которые учитывают особенности естественного языка и сокращения. Каждый этап реализуется с применение различных алгоритмов, в том числе и ИИ.
После синтаксического анализа наступает фаза семантического анализа. Семантический анализ служит как для извлечения информации из текста, так и для генерации правильно построенных текстов. Данный вид анализа базируется на смысловом значении слов.
Данный вид анализа применяется для таких задач, как: автоматическое реферирование и автоматический машинный перевод. Основные требования, предъявляемые к реферату: он должен отражать основные идеи и моменты текста, а также, реферат должен являться корректно построенным текстом. Известны два основных направления в решении этой проблемы: удаление из исходного текста всех «ненужных» предложений и самостоятельное построение реферата исходного текста. Основные сложности, связанные с первым подходом, заключаются в определении ключевых предложений текста, и затем связи этих предложений в единый, удобочитаемый текст. Второй подход включает в себя три этапа: анализ текста и построение его формального описания, выбор из этого описания ключевых моментов, формирование реферата. На сегодняшний день имеются как научные, так и коммерческие разработки систем реферирования, способные обрабатывать русскоязычные тексты.
Автоматический машинный перевод – это одна из старейших задач искусственного интеллекта и на текущий момент представлено множество коммерческих систем, способных переводить несложные тексты.
Вторым направлением обработки текста является его форматирование. Для решения этой задачи создано и создается множество программных систем, среди которых и MS Word.
Здесь все начинается с форматирования одного символа: установки его типа и размера шрифта, угла наклона, подчеркивание, цвет. После чего устанавливаются расстояния между символами в слове(кернинг).
Важнейшей структурной единицей текста при форматирования является абзац. Для него задаются поля, отступы, межстрочное расстояние, отступы до и после него, выравнивание текста(по центру, па правому или левому краю, по ширине), цвет фона.
Заканчивается форматирование текста-заданием параметров страницы, таких как размер, ориентация, количество колонок, границы, разрывы и др.
Технології розробки об’єктно-орієнтованих застосувань.
OLE (Object Linking and Embedding) – технология связывания и внедрения объектов в другие документы и объекты. Данные, разделяемые между приложениями называются OLE-объектом. Приложение, которое может содержать OLE объекты, называют OLE-контейнером. Приложение, данные из которого можно включить в OLE контейнер в виде OLE объекта, называют OLE-сервером. OLE-объекты можно либо присоединить к OLE-контейнеру, либо включить в него. В первом случае данные будут храниться в файле на диске, любое приложение будет иметь доступ к этим данным и сможет вносить изменения. Во втором случае данные включаются в OLE-контейнер и только он сможет просматривать и модифицировать эти данные. OLE позволяет встроить в приложение обработку любых типов данных. Когда объект OLE помещен в буфер обмена информацией, он сохраняется в оригинальных форматах Windows (таких как bitmap или metafile), и в своём собственном формате. Собственный формат позволяет поддерживающей OLE программе внедрить порцию другого документа, скопированного в буфер, и сохранить её в документе пользователя.
Недостатком OLE первой версии является неясность того, как компоненты должны предоставлять свои возможности друг другу, кроме того, установленные связи легко нарушить, например, в результате изменения маршрута доступа к файлу связанного объекта.
Для того чтобы разрешить эту проблему была разработана технология СОМ(Component Object Model - компонентная объектная модель)
Следующим эволюционным шагом стал OLE 2.0, сохранивший те же цели и задачи, что и предыдущая версия. OLE 2.0 стал надстройкой над архитектурой COM. Новыми особенностями стали автоматизация технологии drag-and-drop, in-place activation и structured storage.
СОМ определяет стандартный механизм, с помощью которого одна часть программного обеспечения предоставляет свои сервисы другой. В СОМ любая часть программного обеспечения реализует свои сервисы как один или несколько объектов СОМ. Каждый такой объект поддерживает один или несколько интерфейсов, состоящих из методов. Методы, составляющие каждый из интерфейсов, обычно определенным образом взаимосвязаны. Клиенты могут получить доступ к сервисам объекта СОМ только через вызовы методов интерфейсов объекта – у них нет непосредственного доступа к данным объекта. Чтобы вызывать методы интерфейса объекта СОМ, клиент должен получить указатель на этот интерфейс, затем клиент может использовать сервисы объекта, просто вызывая методы этого интерфейса, как обычные процедуры. Большим недостатком технологии СОМ является отсутствие контроля версий компонентов, что часто называют «ад DLL». Эту проблему решает технология, представленная компанией Microsoft в 2002 году – .NET.
.NET Framework представляет собой дополнительный операционный слой, разделяющий приложения пользователя и базовые сервисы Windows. NET Framework состоит из двух главных компонентов: библиотеки базовых классов и CLR (Common Language Runtime – общая для языков среда исполнения NET-приложений), которые соответственно предназначены для решения следующих задач: - унификации библиотек функций для всех приложений, независимо от используемого языка программирования; - повышения управляемости приложений с точки зрения безопасности и эффективного использования ресурсов.
Программа может писаться на множестве платформо-независимых языков высокого уровня, код которых затем компилируется в промежуточный код IL. Затем, во время выполнения программы, лишь только та часть кода, которая должна быть выполнена компилируется в машинный код и сразу же выполняется.Объединение отдельных .NET-компонентов в одно приложение непосредственно связано с новым понятием “сборка” (Assembly). В сущности, сборка – это и есть .NET-приложение, она реализуется в виде расширенного варианта традиционного исполняемого модуля. Сборка может состоять из одного или нескольких файлов, причем они могут содержать не только исполняемый код, но также и графические изображения, исходные данные и прочие ресурсы. В архитектуре .NET сборки являются минимальным блоком, на уровне которого решаются вопросы внедрения, контроля версий, повторного использования и безопасности. Описание сборки содержится в секции метаданных (она называется манифестом) исполняемого модуля приложения.
недостатками технологии являются потеря производительности примерно на 10-15%, что связано с необходимостью компилирования кода из IL в машинный. А также необходимость наличия предустановленных библиотек Framework.