

5. Дисперсионный анализ: однофакторная модель.
Дисперсионный анализ объединяет значительное число задач математической статистики, в которых анализируется влияние тех или иных факторов на конечный результат. Предлагается к рассмотрению простейшая модель, в которой проверяется гипотеза о влиянии одного фактора.
Пусть имеется k независимых выборок
 (5.1)
(5.1)
Все параметры m1; m2; …; mk; σ2 – неизвестны.
Проверяются гипотезы – H0 : m1 = m2 = … = mk = т ,
альтернативы
– H1
:
i
≠ j,
такие, что ![]() ≠.
≠. ![]() .(5.2)
.(5.2)
Такая
задача возникает, например, в следующей
ситуации. Пусть на k
однотипных станках производятся или
обрабатываются одинаковые детали. На
выходе у каждой детали замеряется
некоторый параметр (например, диаметр).
Он является случайной величиной
вследствие неизбежных отклонений от
стандарта. Получаются те самые k
выборок,
причём индекс i
= 1 ÷ k
нумерует
станки, а индекс j=
1 ÷
![]() перечисляет детали, прошедшие через
конкретный станок.
перечисляет детали, прошедшие через
конкретный станок.
Гипотеза H0 утверждает, что неважно через какой станок прошла конкретная деталь – фактор станка не играет роли. Это соответствует тому, что средние значения всех выборок совпадают. Конкурирующая же гипотеза утверждает о наличии систематических отклонений для некоторых станков.
В более общем случае, можно трактовать рассмотренные выборки как отдельные группы в общем множестве наблюдений. Тогда гипотеза H0 утверждает, что это множество однородно – точнее, все наблюдения извлечены из одной генеральной совокупности, распределённой нормально с Φ(m, σ2). Альтернативная гипотеза говорит о том, что на множестве наблюдений действует хотя бы один посторонний фактор, что и вызывает расслоение множество наблюдений на неоднородные группы.
Для решения поставленной задачи рассмотрим следующие величины:
 –выборочные
средние;
–выборочные
средние;
 –
общее среднее, гдеN
=
–
общее среднее, гдеN
=
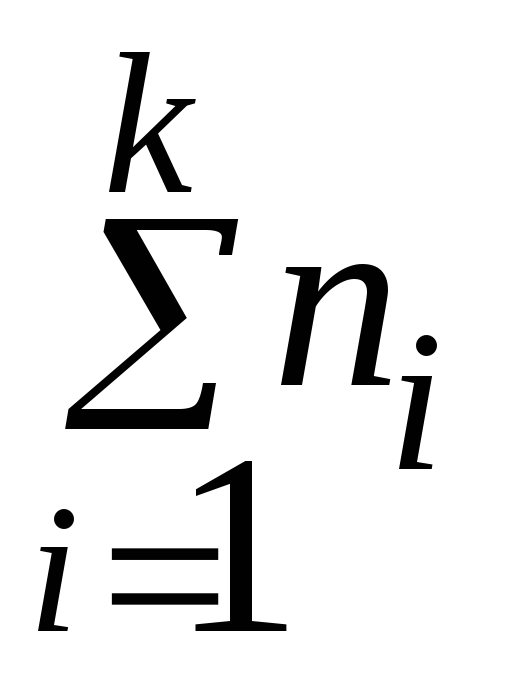 ;
Q1
=
;
Q1
=
 –
сумма квадратов отклонений между
выборками (группами) – характеризует
степень расхождения систематических
ошибок, т. е. рассеивание
по факторам
; Q2
=
–
сумма квадратов отклонений между
выборками (группами) – характеризует
степень расхождения систематических
ошибок, т. е. рассеивание
по факторам
; Q2
=
 –
внутригрупповая (выборочная) сумма
квадратов отклонений – характеризует
остаточное рассеяние, т. е. погрешности
отдельных опытов;
Q
=
–
внутригрупповая (выборочная) сумма
квадратов отклонений – характеризует
остаточное рассеяние, т. е. погрешности
отдельных опытов;
Q
=
 –
полная сумма квадратов отклонений
наблюдений от общего среднего.
–
полная сумма квадратов отклонений
наблюдений от общего среднего.
С помощью простых преобразований можно показать: Q = Q1 + Q2.
Если
верна гипотеза H0,
то Q
/(N
– 1) является
несмещённой оценкой для σ2,
а величина Q
/σ2
χ2N
– 1 ,
т. е. имеет хи-квадрат распределение с
N
– 1 степенью
свободы. Также в предположении верности
нулевой гипотезы все
![]() независимы
и распределены нормальноN(m,
σ2/
независимы
и распределены нормальноN(m,
σ2/![]() ).
Тогда их среднее арифметическое (т. е.
общее среднее) имеет оценку дисперсии
).
Тогда их среднее арифметическое (т. е.
общее среднее) имеет оценку дисперсии
 /(k
– 1) = kQ1/N(k
– 1),
т. е. величина Q1
/σ2
/(k
– 1) = kQ1/N(k
– 1),
т. е. величина Q1
/σ2
![]() .
Но и величинаQ2
/σ2
= Q
/σ2
– Q1
/σ2
=
.
Но и величинаQ2
/σ2
= Q
/σ2
– Q1
/σ2
=
 /σ2
/σ2
![]() =
=![]() –
–![]()
Нетрудно доказать, что Q2 и Q2 – независимы. Тогда справедлива теорема.
Теорема 5.1. Если верна гипотеза H0, то приведённая ниже величина имеет распределение Фишера с (k – 1) и (N – k) степенями свободы, т. е.
 .
(5.3)
.
(5.3)
Соотношение (5.3) задаёт критерий для проверки гипотезы H0 для однофакторного дисперсионного анализа. Задаваясь уровнем значимости гипотезы 1 – ε = 1 – q/100, по таблице распределения Фишера находим q – процентное критическое значение Fq . Гипотеза H0 принимается с вероятностью 1 – ε, если выполняется неравенство F ≤ Fq. Критическая область для данной гипотезы соответствует области решений уравнения P{ F > Fq} = ε = q/100.