

Тема 6. Прогноз на основании линейной регрессии
План темы
6.1. Понятие о доверительном интервале
6.2. Алгоритм нахождения полуширины доверительного интервала
Понятие о доверительном интервале
Если
бы имелись сведения по всей генеральной
совокупности, то модно было бы довольно
точно найти статистические характеристики,
например,
![]() .
Но, как правило, имеется выборка, в
которой порядка десятка точек. По
выборке рассчитывают выборочное среднее
.
Но, как правило, имеется выборка, в
которой порядка десятка точек. По
выборке рассчитывают выборочное среднее![]() .
.
Истинное
значение
![]() может быть как больше, так и меньше
выборочного
может быть как больше, так и меньше
выборочного![]() ,
то есть точное значение
,
то есть точное значение![]() попадает в некоторый интервал, центром
которого является выборочное значение
попадает в некоторый интервал, центром
которого является выборочное значение![]() .
.
Если
задаться вероятностью
(например, 0,9; 0,99; 0,95) попадания
![]() в интервал, то чем больше будет задана
вероятность, тем шире будет получаться
интервал. Если начать уменьшать,
то интервал будет сужаться.
в интервал, то чем больше будет задана
вероятность, тем шире будет получаться
интервал. Если начать уменьшать,
то интервал будет сужаться.
Описанный
интервал называется доверительным
интервалом, а
- коэффициентом доверия. Чаще всего на
практике берут
![]() .
Это означает, что в 95% случаев точное
значение параметра попадает в интервал.
.
Это означает, что в 95% случаев точное
значение параметра попадает в интервал.
Доверительный интервал – это интервал, в который с заданной вероятностью попадает истинное значение неизвестного параметра.
Коэффициент доверия – это вероятность, с которой доверительный интервал накроет неизвестный параметр.
Алгоритм нахождения полуширины доверительного интервала
По
генеральной совокупности для конкретного
x
можно было бы довольно точно найти
прогноз
![]() .
По выборке строится линейная регрессия
.
По выборке строится линейная регрессия![]() и за
и за![]() принимают
принимают![]() ,
снятое с прямой регрессии.
,
снятое с прямой регрессии.
Доверительный
интервал, в который попадает неизвестное
![]() с некоторым коэффициентом доверия,
в случае линейной регрессии оказывается
симметричным относительно
с некоторым коэффициентом доверия,
в случае линейной регрессии оказывается
симметричным относительно
![]() .
Поэтому достаточно найти полуширину
доверительного интервала.
.
Поэтому достаточно найти полуширину
доверительного интервала.
При нахождении используется специально сконструированная статистика (случайная величина), распределенная по закону Стьюдента.
Распределение
Стьюдента
![]() возникает каждый раз, когда сравниваются
два математических ожидания (два
средних). Распределение Стьюдента
симметрично относительно начала
координат. Число степеней свободы для
критерия Стьюдента
возникает каждый раз, когда сравниваются
два математических ожидания (два
средних). Распределение Стьюдента
симметрично относительно начала
координат. Число степеней свободы для
критерия Стьюдента![]() .
.
Полуширина
доверительного интервала в точке
прогноза
![]() вычисляется по формуле:
вычисляется по формуле: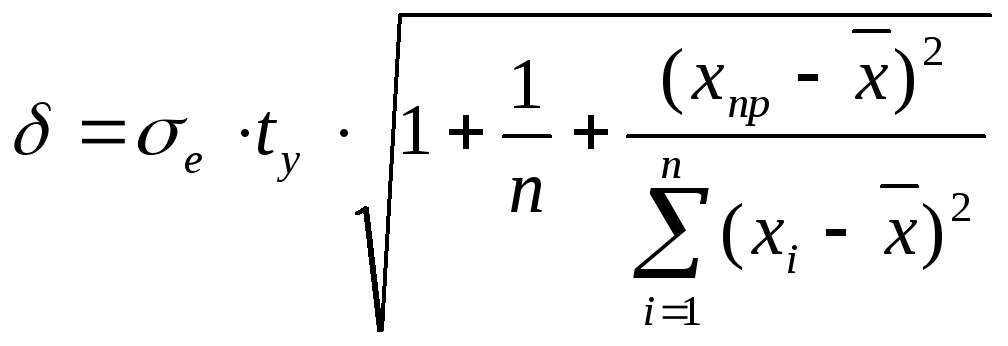 ,
,
где
![]() - среднеквадратичное отклонение
выборочных точек от линии регрессии
- среднеквадратичное отклонение
выборочных точек от линии регрессии![]() ,
здесь
,
здесь![]() ;
;
![]() -
критическая точка распределения
Стьюдента;
-
критическая точка распределения
Стьюдента;
![]() -
объем выборки;
-
объем выборки;
![]() -
точка из области прогнозов.
-
точка из области прогнозов.
Прогнозируемый
доверительный интервал для любого x
из области прогнозов записывается:
![]() .
.
Совокупность
доверительных интервалов для всех х
из области прогнозов образует доверительную
область. Для линейной однофакторной
регрессии она симметрична относительно
линии регрессии. Наиболее узкое место
доверительной области в точке
![]() .
.
Прогноз
для произвольного х
дает интервал, в который с вероятностью
попадает неизвестное
![]() .
То есть прогноз при заданномх
составит от
.
То есть прогноз при заданномх
составит от
![]() до
до![]() с надежностью
с надежностью![]() .
Это прогноз с учетом доверительного
интервала.
.
Это прогноз с учетом доверительного
интервала.
Тема 7. Нелинейная однофакторная модель
План темы
7.1. Линеаризация нелинейных зависимостей
7.2. Алгоритм построения нелинейных эконометрических моделей
Линеаризация нелинейных зависимостей
Многие экономические процессы не могут быть адекватно описаны линейной зависимостью. Примером таких экономических процессов могут служить: жизненный цикл товаров, процесс накопления капитала, маркетинговые усилия фирм и др.
Наиболее часто используется пять нелинейных зависимостей, которые предпочтительнее других зависимостей тем, что их удается линеаризовать (свести к линейным):
1.
Степенная зависимость:
![]() .
.
Для
линеаризации прологарифмируем это
уравнение:
![]() .
Обозначим
.
Обозначим![]() .
Получим линейную модель от новых
переменных:
.
Получим линейную модель от новых
переменных:![]() .
Обратное преобразование:
.
Обратное преобразование:![]() .
Значит,
.
Значит,![]() .
.
2.
Экспоненциальная зависимость:
![]() .
.
Чтобы
ее линеаризовать, прологарифмируем это
уравнение:
![]() .
Обозначим:
.
Обозначим:![]() .
Получим:
.
Получим:![]() .
Обратное преобразование:
.
Обратное преобразование:![]() .
Значит,
.
Значит,![]() .
.
3.
Логарифмическая зависимость:
![]() .
Сделаем замену:
.
Сделаем замену:![]() .
Получили:
.
Получили:![]() .
.
4.
Обратная зависимость:
![]() .
Сделаем замену:
.
Сделаем замену:![]() .
Получили:
.
Получили:![]() .
.
5.
Логистическая кривая:
![]() .
Сделаем замену:
.
Сделаем замену:![]() .
Получили:
.
Получили:![]() .
.