

Методическое пособие Теория информации-2
.pdfЕсли внимательно посмотреть на строение приведенного на рис. 6.25
кодового дерева, можно заметить, что начиная с четвёртого ребра его структура повторяется, т.е. каким бы ни был первый шаг, начиная с четвёртого ребра значения выходных символов кодера повторяются. Другими словами, выходная кодовая последовательность в определённый момент перестает зависеть от значений входных символов, введенных в кодер ранее.
Действительно, из рис. 6.25 видно, что когда третий входной символ вводится в кодер, первый входной символ покидает сдвиговый регистр и не сможет в дальнейшем оказывать влияния на выходные символы кодера.
Одинаковые же узлы могут быть объединены, и тогда начиная с некоторого сечения размер кодового дерева перестанет увеличиваться. В этом случае мы получим кодовую решётку, представленную на рис. 6.24б.
Развитие теории свёрточных кодов происходило в соответствии с тремя основными методами декодирования: порогового декодирования,
последовательного декодирования и декодирование по максимуму правдоподобия (алгоритм Витерби).
Метод порогового декодирования свёрточных кодов аналогичен методу мажоритарного декодирования блочных кодов. Достоинством этого метода является простота алгоритма и реализующих его устройств. Число операций,
необходимых для декодирования одного информационного символа, не превосходит некой постоянной величины.
При пороговом декодировании свёрточных кодов вычисляются синдромы
(признаки места ошибочных символов). Затем эти синдромы или последовательности, полученные посредством линейного преобразования синдромов подаются на входы порогового элемента, где путём «голосования»
(мажоритарный метод) и сравнения его результатов с порогом выносится решение о значении декодируемого символа. Данный метод не полностью реализует потенциальные корректирующие возможности свёрточного кода.
Кроме того, не все свёрточные коды могут быть декодированы данным
211
методом. Чтобы свёрточный код допускал декодирование пороговым методом он должен обладать свойством ортогональности.
Метод последовательного декодирования относится к методам вероятностного декодирования, при котором число операций, необходимых для декодирования одного информационного символа, является случайной величиной (изменяется в зависимости от уровня шумов в канале). При практически приемлемой сложности устройств метод последовательного декодирования по своим характеристикам приближается к методу декодирования по максимуму правдоподобия.
При рассмотрении алгоритмов последовательного декодирования удобно представлять свёрточный код в виде кодового дерева. Каждая последовательность кодируемых информационных символов порождает определенный путь по кодовому дереву (на рис. 6.25 отображены пути для последовательностей символов 01000 и 11100). Задача декодера заключается в отыскании истинного пути, который был порождён кодером. Таким образом,
при алгоритмах последовательного декодирования декодер определяет наиболее правдоподобный путь по дереву, что позволяет исключить из анализа большую часть остальных путей, имеющих меньшее правдоподобие. Одним из критериев близости пути на кодовом дереве к пути, соответствующему истинной последовательности, является расстояние Хемминга между ними.
Возенкрафт предложил следующий алгоритм последовательного (символ за символом) декодирования: вначале на кодовом дереве ищется путь из -го ребра, соответствующая которому кодовая последовательность находится на каком-то определённом расстоянии от переданной последовательности кодированного сообщения и далее производят декодирование первого символа.
Декодирование второго и последующих информационных символов осуществляют таким же образом.
Другим алгоритмом последовательного декодирования является алгоритм, предложенный Фано, который предусматривает вычисление и
212
использование при декодировании наряду с ценой пути (мера отклонения от принятой последовательности) также некоторых порогов.
Алгоритм последовательного декодирования Фано ищет наиболее правдоподобный путь по кодовому дереву или решётке путём проверки каждый раз одного пути. Приращение, добавляемое к метрике ошибок вдоль ветви,
пропорционально вероятности принимаемого сигнала для этой ветви (как в алгоритме Витерби) за исключением того, что к метрике ошибок каждой ветви добавляется отрицательная константа. Величина этой константы выбирается так, что метрика ошибок правильного пути будет в среднем увеличиваться, в то время как метрика ошибок для любого неправильного пути в среднем будет уменьшаться. Путём сравнения метрики ошибок претендующего пути с меняющимся (увеличивающимся) порогом алгоритм Фано обнаруживает и отвергает неправильные пути.
Ещё одним известным алгоритмом последовательного декодирования является алгоритм Зигангирова, который иногда называют стек-алгоритмом,
поскольку для его реализации требуется память большей ёмкости, содержимое которой постоянно упорядочивается определённым образом. В стек-алгоритме более вероятные пути упорядочиваются согласно их метрикам, причём в верхней части (в голове стека) располагается путь, имеющий наибольшую метрику. На каждом шаге алгоритма только путь в голове стека проверяется по разветвлению. Эти продолжения вместе с другими путями затем упорядочиваются согласно величинам их метрик, и все пути с метриками,
которые располагаются ниже некоторой выбранной величины от метрики главного пути, отбрасываются. Затем процесс продолжения путей с наибольшими метриками повторяется.
В качестве метрики ошибок (расстояния Хемминга) путей по кодовому дереву при этом алгоритме также используется функция правдоподобия пути
(цена пути), но с добавлением элемента смещения, величина которого определяется исходя из скорости используемого кода и пропускной
213
способности канала связи путём оптимизации вероятности ошибки декодирования и среднего числа операции при декодировании одного информационного символа, которое является случайной величиной.
Очевидно, что если ни одно из продолжений пути с наибольшей метрикой не остаётся в голове стека, следующий шаг поиска выполняет продолжение другого пути, который приближается к голове стека. Отсюда следует, что стек-алгоритм не всегда даёт быстрое продвижение по начатой траектории при любой итерации. Следовательно, некоторую величину памяти нужно зарезервировать для вновь принятых символов и ранее принятых символов для того, чтобы позволить алгоритму расширить поиск по одному из более коротких путей, когда такой путь достигает головы стека.
При последовательном декодировании количество производимых декодером вычислений тем меньше, чем ниже уровень шумов в канале связи,
т.е. чем меньше ошибок возникает при приёме сообщений. Для компенсации неравномерности вычислений требуется включение в схему буферного запоминающего устройства между последовательным декодером и первой решающей схемой приёмника. Однако при всплеске вычислений,
происходящих при возникновении больших шумов в канале связи, возможно переполнение буферного запоминающего устройства, что приводит к отказу в декодировании.
Метод декодирования по максимуму правдоподобия (алгоритм Витерби)
более эффективен, чем метод порогового декодирования, однако, сложность устройств, необходимых для его реализации, возрастает экспоненциально с ростом длины кода. Рассмотрим данный метод декодирования более подробно.
Идея алгоритма Витерби состоит в том, что в декодере воспроизводят все возможные пути последовательных изменений состояний сигнала, сопоставляя получаемые при этом кодовые символы с принятыми аналогами по каналу связи и на основе анализа ошибок между принятыми и требуемыми символами определяют оптимальный путь по кодовой решётке: оптимальной считается та
214
последовательность символов, расстояние Хемминга которой от принятой последовательности минимально. Поиск в этом случае проводят по кодовой
решётке. Поясним работу декодера Витерби на примере ранее построенной
M
кодовой решётки для несистематического свёрточного кода с порождающими многочленами = 1 + + > и M> = 1+ > (рис. 6.24б).
Пример. Пусть в канал связи была передана последовательность из десяти символов, которая после свёрточного декодера имела вид: 00 11 10 00 01 10 01 11 11 10. При этом при приеме данная последовательность была искажена следующим образом: 00 11 11 00 11 10 01 11 11 10 (искажённые дибиты – последовательности из 2 символов – выделаны жирным начертанием).
Требуется, используя алгоритм Витербли, восстановить переданную в канал связи последовательность и восстановить исходную последовательность,
поступившую в кодер.
Зная начальное состояние кодера (00), а также возможные изменения этого состояния (00 и 10), построим временную диаграмму состояния кодера для первого момента времени (рис. 6.26а). На этой диаграмме из состояния 00
существует только два возможных пути, соответствующих различным входным дибитам. Первому пути – переход кодера из состояния 00 в 00 – соответствует выходная последовательность 00, соответственно метрика ошибок составит 0 (нет расхождений с принятой последовательностью). Второму пути – переход кодера из состояния 00 в 10 – соответствует выходная последовательность 11,
соответственно метрика ошибок составит 1 + 1 = 2 (расхождение в обоих символах). Рассчитанные метрики ошибок подписаны у узлов кодовой решётки для каждого из двух путей (рис. 6.26а).
Для следующего момента времени, соответствующего принятому дибиту
11, возможными будут два начальных состояния кодера: 00 и 10, а конечных состояния будет четыре: 00, 01, 10 и 11. Соответственно для этих конечных состояний существует несколько возможных путей, отличающихся друг от друга метрикой ошибок. При расчёте метрики ошибок необходимо учитывать
215
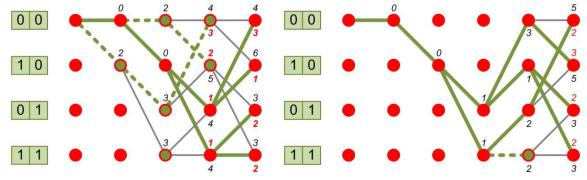
метрику предыдущего состояния, т.е. если для предыдущего момента времени метрика для состояния 10 была равной 2, то при переходе из этого состояния в состояние 01 метрика ошибок нового состояния (метрика всего пути) станет равной 2 + 1 = 3.
а |
б |
Рис. 6.26. Графические пояснения к алгоритму декодирования:
а – первые 4-е шага по кодовой рёшетке; б – первые 4-е шага по кодовой рёшетке после отсева не перспективных путей
Для следующего момента времени, соответствующего принятому ошибочному дибиту 11, отметим, что во все состояния кодера ведут по два пути. В этом случае необходимо оставить только те переходы, которым отвечает меньшая метрика ошибок. Отброшенные таким образом пути выделены на рис. 6.26 тонкими линиями. Кроме того, поскольку переходы из состояния 11 в состояние 11 и в состояние 01 отбрасываются, то переход из состояния 10 в состояние 11, отвечающий предыдущему моменту времени, не имеет продолжения и поэтому тоже может быть отброшен. Стоит отметить, что на данном шаге не существует нулевой метрики ошибок, поскольку дибит принят ошибочно.
На следующем такте работы декодера (анализ дибита 00) появляются уже две вершины, не имеющие продолжения в результате отбрасывания переходов,
имеющих большую вероятность: это состояние кодера на предыдущем шаге 00 (отброшены переходы 00 → 00, 00 → 10) и 10 (отброшены переходы 10 →
01, 10 → 11). При исключении данных вершин на предыдущих шагах также
216

появляются вершины, не имеющие продолжения. Таким образом, из анализа следует, что можно убрать пути, отмеченные на рис. 6.26а штриховой линией,
после чего количество возможных путей сократится, как показано на рис. 6.26б.
При анализе пятого дибита 11 появляется ещё одна вершина, не имеющего продолжения. При этом минимальная метрика ошибок становится равной 2, поскольку данный дибит также принят ошибочно.
Ход решения на шестом, седьмом и восьмом тактах для последовательности дибитов 10 01 11 приведен на рис. 6.27. На последнем такте работы декодера вновь появляется вершина, не имеющая продолжения.
Рис. 6.27. Графические пояснения к алгоритму декодирования
Возможные пути, соответствующие девятому и десятому такту работы декодера, отражены на рис. 6.28.
Рис. 6.28. Графические пояснения к алгоритму декодирования
Отметим, что на последнем такте появляются несколько путей, имеющих тупиковые вершины (отмечены штриховыми линиями). После их удаления останется четыре пути, часть из которых имеют альтернативные решения (в
217
одну и туже вершину можно прийти разными путями, см. рис. 6.29).
Рис. 6.29. Графические пояснения к алгоритму декодирования
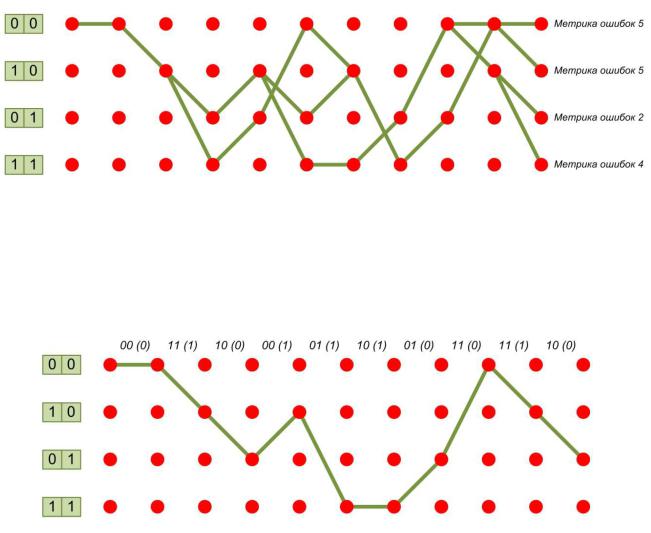
Из полученных вариантов выбираем путь с наименьшей метрикой ошибок, равной 2 (рис. 6.30).
Рис. 6.30. Путь с наименьшей метрикой ошибок при декодировании
По данному пути, пользуясь диаграммой состояния кодера (рис. 6.24),
можно однозначно восстановить последовательность символов на выходе из кодера, невзирая на допущенные ошибки при получении дибитов, а по ним восстановить исходную последовательность, поступившую в кодер. Таким образом, в канал связи была передана последовательность
00 11 10 00 01 10 01 11 10, соответственно исходная последовательность, к
которой было применено свёрточное кодирование, была 0101110010. Стоит отметить, что в случае отсутствия ошибок в приёме последовательности символов минимальная метрика будет равняться 0.
В рамках данного пособия рассмотрены далеко не все существующие на
218
сегодняшний момент коды и методы их декодирования. Однако приведенный объем информации достаточен, чтобы дать читателю общее представление по данному вопросу.
219
7. Методы сжатия изображений, аудио сигналов и видео
В настоящее время сжатие цифровых данных используются повсеместно.
Развитие Интернет-технологий, распространение широкополосного доступа в Интернет и создание мобильных цифровых устройств для записи, передачи,
хранения и воспроизведения текстовой и аудиовизуальной информации привело к тому, что количество информации, хранимой на устройствах памяти,
увеличивается быстрее, чем происходит совершенствование этих устройств, и,
как следствие, требует применение эффективных методов сжатия (компрессии).
Поскольку вопросам сжатия изображений, аудио и видео сигналов уделяется большое внимание, данный материал вынесен в отдельную главу.
7.1. Методы сжатия цифровых изображений
Все методы сжатия информации основаны на том простом предположении, что набор данных всегда содержит избыточные элементы.
Сжатие достигается за счет поиска и кодирования избыточных элементов.
Поток данных об изображении имеет существенное количество излишней информации, которая может быть устранена практически без заметных для глаза искажений. При этом различают два типа избыточности. Статистическая избыточность связана с корреляцией и предсказуемостью данных. Эта избыточность может быть устранена без потери информации, исходные данные при этом могут быть полностью восстановлены. Визуальная (субъективная)
избыточность, которую можно устранить с частичной потерей данных, мало влияющих на качество воспроизводимых изображений, это - информация,
которую можно изъять из изображения, не нарушая визуально воспринимаемое качество изображений. Прежде чем перейти к методам сжатии цифровых изображений рассмотрим, рассмотрим, что они из себя представляют.
7.1.1.Представление цифровых изображений
Компьютерное изображение в его цифровом представлении является
220