

Выполнение этого требования дает возможность не только производить моделирование в режиме on-line, но и экспортировать построенные модели, используя другие программные языки, например Java, SQL, PMML и др. Встраивание модели KXEN в виде программного кода в рабочую базу данных позволяет производить анализ и получать прогнозную оценку в регулярном режиме.
У потенциального пользователя может возникнуть вопрос, почему KXEN не создает отдельное приложение. Ответ достаточно прост - в этой сфере работают уже очень много игроков; также известно, что издержки входа при создании подходящего приложения очень велики. Поэтому создатели KXEN выбрали путь партнерства с ведущими компаниями, которые уже работают на этих вертикальных рынках.
Примером такого партнерства является специальный модуль KXEN для Clementine, хорошо известного приложения Data Mining от SPSS, который интересен как с точки зрения самой интеграции приложений, так и сочетания KXEN с более традиционными техниками Data Mining.
И еще один вопрос, который часто задается потенциальными партнерами: "Зачем мне встраивать технологию KXEN вместо того, чтобы просто связать свое приложение с приложением одного из вендоров (продавцов) Data Mining?" Ответ на этот вопрос следующий: практический опыт показал, что использование дескриптивного анализа и прогнозирования не заканчивается построением модели. Данные меняются со временем, и необходимо периодически производить мониторинг эффективности моделей с целью принятия решения об их корректировке или выставления меток в операционной среде. Компания KXEN включила управление конфигурацией модели в API, тем самым обеспечив сигнализацию об автоматическом выявлении отклонений на входных распределениях или во взаимосвязях входов-выходов. Очевидно, в последнем случае необходимо использование надежных методов, потому что статистические отклонения в производительности модели не должны являться следствием техники моделирования, но должны идентифицировать различия в данных, которые требуется моделировать.
Средства KXEN специально построены на компонентной архитектуре для возможности встраивания в среды не только с целью мониторинга жизненного цикла модели, но и управления этим циклом. Это невозможно через простое соединение с популярным средством прогнозирования. KXEN будет генерировать осмысленные ответы на ситуации из реальной жизни автоматически, просто и действительно быстро. Таким образом, реальный смысл не в том, чтобы запускать внешний пользовательский интерфейс для построения моделей, а в том, чтобы иметь возможность:
∙выявлять отклонения в операционной среде;
∙запускать переобучение моделей;
∙использовать эти модели в режиме реального времени или в процессе пакетной обработки;
∙строить операционные пользовательские интерфейсы, которые будут использовать все возможности по построению моделей.
Структура KXEN Analytic Framework Version 3.0
KXEN Analytic Framework по своей сути не является монолитным приложением, а выполняет роль компонента, который встраивается в существующую программную среду.
313
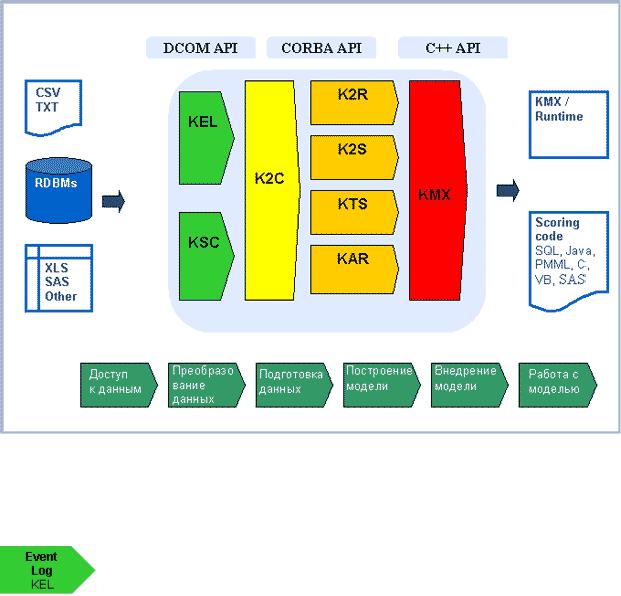
Этот "движок" может быть подключен к DBMS-системам (например, Oracle или MS SQLServer) через протоколы ODBS.
KXEN Analytic Framework представляет собой набор модулей для проведения описательного и предсказательного анализа. Учитывая специфику задач конкретной организации, конструируется оптимальный вариант программного обеспечения KXEN. Благодаря открытым программным интерфейсам, KXEN легко встраивается в существующие системы организации. Поэтому форма представления результатов анализа, с которой будут работать сотрудники на местах, может определяться пожеланиями Заказчика и особенностями его бизнес-процесса. На рис. 27.2 представлена структура KXEN Analytic Framework Version 3.0.
Рис. 27.2. Структура KXEN Analytic Framework Version 3.0
Рассмотрим ключевые компоненты системы KXEN.
Компонент Агрегирования Событий (KXEN Event Log - KEL) предназначен для агрегирования событий, произошедших за определенные периоды времени. Применение KEL позволяет соединить транзакционные данные с демографическими данными о клиенте. Компонент используется в случаях, когда "сырые" данные содержат
314

одновременно статическую информацию (например, возраст, пол или профессия индивида) и динамические переменные (например, шаблоны покупок или транзакции по кредитной карте). Данные автоматически агрегируются внутри определенных пользователем интервалов без программирования на SQL или внесения изменений в схему базы данных. Компонент KEL комбинирует и сжимает эти данные для того, чтобы сделать их доступными для других компонентов KXEN.
Преимуществом использования данного компонента является возможность интегрировать дополнительные источники информации "на лету" для того, чтобы улучшить качество модели.
Компонент Кодирования Последовательностей (KXEN Sequence Coder - KSC) позволяет агрегировать события в серии транзакций. Например, поток "кликов" клиента, фиксирующийся на Web-сайте, может трансформироваться в ряды данных для каждой сессии. Каждая колонка отражает конкретный переход с одной страницы на другую. Как и в случае с KEL, новые колонки данных могут добавляться к существующим данным о клиентах и доступны для обработки другими компонентами KXEN.
Преимуществом использования данного компонента является возможность применять незадействованные прежде источники информации для того, чтобы улучшить качество прогнозирующих моделей.
Компонент Согласованного Кодирования (KXEN Consistent Coder - K2C) позволяет автоматически подготовить данные и трансформировать их в формат, подходящий для использования аналитическими приложениями KXEN. Использование K2C позволяет трансформировать номинальные и порядковые переменные, автоматически заполнять отсутствующие значения и выявлять выбросы.
Преимуществом использования данного компонента является возможность автоматизации подготовки данных, которая позволяет освободить время для непосредственно исследований и моделирования.
Компонент Робастной Регрессии (KXEN Robust Regression - K2R) использует подходящий регрессионный алгоритм для того, чтобы построить модели, описывающие
315

существующие зависимости, и сгенерировать прогнозирующие модели. Эти модели могут затем применяться для скоринга, регрессии и классификации. В отличие от традиционных регрессионных алгоритмов, использование K2R позволяет безопасно справляться с большим количеством переменных (более 10 000). Модуль K2R строит индикаторы и графики, которые позволяют легко убедиться в качестве и надежности построенной модели.
Преимуществом использования данного компонента является автоматизация процесса интеллектуального анализа данных. Модели позволяют детализировать индивидуальные вклады переменных.
Компонент Интеллектуальной Сегментации (KXEN Smart Segmenter - K2S) позволяет выявить естественные группы (кластеры) в наборе данных. Модуль оптимизирован для того, чтобы находить кластеры, которые относятся к конкретной поставленной задаче. Он описывает свойства каждой группы и указывает на ее отличия от всей выборки. Как и в случае с другими модулями, этот модуль также строит индикаторы качества и надежности модели.
Преимуществом использования данного компонента является автоматическое выявление групп, значимых для той конкретной задачи, которую необходимо решить.
Машина Опорных Векторов KXEN (Support Vector Machine - KSVM) позволяет производить бинарную классификацию. Использование компонента подходит для решения задач, основанных на наборах данных с небольшим количеством наблюдений и большим количеством переменных. Это делает модуль идеальным для решения задач в областях с очень большим количеством размерностей, таких как медицина и биология.
Преимуществом использования данного компонента является возможность решения задач, которые прежде требовали написания специальных программ, с помощью промышленного программного обеспечения.
Компонент Анализа Временных Рядов (KXEN Time Series - KTS) позволяет прогнозировать значимые шаблоны и тренды во временных рядах. Используйте накопившиеся хронологические данные для того, чтобы спрогнозировать результаты
316